购买银行金融类产品的企业画像研究
——基于文本分析法
2023-08-19张家普胡佳敏毕以霖李贵鑫
张家普 胡佳敏 毕以霖 李贵鑫
(北京外国语大学国际商学院 北京 100089)
随着社会经济的发展,企业财富积累在迅速增长。Wind数据显示,截至2022年11月,中国非金融企业存款已达74.6万亿元,近10年平均增长率达8.5%。然而,面临通货膨胀的巨大压力,银行存款利率低于CPI指数及股票市场的高风险,使企业在缺乏合适投资渠道的情况下,必须要确保自身资产保值增值,因此收益好、风险可控的理财产品越来越受到企业的青睐。与此同时,商业银行加强对企业财富管理需求的关注,短期公司理财产品、公募基金、私募资管计划等各类理财产品如雨后春笋般在各银行推出,为企业提供了很多选择。企业购买银行的理财产品,于企业而言,可以兼顾收益性和流动性,提高资产配置能力和使用效率;于银行而言,不仅可以帮助其从中获取利润,也是商业银行在存款业务之外募集资金、获取客户的重要方式。因此,银行对企业客户财富管理需求的深入把握,从而为企业制定精准营销策略及差异化服务,将成为银行提高机构理财产品销售份额、抢占市场先机的关键,而企业客户画像的分析,是实现客户隐性特征显性化,帮助深入探究客户需求的有效技术手段。企业画像模式的提出不仅有利于快速识别出哪些企业有财富管理的需求,帮助其根据产品特点找到目标客户,提高对公服务效率,还有利于银行在客户偏好的渠道上与其进行沟通,实现精准营销,提升企业客户在理财需求方面的体验。
值得注意的是,目前有关用户画像的研究多以个人用户为主,对企业画像——尤其是金融营销需求的企业画像研究相对较少。因此,本文以中国某股份制P银行为例,获取2022年7月购买了该商业银行某个理财产品的企业客户名称,通过Python在企查查官网上爬取企业基本信息后,基于图表的描述性分析、词频统计、文本向量化和K均值聚类等方法对该银行的企业客户画像进行分析,以期为银行对该理财产品的营销提供启示。
1 文献综述
近年来,用户画像的刻画已经从自然人逐渐过渡到各类实体,在此过程中,企业画像也得到了学术界和产业界的关注。由于企业画像的研究经常涉及文本语言等非结构化数据,如提取年报中的标签信息、分析企业所属行业或经营范围、对企业评价分析等,因此越来越多的学者在企业画像的研究框架中运用了文本分析或自然语言处理等技术。如田娟等(2018)提出构建基于大数据平台的企业画像标签体系模型和建设框架时,对四种企业特征提取方法——Kmeans、LDA、NB、CNN——各自的优缺点进行比较分析。黄晓斌和张明鑫(2020)通过K均值聚类、层次聚类、密度聚类等方法分析企业竞争对手的特征向量,提出一套融合多源数据的企业竞争对手画像构建模式。曹丽娜等(2022)采用TensorFlow深度学习框架,从质量创新能力、过程质量控制、产品质量水平等维度对中小微企业综合质量画像体系进行构建。
实践应用方面,《中国税务报》2016年就曾报道,大连税务局等政府部门利用企业经营、诚信、风险和贡献等大数据信息构建出口企业画像(王磊,2016)。近年来,Chung等(2021)运用社会网络分析和文本挖掘等方法进行合作伙伴识别分析,蔡盈芳等(2021)将用户画像技术引入涉企政务档案信息管理中,通过采集企业用户基本信息、参与政务服务事项、产生或需要的档案信息、利用政务档案信息的特征及偏好等,充分了解企业用户产生和利用政务档案信息的具体情况;而宋凯和冉从敬(2022)则将企业画像应用到高校专利推荐过程,依托文本聚类、主题模型、文本相似度计算等技术,构建“专利匹配度”指标,实现向企业进行高校专利的个性化推荐。当前,已有如腾讯云、京东数科、中科聚信等大数据企业面向社会提供企业画像服务,用于支持相关机构进行企业安全风险评估与监管(黄家娥等,2022)。
纵观现有文献,针对企业客户画像的技术研究,在理论框架分析上已日臻成熟,并且已经在税务、专利推荐、档案管理、风险评估等方面得到了应用,然而这一技术在金融行业的应用研究相对较少。在“互联网+”的背景下,金融企业必须加快数字化转型,运用现有的企业画像技术分析方法实现更好的精准化营销和决策。因此,本文利用词频统计、TFIDF、无监督学习等方法,对银行的企业客户画像进行研究,为银行针对企业客户进行理财产品的营销提供指导意义。
2 实证分析
2.1 数据获取和预处理
本文获取某P银行2022年7月购买该银行某理财产品的企业客户相关数据集,内容包括企业名称及企业购买理财产品时所在的一级分行。该数据集包含216家企业、24家一级分行。基于企业客户名称的信息,本文利用Python,从公开的企业信用信息查询平台“企查查”上爬取企业的基本信息,包括登记状态、成立日期、注册资本(万元)、纳税人资质、所属行业、企业类型、人员规模、企业地址、行业标签、经营范围等10个字段。
对于爬取结果,做如下预处理。首先,通过观察发现,变量“登记状态”的内容均为“存续(在营、开业、在册)”;变量“纳税人资质”的内容为“一般纳税人”或“增值税一般纳税人”,两者没有显著差别;变量“企业地址”涉及的地域信息与企业所在的“一级分行”信息基本一致。以上三个变量对企业区分度不大,因此对“登记状态”“纳税人资质”“企业地址”三个变量进行剔除;其次,将“成立日期”转换为企业到目前为止的“成立年份”,利于统计分析。进行处理后,每个企业共有8个字段信息可供分析(见表1),其中“行业标签”变量是对“所属行业”的进一步补充;企业所在的“一级分行”“成立年份”“注册资本”“所属行业”,“企业类型”“人员规模”6个变量属于数值型或类别型变量,对其做描述性统计分析,针对“行业标签”“经营范围”2个文本型变量,运用NLP的词频统计、文本向量化处理、K均值聚类等方法进行分析。

表1 企业基本信息数据集
2.2 变量描述性分析
首先,通过统计各个分行的企业数量观察企业的地域分布,结果显示企业数量超过10家的分行主要为北京、南京、宁波、广州等一线或新一线城市分行,其中北京分行的企业客户数量最多,企业数量有97家,占比接近45%,以绝对优势领先于第二、三名分行;其次,从成立年份看,216家企业中成立最久的企业为42年,成立时间不足5年的企业有53家,超过5年但不足10年的企业有51家,两者合计占比接近50%,可见多数企业成立时间不长。从注册资本来看,共有210家企业公布了注册资本,其中注册资本规模最小为6万元,最大为1130000万元,近25%的企业注册资本不到500万,资本规模较小,多数企业(约68%)的注册资本规模在5000万元以下。从人员规模来看,157家企业公布了人员规模,其中人员规模少于50人的企业数量最多,有95家,占比超过60%,可见绝大多数企业为中小规模。所有企业按照企查查提供的企业类型大致可分为9类,其中企业类型为有限责任公司的数量最多,为191家,占比超过88%。此外,在所有企业中,上市企业仅有1家,国有独资企业仅有1家,进一步反映出购买理财产品的多为中小企业;最后,215家企业公布了所属行业,按照企查查提供的企业类型共分为46类,可见购买理财产品的企业行业分布之广泛。然而,从各行业的企业数量来看,仅有8个行业的企业数量超过5家(见表2),其中科技推广和应用服务业、商务服务业和批发业的企业数量最多,合计占比超过50%,而餐饮畜牧业、加工制造等行业的企业数量则屈指可数,说明购买理财产品的企业多分布在高新技术产业、高端服务业等第三产业。
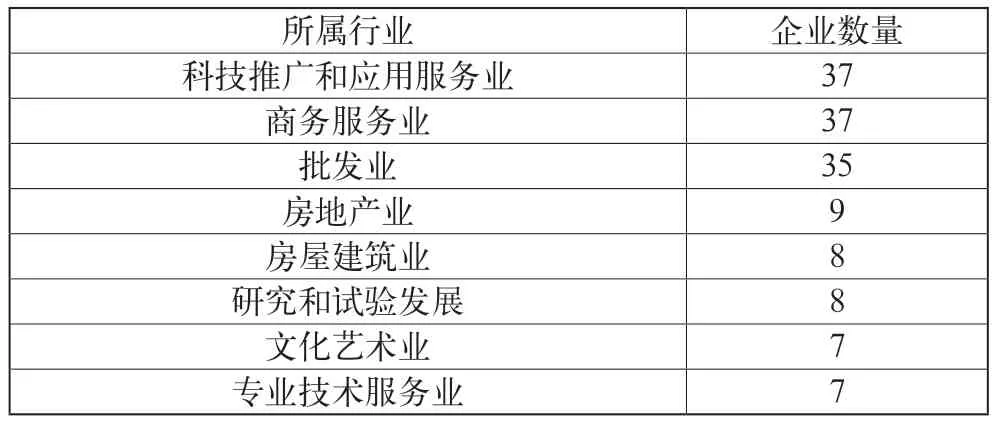
表2 企业所属行业分布
2.3 词频统计
“行业标签”“经营范围”这2个文本型变量无法做分类统计,对此本文对这两个变量做词频统计分析并绘制词云图,以挖掘出文本中的高频词语特征。其中,由于前文分析的“所属行业”只是对企业所在的一级大类行业进行划分,划分颗粒度不够精细,因此通过爬取的“行业标签”可对此做进一步补充。
本文在进行词频统计前,还需要进行文本预处理。变量“行业标签”的词语已经成形,按照符号“#”进行切割即可。变量“经营范围”属于长文本,本文使用python的jieba分词模块对其进行全模式分词,分词之后导入中文停用词表,去除文本中常见的停用词。由于采用的是全模式切词,切出字符长度小于2的词语体现的语义不够明显,因此统计出“经营范围”词语长度大于2的词频。之后,运用wordcloud模块分别绘制“行业标签”和“经营范围”的词云图。
图1基于词频统计做出的词云图。数据显示,出现频次排名前三的为“科学研究和技术服务业”“批发和零售业”“制造业”,此外,“租赁和商务服务业”“商务服务业”“科技推广和应用服务业”等服务业词语出现频次也较高。

图1 企业行业标签词云图
图2 是词频统计制作的词云图。数据显示,出现频次排名靠前的词语除了“进出口”外,“计算机”“机械设备”“电子产品”“化工产品”等和工业相关的词语出现的频率较高,与“技术开发”“技术咨询”“技术转让”等高新技术服务业相关的词频排名也很靠前。

图2 企业经营范围词云图
2.4 文本向量化和K均值聚类
对“行业标签”和“经营范围”的高频词分析只能对企业客户所在的行业得到初步了解,但无法确定企业所在的行业主要有哪些,因此本文运用无监督学习——K均值聚类法分别对“行业标签”和“经营范围”进行聚类分析,以找出购买理财产品的企业的主要行业。
由于K均值模型的输入必须是数值型向量类型,需把每条由词语组成的句子转换成一个数值型向量,所以本文使用TF-IDF算法对文档进行向量化。TF-IDF(李春梅,2015)在信息检索、文本挖掘等场景中是常用的加权技术,用以评估一字词对于一个文件集或一份文件对于一个语料库的重要程度。字词重要性与其在文件中出现的次数成正比增加,但同时会随着其在语料库中出现的频率成反比下降。本文使用Sklearn模块的TF-IDF算法把所有文本数据转换为词频矩阵,作为K均值模型的输入,并将TF-IDF的最大特征值设为20000。
K均值聚类是一种自上而下(top-down)的聚类方法,须预先确定样本中的聚类数目,即K的具体取值,比如根据经验或试错。在对“行业标签”进行K-means聚类时,分别测试当K等于3、4、5类的结果,对比发现,当K=4时,“行业标签”的聚类结果区分更为清晰,因此将K设定为4,结果如图3和表3所示。
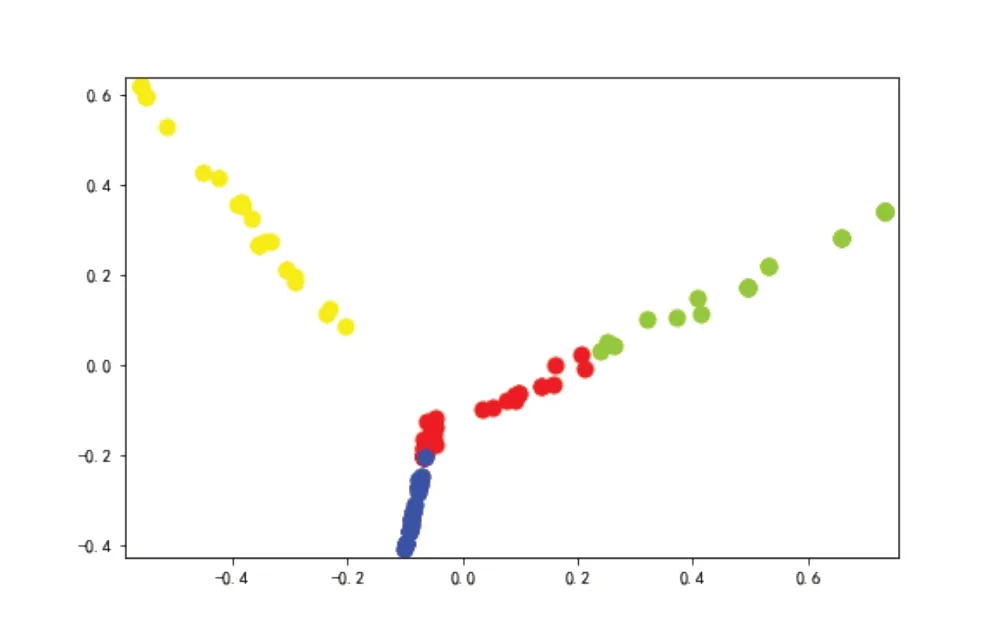
图3 企业行业标签聚类结果图

表3 企业行业标签聚类分析结果
从表3可以看出,P银行购买理财产品的企业主要集中于以下四类行业:第一类以文体娱行业为主;第二类主要为批发和零售业;第三类主要为科学研究和技术服务业;第四类主要为现代商务服务业,包括组织管理服务、投资管理服务等。
企业“经营范围”的K-means聚类结果如图4所示。由于多数企业的“经营范围”登记内容较多,因此从图4可以看出,对“经营范围”的聚类划分并没有“行业标签”那么明确,但结论与基于“行业标签”聚类分析的结果一致,即企业经营范围同样集中在“文体娱乐”“批发零售”“科学研究和技术服务”“租赁和商贸服务”这四类行业。受篇幅限制,聚类划分结果不再展示。
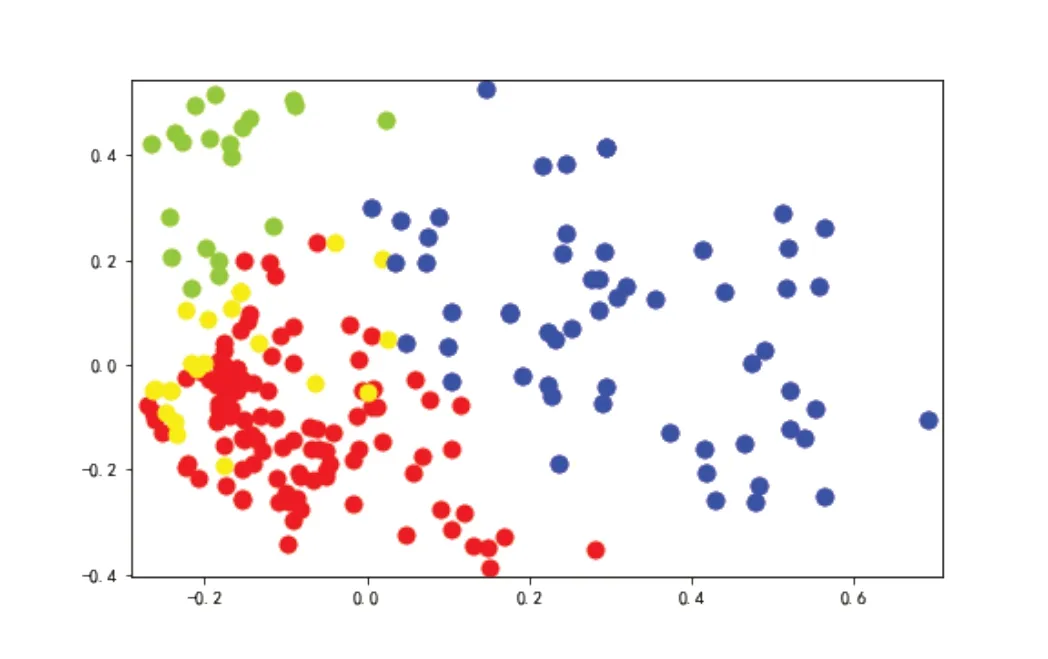
图4 企业经营范围聚类结果图
2.5 企业画像总结
本文基于以上对216家企业基本信息的描述性分析、词频统计分析、K均值聚类分析等,可以初步总结出P银行2022年7月购买其理财产品的企业客户画像:企业主要集中于一线或新一线城市,以北京居多;大多数企业成立时间为10年左右或不足10年,注册资本规模多在5000万以下,人员规模多数少于50人,企业类型以有限责任公司居多,多数为非上市、非国有的独资中小企业;所属行业主要集中于文体娱乐业、批发和零售业、科学研究和技术服务业、现代商务服务业等第三产业,经营范围既包括与“计算机”“机械设备”“电子产品”“化工产品”等工业相关的内容,也有与“技术开发”“技术咨询”“技术转让”等高新技术服务业相关的内容。
3 结语
本文以某股份制P银行为例,获取2022年7月购买了该商业银行某个理财产品的企业客户名称,通过Python在企查查官网上爬取企业的基本信息后,基于描述性分析、文本分析和K均值聚类等方法对该银行的企业客户画像进行分析,总结发现:购买该理财产品的企业主要集中于一线或新一线城市,以北京居多;大多数企业成立时间为10年左右或不足10年,注册资本规模多数在5000万以下,人员规模多数少于50人,企业类型以有限责任公司居多,多数为非上市、非国有独资的中小企业;所属行业主要集中于文体娱乐业、批发和零售业、科学研究和技术服务业、现代商务服务业等第三产业,经营范围既包括与“计算机”“机械设备”“电子产品”“化工产品”等工业相关的内容,也有与“技术开发”“技术咨询”“技术转让”等高新技术服务业相关的内容。银行在进行产品营销时,可通过以上总结的企业特征,寻找或挖掘出企业客户潜在的理财需求。
本文涉及的企业基本为未上市的中小企业,多数企业甚至没有官方网站,因此只能在“企查查”等公开的信息登记网站上爬取企业的基本信息。如果能从银行获得更多维企业相关的数据,如企业在该银行登记的财务数据、该企业历史存贷款数据、企业历史购买理财产品的数据、企业理财需求的偏好数据等,对企业画像的研究也将更加全面丰富,从而帮助银行更快、更高效地判断出哪些企业有购买该理财产品的可能性。
