股票价格波动与分类算法改进
2023-08-15吕双爻宋雨芬
吕双爻 宋雨芬

摘 要:当前,金融业发展日趋全球化、多元化,金融业内部业务相互渗透、交叉,国际资本之间相互合作与竞争,我国的券商发展环境正发生巨大变化。东方财富以互联网金融数据服务为基础,整合券商、基金、期货等资本市场业务,颠覆传统证券服务业,现已成为中国最大市值证券机构。基于此,本文以2021年12月20日至2022年12月20日东方财富整年的股票数据为例,基于排序法计算VaR,并基于定义每日违约情况,运用Logit、SVM、NNET、Decision Tree、KNN等非机器学习和机器学习五种方法对东方财富股价进行分析,探究各变量对违约率的影响。
关键词:VaR;排序法;分类算法;风险评估;股价预测
本文索引:吕双爻,宋雨芬.<变量 2>[J].中國商论,2023(14):-112.
中图分类号:F832 文献标识码:A 文章编号:2096-0298(2023)07(b)--04
1 引言
我国证券市场已成为国民经济的重要组成部分,在我国经济的发展中发挥着越来越重要的作用。当前,股票市场投资证券已成为热门话题。股票市场在带来高回报的同时,也存在高风险。股票市场规模的扩大,交易种类的增加以及投资者偏好的变化使股票市场最终成为一个非线性、非平稳性和其他属性混合的复杂动态系统。
在此背景下,如何正确预测股价走势成为学者们的重要研究方向。从最初的ARMA、多元GARCH等时间序列方法,到人工神经网络、BP神经网络、机器学习等神经网络模型,都起到了良好的预测效果。但是,很多时候并不需要预测一只股票未来的具体涨跌幅,而是希望预测股票未来是涨还是跌,这意味着本文需要处理的是一个分类问题而不是回归问题,因此研究股票价格的分类方法具有重要的现实意义。
同时,在众多风险度量模型中,VaR因其测量风险的定量性、综合性、通俗性等特点在各金融机构中获得了广泛应用和推广,并且被认为是国际金融风险度量的标准。
因此,本文以2021年12月20日至2022年12月20日一年期的东方财富股票数据为样本,引入多种常用的分类器——Logit分类、K最近邻(K-nearest neighbor,KNN)、决策树(decision tree,DT)和支持向量机(support vector machine SVM)、神经网络(Neural network)来预测其极端风险出现的概率,以更有效地针对东方财富进行数据挖掘,并为后续股票个股研究提供参考。
2 文献回顾
2.1 国外研究现状
G.Peter等(2003)和Wijaya等(2010)的研究分别比较了ARIMA模型和人工神经网络ANN模型在进行股票预测时两者的性能,通过实验发现人工神经网络ANN模型的预测精度更好。
Chien-Feng Huang(2012)提出了一个结合遗传算法(GA)和SVR的组合模型用于股票收益预测。该模型首先使用GA算法对输入变量进行特征选择,然后优化SVR算法的惩罚参数和核函数参数,再将特征选择的变量和最优参数输入SVR模型进行股票收益预测。
Chi-Jie Lu(2013)提出了一种基于非线性独立分量分析(NLICA)和支持向量机以及粒子群优化(PSO)算法的混合模型,该模型是NLICA和PSO的混合体。该模型使用NLICA对SVR模型的输入变量进行特征选择,并使用粒子群算法对SVR的参数进行优化,以获得良好的股票预测结果。
2.2 国内研究现状
彭丽芳、孟至青等(2006)利用沙河股份的数据,使用神经网络方法、时间序列方法以及基于时间序列的SVM模型进行股票价格预测,实验结果表明SVM模型在股票时序预测问题上的精度表现最好。
智晶和张冬梅(2009)利用GA算法对神经网络参数进行了优化。股票价格预测的实证表明,优化后的神经网络在一定程度上克服了容易陷入局部最小值的问题,提高了预测的精准度。
韩磊(2013)提出基于PCA和BP神经网络的股价预测方法。该方法采用PCA对输入数据进行降维操作,然后将降维后的数据带入BP神经网络进行训练。实证结果显示,相比传统的BP神经网络,该方法可以达到较高的预测精度。
杨可可(2020)选取恒生电子单支股票作为研究对象,借助Eviews和Excel软件,将方差—协方差法和建立的GARCH模型结合来测算VaR值并分析其风险状况。
3 数据来源及方法介绍
3.1 数据来源
本文利用Tushare包获取东方财富从2021年12月20日至2022年12月20日一整年的股票开盘价格、收盘价格、最高价、最低价、交易量等数据。
3.2 方法介绍
3.2.1 VaR基本理论概述
VaR是在一定置信水平和一定持有期内,某一金融资产或组合在正常的市场条件下所面临的最大损失额,从根本上说是对投资组合价值波动的统计测。VaR能将一系列复杂的风险测度问题量化为一个具体数值,不仅让投资者知道发生损失的大小,还让投资者了解发生损失的可能性;这说明金融资产受整个市场风险的影响,更能反映市场价格的波动规律。
目前,计算VaR值的主要方法有三种:历史模拟法、蒙特卡洛模拟法、方差—协方差法。本文采用历史模拟法,此方法是将历史在未来可以重现作为假设前提,利用历史数据的分布函数来代表将来一段时间的收益率分布。
3.2.2 各模型基本概述
不同的分类算法有不同的应用场景,在一个数据集上效果较好的模型在另一个数据集上却不一定适用,因此对于不同的数据集,更需要具体问题具体分析。
(1)Logit回归分析
Logit回归分析是一种广义的线性回归分析模型,属于机器学习中的监督学习。通过给定的n组数据(训练集)来训练模型,并在训练结束后对给定的一组或多组数据(测试集)进行分类。其中每一组数据都是由p个指标构成。
经典的Logit回归的形式:
(2)K最近邻判别分析法(KNN)
K最近邻判别分析法是一种被普遍应用于各个领域非参数统计方法。KNN可以解决分类或回归问题。其基本思想是计算待分类样本与训练样本之间的距离,选择与待分类样本最接近的K个训练样本,并确定这K个样本中数量最多的一个类别作为待分类样本的类别。
(3)支持向量机(SVM)
作为前馈网络的一种,在解决非线性的分类问题方面具有明显的优势。它可以通过构建超越二维平面以上的多维度决策曲面来实现两类样本数据的精确分离,即最大程度地提高两类数据点之间的分离边缘。
(4)人工神经网络 (NNET)
人工神经网络是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)行为特征,进行分布式并行信息处理的数学模型或计算模型。
(5)决策树(Decision Tree)
决策树方法主要包括两个步骤:构建和修剪。该方法构建的关键是确定每个内部节点的分裂属性和相应的测试内容;修剪的重点是识别和消除数据集中的噪声或异常数据产生的分支。
3.3 模型效果评价指标
3.3.1 ROC曲线
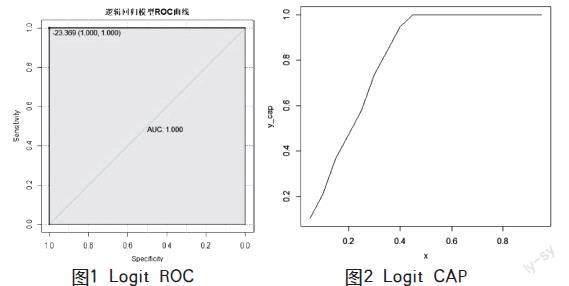
ROC是分类器取不同阈值得到的虚报率或召回率的曲线,经常被用来评价一个二值分类器的优劣。ROC曲线的横坐标是虚报率,纵坐标为召回率,通常召回率越高越好,而虚报率越低越好。因此,当一个分类器的点位于第一象限的左上方时分类器效果较好。
3.3.2 CAP曲线
CAP曲线衡量的是风控模型检出风险的能力。CAP的横轴就是从排序后概率值头部到尾部的移动过程中,阈值以上的(预测为正的)样本占总样本的比例。CAP的縱轴表示的是,在当前阈值下,拣选出来的这些预测为正的样本中,其中含有的真实的正样本占所有正样本的比例。
3.3.3 AP与NP指标
AP即平均精度,是目标模型效果检测与评价中的一个常用指标。AP指标的定义为把阈值设置在紧靠每个正例之下,计算正例的查准率P+,再取平均值。NP则为正例的总数。
4 实证研究分析
4.1 股票指标选择
股票指标是衡量股票价值的重要因素。从功能角度而言,技术指标总体可以分为摆动类指标、趋势类指标、能量类指标3大类。常用的技术指标KDJ、RSI就属于摆动类指标;MACD、MA指标属于趋向类指标;OBV、VOL属于能量类指标。
结合技术指标分类,本文选取交易量、振幅、收益率、MACD、OBV、CCI共6个指标来分析数据具体情况。
4.2 排序法计算VaR
为使用Logit、SVM等方法对东方财富的数据进行分析,首先要使用排序法计算VaR,再分别进行训练和测试。
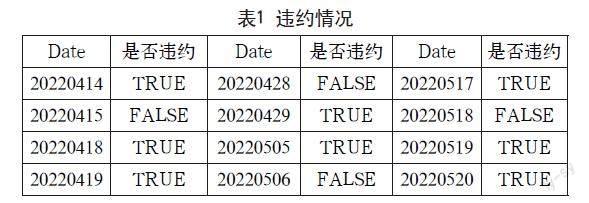
首先计算东方财富的收益率,再根据收益率进行均值和标准差的计算,从而进一步计算VaR的阈值,阈值为0.02257089,再对比次日涨跌幅与VaR值的大小,当涨跌幅大于阈值时则判为违约,标注为TRUE,当涨跌幅小于阈值时则判为不违约,标注为FALSE,具体情况见表1。
4.3 训练与测试
4.3.1 Logit模型
首先,随机划分训练集和测试集,其中训练集包含180天的数据,测试集包含64天的数据。其次,本文第一个使用Logit模型建立模型,以是否违约为被解释变量,以交易量、振幅和收益率、 MACD、OBV、 CCI为解释变量,进行训练集建模,得到结果如下:
是否违约=-6.813e-1.494e-6交易量+5.788e2振幅-8.093e2收益率-3.624MACD-9.966e-7OBV-9.25e-4CCI
本文对测试集进行测试得到ROC=1,说明Logit的训练模型非常好,并计算NP得到19,同样反映出模型效果较好。计算AP值为0.4763158。
4.3.2 SVM模型
第二个使用SVM模型建立模型,以是否违约为被解释变量,以交易量、振幅和收益率、 MACD、OBV、 CCI为解释变量,进行训练集建模,对测试集进行测试得到ROC=0.883,得到的效果没有Logit解释完全。
4.3.3 NNET模型
第三个使用NNET模型建立模型,以是否违约为被解释变量,以交易量、振幅和收益率、 MACD、OBV、 CCI为解释变量,进行训练集建模,对测试集进行测试得到ROC=0.644,得到效果在选取的模型中解释最差。
4.3.4 Decision Tree模型
第四个使用Decision Tree模型建立模型,以是否违约为被解释变量,以交易量、振幅和收益率、 MACD、OBV、 CCI为解释变量,进行训练集建模,对测试集进行测试得到ROC=1,得到的效果与Logit模型相同,并计算出NP为1。
4.3.5 KNN模型
第五个使用KNN模型建立模型,以是否违约为被解释变量,以交易量、振幅和收益率、 MACD、OBV、 CCI为解释变量,进行训练集建模,对测试集进行测试得到ROC=0,效果并不理想,NP为Inf。
5 结果分析
本文得到的结果基于东方财富2022年的一系列数据。首先,采用排序法计算其一年期75%置信度的日度VaR,并当日跌幅超过VaR预测的阈值时,则判定当天为‘违约。其次,将数据随机划分为180个样本的训练集和64个样本的测试集,以交易量、振幅、收益率、MACD、OBV、CCI为解释变量,以是否违约为被解释变量,使用Logit、SVM、NNET、Decision Tree、KNN等模型,并得到ROC,对比ROC值,可以看到Decision Tree与Logit的训练效果最好,SVM次之,NNET和KNN最差。同时,观察Logit结果可以发现,收益率对是否违约的影响最大,振幅、MACD对是否违约的影响其次,交易量、OBV、CCI对是否违约的影响相对较小:
是否违约=-6.813e-1.494e-6交易量+5.788e2振幅-8.093e2收益率-3.624MACD-9.966e-7OBV-9.25e-4CCI
6 改进意见
6.1 解释变量的优化
由上述Logit初次结果,交易量、OBV、CCI的系数都非常小,甚至小于0.0001,因此可以考虑删除这三个解释变量,再次建立Logit模型,可得如下结果:
是否违约=-5.735e+3.311e3振幅-4.895e4收益率-6.825e-1 MACD (1)
改进后的Logit结果如(1)所示,可以看出,收益率对公司股价是否违约具有非常大的负向影响;振幅对公司股价是否违约具有很大的正向影响,股价波动越大,公司股票越有可能违约;MACD同样对公司股票是否违约具有负向影响,这说明应当保证MACD处于较高水平,从而使公司股票处于平稳状态。
除此之外,可以增加其他相关的解释变量进行回归优化。通常股票未来价格涨跌走势不仅仅受到本文所选的6个指标的影响,且股票各特征存在较高相关性,因此采用多因子模型是一种更为优异的方法。常用的因子挑选方法包括主成分分析、Lasso回归、岭回归、序列向前法、序列向后法。
6.2 数据集的划分与计算
在分类识别的机器学习领域,通常将整个目标数据集分为两部分,一是用于訓练和学习建立分类器的训练集,二是用于验证训练后的分类器对新加入样本的准确性的测试集。目标数据集的划分是为了使训练集中的样本数量与测试集中的样本数量相比尽可能得多。
本文数据集划分采用的方法是Hold-Out测试,即把原始数据分为两组,一组为训练集,另一组为测试集,先用训练集训练分类器,然后用测试集测试模型效果,最后将分类准确率作为分类器在Hold-Out检验下的性能指标。这种方法只需要将原始数据随机拆分成两部分,可操作性强,简单便捷。但是,这种方法得到的分类准确率水平很大程度上依赖于原始数据分组的随机性,数据结果并不具有较强的说服力。因此在分类模型方面,可以使用K折交叉验证的方法,加大模型的训练度。交叉验证法是将数据样本切割成较小子集的方法,具体步骤为:
(1)将数据集D分为K个包;
(2)每次将其中一个包作为测试集test,剩下k-1个包作为训练集train进行训练;
(3)最后计算k次求得分类率的平均值,作为该模型或者假设函数的真实分类。
同时滚动训练集,以T月月末为例,从第T-n(n=6,12,18,24,36,48,60…)期至第T-1期的特征和标签作为训练样本,将n个月的样本合并成为训练集。
改进后的模型的训练集和测试集的分割更加合理,所训练的模型也更为准确;对VaR的计算方面,可以根据数据的特征来选择不同方法计算VaR,比如使用正态分布计算VaR。另外,在违约阈值的选择上,历史的违约数据可以根据未来的趋势进行适当调整。
参考文献
Chien-Feng Huang. A hybrid stock selection model using genetic algorithms and support vector regression[J]. Applied Soft Computing2012, 2(12): 807-818.
Chi-Jie Lu. Hybridizing nonlinear independent component analysis and support vector regression with particle swarm optimization for stock index forecasting[J]. Neural Computing and Applications, 2013, 7-8(23): 2417-2427.
G.Peter,Zhang.Time series forecasting using a hybird ARIMA and neural network model[J].Neurocomputing,2003(50):159-175.
韩磊. 利用BP神经网络系统对股票市场进行预测与分析的研究[D]. 天津: 天津大学, 2013.
彭丽芳,孟至青,姜华,等.基于时间序列的支持向量机在股票预测中的应用[J].计算机技术与自动化,2006(3):88-91.
杨可可.证券投资个股风险的VaR值测算分析[J].广西质量监督导报,2020(8):198-199.
智晶, 张冬梅, 姜鹏飞. 基于主成分的遗传神经网络股票指数预测研究[J]. 计算机工程与应用, 2009, 26(45): 210-212.
