基于半监督编码的深度卷积对抗网络模型研究
2023-08-09欧莉莉杜芳芳
欧莉莉, 杜芳芳
(黄河交通学院智能工程学院, 河南 焦作 454950)
0 引言(Introduction)
图像识别技术是深度学习领域的一项重要内容,在识别图像时,深度学习方法研究的基础是对图像进行处理、分析、理解得出结果,图像的预处理、特征的提取与匹配是图像识别技术非常重要的环节。用计算机进行图像识别,不仅能够提高图像数据的处理效率,而且能对人眼很难观察、提取到的图像信息进行更多细节的辨识[1]。图像识别的方法主要有传统图像识别和深度学习图像识别。传统图像识别方法在识别的过程中,只能对图像的低级边缘信息进行处理,无法获得图像的深层信息,并且需要人工进行预处理,导致图像处理的效率和准确率不高。而深度学习图像识别方法能够通过构建多层隐藏层网络,利用计算机自适应地学习图像中的局部细节及图像的空间全局特征,具有很强的识别能力,而且识别图像的准确率也很高。
1 相关理论(Related theories)
2014年,GOODFELLOW等[2]提出了生成对抗网络(Generative Adversarial Networks, GAN),GAN模型的基本框架由生成器和判别器两个部分组成。在生成器中,主要通过对随机噪音的输入,使得产生的样本更接近实际数据的分布。在此基础上,将数据和产生的样本分别输入判别器,由判别器区分两者,最后得到样本为真值的概率。在2015年提出的深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Networks, DCGAN)模型,是对GAN模型的改进,并首次使用卷积神经网络进行特征提取,从而改善了GAN模型学习的稳定性[3]。2016年,OpenAI发布了一种改进的GAN模型,称为半监督生成对抗网络(Semi-Supervised Generative Adversarial Networks, SSGAN)[4]。在训练SSGAN模型时,它的损失函数是通过有监督和无监督的混合学习实现的,可以提高半监督分类的精度[5-6]。
2 半监督编码深度卷积对抗网络模型研究(Research on semi-supervised coding deep convolutional adversarial network model)
2.1 SSE-DCGAN模型
为了实现对图像更高效和精确的识别,文章提出了半监督编码深度卷积生成对抗网络(Semi-Supervised Encoder Deep Convolutional Generative Adversarial Networks, SSE-DCGAN)模型,该模型将GAN、DCGAN、SSGAN和编码器提取特征等方法相结合,最大限度地发挥每一种方法的优势,建立更准确的图像识别模型。图1为SSE-DCGAN模型的基本架构。
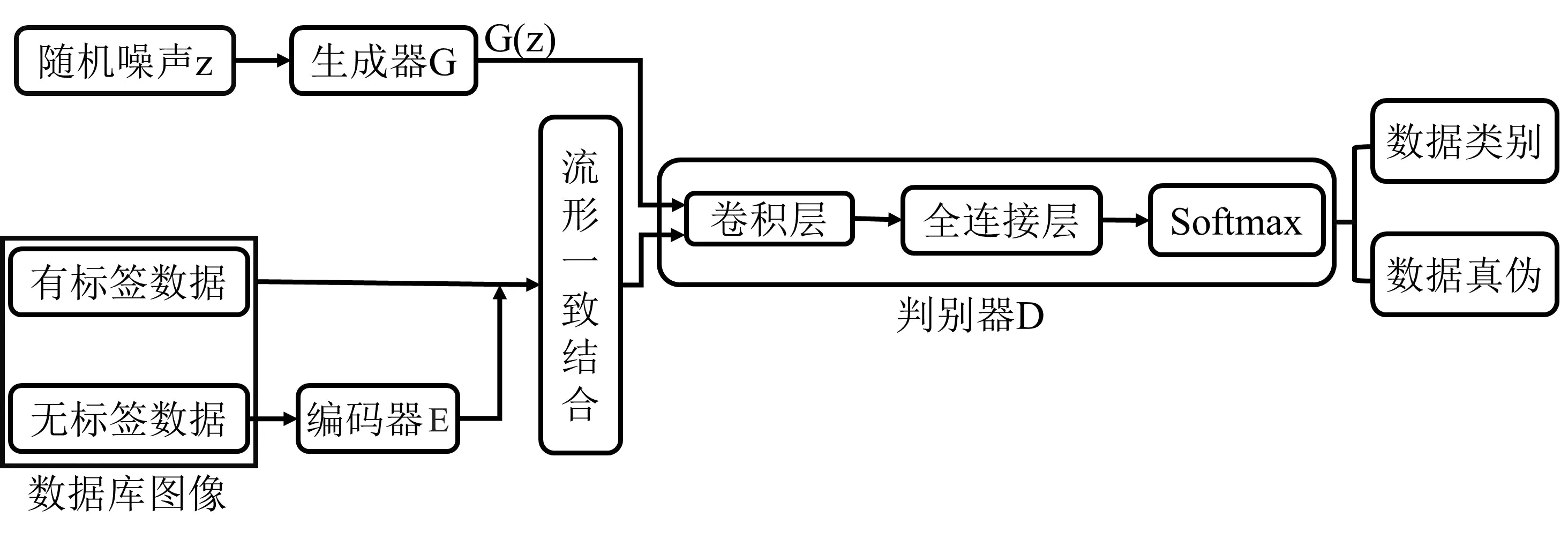
图1 SSE-DCGAN模型基本框架Fig.1 Basic framework of SSE-DCGAN model
在SSE-DCGAN模型中使用流形相一致的合并模式,其过程如图2所示,通过将图像数据和特征进行融合,能有效地处理数据间的不匹配问题,降低网络的计算量。
为了避免因批量初始化(Batch Normalization, BN)操作不当造成的训练过程异常问题,对图片进行处理时采用L2范数归一化[7]。在L2范数处理过程中,第l层的神经元输出如下:
(1)
将L2范数用于隐变量和特征相结合的归一化操作,在对l-1层参数进行逆向求导时,要添加一个导数除以特征模的运算,也就是当SSE-DCGAN模型使用流形一致结合的方式时,可以缩短模型的预计计算时间,进而加快模型的收敛。

图2 SSE-DCGAN模型中流形一致结合方式Fig.2 Consistent binding of manifolds in the SSE-DCGAN model
2.2 SSE-DCGAN模型训练
SSE-DCGAN模型的学习过程就是一个不断优化损失函数的过程。SSE-DCGAN模型中的损失函数包括判别器的损失LD、生成器的损失LG、编码器的损失LE。将三种类型的数据(有标记数据、无标记数据、生成数据)和数据相应的特征输入判别器,并且都有各自对应的损失函数,即有标签数据损失Llabel、无标签数据损失Lunlabel、生成样本损失Lgen、数据特征(编码器)损失LE。如公式(2)所示,有标签数据损失是真实类标签分布和预测类标签的交叉熵损失;无标签数据损失是无标签数据来自真实数据,此时y≠K+1;生成样本损失是生成器生成的伪样本被判别器判断为假样本的损失,此时y=K+1;数据特征损失编码器用来提取真实数据的特征。
在对判别器损失函数进行优化时,有标记的数据需要被监督的学习,无标记数据、伪样本用于无监督学习。即
LD=LE+Llabel+Lunlabel+Lgen=LE+Lsupervised+Lunsupervised
(2)
公式(2)中:
(3)
编码器损失LE用于解决数据之间的偏移问题,它的损失函数是交叉熵损失,如公式(4)所示:
(4)
监督损失Lsupervised主要由Llabel组成,相当于一种有监督的分类工作,对于一个K分类问题,网络参数的优化要求使标记数据的样本和模型预测分布Pmodel(y|x)之间的交叉熵最小,其表达式如公式(5)所示:
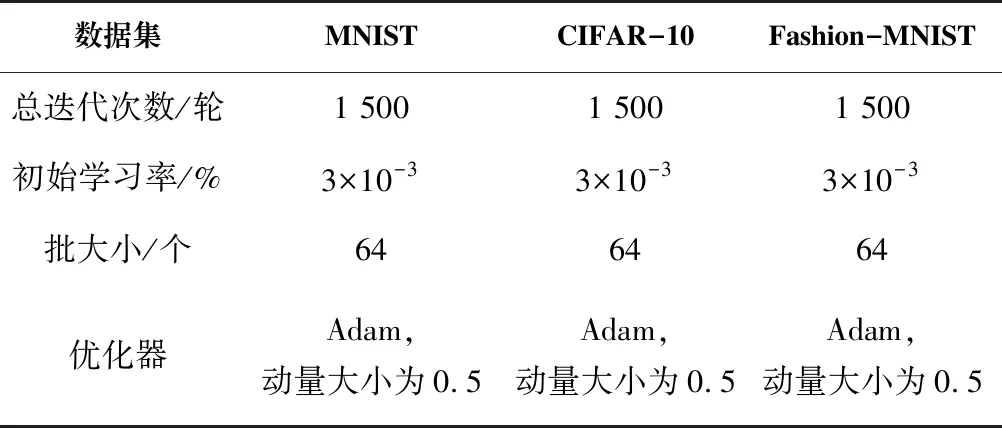
Llabel=-Ex,y~PdatalgPmodel(y|x,y (5) 无监督损失Lunsupervised主要由Lunlabel和Lgen组成。其中,Lunlabel在训练时尽可能最大化无标签数据来自真实数据的概率如公式(6);以及Llabel尽可能最大化样本来自生成样本的概率如公式(7): Lunlabel=-Ex~Pdatalg[1-Pmodel(y=K+1|x)] (6) Lgen=-Ex~Glg[Pmodel(y=K+1)] (7) 对于生成器的损失函数LG来说,为了让生成器对实际数据分布有更好的学习能力,本文使用特征匹配法定义LG[8]。在训练的时候,用伪样本和真样本特征匹配的结果作为生成器的损失函数,使损失函数达到最小值,它的定义在公式(8)中已给出。 (8) 本文将SSE-DCGAN模型应用于MNIST、CIFAR-10和Fashion-MNIST数据集进行图像识别研究。三种数据集中的图片类型如图3所示。 (a)MNIST (b)CIFAR-10 (c)Fashion-MNIST 本文的所有实验都是以Tensorflow为基础,用Python语言完成编程。硬件为通用PC机(CPU 3.60 GHz、RAM 32.0 GB);操作系统为Windows 10专业版(64位)。 在MNIST、CIFAR-10、Fashion-MNIST三种数据集上进行实验时,实验参数的设置如表1所示。 表 1 参数设置 本文对SSE-DCGAN模型的有效性进行分析和验证,具体步骤如下。 3.3.1 MNIST数据集的实验 在MNIST数据集中,为了减少模型占用的运算时间,在训练开始时,先对数据进行归一化处理。为防止模型过拟合,将Dropout参数设定为0.5。有标记样本的数被设定为100个、1 000个和10 000个,一共做了三个对照实验,实验对比的结果列于表2中。从表2中可以看出,当用相同的有标记数据进行测试时,在半监督对抗训练下,SSE-DCGAN模型能提高图像识别的精度。 表 2 MNIST数据集上测试精度的对比结果 从表3中的实验结果可以看出,在模型中加入编码器后,识别精度提高0.43%,这表明在SSE-DCGAN模型中添加编码器对于提高模型的性能是可行的,编码器的引入还可以帮助模型对图像进行更深层次的学习。 表 3 MNIST数据集上的消融实验 图4显示了在训练期间由生成器生成的局部图片的视觉效果:当epoch=1(刚刚开始训练)时,仅能获得一幅模糊的灰度图,但是随着训练次数的增多,各种数值的特征会逐渐呈现出来,其中训练到1 500轮时,各种数值的特征呈现更为显著,说明该生成器对实际数据的分布有着较好的拟合效果。 (a)eopch1 (b)epoch1 500 3.3.2 CIFAR-10数据集的实验 CIFAR-10是一种自然图像数据集,它的图像中包含非常复杂和丰富的细节,生成器中Dropout系数的设定可能会在训练时产生误差,因此本文对SSE-DCGAN模型进行了大量的实验,最终将Dropout系数设定为0.3。根据这个系数,本文进行了3组不同的实验,有标记的样本数为1 000个、2 000个和4 000个,实验结果列于表4中。由表4可知,相比较于其他模型,SSE-DCGAN模型在半监督对抗学习条件下具有更高的识别率。 表 4 CIFAR-10数据集上测试精度的对比结果 为了测试模型在增加了一个编码器之前和之后的辨识能力,消融实验选择在CIFAR-10数据集有标记数据为4 000时进行,对比各种模型的实验结果见表5:在GAN模型中添加编码器后,模型的预测准确率从89.23%上升到91.78%,提升了2.55%。实验结果显示,编码器加入SSE-DCGAN模型中,能够改善实际数据中的图像特征,从而使SSE-DCGAN模型不但能对更复杂的图像进行有效的处理,还能在一定程度上提高图像的识别精度。 表 5 CIFAR-10数据集上的消融实验 图5是生成器在不同的训练次数时产生的局部图像。可以从图中看到,每一幅图像的特征都越来越清楚,特别是模型训练到1 500轮时,每一幅画的特征都很明显。此外,随着训练次数的增加,模型趋于稳定,生成器的性能增强,所生成的虚假样本可以骗过判别器,与实际数据一起训练判别器,最后得到准确的判别表面。 (b)epoch1 500 3.3.3 Fashion-MNIST数据集实验 在Fashion-MNIST数据集上,与MNIST数据集上采用相同的参数设置。同时,在此数据集中,有标记的样本数为1 000个和10 000个。表6中列出了实验结果:在使用相同数据和同样带标记的数据时,SSE-DCGAN模型有效地提升图像识别准确率,获得优于对比模型的识别准确率。 表 6 Fashion-MNIST数据集上测试精度的对比结果 为了检验SSE-DCGAN模型对图像的处理效果,消融实验是在标记数据为10 000个时进行的,将使用编码器之前和之后的模型识别结果进行比较,实验结果见表7。四种识别Fashion-MNIST数据集模型的准确率不断提高,特别是加入编码器之后,SSE-DCGAN模型的精度从89.02%到93.46%提高了4.44%。 表 7 Fashion-MNIST数据集上的消融实验 图6显示了该生成器在训练期间生成的一部分图像。从图中我们可以看到,训练到50轮次时,生成的图片都比较模糊,没有T恤和裙子之类的特征。然而,随着训练轮次不断增加,图像中的特征会越来越显著,当epoch为1 500时,这些特征在图片上更明显,这也说明生成器可以很好地对真实数据进行仿真。 (a)epoch50 (b)epoch1 500 本文将半监督学习引入到生成对抗网络,并且针对生成对抗网络的不足之处,提出了一种基于生成对抗网络的新算法,并通过在三种不同类型的数据集上进行试验,证明了新模型的优势。尽管文中提出的模型可以有效地提高图像识别的准确率,但是仍然存在不足之处:(1)增加了训练模型的参数。采用编码器结构后,虽然提高了图像识别的准确率,但是学习过程中存在大量的参数,使得模型耗时较长。在以后的研究中,可以对该模型进行改进,从而提高其计算效率和识别结果的准确性。(2)近几年来,针对生成对抗网络的研究多集中于对生成器或判别器的改进,该领域尚无新的研究方法,今后可考虑将生成对抗网络与传统的机器学习方法相结合,以达到半监督对抗训练的目的。3 实验结果与分析(Experimental results and analysis)
3.1 数据集



3.2 实验环境
3.3 SSE-DCGAN模型验证实验











4 结论(Conclusion)
