融合时空域注意力模块的多流卷积人体动作识别
2023-08-24吴子依陈泯融
吴子依, 陈泯融
(华南师范大学计算机学院, 广州 510631)
在人体动作识别任务中,主要的输入数据有视频和人体骨架序列。在基于视频的动作识别中,一般以RGB数据作为输入,根据像素点生成特征图像,进而通过分类达到动作识别的目的[1-4]。在基于人体骨架序列的动作识别中,一般以人体关节点的位置信息作为输入,并对其进行特征提取和建模,从而得到最终的分类结果[5-7]。随着高精度深度传感器的技术改进[8]和姿态估计算法[9]对应的准确率不断攀升,人体骨架数据越来越易于获取。由于人体骨架关节点一般由2维或3维的坐标来表示,对应耗费的计算量较小,且人体骨架关节点作为输入数据,具有对照明条件、背景噪声和遮挡等干扰不敏感的优点,使得基于骨架的动作识别成为了计算机视觉领域的研究热点。
近年来,在基于骨架的动作识别领域中,较为主流的深度学习网络有循环神经网络(Recursive Neural Network,RNN)[10-11]、图卷积网络(Graph Convolutional Networks,GCN)[12-16]和卷积神经网络(Convolutional Neural Networks,CNN)[17-21]。其中,RNN运用于动作识别任务中可以很好地处理时序问题;GCN擅长处理非欧几里得的图结构数据,可以根据人体拓扑结构的先验知识来对人体骨架进行动态建模;CNN可通过多层堆叠的卷积操作来提取图像的高阶特征,弥补了RNN在空间特征提取上的不足。与GCN相比,CNN也不需要预先考虑人体骨架结构图的设计。目前仍有大部分研究倾向于设计基于CNN的动作识别网络。如LI等[20]提出了一个端到端的共现特征学习卷积神经网络框架:首先在不同层级中将上下文信息逐渐聚合,然后通过信道置换来对骨架中所有关节点之间的联系进行建模,从而通过获取全局共现特征来提高网络的动作识别能力。
此外,在计算机视觉领域中,注意力机制[22-25]因其有助于网络对骨架序列进行重要性排序,使网络选择性地对关键信息进行编码而受到研究者们的青睐。如:FAN[24]提出了由自注意力与交叉注意力组成的注意力模块,该模块有助于网络提取相应场景中与上下文信息高度相关的关键节点;SI[25]提出了新型注意力图卷积网络(AGC-LSTM),利用注意力机制增强每层网络中关键节点的权重信号。然而,已有研究大多将注意力置于通道或者空间维度上,忽略了时序对于动作识别的重要性。比如“坐下”和“起身”虽然动作构成相同,但由于发生的时间顺序不同而导致动作类别不同。
综上所述,本文为了显式地对骨架序列中帧内空间特征和帧间时序特征进行编码,并运用注意力机制对时间和空间维度上的特征进行有效的权重分配,设计了基于注意力增强的多流卷积神经网络(Attention Enhancement Multi-stream Convolutional Neural Network,AE-MCN)。在AE-MCN网络中,自适应选取运动尺度模块提取人体骨架运动中具有辨别性的轨迹信息,用以提高网络对全局运动的建模能力;融合时空域的注意力模块对高维特征图进行空间维度和时间维度上的权重信号分配,帮助网络获取到有效的时空特征。最后,在3个常用的人体动作识别数据集(NTU60、JHMDB和UT-Kinect)上,将AE-MCN网络与ST-GCN[12]、SR-TSL[17]等网络进行了对比实验。
1 预备知识
1.1 视点不变性特征表示
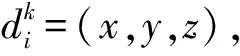
(1)
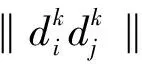
1.2 通道注意力模块
在计算机视觉的领域中,注意力机制可以帮助聚焦部分重要信息,使得网络获得更具价值的特征信息,进一步提升网络性能。JIE等[22]提出运用通道注意力机制来获取不同通道上的全局特征值,并通过广播和矩阵乘法来实现注意力的分配。通道注意力模块通过对卷积层中每个通道上的信息进行权重分配,进而帮助网络获得有效信息。通道上信息的权重越大则代表该通道上的信息越重要,通道上信息的权重越小则代表该通道上的信息的重要性越低。通道注意力模块的结构如图1所示。

图1 通道注意力模块示意图[28]
如图所示,通道注意力模块的操作流程分为以下几步。首先,通过挤压操作F1获取输入特征图X在通道上的上下文信息,得到矩阵N;其次,经由全连接层F2和激活函数操作对矩阵N进行通道上的权重分配,其计算公式如下:
S=σ(W2δ(W1N)),
(2)
其中,W1和W2均为权重矩阵,δ()为PReLU 激活函数,σ()为Sigmoid激活函数。

2 基于人体骨架序列的多流卷积神经网络
本文从人体运动中复杂的时空关系角度出发,显式构建了空间、时序和原始特征模块,让网络可以对骨架序列数据进行有针对性的特征提取与建模;同时,为了对提取出的细粒度特征进行时间维度和空间维度上的权重分配,构建了融合时间域和空间域的注意力模块(Spatio-temporal Domain Attention Module,STAM),以帮助网络更好地获得骨架序列中有效的时空特征。
2.1 时序特征提取模块
视点不变性特征与其他几何特征一样,不包含全局运动信息。YANG等[21]在网络中引入2种运动尺度特征来提取全局运动信息:一是原尺度动作特征,为相邻帧对应关节点的轨迹信息;二是快尺度动作特征,为每两帧之间对应关节点的轨迹信息。人体运动有快有慢,为了学习具有鲁棒性的全局运动信息,本文引入了自适应选取运动尺度模块,其实现原理如图2所示。
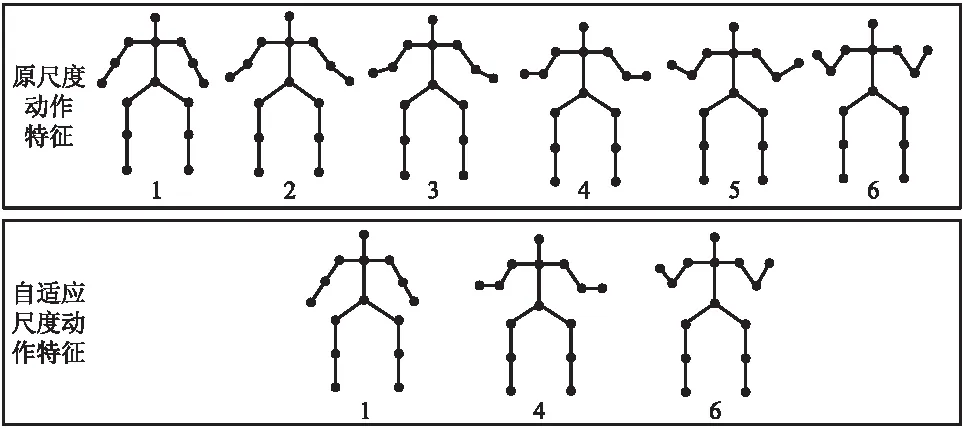
图2 自适应选取运动尺度模块实现原理图
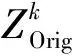
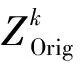
2.2 融合时间域和空间域的注意力模块
在融合时间域和空间域的注意力模块(STAM)中,时间注意力模块(Temporal Attention Module,TAM)以网络隐层输出作为模块的输入数据,将数据的时间维度和通道维度进行互换,并通过压缩和再广播操作来获得时间维度上每帧对应的权重信号;空间注意力模块(Spatial Attention Module,SAM)在通道维度上对输入数据进行压缩,使网络获得特征图在通道上的上下文信息,实现空间维度上的注意力分配。TAM模块和SAM模块在融合前独立运行,参数不共享。
在本研究中,STAM模块的输入数据为网络隐层的输出QC×T×N,其中,C为输入特征图的通道数,T为骨架序列中的帧数,N为骨架中的关节点数。在SAM模块中,为了获取特征图在空间维度上信息的整体分布,首先由卷积操作(Conv2D)和Sigmoid激活函数得到空间注意力张量as1×T×N,即将全通道上的信息进行压缩后赋予特征图上每一位置对应的权重信号,表示该位置与其他帧、关节点之间的关联强度。在TAM模块中,首先将Q在时间维度和通道维度上进行转换,得到Q′T×C×N;然后,通过卷积操作和平均池化(AvgPool)对Q′进行压缩,得到qT×1×1;最后,经扁平化(flatten)和全连接层(FC)操作后,利用Sigmoid激活函数得到时间注意力张量atT×1×1。操作流程如下所示:
as=σ(Convs(Q)),
at=σ(fc(AvgPool(Convt(Q′)))),
其中,Convs()为SAM模块上压缩通道数为1、卷积核大小为1×1的卷积操作,用以获取特征图在空间维度上的全局信息;Convt()为TAM模块上5×5的卷积操作,用以获取特征图在时间维度上的局部感受野,进而通过平均池化操作进一步压缩特征图尺寸,从而得到全局特征响应值。为了实现特征图上的注意力分配,将as和at进行维度转换并广播,分别得到注意力矩阵As和At,两者维度均为C×T×N,然后将As和At以串行的方式与输入数据Q进行相乘。操作流程如下所示:
Sa=Q⊙As,
A=Relu(Sa⊙At),
其中⊙为对位相乘。STAM模块结构如图3所示。
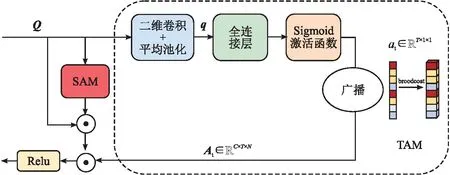
图3 融合时间域和空间域的注意力模块图
2.3 多流卷积神经网络架构
本文提出了融合时空域注意力模块的多流卷积神经网络(AE-MCN),该网络对帧中不同关节点之间的空间特征和帧间时序特征进行提取和建模,并由融合时空域的注意力模块对特征图进行权重分配,从而使网络获得较好的动作识别性能。
AE-MCN网络主要由3个模块组成:空间特征模块、时序特征模块和原始特征模块。每个模块中包含3层CNN,每层CNN在卷积操作之后都带有批归一化操作和Leaky_Relu激活函数。空间特征模块、时序特征模块和原始特征模块中的信息编码方式如下:
为了有效地融合高维时空特征并获得更好的分类结果,首先将空间特征模块、时序特征模块和原始特征模块的输出在通道维度上进行连接,得到维度为C×T×N的特征图;然后,将该特征图输入到STAM模块中,并在STAM模块之后的每层CNN中都加入滑动窗口尺寸为2的最大池化操作;最后,通过空间最大池化层(Spatial MaxPooling,SMP)操作来聚合输出特征图在时间维度上对应的关节点信息,并经由全连接层得到分类结果。AE-MCN网络结构如图4所示。
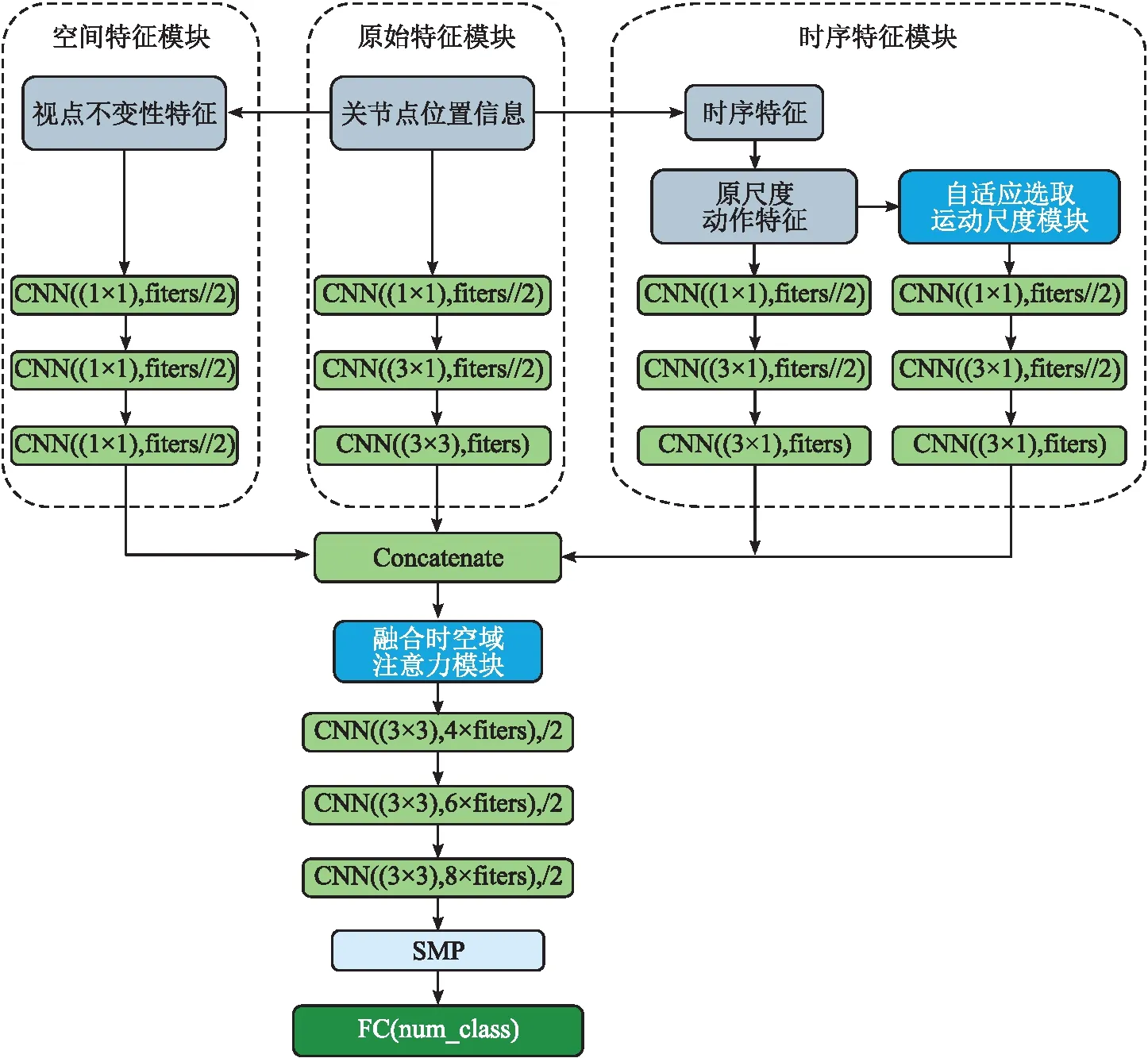
图4 AE-MCN网络结构图
3 实验结果及分析
3.1 实验数据集
为了验证AE-MCN网络的有效性,本文在3个人体骨架动作识别数据集(NTU RGB+D数据集(NTU60)[31]、JHMDB数据集[32]和UT-Kinect数据集[33])上进行了一系列实验。3个数据集的具体构成和评估标准为:
(1)NTU60数据集由Kinect传感器收集而成,用于3D人体骨架动作识别,由56 880个动作样本组成,包含60个动作类别。每帧人体骨架包含25个人体主要关节点,每个关节点位置由3D坐标表示。本研究遵循交叉对象(Cross-Subject,CS)和交叉视角(Cross-View,CV)2类评估基准,将NTU60数据集划分为训练集和测试集:在CS评估基准[31]上,按照人物ID来划分训练集和测试集;在CV评估基准[31]上,将相机1采集的样本作为测试集,相机2和相机3采集的样本作为训练集。本文在CS和CV评估基准的训练集中,分别随机选择10%的数据用做验证集。
(2)JHMDB数据集中总共有928个动作样本,这些样本被拆分成3个训练集和3个测试集,每个拆分集中大约有650个训练样本和250个测试样本。每个动作样本由一个骨架视频来表示,视频中每帧骨架包含15个人体主要关节点,每个关节点用2D坐标(x,y)表示。本文选择三折交叉验证策略得到最后的动作识别准确率。
(3)UT-Kinect数据集包含200个动作样本,对应10个动作类别。其中每个受试者的每个动作都被记录2次。骨架中每个关节点由3D坐标(x,y,z)表示。
3.2 实验参数设置
网络架构由Python编程语言实现并采用PyTorch深度学习框架[34],将Pycharm作为集成开发环境,实验过程中使用1个RTX 2080-ti GPU。在NTU60、JHMDB和UT-Kinect数据集上的实验批大小都设置为64。本文采用ADAM优化器[35],初始学习率为0.000 8,学习率分别在第45、65、80次处衰减10%,训练在第90次结束;权重衰减初始值设置为 0.000 1;所有实验都使用平滑标签[36],其中平滑因子设为0.1,通过交叉熵损失进行分类训练。
3.3 消融实验
3.3.1 自适应选取运动尺度模块的消融实验 本文在NTU60数据集上进行相关的消融实验。首先,将不含自适应选取运动尺度模块、STAM模块且滤波器数目为64个的网络作为基准网络(baseline);其次,在基准网络的基础上添加自适应选取运动尺度模块,并将滤波器数为16、32、64个的网络依次记为AE-MCN-A、AE-MCN-B、AE-MCN-C,以探究参数量对网络动作识别性能的影响。
由实验结果(表1)可知:(1)在添加了自适应选取运动尺度模块的情况下,当滤波器数目为64时,网络在NTU60数据集上取得最佳识别效果。(2)AE-MCN-C网络在CS、CV基准上的识别准确率分别达到了84.9%、91.3%,比基准网络对应的识别准确率分别高出0.4%、0.3%,这说明了滤波器数目为64时,自适应选取运动尺度模块有助于网络提取更具鲁棒性的全局运动特征,使得网络可以更好地实现动作建模。
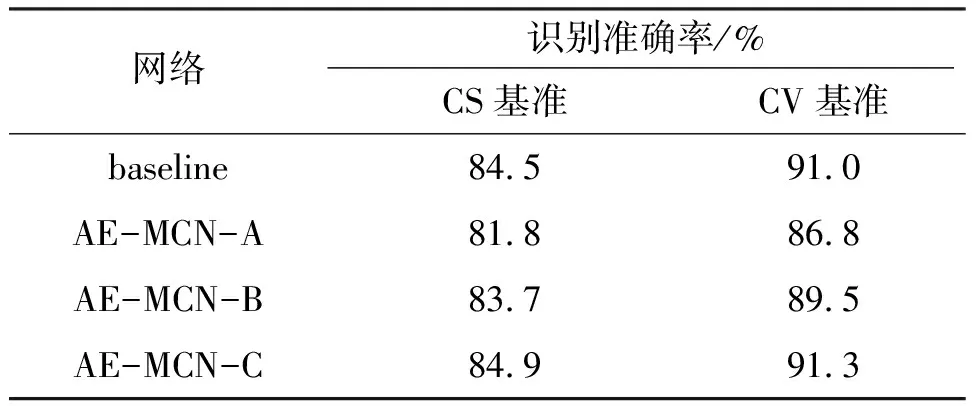
表1 不同自适应选取运动尺度模块在NTU60数据集上的性能
3.3.2 融合时间域和空间域的注意力模块实验 首先,在AE-MCN-C网络的基础上分别加入时间注意力模块(TAM)、空间注意力模块(SAM),设置了2组对比网络,以探究两者对网络识别效果的影响;其次,由于时间注意力模块与空间注意力模块有Serial(串行)、Parallel(并行) 2种组合方式,其中串行方式分为先由时间维度上的注意力矩阵与输入数据进行点乘操作、先由空间维度上的注意力矩阵与输入数据进行点乘操作2种,所以,在AE-MCN-C网络的基础上又设置了3组对比网络:AE-MCN-C+TAM+SAM(Serial)、AE-MCN-C+SAM+TAM(Serial)和AE-MCN-C+TAM+SAM(Parallel),以探究时间注意力模块和空间注意力模块的不同组合方式对网络识别效果的影响。
在NTU60数据集上的实验结果(表2)表明:(1)单独引入时间注意力模块(TAM)或空间注意力模块(SAM)的网络的识别准确率均低于融合时间域和空间域的注意力模块的网络,这说明针对融合后的时空特征图,引入单一的时间注意力或空间注意力模块不利于网络提取有效的时空特征,对时空特征图进行有针对性的权重分配更有助于网络提取到更具判别性的动作特征。(2)AE-MCN-C+SAM+TAM(Serial)网络在CS、CV基准上的识别准确率分别达到了86.3%、92.4%,表明先由空间维度上的注意力矩阵与输入数据进行点乘,再获取特征图时间维度上注意力的串行组合方式获得了最佳的识别效果。

表2 不同组合方式的时间和空间注意力模块在NTU60数据集上的性能
3.4 对比实验
在3个数据集上,将包含了自适应选取运动尺度模块和融合时空域注意力模块的动作识别网络(AE-MCN)与 ST-GCN[12]、DD-Net[21]等网络进行了对比实验。其中,在NTU60数据集上,将AE-MCN网络与VA-LSTM[37]、ElAtt-GRU[38]、ST-GCN[12]、DPRL+GCNN[39]、SR-TSL[17]、PR-GCN[13]网络进行对比;在JHMDB数据集上,将AE-MCN网络与Chained Net[40]、EHPI[18]、PoTion[41]、DD-Net[21]网络进行对比;在UT-Kinect数据集上,将AE-MCN网络与FusingFeatures[42]、ElasticCoding[43]、GeoFeat[22]、GFT[44]网络进行对比。
由实验结果(表3至表5)可知 AE-MCN网络在3个数据集上的分类效果最好:(1)在NTU60数据集上,AE-MCN网络在CS、CV基准上都取得了最好的动作识别效果。在CS基准上,AE-MCN网络取得了86.3%的识别准确率,分别比PR-GCN、SR-TSL网络提高了1.1%、1.5%;在CV基准上,AE-MCN网络取得了92.4%的识别准确率,与SR-TSL网络的识别准确率持平,但比PR-GCN网络的识别准确率高出0.7%。(2)在JHMDB数据集上,DD-Net网络[21]使用一维卷积,通过关节点联合距离特征(Joint Collection Distances,JCD)和全局运动尺度模块进行空间、时间维度上的特征提取与建模,取得了81.6%的识别准确率。而AE-MCN网络通过引入自适应选取运动尺度模块和融合时空域的注意力模块,帮助网络提取到具有鲁棒性的全局特征和重要的时空特征,在JHMDB数据集上取得了83.5%的识别准确率,比DD-Net网络的识别准确率提高了1.9%。(3)在UT-Kinect数据集上,与GFT网络相比,AE-MCN网络的识别准确率提高了1.9%。综上所述,网络通过自适应选取运动尺度模块可获取人体骨架序列中重要的时序特征,且融合时空域的注意力模块可帮助网络获得分流提取到的特征图在时间维度和空间维度上的权重分配,从而有效地提高网络的动作识别性能。
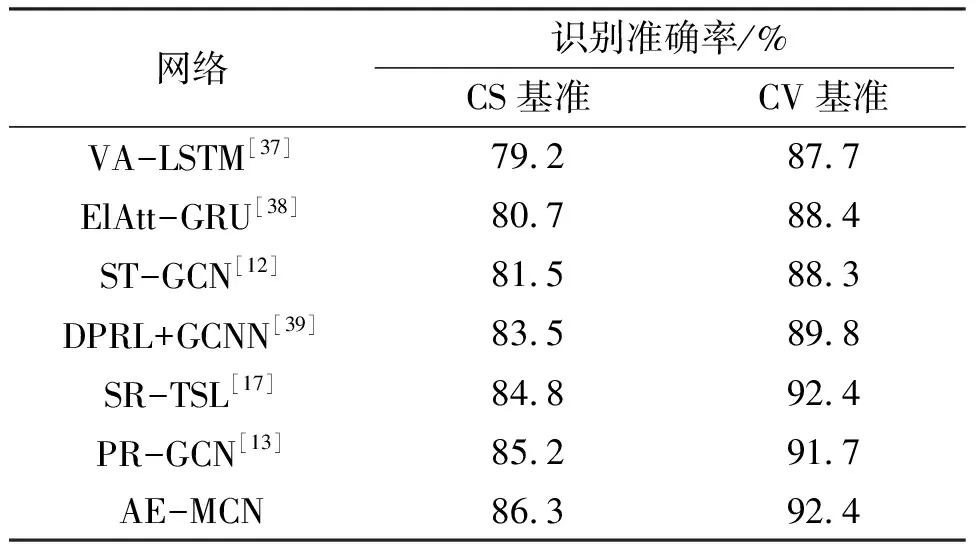
表3 不同网络在NTU60数据集上的性能比较

表4 不同网络在JHMDB数据集上的性能比较

表5 不同网络在UT-Kinect数据集上的性能比较
4 总结
为了更好地实现特征提取与建模,本文设计了多流卷积神经网络(AE-MCN)。首先,为了学习具有鲁棒性的全局运动信息,设计了自适应选取运动尺度模块,以从原尺度动作特征中提取重要的时序特征,并减少特征提取过程中的信息损失;其次,通过融合时空域注意力模块(STAM)来对网络隐层输出数据进行注意力的分配,从而帮助网络获取有效的时空特征。在NTU60数据集上的消融实验结果证明了自适应选取运动尺度模块和STAM模块的有效性:添加了自适应选取运动尺度模块且滤波器数量为64的网络在CS、CV基准上的识别准确率分别达到了84.9%、91.3%,比不含该模块的网络的识别准确率分别高出0.4%、0.3%;添加了STAM模块的网络取得了最佳的识别效果,在CS、CV基准上的识别准确率分别达到了86.3%、92.4%。在3个常用的人体动作识别数据集(NTU60、JHMDB和UT-Kinect)上的对比实验结果表明AE-MCN网络的有效性:在NTU60数据集上,AE-MCN网络在CS、CV基准的识别准确率分别为86.3%、92.4%;在JHMDB数据集上,AE-MCN网络的识别准确率为83.5%;在UT-Kinect数据集上,AE-MCN网络的识别准确率为97.9%。实验结果表明AE-MCN网络中的分流结构可提取出具有判别性的时空特征,且由时空域注意力模块对其进行时间维度和空间维度上的权重分配有助于网络获得较好的动作识别效果。
由于人体骨架数据较难刻画细微的动作且不包含交互对象(书和键盘)等的相关信息,导致AE-MCN网络在捕捉高精度动作信息时存在一定难度,对多局部细粒度化动作和人物交互动作的识别准确度还存在较大的进步空间,例如打喷嚏、敲键盘和看书等动作。后续研究可以结合多模态数据对动作进行更加全面的描述,从而使基于骨架的人体动作识别模型可以更好地识别细微动作,并实现人物之间交互的动作建模。
