面向机器学习的知识图谱与问答系统设计
2023-08-09黄宇皓


摘 要:作为一种结构化的语义知识库,知识图谱近年来被多个领域所应用,然而在机器学习这一专有领域仍存在空缺。文章描述了如何构建一个面向机器学习领域的知识图谱,并基于该图谱设计了一个问答系统。在图谱的构建过程中,主要使用了爬虫技术以及部分 NL.P 方法对数据进行采集和处理,最终得到1个包含2442 个实体的知识图谱,并将其存储在 Neo4i 图数据库中。针对间答系统设计部分结合基于规则正则匹配以及基于词向量相似度匹配的方法,构建了问答模块。该领域图谱的构建和问答系统的设计,将使研究人员和爱好者更轻松地获取高质量的机器学习领域的知识。
关键词:知识图谱:问答系统;机器学习
中图法分类号:TP18文献标识码:A
1 引言
知识图谱的起源可追溯到20 世纪30 年代,但其正式概念是由Google 于2012 年提出的。它被描述为一个提供智能搜索服务的大型知识库,可以将独立的知识以三元组的形式形成语义知识的一种形式化描述框架,形式化地描述真实世界中各类事物及其关联关系[1] 。领域知识图谱是特定领域应用的知识图谱,在金融、军事、医疗等多个领域都得到了应用,如IBMWatson Health 医疗知识图谱[2] 。由于知识图谱的结构化程度高且知识质量高,基于知识图谱的问答系统越来越受到人们的青睐,它弥补了传统问答系统检索效率低和检索知识质量不高的缺点。
如今,机器学习的热度不断上升,然而当前机器学习领域图谱的开发仍处于空白阶段。为了使机器学习专有领域的知识能够形成一个结构化的语义网络,以及为机器学习领域的相关研究提供便利,本文将介绍机器学习领域图谱的构建过程,并基于图谱设计一个问答系统。
2 基本技术概述
2.1 知识图谱构建理论
知识图谱的构建通常包含知识抽取、知识融合、知识加工和知识更新等步骤[3] 。获取相关语料后,需要对语料进行预处理,然后进入知识抽取环节。知识抽取主要包括实体识别、关系抽取以及属性抽取3 类任务。实体识别用于识别文本中的特殊实体,关系抽取用于从文本中识别实体之间的关系,属性抽取用于从文本中提取实体的属性。
这些任务的完成早期依赖于专家手工定义规则,而基于机器学习方法的技术现在更为实用。本文主要使用基于机器学习的方法进行知识抽取,同时使用了OCR 技术以及爬虫技术。在知识融合阶段,主要工作有实体对齐、实体消歧,本文通过基于机器学习的方法来完成这些任务。完成上述工作后,需要将知识图谱数据存储到数据库中。根据存储方式的不同,知识图谱通常可以存储在RDF 数据库、关系型数据库或者图数据库中。本文使用Neo4j 图数据库对知识图谱进行存储[4] 。
2.2 基于知识图谱的问答系统设计理论
构建基于知识图谱的问答系统通常有3 种方法:基于模板匹配;基于语义解析;基于向量建模[5] 。本文将结合基于规则正则匹配的方法和基于Word2Vec向量建模的方法,提升智能问答的应答率、准确率。
3 机器学习领域图谱构建
本文采用自底向上的框架构建机器学习领域的知识图谱,基本流程如图1 所示。
3.1 数据采集
构建知识图谱首先需要收集相关语料。为了保证实体词的专业性,本文参考了机器之心团队编写的专有术语库,其中收纳了2 442 个机器学习专有领域的术语,这些术语来源于领域专家以及权威教科书等,并经过了校对等工作,具有较强的专业性与公信力。本文以这些术语为基础,建立关键词表,并将其作为图谱的实体词库。
以实体词库中的专业词汇为关键词,利用网络爬虫技术从万方、维普数据库中获取了23 579 篇包含这些关键词的期刊文献,并使用request 库、BS4 库等工具对每个实体词的百度百科词条以及维基百科词条进行爬取,在后续知识抽取的步骤中会对这些数据进行进一步处理。
3.2 知识抽取
知识抽取工作共分为3 个部分:实体识别、关系抽取和属性抽取。实体识别部分首先采用OCR 技术,对采集的23 579 篇领域期刊文献进行文本的提取,文本使用Stanford CoreNLP[6] 进行实体识别,借助构建好的实体词库进行筛选,并进行数据清洗、语句分词、去停用词等工作,过滤出与实体词相关的语料。针对关系抽取部分,本文采用上下位关系来表示实体之间的关系。上下位关系即包含与被包含的层级关系,即一个概念或实体(上位词或父类)包含另一个概念或实体(下位词或子类)的关系。例如,“机器学习”为一级实体节点,“神经网络”作为二级实体节点是“机器学习”这一实体的分支,可以作为其下位词。本文使用Stanford CoreNLP 对实体识别中过滤好的语料进行依存句法分析,提取出实体词之间的上下位关系。
针对属性抽取部分,首先抽取所有实体词的基础属性。基础属性从先前爬取的百度百科即维基百科语料中进行抽取, 其主要包含名稱( name)、定义(definition)、应用(application)。对于实体词中的具体算法或算法分支,它们通常为4 级节点或更低层级的节点,除基础属性外还添加了“期刊属性”,将以该节点为关键词的专业期刊数据收录到属性中,其主要包含标题(title)、发表时间(date)、作者(author)、摘要(abstract)。
3.3 知识融合
在知识融合阶段,实体消歧任务是本文的主要工作。知识图谱中,实体词有可能出现实体二义性,即一个实体可能在不同语境下代表的意思不同。例如,bias(偏差)在统计学和机器学习中通常指预测值与实际值之间的差距,但在其他上下文中也可能指偏见或倾向。
为解决歧义问题,本文采用基于知识库链接的实体消歧方法,这种方法通过将自然语言文本中的实体链接到实体词库中对应的实体来消除歧义。CN?DBpeida 提供了Mention2Entity 数据集,其含有大量歧义词的字典,可以用来解决歧义问题[7] 。
3.4 图谱入库
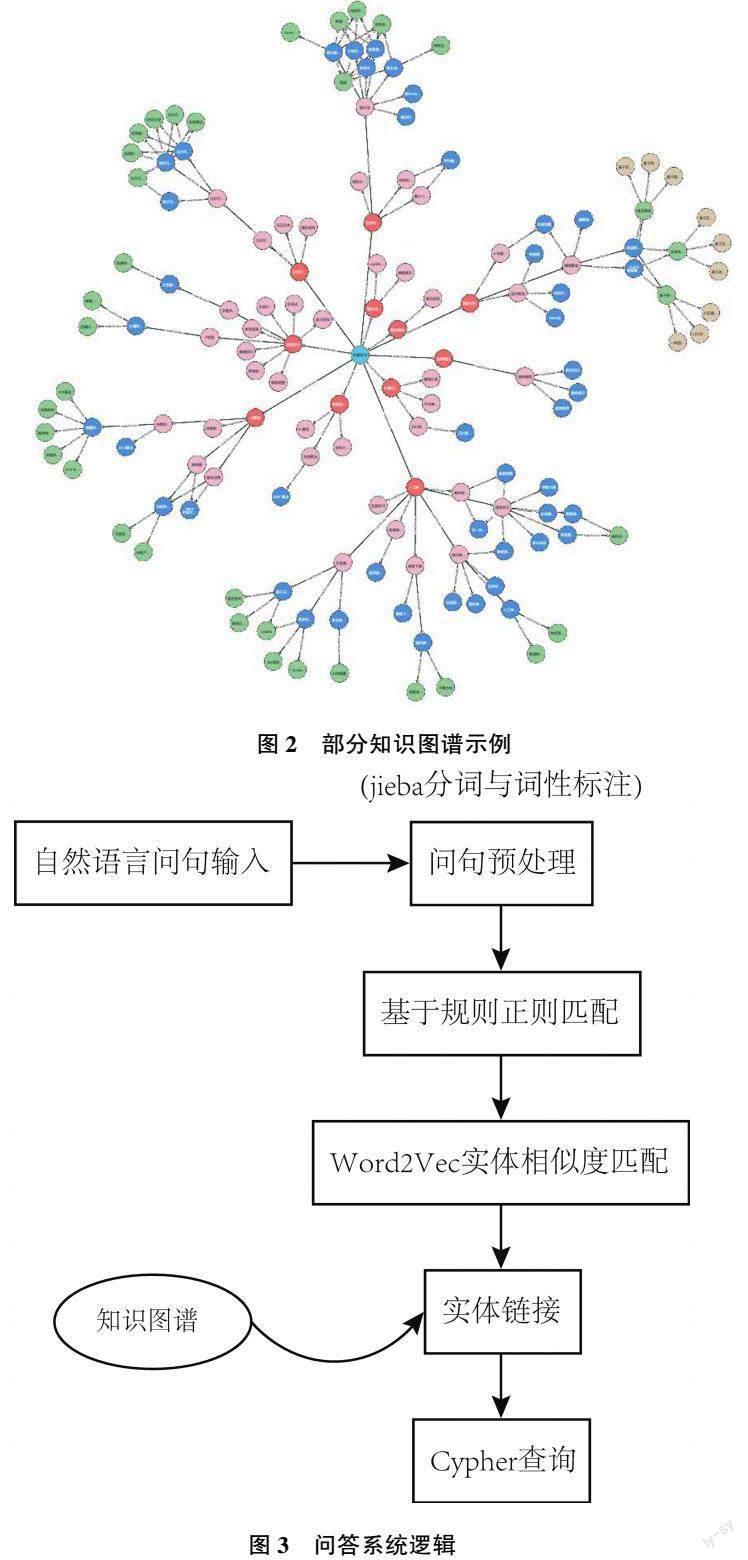
对于知识图谱的存储,本文使用图数据库Neo4j进行存储入库。Neo4j 将图作为数据结构,充分利用了图数据结构的特性,使用图节点、边、节点属性与边属性来表示数据,并将Cypher 作为数据库查询语言。经过3.1~3.3 节的处理后,可以得到关于实体词库中2 442 个节点“实体?边?实体”的三元组数据,其已经储存了节点属性的数据文件,通过py2neo 库将这些数据批量导入Neo4j 数据库,即完成了知识图谱的存储。存储完毕后,随机抽取200 组实体关键词并对其进行查询,均成功返回结果,平均返回时长为269 毫秒,响应速度快。部分知识图谱示例如图2 所示。
4 问答系统设计
基于构建好的机器学习领域图谱,设计一个问答系统,旨在帮助研究人员和机器学习爱好者更轻松地获取高质量的机器学习领域知识。问答系统设计逻辑如图3 所示。
4.1 问句预处理
用户输入自然语言问句后,需要提取问句的语义信息,以及进行命名实体识别工作。在本问答系统中,将jieba 库作为解决方案。jieba 库是一个中文分词工具库,使用Python 实现,支持自定义词典,可以根据实际需求添加或删除一些自定义词汇,以便更好地满足特定领域的分词需求。通过jieba 库对用户输入的自然语言问句进行分词,并提取其中的命名实体,可以获取更准确的语义信息。
4.2 意图识别与答案推理
对于问句的意图识别,本系统结合了基于规则集的方法以及向量相似度匹配。问句预处理得到分词与词性标注结果后,进行实体的关键词抽取,首先采用基于规则集的方法,对问句进行正则匹配,若成功匹配,则说明问句在预设规则库中,可以直接根据规则模板将原本的自然语言问句转换为Cypher 查询语句,进而链接到Neo4j 数据库中并推理得到问题答案。部分规则集示例如表1 所列。
然而,仅使用规则模板库来理解用户输入问句的成功率非常低。如果未匹配到规则集,系统将采用向量相似度匹配。本系统使用Word2Vec 模块来实现这一点。Word2Vec 是一种双层神经网络词向量模型,可以将词映射为一个向量来表示词间联系,映射的向量为神经网络中的隐藏层[8] 。若输入问句不能匹配规则集,则使用预训练的词向量模型计算问句与知识库中问题的相似度,本文调试时使用余弦相似度计算,匹配得到与问句最相似的问题,并链接Neo4j 数据库,最终得到答案。
4.3 结果分析
对每类问题,设置了100 道测试问句,对问答系统进行测试,测试结果如表2 所列。
对于实体信息类、属性信息类以及应用信息类问题,可以发现应答率和准确率较高;而对于比较信息类问题,应答率和准确率显著下降。
5 结束语
本文通过网络爬虫、NLP 等技术构建了一个机器学习专有领域的知识图谱,并基于该图谱设计了一个问答系统,为机器学习的研究者和爱好者提供了一个快速、准确查询领域知识的平台。然而构建的图谱在时效上具有局限性,由于缺乏知识更新的手段,无法获取最新的专业术语以及期刊信息,需要每隔一段时间进行人工更新工作。另外,设计的问答系统对于处理逻辑较强的问题效果欠佳,可以考虑引入更强大的语义理解模型,以提高系统的应答率与准确率。
参考文献:
[1] 田玲,张谨川,张晋豪,等.知识图谱综述———表示、构建、推理与知识超图理论[J].计算机应用,2021,41(8):2161?2186.
[2] IBM. Watson Health 医疗保健数据分析的重要性[EB/OL]. https: ∥ www. ibm. com/ cn?zh/ watson?health/ learn/healthcare?data?analytics.
[3] SINGHAL A. Introducing the knowledge graph: things, notstrings [EB/ OL].https:∥www.blog.google/ products/ search/introducing?knowledge?graph?things?not/ .
[4] Neo4j.Neo4j[DB/ OL].https:∥neo4j.com/ .
[5] 袁博,施运梅,张乐.基于知识图谱的问答系统研究与应用[J].计算机技术与发展,2021,31(10):134?140.
[6] MANNING C D,SURDEANU M,BAUER J,et al.The StanfordCoreNLP natural language processing toolkit [ C ] ∥Proceedings of 52nd annual meeting of the association forcomputational linguistics:system demonstrations.2014:55?60.
[7] XU B,XU Y,LIANG J,et al.CN?DBpedia:A never?endingChinese knowledge extraction system [ C] ∥ Advances inArtificial Intelligence: From Theory to Practice: 30thInternational Conference on Industrial Engineering and OtherApplications of Applied Intelligent Systems,IEA/ AIE 2017,Arras,France,June 27?30,2017,Proceedings,Part II.Cham:Springer International Publishing,2017:428?438.
[ 8 ] RONG X. WORD2VEC PARAMETER LEARNINGEXPLAINED [ EB/ OL]. HTTPS: ∥ ZHUANLAN. ZHIHU.COM/ P/183161311.
作者简介:
黄宇皓(2001—),本科,研究方向:大数据分析。
