基于视频阵列处理器的3D-HEVC视差估计算法并行设计与实现
2023-08-10蒋林冯茹
蒋 林 冯 茹
(西安科技大学计算机科学与技术学院 陕西 西安 710121)
0 引 言
由于多视点视频的数据量呈现爆炸式增长,这对3D-HEVC等三维编码技术提出了极高的要求。随着视频编码技术的不断发展,帧间预测技术经历了不断提升与改进的过程。视差估计是3D-HEVC中计算复杂度较高的模块,其编码时间占到整个编码时间的60%。视差估计算法本质就是用于寻找当前编码块或者当前预测块在不同视点上对应图像中的最佳匹配块。也就是按照某种数学准则在左右图像上寻找匹配点或块的过程,就是一个图像匹配的过程。获取的视差矢量就是两个对应点或块之间的位置差异,它代表了左右图像在空域上和时域上的冗余信息。直接根据深度图推导视差矢量(Disparity Vector,DV),提出基于深度图的视差矢量[1](Depth Map based Disparity Vector,DMDV),计算复杂度高,内存占用量大。Chen等[2]提出相邻块视差矢量(Disparity Vector From Neighboring Blocks,NBDV)。NBDV算法的基本思想是利用从另一视点预测得到的、与当前编码块位于同一编码位置的相邻块的时空运动信息,导出当前编码块的视差矢量。为了提高获取视差矢量的计算效率,很多学者对此进行研究,提出多种解决方案。
文献[3]提出基于参考块与当前编码块的空间相关性和时间相关性,来获取当前编码块的视差矢量,并且对基于深度图的视差矢量获取提出改进,从而有效节省编码比特数,提高时效性。文献[2]计算当前编码块的视差矢量,不使用深度图获取,而是在纹理图编码后,利用当前编码块在时域上和空域上的相关性,来预测当前块的视差矢量,来降低编码冗余。文献[4]提出了一种可扩展的大规模并行快速搜索算法,降低运动估计ME和视差估计DE在块匹配过程中的计算成本,相比于现有的全搜索和快速搜索,在计算复杂度方面分别提高245.8倍和8.4倍。文献[5]提出运动和视差矢量早期确定算法,以降低3D-HEVC计算复杂度,采用自适应优化算法来选择有效的视图间视差矢量(DV)候选。文献[6]提出了一种基于单向视差搜索算法的三维高效视频编码(3D-HEVC)视差估计(Disparity Estimation,DE)的硬件设计。该架构被用于处理四个方形预测单元(PU)尺寸,而不是使用所有24种可能的PU尺寸。文献[7]提出搜索所有时域和空域相邻块的DV,所有有用的DV被构成一个候选列表,删除列表中的冗余的DV,求出剩余DV的平均值作为最后的NBDV,提高获取DV的速率。为解决PU无法并行处理问题,文献[8]提出一种并行的处理方案。在此基础上,文献[9]提出一种以编码单元(CU)为基础的编码单元去执行DV的推导,不仅节省相邻块,还使多个PU进行并行处理。
综上所述,针对3D-HEVC视差估计算法计算复杂度高的问题,主要通过三方面来进行优化:一是从搜索算法并行化的角度来优化;二是通过四叉树结构进行快速的模式决策方法来减少编码冗余;三是通过边缘信息加快对编码块的搜索。3D-HEVC测试模型中无论是纹理视频还是深度视频帧间预测算法都是串行执行的,因此,减少视差估计过程中的计算复杂度,始终是提升3D-HEVC编码效率的关键。研究视差估计算法的并行性对于整体编码效率的提升起着至关重要的作用。
1 视差估计算法并行性分析
NBDV通过每一个当前CU的空域时域相邻块的运动矢量或者运动补偿预测(MCP)得到的视差矢量。这种原理与Merge/AMVP很相似,空域和时域相邻块按照所给顺序进行搜索,第一个可用的DV作为最后的NBDV。最初搜索相邻块的顺序是空域DCP块——时域DCP块。
1.1 空域候选列表的建立
如图1所示,当前编码单元有5个相邻块,分别记作A0、A1、B0、B1、B2。搜索视差矢量按照A1、B1、B0、A0、B2的顺序对每一个块进行搜索,如果找到第一个可用的视差矢量(DV),就认作为当前编码单元的NBDV。

图1 空域相邻参考块
1.2 时域候选列表的建立
在时域上进行视差矢量搜索时,由于候选帧数目庞杂,并且空域相邻块DV的准确性不如时域相邻块DV,因此首先搜索时域DCP块,其次是空域DCP块,最后搜索空域DV-MCP,搜索步骤较为烦琐。根据文献[10]提到减少搜索块的方法,从每个候选帧图像搜索18个块变为现在只搜索两个块,即中间的块(T1)和右下角的块(T0),时域块的搜索顺序为T1-T0,如图2所示。
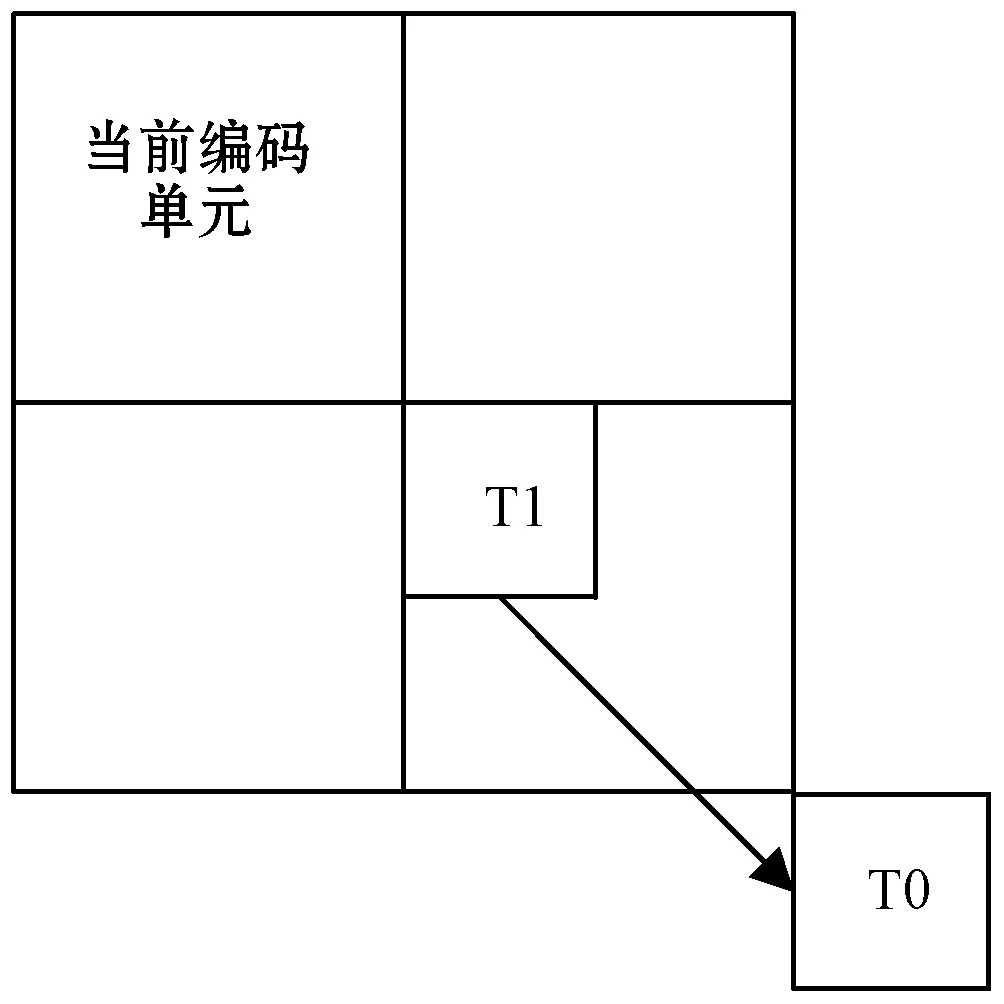
图2 时域相邻参考块
基于相邻块的视差矢量预测算法是将一帧图像分为互不重叠的许多宏块,并且认为一个块内所有的像素点的相对位移是相同的,其目的是为当前视点的一帧图像的每个块查找最佳匹配块,从而在其参考视点的参考帧搜索到最佳匹配块,图3为相邻块视差矢量的块匹配示意图。

图3 视差估计块匹配示意图
通常选择SAD作为匹配准则,若块大小为N×N,第n帧中左上角坐标(x,y)的块与第n-1帧中左上角坐标(x+a,y+b)的块之间的SAD如式(1)所示。
fn-1(x+a+i,y+b+j)|
(1)
式中:fn(x+i,y+j)表示第n帧中坐标为(x+i,y+j)%处的像素值,fn-1(x+a+i,y+b+j)表示第n-1帧中坐标为(x+a+i,y+b+j)处的像素值。(a,b)表示视差矢量DV,即当前块到参考块之间的相对位移。
视差估计中最耗时的模块是块匹配操作,在进行块匹配操作时,在时域上和空域上分别搜索与当前编码块相邻的块,判断其相邻块与当前编码块的SAD值,并选择最小SAD值,将此SAD值及其对应块存储,计算视差矢量。由于搜索的相邻块数目烦琐,且对于视差估计算法中数据计算密集,访存量较大,全局数据较少,像素之间处理相互独立,块与块之间的处理也相互独立,因此存在较大的并行性。
块匹配已经成为视差估计算法中最广泛使用的方法,其中SAD值计算模块占据了大量的编码时间,块匹配的基本思想就是将每一帧视频划分为固定大小的块,并且基于某种搜索规则和匹配标准,通过在搜索窗口的块匹配来估计和当前块最相似的块,并且通过块的相对位移来获得视差矢量。因此,视差估计的准确性以及运算速率直接影响到编码的质量和性能。考虑到搜索过程中只关注当前编码块的结果,不需要参考其他块匹配的结果,所以可以同时进行几个块的匹配操作,并且这几个块同时执行相同的处理过程,因此,对于视差估计算法的并行性分析尤为关键。从软件的角度,并行的方式分为任务级并行和数据级并行,任务级并行是指在不同的时间内并行完成不同的任务,因为任务的数量是一定的,所以任务级并行是不可扩展的,本文主要从数据级并行的角度来对算法的宏块进行并行。在查找最佳块匹配过程中主要是SAD值计算和加载参考块两个模块。
SAD值计算模块主要是由当前编码块存储器、参考块存储器、预测单元,以及存储视差矢量和SAD值的寄存器这几部分组成,将一个预测单元块分成许多比如8×8的小块,这些小块可以并行的进行处理,没有数据相关性,最后将所有预测单元得出的数据合并并且存储其视差矢量和SAD值。加载参考块主要是从搜索窗中加载并下发不同的参考块,在加载和下发参考块后进行数据的更新。在加载和下发参考块数据过程中,可以同时向不同的PE下发数据,这样每个PE可以并行地处理参考块数据,减少时间和资源消耗。
2 视差估计算法并行映射方案设计
3D-HEVC编码过程中,一帧视频图像由多个或一个slice组成,而一个slice又可以被分割为多个编码树单元(Coding Tree Unit,CTU),CTU的尺寸大小为8×8到64×64。编码效率取决于CU尺寸的大小以及划分的深度,尺寸越大,分割的深度越大,编码效率也就越高。CU携带着编码块的运动信息,大小范围从8×8到64×64,其中块划分方式分别为:64×64块深度为0、32×32块深度为1、16×16块深度为2、8×8块深度为3。为了对编码过程中CU块的尺寸大小分布情况解释更加清晰,对3D-HEVC参考软件(HTM)中几种测试序列进行了分析统计。图4是不同深度下几种测试序列分布情况。这几种测试序列Depth为0即块大小为8×8占比最为明显,均超过总分布的60%,因此,论文中选择8×8块进行视差估计并行实现。
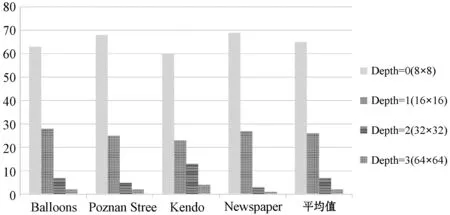
图4 CU不同尺寸的分布情况
本文提出的具体并行设计思想:首先,读入当前编码块和搜索窗数据;其次,同时在空域上和时域上搜索相邻块获取视差矢量,时域相邻块顺序为T0、T1,在其中选择与当前编码块最匹配的块,空域相邻块顺序为A1、B1、B0、A0和B2,在其中选择与当前编码块最匹配的块;最后通过比较这两个最优块候选块选出一个最匹配块,计算视差矢量,完成一个块的视差估计,即当前块的NBDV过程结束。图5是视差估计算法流程图,并行化过程如下:

图5 视差估计算法流程
1) 从当前帧中按照CTU的执行顺序依次处理8×8的块,从参考块中取对应搜索窗大小块,将数据准备好,分配到不同的PE。
2) 同时调度相关PE,在时域相邻块T0和T1和空域相邻块A1、B1、B0、A0和B2同时进行搜索,计算各自的SAD值,进行块匹配操作。在这个过程中,考虑到数据之间存在相关性,因此在进行块匹配之前就已经将当前块和搜索窗数据分配在不同PE,使得不同PE可以同时操作,并行计算各自的SAD值。
3) 根据上一步计算得到的SAD值,分别计算空域和时域相邻块的最优SAD值,并选取各自最小的SAD值,分别得到最优时域和空域相邻块。
4) 根据上一步得到的最小空域相邻块SAD值和时域相邻块SAD值进行比较,从这两个SAD值中得到最优的SAD,得到最匹配的块,由此得到视差矢量,完成一个块的视差估计。
3 基于视频阵列处理器的视差估计算法并行化实现
3.1 可编程可重构视频阵列处理器硬件结构
结合3D-HEVC视频编码标准的特点,本文采用一种可编程可重构的视频阵列处理器进行并行化设计。视频阵列处理器[11]由1 024个轻核处理单元(PE),通过邻接互连组成32×32的阵列处理器,其中每16个PE组成一个处理器簇(PEG)。采用全局片上网络局部共享存储的通信机制,即簇内通过邻接互连和共享存储进行数据交互,簇间通过片上网络进行远距离通信,图6所示为视频阵列处理器的硬件结构,包括数据输入存储、数据输出存储、全局控制器、阵列处理器和指令存储器五部分组成。全局控制器是可重构机制的核心,主要是对PE上计算资源的管理与控制,上层接入主机,下层是PE组成的阵列处理器。在主机接口与阵列处理器之间形成一个层次化编程网络,它可以对阵列资源进行合理的分配与调度,实现多种模式的灵活切换。在每个处理单元中都有一个指令存储和数据存储,因为涉及到两种模式的切换,将指令存储分为两部分,0~511号地址配置为0,512~1023号地址配置为1,并通过全局控制器发出的指令让对应的PE执行相应的操作,从而达到两种配置间的任意切换。指令下发网络是动态重构机制的核心模块,论文主要用到的是指令下发模块中的指令下发和指令广播操作。首先将指令存储在每个PE自带的指令存储中,再通过指令广播的方式启动需要进行操作的PE。指令下发操作的作用是将全局指令存储器中的指令下发到指定的PE。
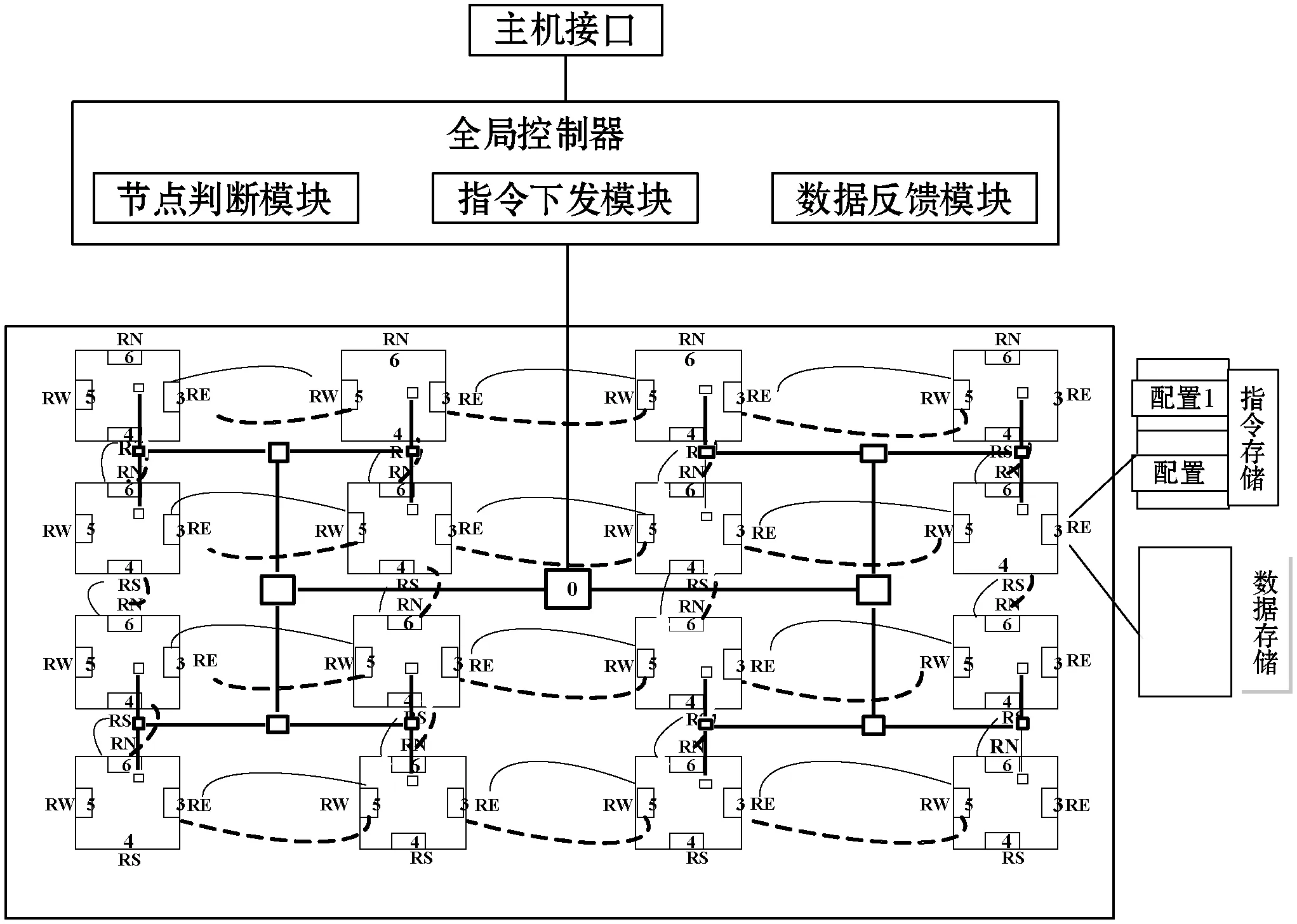
图6 可重构机制的视差估计算法的硬件结构
3.2 视差估计算法并行映射方案
在视差估计算法中,由于搜索当前编码块在空域和时域上相邻块数目较多,搜索顺序复杂,耗时较长,且算法效率低下,因此本文采用数据并行的思想,在同一时间处理时域上和空域上块数据,缩短数据读取时间和计算时间从而提高算法的计算效率。这里以8×8块为例,给出算法的映射图如图7所示。

图7 视差估计算法并行映射图
具体的操作步骤如下:
Step1原始数据和参考数据加载。当前帧的数据存储在数据输入存储(Data Input Memory,DIM)中,参考帧数据存储在外部数据输出存储(Data Output Memory,DOM)的。PE00与DIM相连,将外部存储中原始的一帧图像分为8×8的块送给PE00,然后PE00在进行数据分配,分别下发给PE01、PE02、PE11、PE12、PE13、PE21和PE22;PE10与DOM相连,将外部存储中参考帧图像分为16×16块送给PE10,然后PE10再进行数据分配,分别下发给PE01、PE02、PE11、PE12、PE13、PE21和PE22。为了提高数据传输速率,不需要等待PE00下发完数据后PE10再下发数据,只要从DOM取到数据,便可下发。
Step2块匹配操作。各个PE接收到数据之后,PE01、PE02、PE11、PE12、PE13、PE21、PE22开始并行地进行SAD值计算,选取SAD值最优的块,在这个过程中,计算并不存在数据相关性,所以块匹配操作可以在7个PE中同时进行。块匹配计算完成后,时域上最匹配的块和最优SAD值寄存在PE03,空域 上最匹配的块和最优SAD值寄存在PE23。
Step3获取视差矢量。通过比较在PE03寄存的时域上最优SAD值和在PE23寄存的空域上最优SAD值,得出与当前编码块最匹配的块,并计算出视差矢量,完成视差估计。
4 实验与分析
4.1 实验平台环境及测试方案
为了验证视差估计算法并行实现方案的可行性,论文基于BEECube公司BEE4开发平台搭建的视频阵列处理器原型系统进行验证和测试。首先,根据视频阵列处理器提出的汇编指令进行算法编译,接着在指令翻译器上将汇编代码指令翻译成二进制送给硬件结构;然后,通过QuestaSim 10.1d进行功能仿真,可以通过查看信号如目标寄存器号、寄存器的值和内部数据存储器的值验证仿真结果是否正确。从而在所搭建的可编程可重构视频整列处理器DPR-CODEC上进行视差估计算法的全面验证和测试。在Primeton BPS开发环境下对硬件平台进行逻辑综合,基于BEE4开发平台上的XC6VLX550T FPGA进行硬件测试。表1是在算法验证时需要的环境及所使用工具。
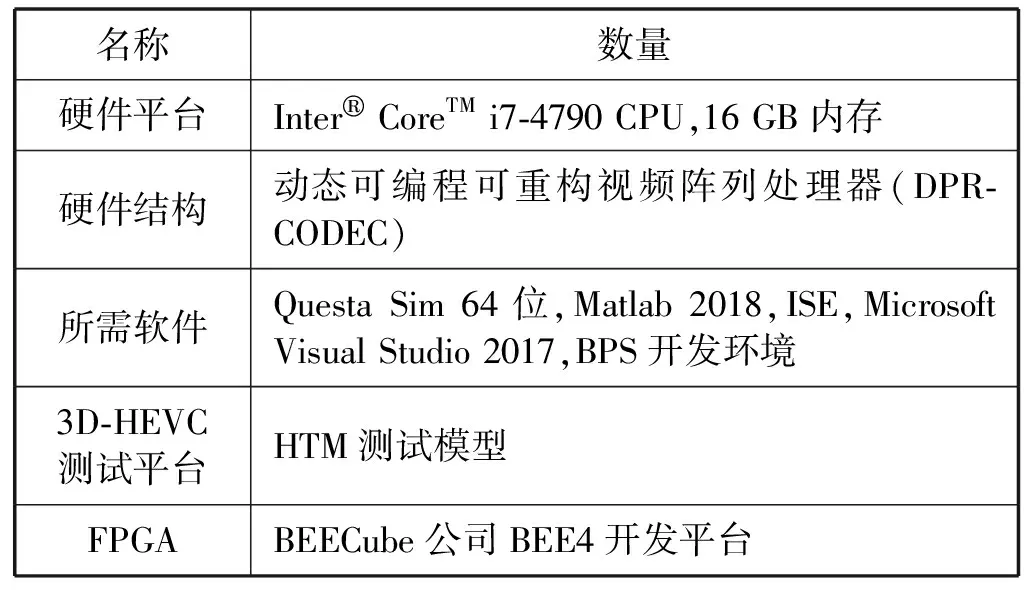
表1 算法验证测试环境和所使用工具
4.2 运行时间对比分析
视差估计算法中块匹配过程采用全搜索算法进行匹配,因此不会降低图像的编码质量,算法执行过程中,可以分为四个模块,即原始数据的加载以及下发、参考数据加载、参考数据下发和SAD值计算模块。通过串行和并行两种实现方案,对算法各模块运行时间作对比分析,串行实现方案是将四个模块在视频阵列处理器的一个PE单独操作,并分别记录每一个模块的运行时间。并行实现方案使用视频阵列处理器中的12个PE来执行程序,模块运行的时间通过QuestaSim软件进行功能仿真得到。在算法执行过程中,记录每一个模块开始到结束的时间来计算运行时间。视差估计算法各模块进行串行和并行的运行时间和如表2所示。根据所统计的时间可以看出,本文所设计的方案主要在参考数据下发以及SAD值计算的过程中提升了并行性,减少了编码时间。两种块方式的匹配过程参考数据的下发和SAD值计算模块加速比超过了4。并行性提升最多的模块为参考数据的下发和SAD值计算模块,加速比分别为4.9和4.37。因为本方案在数据下发的过程中,当PE10的参考块数据存完后,给其握手信号,其他PE便开始块匹配操作,充分利用空闲PE的资源,减少PE等待时间。而原始数据和参考数据的加载过程中加速比不高,因为数据按照地址顺序存储,并行性提升不大。
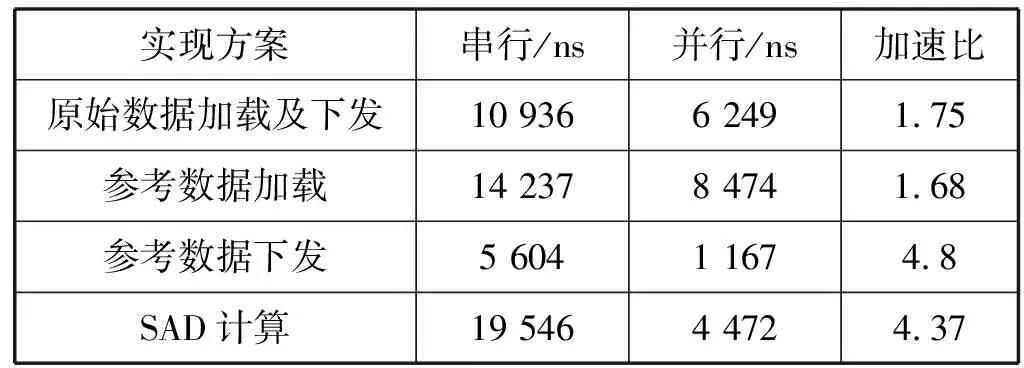
表2 视差估计算法各模块运行时间
文献[12]选出当前编码单元的空域、时域相邻块所有最优视差矢量重新建立NBDV候选列表,根据列表中DV的数量,结合率失真优化算法推导视差矢量来减少编码时间,本文是通过并行处理当前编码单元的相邻候选块来提高算法速率。与文献[12]相比,本文对测试序列Newspaper进行视差估计处理的编码时间减少最多,减少了29.67%,相比文献提升了15%,具体结果如图8所示。

图8 与文献[12]编码时间百分比对比
4.3 运算性能分析
视差估计算法在Primeton BPS开发环境下对硬件平台进行综合,再通过BEE4开发平台XC6VLX550T FPGA对设计进行综合。表3所示为8×8编码块综合结果,从工作频率、资源占用率分别进行比较。文献[13]工作效率比本文低,且资源占用比本文大;文献[14]提出了称为MCADSW视差估计算法,并且提出相应的VLSI体系结构,其工作频率远低于本文,且资源占用率很大;文献[15]提出了一种面向硬件的自适应窗口大小视差估计(T-AWDE)算法和第一个实时的三目视差估计(DE)硬件,工作效率高于本文,但是资源占用率也明显大于本文。
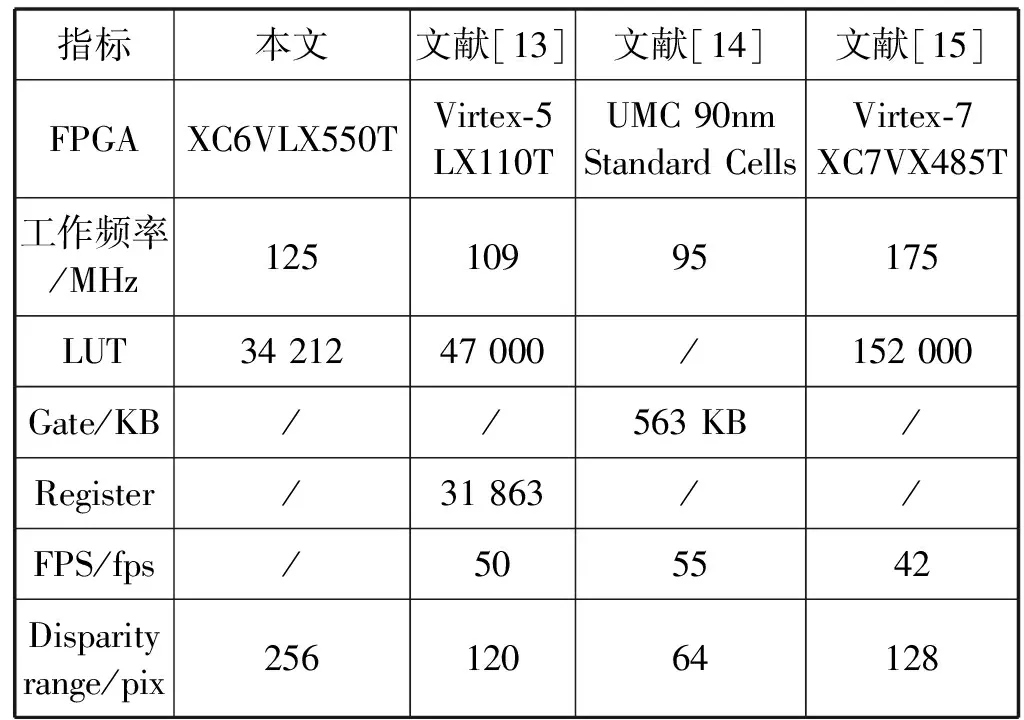
表3 运算性能比较
5 结 语
本文针对软件实现视差估计算法存在处理数据量大、运算时间长和资源消耗大的缺点,基于视频阵列处理器提出了视差估计的并行化实现方案,在阵列结构中完成并行映射、功能仿真及FPGA测试。该方案主要包括原始块数据和参考块数据加载和下发模块以及块匹配模块,充分挖掘了数据块之间的并行性,减少了PE等待时间,提高了运算速率。实验结果表明,所提出的并行实现方案相比于串行单PE时间节省了59%,本文中测试序列Newspaper的编码时间减少最多,减少了29.67%,相比文献[12]提升了15%,该结构在具有较高的执行效率的同时也具有较好的灵活性。
