云计算框架下SPRINT大数据分类算法的优化及应用
2023-08-26周雅静
周雅静

关键词:云计算框架;优化SPRINT分类算法;GiNi值;子节点
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)20-0093-05
0 引言
云计算是一种新型的分布式计算模式,利用信息网络技术将资源发布于网络中,并有偿将计算服务提供给客户。作为一种新型的分布式计算模式,云计算采用了虚拟化核心层[1],为用户提供开源、便捷的计算服务[2]。国内外有部分学者对云计算框架在大数据分类领域的应用进行了研究。学者Tawalbeh L等人[3]从云计算的分布式计算理念入手分析,重点研究云计算框架在处理海量大数据时的实用性;学者Banchhor等人[4]着重研究了云计算框架在数据实时存储方面的优势,能够确保数据分类时核心数据不丢失;包涵等人[5]重点介绍了云计算框架在处理不平衡大数据分类过程中的应用情况,云计算框架有助于解决小样本数据集的分类问题;付东杰等人[6]研究了云计算框架在遥感大数据分类中的应用。
但现有研究涉及的数据集规模有限,且分类算法与云计算框架的结合度较弱,没有发挥出云计算框架的优势。对基础大数据进行分类是云计算的最重要分析环节之一,其中规则归纳法[7]、贝叶斯分类法[8]、决策树法等都是较为常用的分类方法[9]。与前两种分类算法相比,决策树的优势在于结构简单、效率高、准确率有保障,是最受欢迎的分类方法。ID3分类法[10]和SLIQ方法[11]是目前应用最为普遍的决策树模式,ID3分类法以信息增益最大的属性为树节点的判定条件,直到全部的数据分类完成。但该方法的数据计算复杂度过高,且与云计算框架的兼容性较差;SLIQ方法可以同时处理不同类型的数据属性,但该方法分类准确率有待提升,应对大规模数据集的效率也难以满足实际应用的需求。
为解决现有分类树模型的不足,本文在云计算框架下提出一种优化SPRINT大数据分类算法,能够应对处理大规模数据集,并易于实现云计算框架的并行化处理。同时,使得云计算框架下SPRINT大数据分类算法的优势能够得以充分发挥,算法的兼容性更好,且通过最优分割点的选择和数据结构的改进,SPRINT大数据分类算法并行计算优势较为明显,无论是在算法的分类效率还是分类精度方面均得到了显著提升。
1 云计算的应用框架
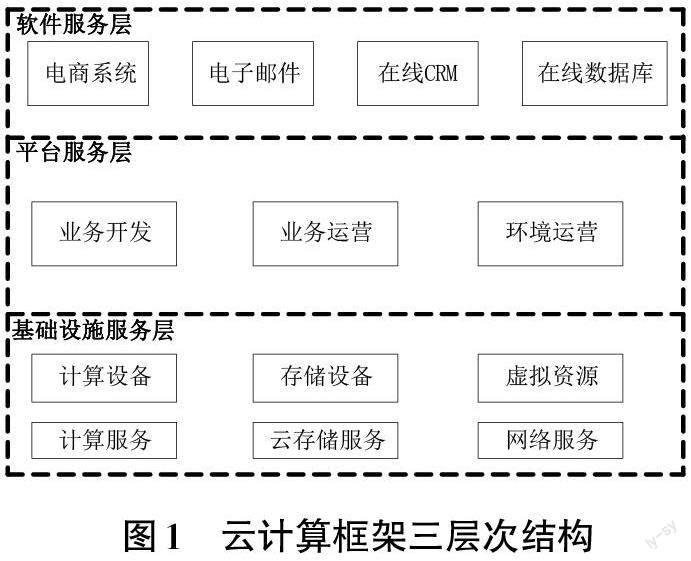
云计算框架在云端布置了多个计算机资源,基于网络将计算任务分配到云端,有云计算需求的用户可在云端申请大数据计算服务和云端存储服务[12]。云计算按照服务类型分为软件服务层、平台服务层和基础设施服务层,各层次的划分如图1所示。
软件服务层的主要用户是开发人员,用户通过浏览器在云端操作,获取相应的计算服务和数据服务,节省了大量的软硬件投入;平台服务层通过环境运营、业务运营和业务开发等整合供应商资源,降低数据运营的成本;基础设施服务层提供了虚拟机服务[13],主要的服务对象是系统管理员。
2 SPRINT 分类算法的优化与应用
2.1 经典SPRINT 算法
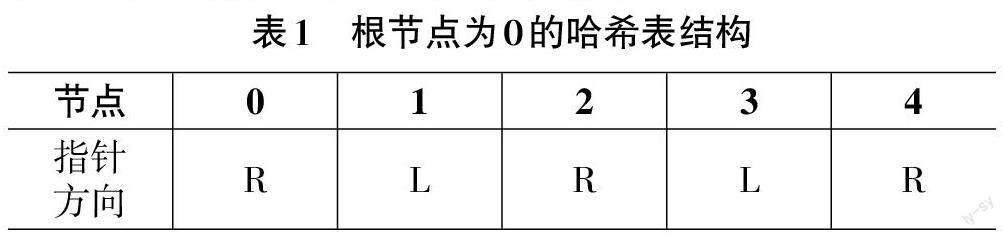
SPRINT算法是一种含有大量类别标识参考数据的监督学习决策树,该算法采用了自上而下的递归方案建树,并将大数据样本划分为训练集和测试集。SPRINT算法定义了属性列表和类直方图,是从训练数据集中创建属性列表,与决策树的根节点对应,对连续型属性进行排序。在建树过程中根节点不断分裂为子节点[14-15],对应的属性列表也被分割到子节点中,同时,解决了数据分类前的多次排序问题。针对离散型大数据,SPRINT算法采用类直方图记录属性值的分布情况,以GiNi指数作为大数据集最优属性的选择标准,再利用哈希表结构记录决策树的分裂信息,将哈希表[16-17]的数值记录于各子节省上,如表1所示(以根节点为0的哈希表为例)。
SPRINT算法既可以处理连续型数据,也可以处理离散型数据,同时支持对数据的并行处理。
2.2 对经典SPRINT 算法的优化与改进
SPRINT 算法作为经典的分类算法之一,具有易于实现并行化及伸缩扩容性良好等优点,但同样存在寻找最佳分割点时计算效率较低等不足,特别对于超大型数据集。为此,文章提出一种基于云计算框架的SPRINT优化分类算法,其方法是利用GiNi值节点的分割提升连续属性的优化能力和分类算法并行计算能力,然后重新划分大数据集的子集,并依据最佳分割点完成决策树的构建,提升大数据分类处理能力。
1) 最佳分割点识别与数据结构改进
SPRINT算法利用GiNi指数寻找最佳的决策树分割点,设大数据集S 的总记录数为n,数据总类别数为m,则GiNi指数表示如下:
经典SPRINT算法在寻找最优属性分割点时需要扫描属性列表,而本文优化的SPRINT算法从当前节点属性集中随机选择一个属性列表,并计算与之对应的GiNi值;然后再选择后补属性列表同时计算GiNi 值,对比两个GiNi值的大小。如果当前属性值较小,将当前的属性列表保存在内存中,删除其他列表信息;如果当前属性值较大,依然保存原有的属性列表,该列表对应的GiNi值即为最优的属性规划。经过改进后的SPRINT算法通过计算GiNi值和哈希表寻找最佳的属性分割点,避免了本地内存过度的占用并降低了资源的消耗。
2.3 优化决策树模型的创建与应用
云计算框架中内置了与待分类大数据集相关的Web应用,用户基于客户端向服务器发送请求,并寻找对应的云服务项目,根据对应的配置调用合适的Servlet。选定的Servlet 内部利用Java 反射机制加载SPRINT大数据的分类,云计算框架的具体Servlet数据分类执行流程如图2所示。
服务器解析用户需求的ID,调用已有的服务器规则引擎,判断ID是否可以本地运行。如果可执行,直接在Servlet 中执行;如果不可执行,则生成对应的IDF_DATA加以封装,并重新到本地服务器上执行。哈希表占用的空间较大,需要外接存储设备拓展空间,存储设备中的属性列表视为子节点对应的属性列表。改进后的SPRINT算法不需要在拓展存儲中生成节点属性列表,而是基于GiNi值结果比较寻找最佳子集分割点,实现对决策树的构建,决策树的建树过程表示如下:
Step1:先实现对大数据集分割属性的划分,同时生成对应的哈希表。
Step2:保留当前层的哈希表,在下一层节点上利用当前层哈希表和拓展内存中的属性列表,生成新的属性列表。
Step3:采用逐层迭代的方式类推,逐渐构建成树状结构。因为在寻找最优分割点时会使用到列表信息,如果不在属性列表中生成列表信息,则只能通过调用哈希列表函数并结合根节点属性解决。
Step4:结合表1及测试数据集的片段生成的决策树如图3所示。
判断数据集中的列表属性是离散型属性还是连续型属性,并对列表执行预排序,如果识别出当前列表中的类别符合要求随即终止迭代。对于离散型属性比较GiNi值来确定,是否选择当前节点作为目标节点;而对于连续型属性,不仅要扫描属性列表,还要计算出每个最优分割节点对应的GiNi值。当完成属性分割得到最优分割节点的GiNi值后,同时生成当前节点对应的哈希表,实现对数据集全部未划分属性的划分,对建树的过程描述如图4所示。
优化SPRINT算法主要从属性分类的最优节点选择和降低算法总体复杂度两个方面来提升和改善经典决策树算法的性能。在云计算的框架下,基于GiNi 值结果比较的子节点属性分裂过程减少了分裂属性列表的操作,同时也减少了在本地磁盘中连续生成子列表的操作,节省了磁盘空间消耗,有效提升了大数据分裂过程中的决策树构建效率。
3 实验结果与分析
3.1 实验环境搭建
为进一步验证云计算框架下优化SPRINT算法的大数据分类性能,在实验过程中安装了MySQL数据库和Infobright列式数据库,并同时创建了10 000条有效的大数据记录。实验所用的相关软硬件设置如表2 所示。
3.2 实验结果分析
1) 算法分类效率对比
从MySQL数据库的记录中随机筛选出1 000条数据并分成10组,分别采用ID3分类法、SLIQ方法和本文改进的SPRINT算法验证对大数据的分类效率,验证过程分为以下3个环节,采用了交叉验证的方法标定特定值提取时间:首先,计算出数据表中单一记录的个数(随机选取一个数据记录)。然后,筛选出标定特定值的记录(共标记3个特定值)。最后,统计不同字段的数据总数(共选择3个字段),统计结果如表3 ~表5所示,提取数值的时间越短,证明算法的效率越高。
统计结果显示,借助云计算框架并基于优化SPRINT算法能够显著提升对目标数据的分类提取效率,节省数据提取和分类时间。随着待分类数据量的持续增加,优化的SPRINT算法稳定性优势会更加明显,能够确保分类计算效率不衰减,数据统计结果如图5所示(以筛选出的1 000条数据为例):
图5中的数值变化显示,随着待分类数据规模的增加,云计算框架的优化SPRINT算法分类耗时短、效率高,性能不衰减。
2) 算法分类性能对比
文章从决策树结构的生成时间和算法的加速比两个方面对云计算框架下优化SPRINT算法的性能进行分析,同时引入ID3分类法、SLIQ方法参与对比。将产生的数据集存储于本地硬盘中,根据数据集的规模生成属性列表,节点数量设定为8,当遍历完10 000条数据后决策树自动生成,3种算法的决策树生成时间变化情况如图6所示:
当参与属性列表构建和决策树形成的节点数量较少时,各分类算法下建树时间相差较小,随着参与建树的节点数量不断增加后,优化SPRINT算法的建树时间更短,优势逐渐显现出来,分类算法的性能优势更加明显。分类算法的加速比能够直接地显示出算法的性能,当有更多的节点接入后决策树的建树时间会以更快的速度减少,加速比越快代表算法的性能越强。3种不同分类算法下的加速比变化情况如图7所示。
优化SPRINT算法的优势在于利用大数据框架提升了节点之间的通信效率,优化了分类算法的细节处理能力。由图6中数据点的变化情况可知,随着接入节点数量的增加,优化SPRINT算法分类加速性能的优势也开始显现出来。统计各算法的分类精度,仍旧从MySQL数据库的记录中随机筛选出1 000条数据并分成10组验证,结果如表6所示(分类精度为正确分类数据值与数据总数的比值)。
随着数据规模的增大,通过分析各算法分类精度的变化情况,可以发现,云计算框架下优化SPRINT算法的数据分类精度衰减相对于相对传统算法更低,算法的性能更加稳定可靠,如图8所示。
4 结束语
本文在云计算框架下设计了一种优化SPRINT大数据分类算法。云计算框架采用了三层次的基础设计结构,便于用户实时需求的传递和通信节点之间数据的有效传输。根据用户实际访问需求和数据集的规模,将大数据集合分割成若干数据集列表,计算出最佳的GiNi值,并優选出最佳的分割节点。实验结果表明,云计算框架下的优化SPRINT大数据分类算法效率更高,性能更强。
