一种基于语音识别的PLC控制方法
2023-08-21侯龙潇雷珊珊
侯龙潇,张 桦,赵 聪,雷珊珊
(河南省机械设计研究院有限公司,河南 郑州 450003)
在工业生产中,设备的操作员通常使用按钮、触摸屏、鼠标、键盘等人机交互装置对工业设备进行控制。其原理是通过输入装置进行信号的输入和参数的修改,经由可编程逻辑控制器(PLC)内部进行逻辑处理后输出指令到外部执行机构,从而实现对设备的控制。
随着工业4.0时代的到来,越来越多的工厂引入自动化设备来代替原有的人工作业,从原来的纯手工作业和一人一机器的作业模式转变为一人控制一条生产线的作业模式。“机器换人”模式的优点是可以提高工作效率、节约人力成本等,但缺点也随之而来。面对越来越复杂的生产工艺,为了满足需求,工业设备的数量会越增越多,操作逻辑也会变得越发繁琐,按钮、触摸屏按键等输入装置的数量也会随之增多,传统的人机交互方式的复杂程度也会相应增加。操作人员需要从众多的按钮和界面中找到正确的输入装置进行操作,不仅浪费时间,对操作人员的素质要求也高,没有经过系统培训和长时间操作经验的操作员很难胜任工作。
基于上述问题,本文研究了一种通过使用语音指令控制PLC的方法,旨在代替传统的输入装置完成对工业设备的控制,降低人机交互的复杂程度,缩短操作人员的训练周期。
1 方法概述
本文所述方法的流程如图1所示。

图1 方法流程图
2 语音指令样本处理
2.1 语音样本采集
为了获取原始的语音样本,本文使用pyaudio模块对语音样本进行采样。采用16 kHz采样帧率、2.5 s时长采集单个语音指令样本。为了方便后期模型训练,将采集到的原始语音样本以样本分类号加样本序号的方式命名,样本分类号和样本序号之间使用符号“-”进行分隔,以wav格式保存语音样本。
2.2 谱减法去噪
原始语音指令样本中噪声的主要构成是环境噪声,为了获得纯净的语音样本,需要对语音样本进行去噪声处理。
本文采用谱减法剔除语音样本中的环境噪声。谱减法的基本原理是默认混合信号(含噪信号)的前几帧仅包含环境噪声,并利用混合信号的前几帧的平均幅度谱作为噪声的幅度谱,最后利用混合信号(含噪信号)的幅度谱与估计到的幅度谱相减,得到纯净语音信号的幅度谱。
读取采集到的原始语音样本文件,将波形数据转换为数组x(n)。对x(n)加汉明窗并分帧,则每帧数据为xi(n)。对第i帧信号进行傅里叶变换至频域即可得到第i帧信号的幅度谱Xi(w):
(1)
式中:n为当前帧编号,w为时域离散信号的编号,N为时域离散信号的点数。
假设语音样本的前几帧中没有有效的信息成分,即前几帧为纯粹的噪声信号,则取语音样本的前n帧作为噪声帧,估计出噪声帧的平均能量值Dn(w)为:
(2)
当语音信号大于噪声的功率时,用原始语音减去噪声成分;当语音信号小于噪声的功率时,则用估计出来的噪声信号表示下限值:
(3)
式中:Yi(w)为去噪后语音帧幅度谱,D(w)为噪声帧幅度谱。
之后再将去噪声后的每帧幅度谱信号进行傅里叶逆变换得到时域语音信号,将去噪声后的语音样本以wav格式进行保存。
2.3 端点检测
每个语音样本的采集时长为2.5 s,但是真正有意义的音频并不是充满整个采集周期,此外由于语音样本经过2.2节的去噪声处理,会使语音样本的起始端和末尾端产生空白段。端点检测就是在一段包含语音的信号中,准确地确定语音的起始点和终止点,将语音段和非语音段区分开[1]。
本文采用双门限法对语音指令样本进行端点检测。一段语音信号分为静音区、清音区和浊音区三部分。其中浊音区的短时能量最大,取一个较高的短时能量阈值区分浊音区和清音区;清音区的能量较低,取一个较低的短时能量阈值来判定语音的开始;另外由于微小的噪声也有可能超过低阈值,但并不是语音的开始,这就需要通过短时过零率区分清音区和静音区。流程如下:
1)取一个较高的短时能量作为阈值MH,利用这个阈值,先分出语音中的浊音区(如图2中的A1~A2区间);

图2 双门限法示意图
2)取一个较低的能量阈值ML,利用这个阈值,从A1、A2向两端进行搜索,将较低能量清音区也加入到语音段(如图2中的B1~B2区间);
3)取一个短时过零率的阈值Zs,利用这个阈值,从B1、B2继续向两端进行搜索,短时过零率大于3倍Zs的部分,则认为是语音的清音部分。将该部分加入语言段,就是求得的语音段(如图2中的C1~C2区间)。
2.4 计算MFCC
在语音识别领域,最常用到的语音特征就是梅尔倒谱系数(Mel-scale frequency cepstrum coefficients,MFCC)[2]。通过对人类听觉的研究发现,人类听觉的敏感度取决于声波的频率,其中200~5 000 Hz的声波频率能最大程度地影响语音的清晰度。此外,由于频率较低的声音在内耳蜗基底膜上行波传递的距离大于频率较高的声音,因此低音容易掩蔽高音[3]。为此,人们在从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波[4]。将每个梅尔滤波器输出的信号能量作为此信号的MFCC参数,对此参数进一步处理组合后作为语音的MFCC特征。
由于高频语音部分的能量较小,为了提升高频部分,使信号的频谱变得平坦,先对端点检测后的语音信号进行预加重处理:
y(n)=x(n)-αx(n-1)
(4)
式中:y(n)为预加重后的数据;x(n)为当前帧数据;α为预加重系数,取值0.97。
完成预加重后,将信号进行分帧。其中帧长25 ms,帧移10 ms,对每一帧数据进行加窗。对加窗后的每帧信号进行快速傅里叶变换:
(5)
式中:N1为帧总数。
获取每一帧的能量总和:
Di=|Xi(w)|2
(6)
式中:Di为分帧后每一帧的能量总和。将功率谱通过一组梅尔尺度的三角窗滤波器组(共26个),对信号的功率谱滤波。每一个三角窗滤波器覆盖的范围都近似于人耳的一个临界带宽,以此来模拟人耳的掩蔽效应。滤波器组的示意图如图3所示。
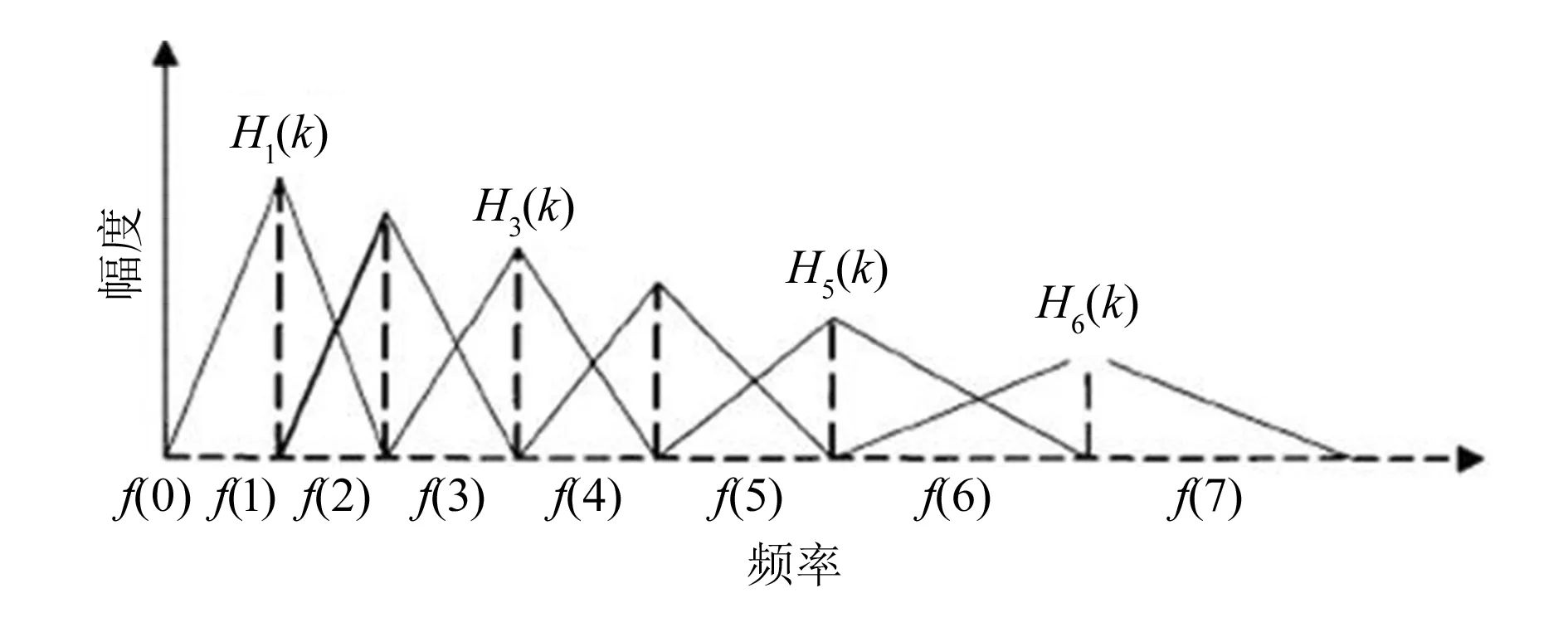
图3 梅尔滤波器组示意图
滤波器频率响应为:
(7)
式中:Hm(k)为通过梅尔滤波器后的响应结果,k为第m个三角滤波器的谱线索引号,f(m)为各个三角滤波器的中心频率。
计算每个滤波器组输出的能量:
(8)
式中:H(m)为每个滤波器输出的能量值,M为滤波器总数。
为了去除各维信号之间的相关性,对能量的对数做离散余弦变换,得到MFCC参数,其中i为数据的帧号,l为第i帧的第l列:
(9)
式中:cmfcc(i)为MFCC参数。
标准的倒谱参数只反映了语音参数的静态特性,语音的动态特性可以用静态特征的差分参数来描述:
(10)
式中:dt为第t个一阶差分,cmfcc(i+l)、cmfcc(i-l) 为当前语音帧的相邻前后帧MFCC参数。
将一阶差分的结果再代入式(10)中就可以得到二阶差分的参数。最后将帧能量也加入到MFCC特征中,即MFCC特征是由MFCC参数、一阶差分参数、二阶差分参数和帧能量组成的。
3 训练GMM-HMM模型
3.1 GMM-HMM简介
若系统在时间t的状态只与其在时间(t-1)的状态相关,那么可以将系统构建成一个离散的一阶马尔科夫链(Markov chain)。若只考虑独立于时间t的随机过程:
P(qt=si|qt-1=sj)=aiji,j∈[1,N]
(11)
则该过程为马尔科夫模型。式中qt为系统在时间t的状态;s为系统所有状态分类中的某个状态;P(qt)为系统相对于时间t处于某个状态的概率;aij为转移概率。在马尔科夫模型中,每个状态代表了一个可观察的事件。在实际应用中,如果模型所经过的状态序列是未知的,只知道状态的概率函数,那么该模型是一个双重的随机过程。其中模型的转换状态是隐蔽的,可观察事件的随机过程是隐蔽状态转换过程的随机函数[5]。
混合高斯随机变量的分布非常适合描述语音序列的MFCC特征,用GMM建模声学特征O1,O2,…,On,每一个特征是由一个音素确定的,不同特征可以按状态进行聚类。假设声学特征的概率P(O|sI)服从正态分布,则O1,O2,…,On就是一个混合高斯模型的下采样值。
由于在HMM中音素被表示为隐状态,即每一个特征是由某几个状态确定的,不同音素特征可以按状态来聚类,因此将GMM整合进HMM中来拟合基于状态的输出分布。
3.2 数据准备
首先将语音样本集中的每个语音样本组随机抽出10%的样本数量作为测试集,然后对训练集和测试集中语音样本的MFCC特征和样本序号进行分类标号。
3.3 模型训练
本文使用hmmlearn框架中的GMMHMM类建立孤立词识别模型。步骤如下:建立模型组列表;对每一个语音指令建立模型;设置每个音节的状态数目为3,每个音节的特征由3个混合高斯成分的GMM表示,每一个状态由一个对角协方差矩阵表示,最大迭代次数为10次,每次通过迭代学习更新状态转移概率、每个高斯成分的均值、每个高斯成分协方差以及每个高斯成分的权重。
模型组建立完成后使用GMMHMM.fit()函数对训练集样本的特征进行训练,流程如下:
1)对语音信号的每个音素分别使用HMM-GMM进行三状态建模,其中HMM的发射概率使用高斯分布函数建模。
2)初始化对齐。将语音信号的帧平均对应到每个状态。
3)更新模型参数。将统计获得的每个状态的转移次数,除以总转移次数,获得每个状态的转移概率。
4)使用维特比算法,根据上一步得到的转移概率和条件概率,重新对语音信号进行状态级别的对齐。
5)重复步骤3)和4),直至收敛。
6)保存训练完成的模型。
3.4 模型测试
首先使用语音样本组中随机抽出的测试集对训练完成的模型进行测试。将测试集语音样本的MFCC特征放入模型组中,使用score()函数获取该语音特征在每个语音模型上的得分。然后选取最高得分的模型与测试语音的标签进行比对,并统计正确率。
4 关联语音指令与PLC寄存器数据
4.1 西门子PLC通信协议及数据简介
S7协议是西门子PLC通信的核心协议,它是一种位于传输层上的通信协议[6],传输层为ISO-On-TCP协议,依赖于网络层的IP协议,其物理层/数据链路层可以是MPI总线、PROFIBUS总线或者工业以太网。
PLC的数据存储通过“变量”的形式与存储区间关联,分为输入(I)、输出(O)、位存储(M)和数据块(DB)[7]。程序在访问对应的存储区时,是通过访问CPU的过程映像对相应地址进行操作的。
4.2 snap7简介
snap7 是一个基于以太网与S7系列的西门子PLC通讯的开源库,封装了S7通信的底层协议,可使用普通电脑通过编程与西门子S7系列PLC进行通信。支持S7系列的S7-200、S7-200 Smart、S7-300、S7-400、S7-1200以及S7-1500的以太网通信。
4.3 snap7与PLC的连接
PLC作为服务器端,基于TCP协议,PC端使用snap7作为客户端进行网络连接。PC与PLC需要处于同一网段,并且需要将连接的端口设置为2号端口,以避免与PLC连接的其他设备冲突。
4.4 area与PLC数据寄存器数据的映射关系
PLC所执行命令操作的原理是修改对应寄存器地址中的数据。选择snap7库中的Client模式,Client模式里提供了读写PLC存储区的函数:client.read_area(area, dbnumber, start, size)和client.write_area(area, dbnumber, start, size)。area为snap7的地址;dbnumber为数据块地址编号;start为读写字节的起始地址;size为读写的数据类型所占字节长度。其中参数area地址类型(十六进制类型)与PLC存储区的映射关系如表1所示。

表1 参数area与PLC存储区映射关系
通过使用snap7库中的函数client.read_area()和client.write_area()可对PLC的输入输出寄存器数据中的数据进行读取和写入。对于V和M存储区,则需要使用函数client.db_read()和client.db_write()对V和M存储区变量进行读写操作,其参数与使用方法同读写输入输出寄存器。
4.5 建立语音标签与PLC存储区数据的连接
语音标签首先匹配snap7的函数,再通过函数对PLC存储区的数据进行读写,从而建立起语音模型到PLC数据的连接。
第3节训练完成的语音模型由若干条语音指令组成,首先建立语音指令标签,标签数量需等于语音指令数目,将标签号与语音指令一一对应;然后通过语音指令的内容,将语音指令的标签按照读、写功能进行第一次分类,再按照需要修改的PLC存储区位置进行第二次分类,经过两次分类可以确定语音指令标签所调用的snap7函数;最后根据PLC存储区变量的地址确定snap7函数的参数值。
5 语音指令控制PLC
5.1 语音指令采集、预处理、特征提取
为了保证语音指令能与语音样本模型达到良好的匹配度,语音指令的采集及预处理使用和语音样本一样的设置及处理流程,即以16 kHz采样帧率、2.5 s时长采集单个语音指令,使用谱减法去除噪声,采用端点检测去除音频两端的空白部分,最后计算出MFCC特征。
5.2 模型匹配
创建语音指令特征在模型组中每个语音模型的匹配分数列表;加载训练完成的模型组,使用score()函数获取实时语音特征在每个语音模型上的得分,并存入预测分数列表;筛选出分数最高的模型,得到该模型对应的语音标签。
5.3 控制PLC
PC端作为客户端与PLC建立连接,判断语音标签所对应的函数、对应PLC寄存器的地址和参数;根据第4节建立的语音标签与PLC存储区的连接,调用对应的函数对PLC寄存器数据进行修改,实现对PLC的控制。
6 试验结果与分析
6.1 试验准备
本文设计了7个语音指令,分别为“CPU RUN”“Q0.0输出”“Q0.0复位”“绿灯打开”“绿灯关闭”“红灯闪烁5次”“急停”;每个语音指令进行30次录音,以语音样本加序号进行命名并保存;每个语音样本随机抽出3条语音指令作为测试集,其余的组成训练集;对所有的原始语音样本进行预处理并计算MFCC特征。
本文试验用PLC使用西门子S7-smart系列的ST40 CPU模块。CPU模块的运行指示灯对应语音指令“CPU RUN”,输出DQa组第1个输出点对应“Q0.0”,输出DQa组第2个输出点对应“绿灯”状态,输出DQa组第3个输出点对应“红灯”状态,“急停”时DQ输出组全部复位。
对采集到的语音指令的MFCC特征建模进行迭代训练,并对训练完成的模型进行保存。部分语音模型训练迭代收敛情况如图4所示。
语音指令为“Q0.0输出”时,CPU模块DQa状态如图5所示。

图5 CPU模块DQa状态图
6.2 试验结果
试验时按照随机顺序说出语音指令,每个指令试验15次,观察PLC执行的动作并记录。表2为试验结果统计。
6.3 结果分析
实时语音指令控制PLC的试验,进行了总计105次测试,总体成功率达到92.4%。可见本文提出的方法可以满足一些精确度要求不高的PLC控制要求。
分析试验结果可知,语音指令发音相近的情况下容易出现识别错误,主要原因可能是因为起到区分性作用的特征在序列上整体位置比较靠后,在模型训练中计算概率是由状态转移概率乘以观测值的概率,所以在序列后端计算出的概率就非常小,导致区分性不强。在后续的改进中考虑在计算概率时加入正则项,以防止出现序列后端概率数值过低的问题。另外,考虑增加冗余的语音指令模型组,共同对输入的语音指令进行识别,以增强语音识别的容错性。
7 结束语
针对传统工业领域控制方式引发的问题,本文基于GMM-HMM语音模型,提出了一种通过语音指令控制PLC的方法。该方法通过采集语音指令样本,对模型加以训练,建立语音指令和PLC寄存器之间的映射,将按钮、按键等工业控制手段替换成对操作人员更为友好的语音指令,完成对工业设备的控制。相较于传统的控制方式,降低了操作的复杂程度,为工业控制模式增加了新的方式和思路。
