评分函数在蛋白质-配体结合方面的应用研究进展
2023-08-10曹雨康
曹雨康 江 健,2* 刘 杰,2
1(武汉纺织大学数学与计算机学院 湖北 武汉 430200)2(武汉纺织大学数学与计算机学院非线性科学研究中心 湖北 武汉 430200)
0 引 言
蛋白质与配体的相互作用存在于生物体每个细胞的生命活动过程中,是细胞中一系列重要生理活动的基础。许多生物过程中,如遗传物质复制、基因表达调控、信号转导和免疫应答等都涉及蛋白质与配体的结合。研究蛋白质与配体相互作用的方式和程度,将有助于蛋白质功能的分析、疾病致病机理的阐明和新型药物的开发等众多难题的解决。因此,研究蛋白质-配体相互作用已成为生物化学、生物物理学和分子生物学研究中的核心问题之一。
为了评估蛋白质与配体的结合,人们开发了各种评分函数。自20世纪90年代初以来,研究和开发评分函数成为了一个非常活跃的领域。据不完全统计,文献中公开报道的评分函数已有上百种之多,虽然发展迅猛,但是却没有形成一个合适的分类方案和命名约定。为了促进评分函数在评估蛋白质与配体这一领域的良好发展以及方便初学者对该领域的学习认识,Liu等[1]根据不同评分函数使用的方法和不同的推导方式,将这一领域目前存在的评分函数划分为四大类:基于物理的评分函数、实证评分函数、统计势评分函数、基于描述符的评分函数。其中:基于物理的评分函数通过计算蛋白质与配体结合时的相互作用力来进行评估;实证评分函数使用多元线性回归来拟合现有数据[2-4];统计势评分函数可直接使用蛋白质-配体复合物的数据集,无须进一步地训练[5-7];最后,基于描述符的评分函数是由数据驱动的,除了描述符和机器学习算法之外,其性能很大程度上取决于训练集的好坏,可以处理大量多样化的数据[8-11]。同时文献[12-13]提出了一套评价药物-靶标亲合性评分函数性能的方法体系——CASF(Comparative Assessment of Scoring Functions),用来帮助用户对评分函数进行合理的选择,也为发展评分函数的理论研究提供依据。本文根据这些分类方法和评价体系对目前主流的一些评分函数进行了综述性的介绍,并对评分函数当前存在的一些问题进行了总结,对未来的发展趋势进行了展望。
1 基于物理的评分函数
一开始并没有专门为评估蛋白质与配体相互作用而开发的评分函数,然而由于19世纪70年代Martin和他同事开创性的工作,力场才被逐渐应用到模拟生物大分子中来[14-15]。研究人员因此可以利用力场来计算蛋白质与配体之间的相互作用,评分函数的概念也由此而生。由于蛋白质与配体相互作用的性质,研究者们通常利用的是力场中的非共价相互作用,包括范德华力、静电相互作用和氢键。例如DOCK评分函数[16-17]和AutoDock评分函数[18]的早期版本都使用了AMBER力场[19-21]作为评分引擎,随后这些评分函数考虑了溶剂效应对蛋白质与配体结合的影响从而得到了进一步的发展[22-23],而且鉴于当今计算机的强大性能,量子力学可能会取代力场在评估蛋白质与配体结合中的作用,虽然这种方法还存在很多技术难题,但在很多研究中都有了突破和进展。后来Liu等[1]将这些利用现代力场、量子力学方法和溶剂效应的评分函数统一命名为基于物理的评分函数,这类评分函数大多满足如下形式:
ΔGbinding=ΔEvdw+ΔEelectrostatic+[ΔEH-bond]+ΔGdesolvation
(1)
式中:ΔGbinding表示蛋白质与配体形成复合物的过程中结合自由能[24]的变化;ΔEvdw表示范德华力;ΔEelectrostatic为静电相互作用;[ΔEH-bond]表示氢键;ΔGdesolvation则表示去溶剂化能,综合起来衡量蛋白质与配体的相互作用情况。
前面提到的DOCK评分函数由Elaine等在1991年提出,他们通过计算蛋白质三维结构上各点势函数中的受体依赖项来达到评估的目的,力场在其中发挥了重要的作用。AutoDock是一套分子对接软件,用于预测柔性配体与已知结构大分子的结合,同样使用力场作为评分引擎,是计算机辅助药物设计的典型例子。Wang等[25]在AutoDock的基础上,引入量子化学计算得出的部分电荷数值,使新的模型与AutoDock中的评分函数相比,在对接能力以及评分能力均有提高。Yin等[26]曾提出过一种评分函数——MedusaScore,这个函数基于一个包括范德华力、溶剂效应和氢键在内的物理相互作用模型。为了保证函数的可迁移性,他们没有使用蛋白质-配体实验数据进行参数训练,而是在诱饵识别和结合亲和力[27]预测方面对函数进行了测试,同时他们发现函数产生误差的原因可能是没有考虑结合时的熵损失,这也为改进函数提供了思路。文献[28-29]更加关注的是如何计算蛋白质与配体相互作用时的结合亲和力,他们基于半经验量子力学方法(Semiempirical Quantum Mechanics)设计了一个评分函数,该函数可以计算蛋白质与配体结合过程中的静电相互作用和溶剂化自由能。这个基于物理的评分函数能够计算出多种蛋白质与配体复合物结合亲和力的变化趋势,除此之外还能区分出天然复合物与诱饵蛋白。Jones等[30]针对小分子与已知三维结构的大分子结合模式的预测,设计了一个自动化的配体对接程序——GOLD(Genetic Optimisation for Ligand Docking),利用遗传算法(Genetic Algorithm)进行蛋白质与配体的结合运算,结合时的蛋白质为部分柔性而配体为完全柔性。因其准确性和可靠性在分子圈内评价很高,国内许多科研单位都已引进该软件。Madhavilatha等[31]则采用了一种将多个评分函数进行组合的技术,并将其应用到药物设计中,并且在命中率、假阳性率和丰富度上均有明显提高,与单个评分函数相比,这种组合技术能提供更准确的结果。与此类似的是Perez-Castillo等[32]提出的将单个评分函数整合到一起用于虚拟筛选的方法,他们使用遗传算法来寻找组合评分函数。
2 实证评分函数
Bohm[33]发表的评分函数是公认的第一个实证评分函数,如今在Discovery Studio这个软件中仍然可以用到这个评分函数。实证评分函数的特点在于它通过汇总许多单独的指标来评估蛋白质与配体的结合情况,每个指标都是结合过程中的一个重要因素。例如实证评分函数ChemScore[34]便满足如下公式:
ChemScore=SH-bond+Smetal+Slipophilic+Protor+Pstrain+
Pclash+[Pcovalent+Pconstraint]
(2)
式(2)分为S和P两部分,S为奖励分数,P为惩罚分数。式中:SH-bond为氢键奖励分数;Smetal为与金属离子的配位键奖励分数;Slipophilic为亲脂性奖励分数;Protor为冻结的旋转键惩罚分数;Pstrain为配体的内部应变能惩罚分数;Pclash为蛋白质与配体之间的空间碰撞惩罚分数;Pcovalent和Pconstraint分别为可能存在的共价对接和约束惩罚分数。函数由这些不同的分数组合在一起得出最终的评分结果,实证评分函数通常采用多元线性回归或最小二乘法来计算每个影响因素的权重。
Bohm[33]研究的评分函数LudiScore作为实证评分函数的开创性研究,只采用了34种蛋白质-配体复合物作为训练集,在如今看来可能觉得训练集较小,但是在20世纪90年代末发表的实证评分函数使用的训练集复合物数量普遍小于100,在这种有限的数据集上很难获得鲁棒的评估模型。后来Wang等[35]在LudiScore、ChemScore和SCORE[36-37]的基础上提出了一个新的实证评分函数——X-Score,它的复杂度与LudiScore大致相同,区别在于它使用的训练集复合物数量达到了200,而且比LudiScore拥有更多的参数以供调节,因此得到了收敛的回归模型,在蛋白质与配体结合亲和力的预测上表现更好。评分函数经过多年的发展积累了很多蛋白质-配体复合物的结合数据,如PDBbind-CN数据库[38]。该数据库系统地收集了蛋白质数据库中各类蛋白-配体复合物的三维结构以及亲合性实验数据,致力于提供结构信息和物理化学性质之间的联系,可以为各类分子识别的理论研究提供知识基础,在许多大学、研究所和医药公司的努力下,PDBbind-CN数据库一直在更新与发展。
在实证评分函数近几年的研究中,Syrlybaeva等[39]提出了一种新的CBSF(Contacts-Based Scoring Function)实证评分函数,用于预估蛋白质与小分子之间的结合自由能。函数的权重系数从一个预先训练好的神经网络中推导得出,有较高的精确度。ADMET(药物的吸收、分配、代谢、排泄和毒性)药物动力学方法是当代药物设计和药物筛选中十分重要的方法,然而用这么多ADMET性质来评估化合物的药物相似性并不容易。Guan等[40]提出了一个名为ADMET-score的评分函数来评估化合物的药物相似性,并使用一些退出市场的药物对其进行了测试。文献[41-44]研究的GlideScore可能是目前最成熟的实证评分函数之一,其特点在于它将氢键分为中性-中性、中性-带电和带电-带电三种类型,这使奖励分数与惩罚分数处理地更加细化。与传统评分函数不同,它没有直接将配体对接至已知三维结构的蛋白质上,而是近似地预测对接对象的构象、方向和空间位置,这种方法的准确度几乎是上一部分提到的自动化的配体对接程序GOLD的两倍。后来王玮[45]在一次研究中发现,GlideScore在成功识别蛋白质-配体复合物的晶体结合构象的前提下,对这些复合物的反向对接过程的识别率只有57%,其原因可能是GlideScore存在不同蛋白之间的噪声,在后续的研究中,他们发现引入一个以“Balance”为核心的修正项,可将预测准确率提高到72%,并将改进后的评分函数命名为BCGlideScore。
3 统计势评分函数
在1996年DeWitte等发布的设计项目SMoG(Small Molecule Growth)中,统计势评分函数首次被提出,并在接下来的十年左右的时间里迅速普及[46-47]。这是根据蛋白质与配体的结合亲和力对已知三维结构的蛋白质-配体复合物进行排序的一种方法。这一类型的评分函数在技术层面可能有所不同,但它们遵循着相同的原则:求出蛋白质与配体之间的统计成对势[48]:
式中:lig为配体的原子数;prot为蛋白质的原子数。从而达到排序的目的。ωij(r)是原子对i-j之间的距离相关势,可以根据玻尔兹曼方程分析导出:
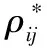
统计势评分函数首次在SMoG项目中被提出后,这一类型的评分函数的研究引起了人们的广泛关注。Muegge[49-50]开发了评分函数PMF(Potential of Mean Force),其使用蛋白质-配体复合物的结构信息来推导原子对相互作用势能。用计算出的PMF得分来衡量不同蛋白质-配体复合物的结合亲合力。文献[6,51]提出了DrugScore,他们在文章中介绍了这个评分函数的开发和验证过程,它可以很好地区分已成功对接的蛋白质配体结构和一些由计算机程序生成的偏差量较大的结构。后来在DrugScore2018[52]版本中,他们对训练集进行了升级,并在CASF-2013中对其进行了测试,在评分、排序和对接能力上均表现良好。Huang等[53]使用一种新的迭代方法开发出一个统计势评分函数ITScore,ITScore中蛋白质与配体的成对统计电势来自由蛋白质数据库中的786个蛋白质-配体复合物组成的训练集,他们采用的迭代方法的基本思想是通过迭代提高成对统计电势,直到函数能正确地将训练集中的复合物结构与诱饵结构区分开。与此类似的是Yan等[54]开发了一种基于统计势的双迭代评分函数DIScore/RR,用于评估RNA与RNA的相互作用。这个双迭代函数通过迭代更新势函数解决了参考状态的问题,并通过迭代解决了常规方法中依赖诱饵的问题,有助于RNA结构和RNA复合物的预测和设计。Xu等[55]提出了一种基于碳原子的评分函数OPUS-CSF,用于蛋白质模型结构的排序。Zheng等[56]提出的统计势评分函数KECSA重新定义了参考状态,从而使他们能够将成对统计电势与LJ势(Lennard-Jones)联系起来(LJ势由蛋白质数据库中蛋白质-配体复合物的结构数据生成),通过这一方法他们推导出了49种原子对的相互作用。
在此之后,Liu等[57]基于两个蛋白质-配体复合物训练集,采用迭代法开发了一种基于统计势的卤键评分函数,称为XBPMF,用来预测蛋白质与配体的相互作用。他们将蛋白质-配体复合物的结构信息转换为与原子对距离相关的成对电势,在对接、评分和排序能力上表现中等。对非共价相互作用卤键[58-60]有较好的预测效果。Huang等[61]研究的一种平均力势能评分函数,也属于统计势评分函数,同样用来评估蛋白质与配体的结合。他们介绍了平均力势能评分函数的背景和最新进展,并讨论了可能遇到的挑战与未来进展的方向。王希诚等[62]研究的一种通过计算原子对间距离来评价结合自由能的统计势评分函数,其构造方法与前面提到的平均力势能函数相似,同时采用基于信息熵的多种群自适应遗传算法,在降低了计算效率的同时,预测精度得到了提高。汪心亭[63]提出的一个复合的统计势评分函数ITCPS(Iterative Composite Scoring function)综合考虑了成键与非成键势能,以及依赖方位取向的相互作用和疏水相互作用,在测试中有较高的成功率。
4 基于描述符的评分函数
基于描述符的评分函数的研究开始于2004年左右[64-65],这种方法由于研究中包含大量描述符而得名。其特点是将定量结构-活性关系(Quantitative Structure-Activity Relationship,QSAR)研究方法[66]引入到了蛋白质与配体相互作用的评估中。自计算机辅助药物设计实现以来,QSAR研究方法便广泛应用于预测化合物的理化性质和生物活性中。这类评分函数通常使用如随机森林、贝叶斯分类器、神经网络和支持向量机在内的机器学习算法来进行变量的选择,近年来得到了蓬勃的发展[67],与实证评分函数类似,它也需要一些已知结构和结合数据的蛋白质-配体复合物的训练集来推导函数模型。但与前面三种评分函数通常为线性函数不同的是,基于描述符的评分函数由于采用了机器学习算法通常为非线性函数[68]。
Durrant等[69-70]提出的一种基于神经网络的评分函数(NNScore)便属于基于描述符的评分函数,他们建立的这个模型能够模拟大脑的微观组织,可以快速准确地预测候选配体的对接姿势,此外他们还提出了NNScore 2.0版本,NNScore 2.0在预测结合亲和力时考虑的结合因素更全面,网络输出方式也不同于1.0版本。NNScore除了单独使用,还能与其他评分函数配合使用,在药物设计与发现方面发挥着不小的作用。Ballester等[8]将随机森林算法应用到了预测蛋白质与配体结合中,采用蛋白质数据库(v2007)为训练集,以蛋白质-配体原子作用对为描述符,提出的RF-Score评分函数通过非参数机器学习算法进行建模,训练集越大,函数预测的准确性越高。与此类似的是Zilian等[71]在实证评分函数SFCscore的基础上,对一个含有1 005个蛋白质配体复合物的训练集用随机森林算法进行回归,提出了改进的SFCscoreRF,改进后的版本在面对大型数据集时预测准确性更高。Li等[72]根据氢键相互作用、静电相互作用、范德华相互作用等九种描述符开发了一个基于多种分子描述符的评分函数——ID-Score,他们使用支持向量回归的方法挑选出关键的分子描述符从而构建评分函数模型,用来拟合蛋白质与配体的结合亲和力,在基于结构的药物设计中被广泛应用。Neudert等[51]使用剑桥晶体结构数据库CSD(Cambridge Structural Database)中的信息为基础,提出了基于描述符的评分函数DXS,测试后他们认为DXS在对接、评分及排序上表现良好。Nguyen等[73]对频谱与几何关系问题提出了新的研究思路。他们提出了一种新的代数图学习函数AGL-Score(Algebraic Graph Learning Score),从而将高维物理和生物学信息编码为低维的表示形式,他们通过多个基准数据集,对提出的AGL-Score模型的评分能力、排名能力、对接能力和筛选能力进行了验证。结果表明AGL-Score模型在蛋白质配体结合评分、排序、对接和筛选等方面优于其他最新的评分函数。他们的这项研究表明机器学习方法是用于分子对接和虚拟筛选的强大工具,同时也表明谱几何或谱图具有推断几何性质的能力。冯永娥[74]基于位置权重矩阵开发的评分函数主要应用于预测蛋白质的二级结构,他们在CB513数据库中分别截取2种不同的残基片段,统计20种氨基酸在蛋白质的三种二级结构(alpha螺旋、beta折叠和无规则卷曲)序列中各个位点的位置权重矩阵,然后利用基于位置权重矩阵的评分函数来预测蛋白质的二级结构,取得了较好的结果。与此类似的是王世缘等[75]研究的位置评分函数,用于预测转录因子的结合位点,他们下载了ABS数据库[76]和TRANSFAC数据库[77]中所共有的位置权重矩阵,并计算出位置权重矩阵的估计概率和矩阵中不同列上结合位点序列的保守性,从而构建出位置评分函数,该函数由于考虑了多个同源物种的相关启动子序列信息和进化保守性信息从而预测结果更为准确。苏敏仪等[78]研究了预测药物分子解离速率常数(koff)[79-80]的通用型定量结构-动力学关系(QSKR)模型,他们收集了406个配体分子的解离速率常数实验值,采用分子模拟方法构建了所有配体与靶蛋白复合物的三维结构模型,然后基于蛋白质-配体原子对描述符,采用随机森林算法来构建QSKR模型。
王帅等[81]将深度学习算法引入到了预测RNA二级结构的评分函数中,提出了一种基于双向LSTM(Long Short Term Memory)神经网络的RNA二级结构评分函数。与传统的机器学习方法不同,他们的深度序列模型允许对整个RNA序列进行建模,避免了传统机器学习会丢失全局信息这一问题,同时他们对已有短序列的RNA二级结构评分函数在算法上进行了改进,改进后的评分函数可以预测变长序列的RNA二级结构。李春华等[82]则对蛋白质-RNA对接中评分函数设计的进展进行了总结,在此基础上他们将自己发展的60×8氨基酸-核苷酸成对偏好势与基于物理的能量项(静电能和范德华能)进行组合,提出了一个加权组合评分函数RpveScore,对蛋白质-RNA的对接预测成功率较高。同时他们也研究了蛋白质-蛋白质分子对接中评分函数的应用[83],对这其中存在的问题进行了总结,并提出了对该领域未来工作的展望。Karasikov等[84]提出了一种用于单模型蛋白质质量评估的方法SBROD(Smooth Backbone-Reliant Orientation-Dependent),首先提取特征,然后训练预测模型来构建评分函数,SBROD只从蛋白质主链构象提取几何结构特征,因此在对蛋白质结构进行排序时,不用考虑蛋白质的侧链构象。刘飞等[85]基于部分互信息(Mutual Information,MI)和贝叶斯评分函数,提出了一种新的基因调控网络构建算法,可以有效挖掘基因间调控关系,快速构建基因调控网络。Lu等[86]提高了基于机器学习评分函数的鲁棒性和适用性,他们提出的ΔvinaXGB(extreme gradient boosting)与同类型评分函数相比性能更强,而且对不同类型结构的模拟对接也有较高的预测精度。Karlov等[87]提出的MPNN(Message Passing Neural Network)评分函数采用图卷积神经网络来预测蛋白质与配体的结合,他们在不同的数据集上对MPNN进行了测试,并与其他评分函数进行了比较。Shen等[88]则对近年来发展的基于机器学习评分函数的研究进展进行了总结,并对近年来发展的基于深度学习的评分函数进行了探讨与展望,他们认为前者的不断发展必将促进药物设计的前期研究,加快新药物的研发速度。Levin等[89]开发了一个机器学习模型用于预测CDK(细胞周期蛋白依赖性酶)的结合亲和力,并将该模型与传统的评分函数进行比较。
关于评分函数在蛋白质-配体结合方面的应用汇总如表1所示。
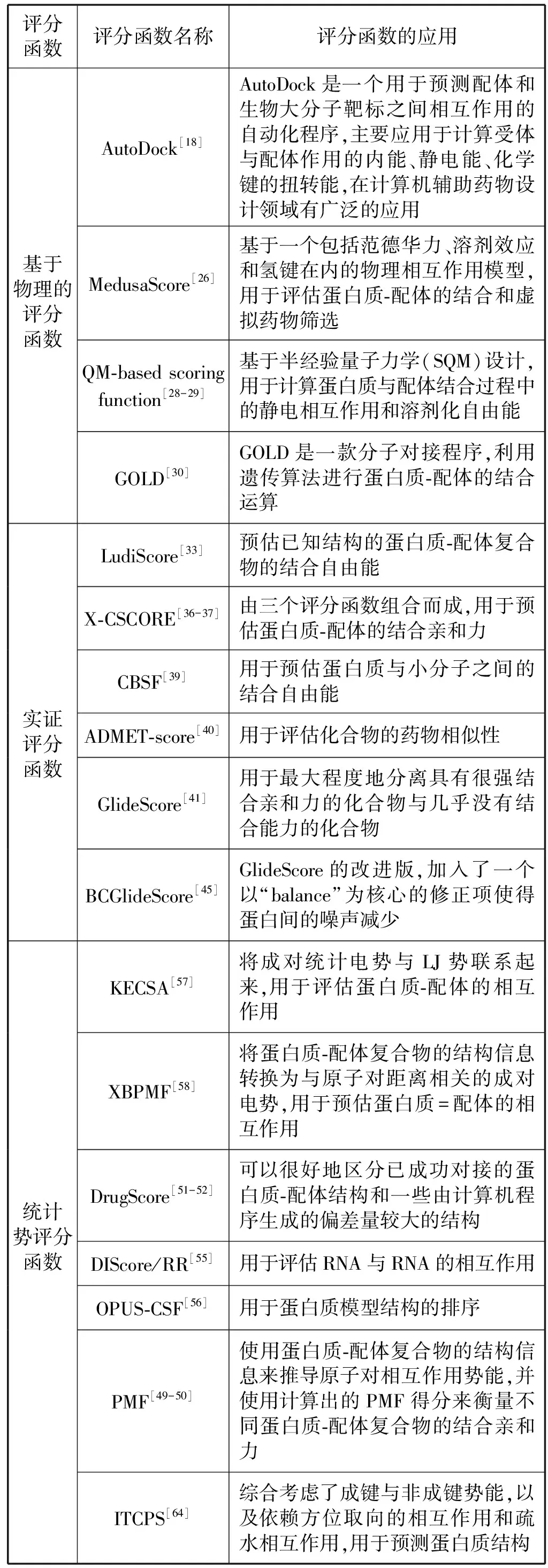
表1 评分函数在蛋白质-配体结合方面的应用
5 结 语
评分函数在基于结构的药物设计和虚拟筛选中发挥着重要的作用,近年来呈现蓬勃发展的势头,广泛应用于配体对接姿势预测、复合物排序、蛋白质与配体结合亲和力预测等方面,本文根据评分函数的分类对一些具有代表性的评分函数进行了梳理与介绍,可以看到在国内外学者的努力下,越来越多评分函数被开发出来,它们都有各自的优势和缺点:
(1) 基于物理的评分函数有一个明显的优势在于它可以利用现代力场、量子力学和溶剂化模型等方法,而且近二十年来计算化学领域取得了长足的进步,当蛋白质与配体的结合自由能能够被准确地计算出来时,基于物理的评分函数应该会成为主流。这类评分函数无论是基于力场还是其他模型,在实验中测得的结合自由能变化很小,而且函数中每个单独的能量项都存在固有误差,因此目前基于物理的评分函数通常需要缩放参数来达到更佳的实验效果。
(2) 实证评分函数通过蛋白质与配体复合物的数据集来计算权重,而早些年由于缺少较好的数据集,实证评分函数没有得到良好的发展,随着大量蛋白质配体复合物的结构信息和结合数据被采集,数据集的质量越来越高,因此实证评分函数的优势近些年得以展现,但是它仍然存在着一个问题:从各种文献中收集到的实验数据可能不是在同一条件下得到的,这会使预测结果产生误差。为了避免这个问题,应尽量使用同一来源的数据。
(3) 统计势评分函数主要优点在于其概念和计算简单,与基于物理的评分函数相比,它对原子进行成对处理因此效率更高;与实证评分函数相比,它可以捕捉到蛋白质-配体相互作用中所隐藏的能量因子从而使函数形式更优。同时统计势评分函数在如下方面还需要改善:考虑熵效应对复合物能量的影响从而提高函数的准确性;对原子类型进行适当的分类,做好原子对出现次数和原子类型数目之间的平衡;目前的成对电势太过简化,由于引入了更多待定参数,如何整合多个对象的相互作用以及这样做是否可以提高评分函数性能仍然未知;在参考状态不明确时,对绑定模式的预测和虚拟筛选(virtual screening)仍存在问题,解决这个问题的方法之一是采用ITScore中的迭代方法,该方法考虑了复合物的结构和诱饵结构。这些方面逐渐完善后,平均势能评分函数将成为基于结构的药物设计中宝贵的工具。
(4) 基于描述符的评分函数优势在于它可以利用机器学习算法对难以建模的情况进行计算,并且对评分函数的形式没有限制,可以直接从实验数据直接推断出可能的结合方式。很多报告认为基于描述符的评分函数比其他类型的评分函数预测效果更好,许多学者对此存在争议,因此有必要在评分能力、排序能力、对接能力和筛选能力等方面对它们进行比较。
总体而言,对评分函数在评估蛋白质与配体的研究中,我们正面临着许多挑战性课题:目前的评分函数在评分和排名这些方面表现较差;在虚拟筛选时对较低结合亲和力和无亲和力区分效果不好;种类众多,但哪一种代表着评分函数的发展趋势并没有形成共识。经过近三十年的发展,评分函数已经形成了坚实的理论基础,在实际应用方面也取得了许多成效,除此之外,合适的分类方案和命名约定的提出也使评分函数的发展更为健康高效。将来随着更多高质量多样性的蛋白质配体复合物训练集应用到评分函数中,已有的评分函数可以得到进一步的完善,更多新的评分函数会逐渐被开发出来,评分函数在药物设计以及其他领域也会得到更广泛的应用。
