基于检验大数据的多尺度肺恶性肿瘤预测模型研究
2023-08-26王莹顾大勇
王莹 顾大勇


关键词:肺恶性肿瘤;医学检验;大数据;机器学习
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)20-0040-03
0 引言
肺恶性肿瘤常称为肺癌(Lung Cancer,LCA) ,LCA 在我国是最常见的高发恶性肿瘤, 发病率和死亡率均位列恶性肿瘤首位,全球近40%的LCA患者来自我国[1]。LCA在发病早期无典型或特殊临床表现,容易被忽视,多数LCA患者就诊时已进入中、晚期,治疗效果不佳。因此,LCA的早期诊断对于患者能否及时接受治疗显得十分重要。随着科技的进步,人工智能、生物标志物和影像学相结合为LCA筛查开辟了新途径[2],如血清学指标联合多层螺旋CT可提高LCA检出率,并且能够准确区分疾病类型[3]。血液检验具有近似无创、安全性高、操作简单易获取以及价格低廉等优点,LCA相关血清学肿瘤标志物的检测推荐为疑似LCA患者的必检项目之一,但单独检测的这些标志物的特异性、灵敏度不高,联合检测多项肿瘤标志物已逐渐成为LCA诊断的重要辅助手段[4]。研究表明,应尽可能扩大生物标志物的筛选范围[5]。异常增殖的肿瘤细胞随着血液进入各个组织器官,在全身各部位会有不同的表现,分泌的细胞因子及各种功能蛋白会造成各项检验指标发生变化,即使检验指标处于正常参考值范围,但指标间相互的关系也可能发生了改变,只是普通人工筛查模式无法发现,通过人工智能技术对人体一系列代谢指标进行数据挖掘,可以发现很多潜在的变化[6]。研究表明,采用随机森林机器学习算法挖掘277例患者的19项血液常规检验项目形成的预测模型能够识别LCA患者[7],其泛化能力有待进一步验证。目前缺乏采用多种机器学习算法对包括血液、体液、免疫等全量检验项目构建LCA预测模型的进一步研究。
本研究基于多尺度检验项目采用4种机器学习算法分别构建LCA预测模型,并研究检验项目在LCA预测模型中的价值以及不同尺度对预测能力的影响。
1 研究材料与方法
1.1 研究材料
本研究的原始数据来源于深圳市某综合性三甲医院2016年10月1日—2021年09月30日的全量检验数据及相应诊断结果。在大数据平台通过数据集成、数据治理和数据开发形成检验大数据。检验项目总计1 297项(包括少量来自不同仪器设备重复的相同检验项目)。根据LCA相关诊断结果检索的21 270 例LCA 患者和混合19 841 例健康体检人员合计41111例人员对应的LCA检验大数据。经过数据类型转换、归一化成为机器学习数据源。
1.2 方法
采用逻辑回归二分类(Logistic Regression,LR) 、支持向量机(Support Vector Machine,SVM) 、K 近邻(KNearestNeighbor,KNN) 和服务器参数可伸缩多元决策回归树(Parameter Server-Scalable Multiple AdditiveRegression Tree,PS-SMART) 4 种机器学习算法挖掘全维度检验项目与诊断结果的关系。其中LR 的可解释性强,训练的参数即为每个特征(检验项目)的权重且输出为概率值,非常适合二分类场景。SVM基于统计学习理论的一种机器学习方法,通过寻求结构风险最小化,提高学习机泛化能力,从而实现经验风险和置信范围最小化。SVM属于强分类器,准确度较高。KNN算法简单易用,根据距离新的对象最近的K个点的类别预测新的对象对应的类别。GBDT(GradientBoosting Decision Tree) 二分类算法的原理是设置阈值,如果特征值大于阈值,则为正例,反之为负例。PS-SMART是GBDT基于PS实现的迭代算法。4种机器学习算法的原理机制不同,有利于互相佐证。
机器学习业务流程包括数据拆分、模型训练、模型预测和预测结果评估,同一机器学习数据源被不同机器学习算法对应的数据拆分模块分别随机拆分为两类(本研究采用80%为训练数据和20%为测试数据的拆分比例),随机拆分是数据分类差异的唯一因素。机器学习训练模块使用机器学习算法基于训练数据生成预测模型,预测模型对测试数据计算得出预测结果,预测结果分别导入相应的混淆矩阵模块和二分类评估模块,对4种预测模型分别进行评估。业务流程如图1所示,为了有效对比预测模型,所有实验步骤的设定与实施完全一致。
1.3 预测水平评估指标
评估采用混淆矩阵和二分类评估两种方法。
混淆矩阵每一列代表一个类的预测情况,每一行表示一個类的实际样本情况。混淆矩阵采用准确率、精确率、召回率和F1 Score合计4个评估指标[8]。其中F1 Score是为了均衡地评估精确率和召回率而设计的综合评估指标。
二分类评估主要采用F1 Score和受试者工作特征曲线(Receiver Operating characteristic Curve,ROC) 下面积(Area Under Curve,AUC) 两个指标,AUC数值为[0,1]区间,越接近1区分能力越高。
2 实验与分析
2.1 全量检验项目预测模型
2.1.1 二分类评估结果
4 种机器学习预测模型的AUC和F1 Score均高于0.980和0.940,如表1所示。表1表明4种机器学习预测模型均有较高的预测能力。
2.1.2 混淆矩阵评估结果
4 种机器学习模型的正样本的准确率、精确率、召回率和F1 Score共计16项,其中14项高于0.900,剩余2项均高于0.850,如表2所示。
2.1.3 LR 二分类预测模型
LR二分类预测模型由患者年龄、性别、就诊类别和1 297项检验项目合计1 300项组成,其中权重前20 项如表3所示。
权重为该检验项目在LR二分类模型中的系数,权重数值越大,该检验项目与目标列对应诊断结果的相关性越大。由于项目编码缺乏统一规划的历史原因,存在项目编码6465和5316为来自不同仪器设备的相同检验项目的情况。缺失率指未做该检验项目的患者数量与总计21 270例患者的比率,20项特征列中缺失率大于30%的高达18项,只有年龄和就诊类别(住院或门诊)两项缺失率小于30%。
2.2 多尺度预测模型对比分析
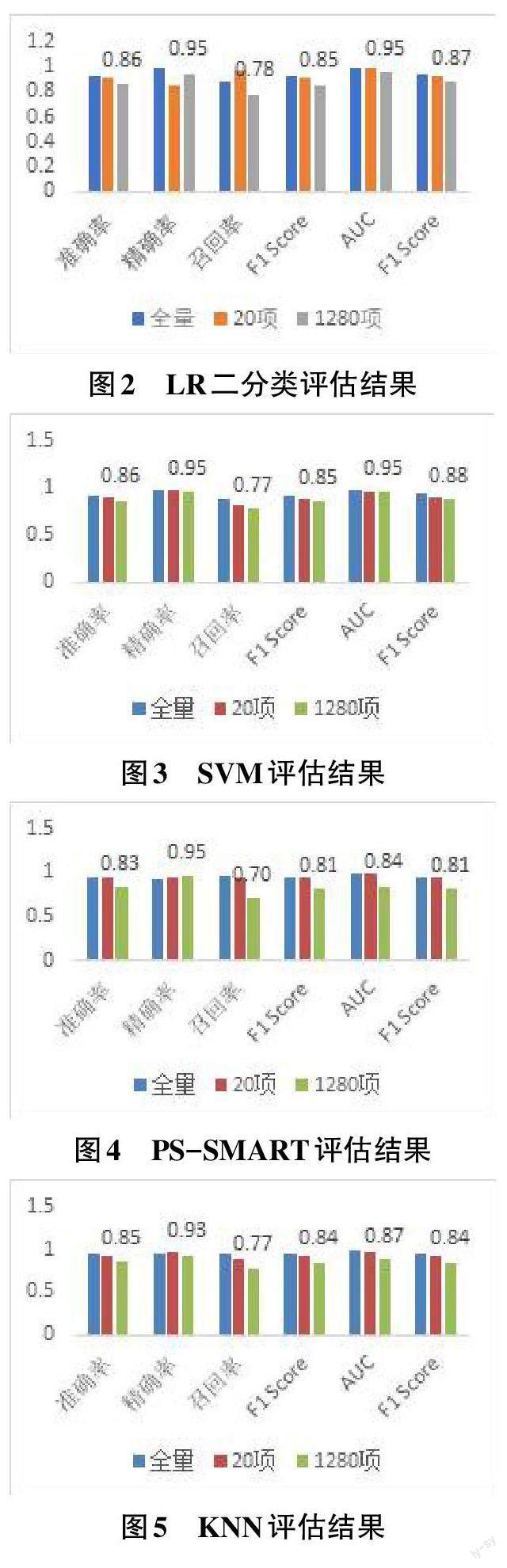
将原1 300项特征列分为两部分:20项权重大的特征列和剩余1 280项特征列,采用4种机器学习算法分别对20项特征列和1 280项特征列训练生成预测模型,通过混淆矩阵和二分类评估两种方法评估预测水平。基于全量、20项、1 280项检验项目数量形成三种不同尺度的预测模型。
结果表明,全量模型的整体预测水平优于20项特征列模型,20项特征列模型优于1 280项特征列模型。相对整体预测水平,SVM算法生成的预测模型各项指标对比结果完全一致(图3) ,LR二分类模型的精确率和召回率(图2) ,PS-SMART 模型的精确率(图4) ,KNN模型的精确率(图5) 对比结果略有反差。图中标注数据均为预测水平相对较低的1 280项预测模型的预测结果。
3 讨论
本研究采用4种机器学习算法并行生成的预测模型均具有较高的预测水平,表明预测模型的稳定性和可靠性。以直观输出参数、可解释性强的LR预测模型为例,其中权重较大检验项目与诊断结果相关性较大可分为三种情况,第一种是已经具有大量临床研究,包括年龄、神经元特异性烯醇化酶(Neuron-Specific Enolase,NSE)、红细胞体积分布宽度、超敏C 反应蛋白、尿蛋白、肿瘤相关物质综合检测等18项。研究表明,年龄是LCA发病的重要因素,经过统计21270 例LCA患者中年龄大于40岁为20 529例,大于60岁为12 005例(占比56.4%) 与中国国家癌症中心调查结果(2005—2014年的10年间,年龄≥60岁肺癌患者比例从41.2%增至56.2%) [9]基本相符。LCA患者年龄分段统计与深圳市LCA发病率在0~29岁年龄段极低,30~49岁年龄段出现缓慢增长,50岁之后发病率随着年龄增长而迅速上升,在75~84岁年龄段发病率达到最高峰[10]基本相符。Cai-Ming Xu等人[11]研究认为神经元特异性烯醇化酶NSE在各种肺部疾病的诊断、治疗监测和预后评估中可以发挥重要作用。第二种数学意义上的相关性,例如21 270例LCA患者其中16 349例为住院患者,4 921例为门诊患者。住院患者约占总数的77%,特征相对明显,故表现出相关性强,也符合多数LCA患者就诊时已进入中、晚期的状况。第三种是有待进一步研究的检验项目,例如,目前尚未有二氧化碳结合力与LCA的关系研究,推测LCA患者呼吸功能障碍导致二氧化碳结合力增高,从而表现为二氧化碳结合力与LCA诊断结果强相关。
机器学习预测模型的水平取决于训练数据的质量,训练数据尽可能全面覆盖所代表的真实的数据类型,人为甄选数据会错失发掘数据潜在价值的机会。例如在数据准备阶段,所有检验项目中,仅入选缺失值<30%的变量[12-13] ,若参照该标准,则本研究中全量LR二分类模型中的权重前20项特征列中18项检验项目均不符合要求而被排除。通过多尺度预测模型的对比,直观展示了基于全量检验项目预测模型的优势。
4 总结
本研究通过预测模型一方面定量展示了检验项目在LCA诊断中的价值,另一方面通过多尺度预测模型的对比分析佐证了基于全量检验项目构建预测模型的必要性。本研究使用了近5年的全量检验数据作为样本,采用3种检验项目數量尺度,存在一定的局限性。混合对照的健康体检人员不排除存在LCA患者的可能性,从而导致预测模型存在较小的偏差。后续可以纳入多中心的检验数据,并结合临床诊断进一步挖掘检验项目与疾病诊断相关的信息。
