基于改进卷积神经网络的图像数字识别方法研究
2023-08-09王耀宗张易诚康宇哲
王耀宗, 张易诚, 康宇哲, 沈 炜
(浙江理工大学计算机科学与技术学院, 浙江 杭州 310018)
0 引言(Introduction)
纸质试卷作为教学考试的重要载体,被广泛应用于各种考试中。一直以来,试卷分数的统计主要有两种方式:一种是人工阅卷,教师通过口算或计算器对试卷分数进行汇总;另一种是使用特定的答题卡,通过光标阅读器对答题卡进行扫描,进而统计分数。前者不仅需要消耗大量的人力和时间,而且效率低、错误率高,后者需要制作特定的答题卡且光标阅读器价格昂贵,无法大规模应用[1]。
随着卷积神经网络的发展,数字识别技术在教学考试中得到了广泛应用。周铁军等[2]基于Keras构建了可以识别分数为70分以内的卷积神经网络,但该网络的识别准确率不高,只有94%。仝梦园等[3]提出了一种融合贝叶斯分类器的分数识别算法,该算法虽然有着较高的识别率,但是无法准确地定位题目的分数,存在漏检风险。
针对上述问题,本文采用一种带有特殊分值框的试卷,并在此基础上提出了一种基于改进卷积神经网络的试卷分数识别方法。该方法分为两个部分,第一部分基于YOLO目标检测算法对该分值框进行定位,并引入膨胀卷积模块丰富感受野、优化调整边框损失函数、提高收敛速度[4]。第二部分基于ResNet卷积神经网络对分数进行识别,并融合注意力机制提高特征提取能力[5]。实验结果表明,该方法可以准确高效地识别试卷图像中的分数,大幅度降低人工阅卷的工作量。
1 模型构建(Model building)
1.1 YOLOv5
1.1.1 YOLOv5模型结构
相较于R-CNN(区域卷积神经网络)、Fast R-CNN(快速区域卷积神经网络)等二阶段(Two Stage)算法,作为一阶段(One Stage)算法的YOLO有着更快的检测速度,并且随着YOLO版本的不断迭代,其准确率也有了很大的提高[6-7]。本文基于YOLOv5目标检测算法实现对分数框的定位,该算法结构由输入端、Backbone(骨干)、Neck(瓶颈)和Head(头部)四个部分组成,如图1所示。
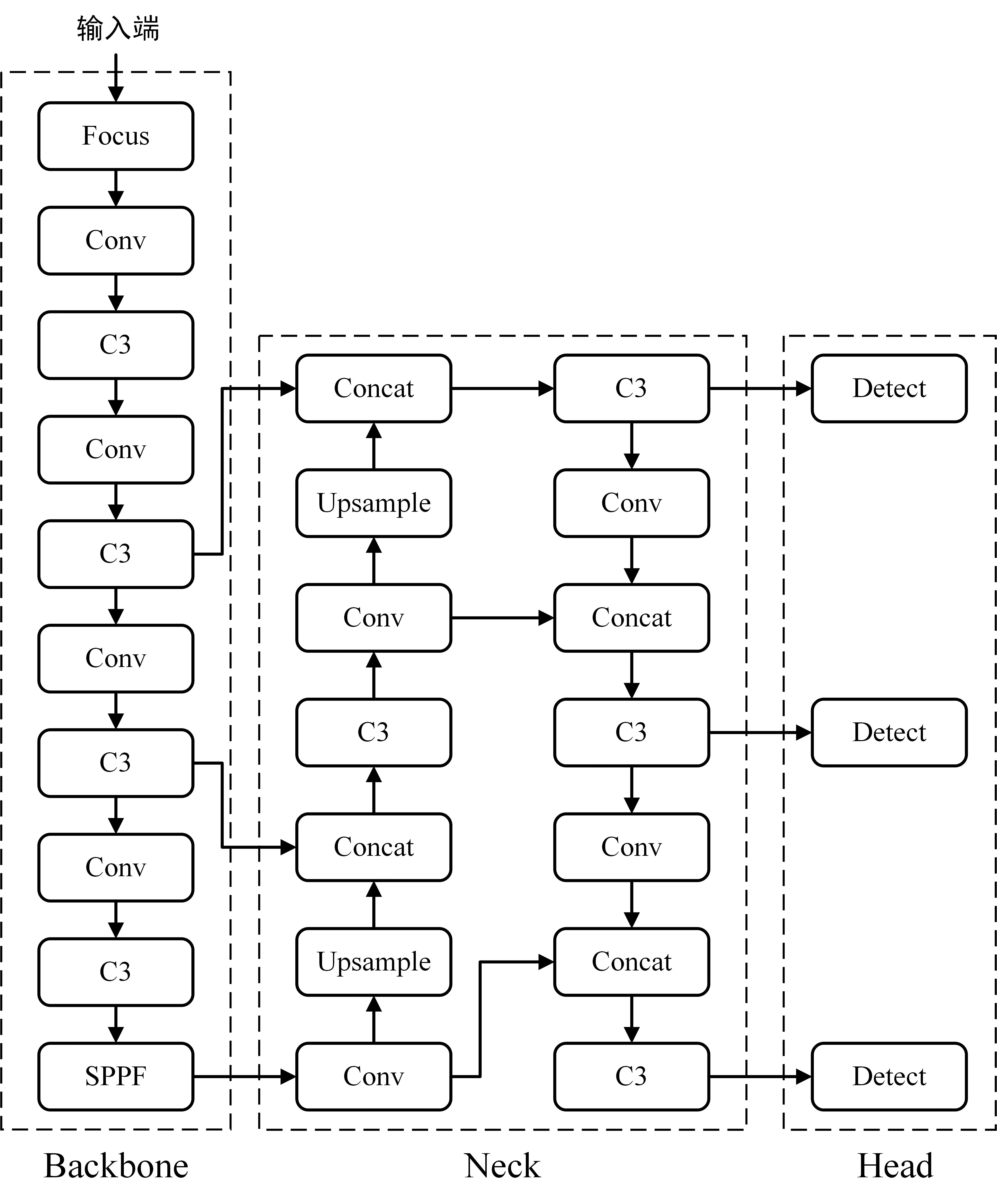
图1 YOLOv5结构图Fig.1 The structure of YOLOv5
输入端使用Mosaic数据增强方式随机选取数据集中的四张原始图片进行随机裁剪、缩放和排布,拼接为一张图片作为输入,这样不仅可以大幅度丰富数据集,还能丰富目标物体的尺度,提高整个网络的鲁棒性。
Backbone中使用了Focus结构和C3结构。Focus使用切片操作把一个大尺寸特征图拆分成多个小尺寸特征图,然后进行Concat(拼接)操作。C3是基于CSP结构将原本的残差结构分为两个部分,一部分仅经过一个基本的卷积运算模块,另一部分使用了多个残差块堆叠,最后将两个部分进行Concat操作,这样不仅可以实现更丰富的梯度组合,还能在增强网络特征提取能力的同时,大幅度减少参数量[8]。
Neck中使用了特征金字塔网络(Feature Pyramid Networks,FPN)和路径聚合网络(Path Aggregation Network,PAN)相结合的结构[9-10]。FPN自顶向下通过下采样将高阶的强语义特征和低层的位置信息融合,而PAN自底向上通过上采样将低层的强定位特征传递到高层,最终实现高层特征与底层特征相互融合和相互补充,丰富了模型的分类和定位能力。
Head中使用三个Detect检测器分别对不同尺寸的特征图进行检测,确保了网络对大目标和小目标都有不错的检测效果。
1.1.2 YOLOv5融合膨胀卷积模块
膨胀卷积(Dilated Convolution)通过在标准的卷积核中注入空洞增加模型的感受野[11]。相比常规的卷积操作,膨胀卷积通过膨胀率控制卷积核的膨胀程度。感受野的计算公式如下:
RFi=RFi-1+(k-1)×s
(1)
其中,RFi是当前感受野,RFi-1是上一层感受野,k是卷积核的尺寸,s是步长。
本文使用膨胀率为3和5、卷积核大小为3×3的膨胀卷积对特征图进行卷积操作,然后将两个输出特征图拼接构成膨胀卷积模块(Dilated Convolution Module,DCM),如图2所示。目标检测为了保证感受野需要依靠下采样,但是下采样会导致图像的位置信息丢失,因此本文在YOLOv5中SPPF(Spatial Pyramid Pooling Fast)层后添加一个该模块的分支,并将输出特征图送入第三个Detect检测器,以此丰富不同感受野的上下文信息。

图2 膨胀卷积模块Fig.2 Dilated convolution module
1.1.3 改进边界回归损失函数
YOLOv5使用CIoU作为衡量边框损失的函数,如公式(2)和公式(3)所示,b和bgt分别代表预测框和真实框,IoU为预测框和真实框的交并比,ρ2(b,bgt)表示预测框与真实框中心点的欧式距离,c表示预测框与真实框的最小外接矩形的对角线距离。
(2)
(3)
ZHANG等[12]在CIoU的基础上提出了EIoU损失函数。EIoU不仅考虑了CIoU已经涉及的重叠面积和中心点距离的影响,还考虑了边长的影响,表达式如下:
LEIoU=LIoU+Ldis+Lasp
(4)
cw和ch是包含预测框和真实框的最小闭包区域的宽度和高度,w和wgt表示预测框与真实框的宽度,ρ2(w,wgt)表示预测框与真实框宽度的欧式距离,h和hgt表示预测框与真实框的高度,ρ2(h,hgt)表示预测框与真实框高度的欧式距离。
GEVORGYAN[13]提出了SIoU损失函数,SIoU考虑了角度损失、距离损失、形状损失和IoU损失。角度损失的示意图(图3)和表达式如下:

图3 角度损失图Fig.3 Diagram of angle cost

(5)
(6)
(7)
(8)

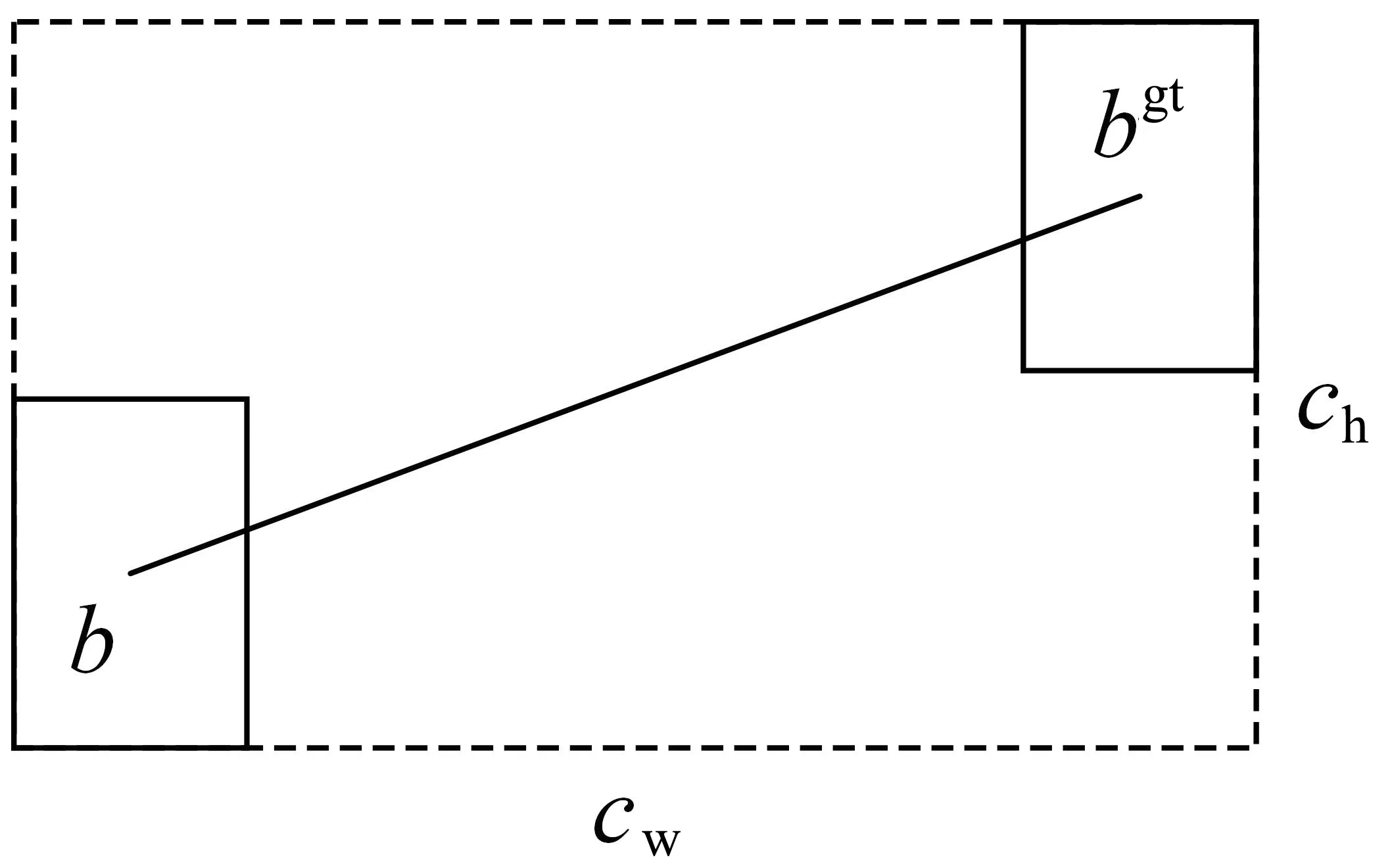
图4 形状损失图Fig.4 Diagram of shape cost
(9)
(10)
其中,Ω为形状损失,θ为超参数,w和h为预测框的宽和高,wgt和hgt为真实框的宽和高。距离损失的表达式如下。
(11)
(12)
其中,Δ为距离损失,cw和ch为预测框和真实框的最小外接矩形的宽和高。最终SIoU损失函数表达式如下:
(13)
本文分别使用EIoU和SIoU替换原始的CIoU,并在相同数据集中进行实验验证。
1.2 ResNet
1.2.1 ResNet模型结构
相较于LeNet和VGG等相对浅层的网络,ResNet使用了残差块结构,如图5所示,该结构将特征矩阵X进行卷积得到F(X),然后通过shortcut(短接)分支传递特征矩阵X,再将X和F(X)相加后进行激活[14-15]。ResNet网络解决了网络过深时的梯度爆炸和梯度消失的问题,使得网络层数可达百层。
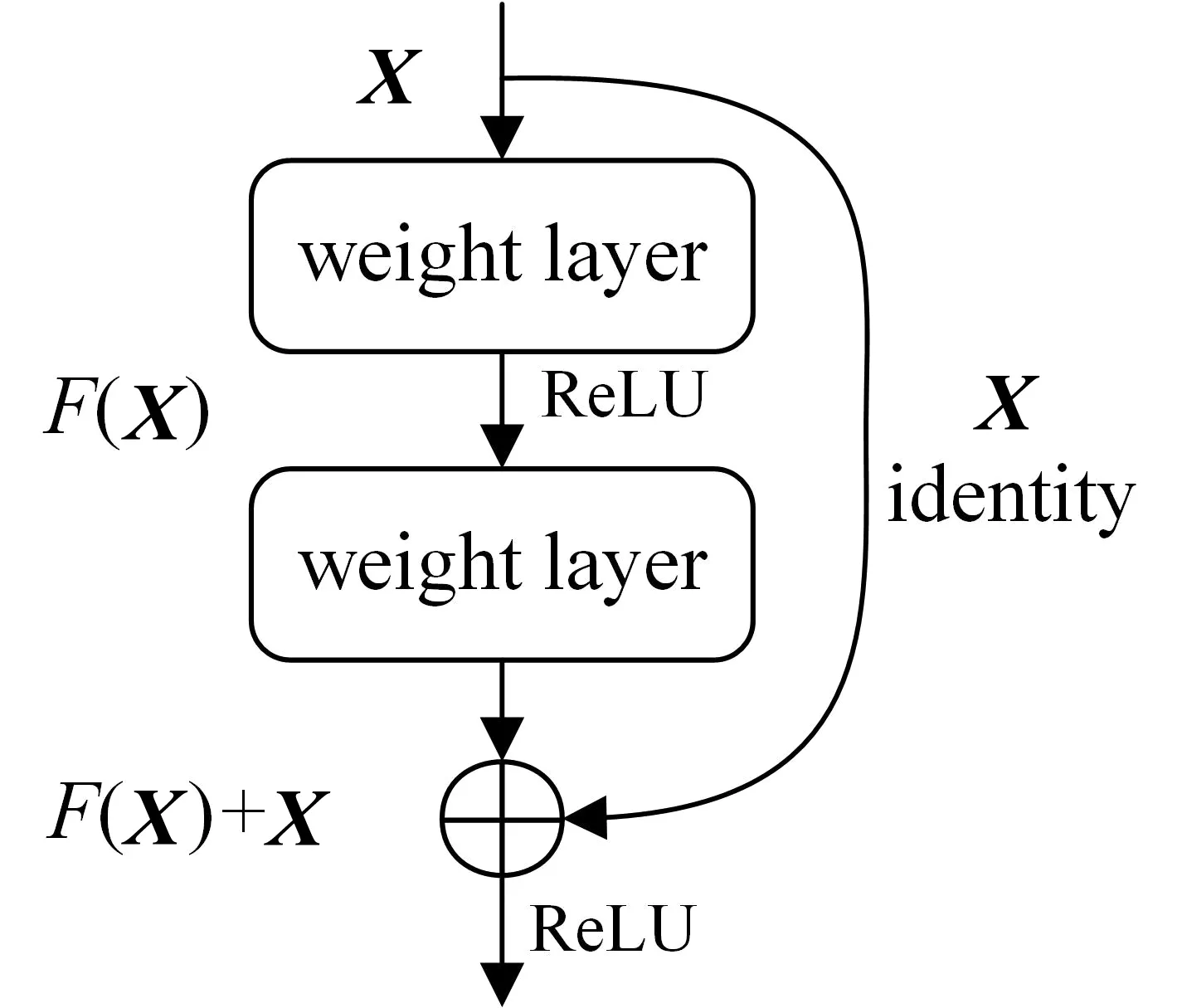
图5 残差块结构图Fig.5 Residual block structure diagram
本文基于ResNet18卷积神经网络实现分数识别,该网络主要由基本残差块组成。图6(a)为基本残差块Ⅰ,它包含一条直线路径和一条跳跃路径。直线路径由两个3×3的卷积层和两个批量归一化(Batch Normalization,BN)层组成,中间使用ReLU函数激活。跳跃路径则直接将输入特征图与直线路径的输出相加。最后将相加结果通过ReLU函数激活后输出。图6(b)是基本残差块Ⅱ,它和普通残差块结构相似,区别是跳跃路径增加了一个1×1的卷积层和一个BN层,用于对输入特征图进行下采样。

(a)基本残差块Ⅰ

(b)基本残差块Ⅱ
ResNet18结构如图7所示,输入图像先进行7×7的卷积和最大池化操作,然后经过8个基本残差块进行特征提取,最后经过平均池化和全连接输出预测概率。

图7 ResNet结构图Fig.7 The structure diagram of ResNet
1.2.2 ResNet融合注意力机制
当我们看到一张图像时,大脑会优先注意到图像中的重点信息,因而可能会忽视其他部分。注意力机制就是模仿人类大脑处理图像信息产生的,其可以使网络自动关注到一些重点区域。
卷积注意力模块(Convolutional Block Attention Module,CBAM)是一种轻量的注意力模块,结构如图8所示,其包括通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)[16]。本文将CBAM融合到ResNet网络中,在网络的第二层和倒数第二层加入CBAM,以此提高该网络在通道和空间上的特征提取能力。

图8 CBAM结构图Fig.8 The structure diagram of CBAM
2 实验(Experiment)
2.1 数据集
本文所采用的试卷扫描图像示例如图9所示,试卷包含一种特殊的分值框,该分值框由两个部分组成,上半部分是可识别出题号信息的二维码,下半部分可供老师填写分数。除此之外,可通过试卷左上角的二维码识别学生的学号信息,这样可将学生的学号、题号和分数信息关联起来。本文共使用1 000张以24位、150×150 dpi格式保存的浙江理工大学若干课程试卷扫描图像作为数据集,并按照1∶1的比例将其随机分为训练集和验证集。

(a)试卷第1页

(b)试卷第2页图9 试卷扫描图像
2.2 实验环境
本实验所使用的CPU为Intel(R) Core(TM) i5-10400 CPU @ 2.90 GHz,操作系统为Ubuntu 20.04,GPU为 NVIDIA GeForce GTX1060,软件环境为Pytorch1.12和Python3.7等。
2.3 分值框识别结果
为了选择性能更好的IoU损失函数,在YOLOv5网络中基于相同数据集分别使用CIoU、EIoU和SIoU对模型进行训练,结果如表1和图10所示,其中mAP@0.5∶0.95表示IoU从0.5一直取值到0.95,每隔0.05计算一次mAP的值。从图10中可以看出,相较于CIoU,EIoU和SIoU的收敛速度更快且EIoU和SIoU在mAP@0.5∶0.95指标上分别比CIoU高了1.1%和1.0%,因此最终选择EIoU作为边界框的损失函数。

表 1 不同IoU的实验数据
为了验证膨胀卷积模块(DCM)的有效性,研究人员又使用了相同数据集分别对原始YOLOv5和融合膨胀卷积模块的YOLOv5进行实验,并采用mAP@0.5∶0.95作为评价指标,结果如表2所示,YOLOv5-EIoU-DCM组合相较于YOLOv5-CIoU组合和YOLOv5-CIoU-DCM组合分别有1.7%和1.1%的提升,证明了该模块的有效性,因此使用该组合对试卷图像中的分值框进行识别,试卷的识别效果如图11所示。
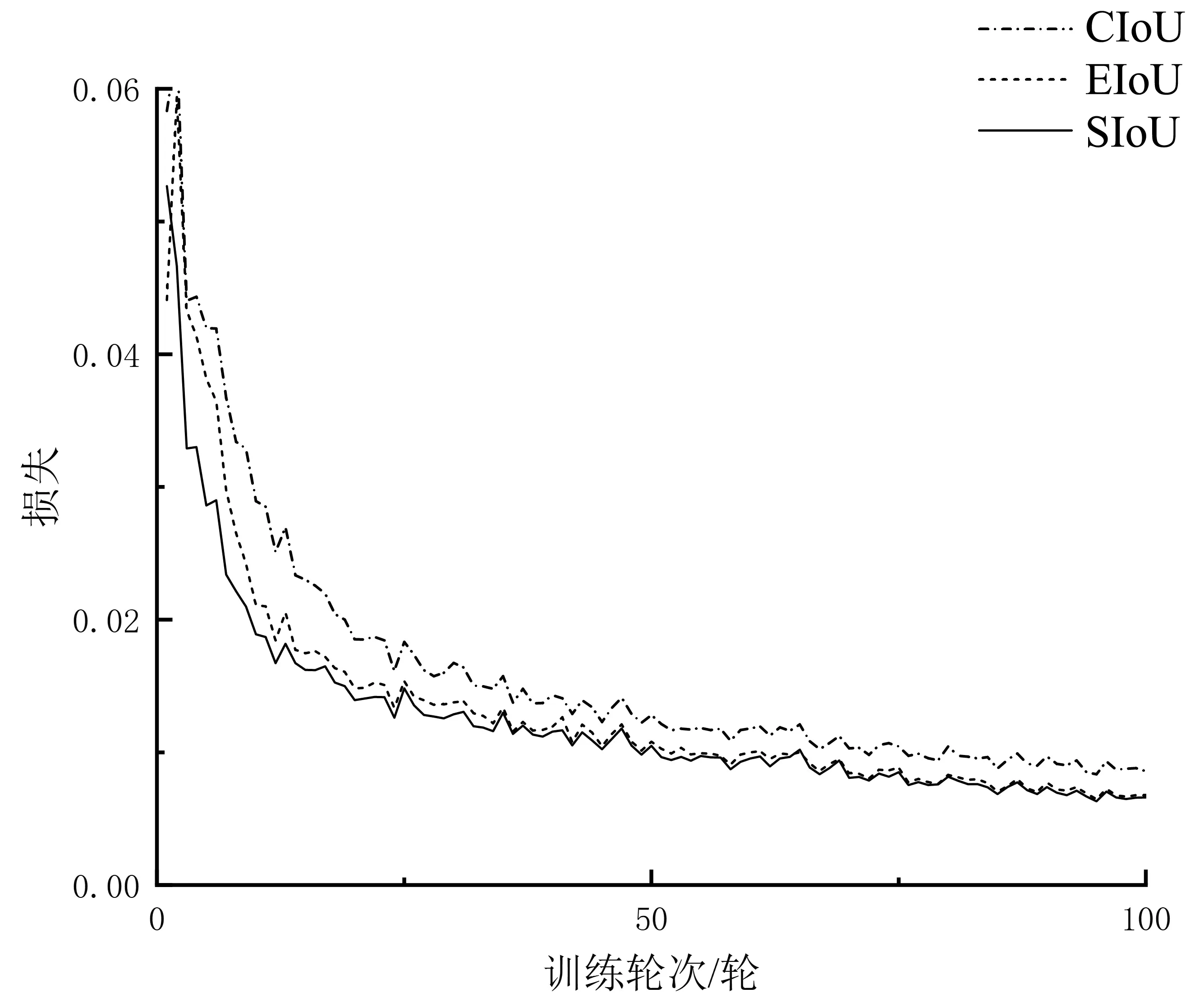
图10 不同IoU方法的损失曲线Fig.10 Loss curve of different IoU methods

表 2 YOLOv5实验数据

(a)试卷第1页

(b)试卷第2页
2.4 分数识别结果
本文使用ResNet卷积神经网络对试卷中分数进行识别。图像共有11个分类,即0~9共计10个分类和空白分类。因为手写数字总是会有一些倾斜角度,并且扫描的试卷难免会有一些噪声,所以需要对图像进行预处理,将图像在(-30°,30°)内随机旋转一定角度,并添加了10%的椒盐噪声。实验结果如表3所示,相较于原始的ResNet网络,融合了CBAM的ResNet网络虽然FPS(帧率)降低了6.6%,但是准确率提高了0.4%。

表 3 ResNet实验数据
2.5 实验结果与分析
为了验证改进后网络的识别效果,研究人员分别使用4种不同的网络组合对试卷扫描图像进行识别。结果如表4所示,相较于原始的YOLOv5-CIoU与ResNet的组合,YOLOv5-EIoU-DCM与ResNet-CBAM的组合虽然FPS降低了约7.7%,但准确率提高了2.2%,证明了改进模型的有效性。
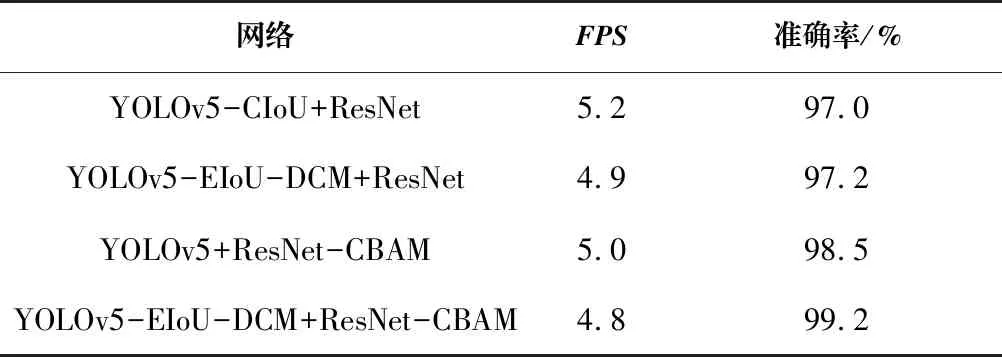
表 4 实验结果数据
3 结论(Conclusion)
针对试卷分数的统计问题,本文采用一种带有特殊分值框的试卷,并提出一种基于改进卷积神经网络的分数识别方法。该方法首先基于YOLOv5目标检测算法对试卷中的分值框进行定位,然后基于ResNet卷积神经网络对分数进行识别。研究人员在YOLOv5中引入了膨胀卷积模块并优化调整了边框损失函数,相较于原始的YOLOv5,YOLOv5-EIoU-DCM组合在mAP指标上有1.7%的提升。此外,本文研究将CBAM融入ResNet中,相较于原始ResNet,融合了CBAM的ResNet准确率有0.4%的提高。最终结果表明,改进模型对题目分数的识别率更加优秀,识别准确率为99.2%,可以准确且高效地识别试卷图像中的分数。
