考虑微震前兆特征的CNN-GRU冲击危险性分析模型
2023-08-04李海涛张海宽齐庆新
李海涛,张海宽,齐庆新
(1.煤炭科学研究总院有限公司 深地科学研究院,北京 100013;2.煤炭资源高效开采与洁净利用国家重点实验室,北京 100013)
煤矿冲击地压具有发生突然、破坏猛烈的特点[1-4],会造成巷道大范围破坏甚至人员伤亡,是对于煤矿安全生产威胁最为严重的灾害之一,基于可靠数据提升冲击危险性预测的准确性,对于有效防治冲击地压具有十分重要的意义。目前,学者们主要通过将多类型数据进行权重融合[5-11]以实现对于目标区域危险性的评价。
微震监测以其较大的空间覆盖能力和相对高质量的监测数据,为煤矿冲击危险性分析预测提供了可靠的支撑[12-14]。在对矿井中危险灾害的分析和预测研究方面,相关研究利用微震监测数据的时序、地点、能量和应力等数据对机器学习算法或其他算法进行训练,然后预测矿井中的危险灾害。窦林名等[15]以微震为主,通过选取冲击变形能、时序集中度、时空扩散性等13 个监测预警指标,搭建了集成微震、应力、钻屑等多种监测手段的冲击矿压风险智能判识与多参量监测预警云平台;YIN 等[16-17]利用应力、扭矩、体积、应力变化等微震监测数据基于集成算法和神经网络算法对冲击地压的预测进行了研究,并取得了较好的效果。相关矿井中危险灾害分析和研究很少考虑危险灾害的前兆信息、时空特性和发生机理等信息,且多数矿井中仅有时序、地点和能量等监测数据,这些方法无法在实际工程中广泛使用。
基于微震监测数据对矿井中冲击地压发生机理的研究中,学者们通过对矿区整体微震活动时空分布特征的研究认为微震参数的变化规律可作为预测地压灾害的前兆特征[18]。袁瑞甫等[19]研究了煤柱型冲击地压微震信号分布特征后,总结了冲击地压发生前有一段微震活跃期、静默期、和发生地点集中等冲击地压发生的前兆信息。相关机理研究可以为分析和预测方法中数据集特征的建立提供一定依据,从而提高基于机器学习算法对矿井中危险灾害的分析预测的准确率和泛用性。
与冲击地压对应的微震事件样本量极为有限,而常规微震事件虽然样本体量大,但往往缺乏训练标签,均无法支撑机器学习模型的应用。为此,通过跟踪某矿井微震事件及其对应的矿压显现特征,并将能够产生明显震感或动力显现特征的微震事件标注为“危险事件”,以此获得含标签的大体量微震数据集;并进一步针对无法准确判定某次微震事件危险性的问题,考虑冲击地压的发生机制和前兆信息,基于深度学习模型提出了分析矿井中微震危险性的方法。该方法主要分为3 个步骤:选取分析特征;建立数据集和处理不平衡样本;训练和测试基于深度学习的分析模型,将该模型用于分析某矿井微震监测数据取得了较好的效果,同时大量实验验证了该模型具备了较好的泛化能力。
1 算法框架
考虑冲击地压的前兆信息,基于CNN-GRU 模型(卷积神经网络[20]-门控循环单元模型[21])提出了利用微震监测数据分析冲击危险性的方法(卷积神经网络-门控循环单元模型)。
1.1 建立分析指标
由于多数矿井微震监测数据的特征主要包括时间、地点、能量,因此考虑冲击地压发生的前兆信息[15,18-19],建立了微震事件的时序集中度、2 次微震事件时间间隔、空间密集度、能量和能量集中度5 个分析特征。
根据相关研究,冲击地压等矿井动力灾害发生前有一段明显的微震活跃期,这是因为围岩正在与外界发生能量交换,围岩结构处于非稳态的调整期,这一性质用时序集中度表示为:

在大能量的危险事件发生前,微震活动会出现较短的平静时期,一般称为静默期,但不同危险事件的静默期长短相差较大,静默期可用本次微震时间与上次微震时间间隔表示ΔT。
微震事件的空间分布与微裂隙在岩体内部空间的发生发展过程相对应,因此分析微震事件的空间分布规律变化对于了解岩体稳定性有重要作用,在冲击地压等危险事件发生前微震的空间密集度会明显上升,可表示为:

矿山中冲击地压的发生时,巷道周围围岩体中的压力由稳态增加至极限值,会造成岩体内能量突然释放,能量是分析矿山冲击地压等危险事件的重要特征。同时,建立了能量集中度指标来反映冲击地压发生前的能量变化和微震分布情况,计算公式如下:

由于几种监测数据的数值大小不一,在分析指标建立之后需对能量指标进行标准化进行处理,公式为:
式中:xi、yi为标准化处理前后的第i 个数据值;n 为监测事件总数。
1.2 数据集
对数据集建立和处理步骤为:①根据分析特征和微震监测事件的危险性建立初始数据集;②在时间尺度上将初始数据集分为训练集、验证集和测试集;③对分割后的每个数据集进行样本不平衡性的处理。上述步骤的顺序和处理方法不可改变,如果对样本的不平衡处理出现在分割数据集之前,或不在时间尺度上而是随机分割数据集,会出现模型在训练集或验证集上效果极好,但在真实数据的测试集上效果极差的现象。
分析框架中的数据集以根据微震监测数据建立的分析特征为数据集特征,以微震事件的危险性作为标签建立数据集。考虑到各个监测数据的数量级不同,需对数据进行标准化处理,训练模型中使用的损失函数为交叉熵,因此对标签进行One-Hot 编码处理。
对于不同矿井或同一矿井的不同开采地点,微震监测数据对应的地质环境是不同的,部分冲击地压等危险事件的分析模型在测试集上效果很好却很难直接应用。因此,为模拟现实工程的直接应用情况,本框架将数据集在时间尺度上分为训练集、验证集和测试集3 个部分,将训练集数据输入到模型中进行训练,在验证集上对训练的结果进行评价,选取性能最好的模型直接应用到测试集中验证模型的泛化性能。
开采过程中危险事件对应的微震监测数据数量要远远小于不危险事件,所以在训练模型之前需要处理不平衡数据。目前,从数据角度出发的不平衡数据处理方法主要有采样和数据合成方法。其中采样可分为从少数类样本中随机采样来增加新的样本的上采样方法和从多数类样本中随机选择少量样本,再合并原有少数类样本作为新的训练数据集的下采样方法。数据合成方法是利用已有样本生成更多样本,这类方法在小数据场景下有很多成功案例,其方法包括合成少数类过采样技术(SMOTE[22])和自适应合成方法(ADASYN[23]),SMOTE 算法的对少数类样本进行分析并根据少数类样本通过人工合成新样本然后添加到数据集中,其改进算法包括Borderline-SMOTE[24]等;ADASYN 主要思想是根据数据分布情况为不同的少数类样本生成不同数量的新样本。根据对矿山微震监测数据的研究,矿山监测数据中危险事件分布位置呈现分散且分布于非危险事件之间的特点,因此主要使用对采样数据添加扰动的上采样方法处理不平衡数据集。
1.3 CNN-GRU 联合神经网络
近些年来卷积神经网络(CNN)在图像视觉领域取得了巨大的成功,CNN 是1 个深度学习框架,其灵感来自于猫的大脑视觉皮层[25]。CNN 的体系结构可以有所不同,通常由几个卷积层、激活层组成,在计算机视觉领域一般也包含池化层或全连接层,其作用是保证卷积神经网络模型对图片分类任务的平移不变性,由于每组数据有限,因此构建的CNN 结构中只有卷积层和激活层。卷积层的作用是提取数据中的代表性特征,多个卷积核存在于1 个卷积层中,也被称为滤波器。该滤波器类似于1 个滑动窗口,它在数值矩阵中以特定的步幅来回移动。在对滤波器和数值矩阵进行卷积运算后,可以得到图像的初始特征图,并将其发送到卷积层的激活函数中。卷积核运算示意如图1。

图1 卷积核运算示意Fig.1 Schematic diagram of convolution kernel operation
通常在特征提取之后会引入正则化方法,来加快网络训练和收敛速度,防止模型梯度爆炸和过拟合,目前主流方法有批正则化[26](Batch Normalization)和Dropout[27]方法。将提取的特征输入到激活函数中来为卷积神经网络中加入非线性因素,卷积神经网络模型(CNN)中使用的激活函数为Relu[28]函数,其公式如下:
循环神经网络(RNN)对于序列数据的处理拥有巨大的优势,因为其实一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。长短期记忆网络(LSTM)[29]和门控循环单元(GRU)[21]是循环神经网络(RNN)的主要变种(目前也有学者认为GRU 是LSTM 的变种),考虑到参数的数量和计算效果,在构建模型中选取门控循环单元(GRU)。
单个门控循环单元(GRU)结构如图2。
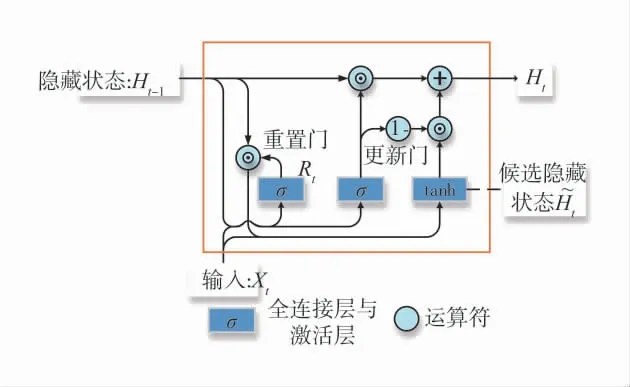
图2 门控循环单元结构Fig.2 Door control cycle unit structure
重置门和更新门的输入均为当前时间步输入Xt与上一时间步隐藏状态Ht-1,输出由激活函数为Sigmoid 函数的全连接层计算得到。Sigmoid 函数、重置门Rt和更新门Zt的计算如下:
式中:Wxr、Wxz、Whr、Whz为权重参数;br、bz为偏差参数;h 为隐藏单元个数;Xt为给定时间步t 的小批量输入;Ht-1为上一时间步的隐藏状态。
将当前时间步重置门的输出与上一时间步隐藏状态做元素乘法(符号为⊙)。如果重置门中元素值接近0,那么意味着重置对应隐藏状态元素为0,即丢弃上一时间步的隐藏状态。如果元素值接近1,那么表示保留上一时间步的隐藏状态。然后,将按元素乘法的结果与当前时间步的输入连结,再通过含激活函数tanh 的全连接层计算出候选隐藏状态,其所有元素的值域为[-1,1]。具体来说,tanh 激活函数和时间步t 的候选隐藏状态的公式为:

随着计算机视觉相关研究的发展,卷积神经网络(CNN)和循环神经网络(RNN)的联合神经网络(CNN-RNN)在图像字幕领域取得了较大进展,其主要通过卷积神经网络对图像的空间结构和相关信息进行特征提取,然后将提取的特征输入到RNN 网络中生成对应图片信息相关的解释。受图像字幕领域的神经网络结构启发,对于微震数据相关特征的分析首先利用卷积神经网络对分析特征进行信息提取和信息融合等操作,然后以提取的特征作为初始隐藏状态,将分类特征作为输入参数。
建立的CNN-GRU 联合卷积神经网络,主要由5 层卷积神经网络层、5 个门控循环单位结构和2 层全连接层构成,由于输入的分析特征尺寸较小所以设计的模型较为简单且卷积神经网络中没有pooling 层,该模型在实验中取得效果最好。在CNN 模型输入中可将4 个分析特征视为4 个特征或1 个特征的4 个数据,主要使用前者输入,CNN 模型结构中1×1 卷积主要起到信息升维度和跨通道融合的作用,3×3 和2×2 卷积主要起到增加同一通道的信息交流的作用。即使增加模型的层数也不会提升模型在测试集上的效果,且会出现网络退化现象,即层数增加反而导致模型的训练效果和测试效果均下降。参考ResNet[30]和DenseNet[31]网络结构,即使模型加入恒等映射,在测试集上的效果也未提升。
2 实例应用
使用某煤矿矿井的微震监测数据对建立的分析框架进行验证,该微震监测数据包括从2017 年1 月到2018 年7 月的13 583 条数据,监测内容包括微震发生时间、地点和能量,在13 583 条数据中强震动对应的危险事件数量为114。首先根据微震监测数据计算时序集中度、空间密集度、时间间隔和能量作为数据集特征,以是否发生危险事件作为标签,然后在时间尺度上按照50%、20%和30%的数量将数据集划分为训练集、验证集和测试集。时序集中度和空间密集度需要根据前n 次微震事件的数据进行计算,取n=1,2,…,30,建立30 组数据集。为模拟模型的直接应用情况,然后对训练集和验证集的联合数据集、测试集分别数据不平衡处理,使测试集的数据不与其他数据集有交叉,考虑到对危险事件预测的重要性设定了3 个测试集,分别为单独危险事件的测试集、单独不危险事件的测试集和混合事件测试集,混合事件测试集中使用上采样加扰动的方法使两种事件的样本数量几乎相同。使用CNN-GRU模型计算,需要计算的参数为3 446 个,模型中使用Adam 优化器和Cross Entropy Loss 损失函数,学习率为0.01。最后将处理的数据输入到CNN-GRU 模型中,得到的30 组计算结果如图3。
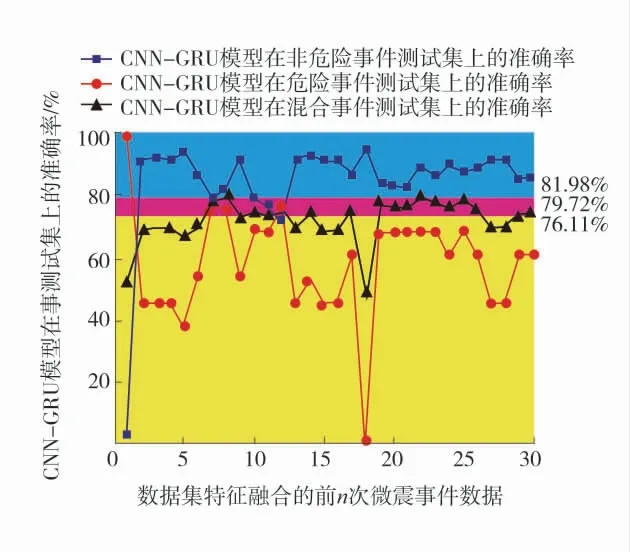
图3 CNN-GRU 模型在融合前n 次微震事件数据的测试结果(n=1,2,…,30)Fig.3 Test results of n microseismic event data of CNN-GRU model before fusion(n=1,2,…,30)
通过计算结果可以看出,模型在不同数据集上达到最高准确率时,所对应的n 不同:①当n=8 时模型在混合事件测试集上取得最佳效果,准确率为79.72%,该模型在危险事件数据集上准确率为81.98%,在非危险事件测试集上准确率为76.11%,此时模型在验证集准确率为79.05%(因验证集和测试集都未参与训练,所以模型在测试集上的准确率高于验证集是合理的),这与模型在混合测试集上的准确率相近,说明该模型的迁移效果极好;②模型在非危险数据集上的最高准确率出现在n=19时,准确率为94.96%,但此模型在危险数据集上的准确率0,其在混合测试集上的表现最差,这可能和监测数据的分布有关;③而当n=1 时,模型在非危险数据集上准确率仅为4.39%,而在危险数据集上的准确率为99.09%。这是因为对微震事件的危险性进行分析是二分类任务,在不能准确确定阈值的情况下,当1 个模型将更多的事件分为危险事件时,其在危险数据集上的准确率就更高,在不危险数据集上的准确率就更低,反之亦然。模型在混合测试集上的结果在进行微震事件危险性的分析时更具有参考意义。
3 讨 论
3.1 不同模型之间的对比分析
使用单独CNN 和单独GRU 模型对2 节中煤矿矿井的微震监测数据进行分析,分析流程除了神经网络模型不同外其他均相同。2 个模型训练过程中均使用Adam 优化器和Cross Entropy Loss 损失函数,CNN 模型参数总数为1 384 个,GRU 模型参数总数为412 个。取n=1,2,…,30,建立30 组数据集,CNN-GRU 模型、CNN 模型和GRU 模型融合前n 次微震事件数据的测试结果对比如图4。

图4 3 种模型在测试集上的效果对比Fig.4 Comparison of the effects of three models on test sets
通过图4 可以发现:当n 变化时(除去n=18时),GRU 模型在全部测试集上的表现都相对稳定,不同CNN 模型在测试集上的性能变化很大,但最高准确率大于GRU 模型的最高准确率;多数情况下,GRU 模型在混合数据集上的性能表现好于CNN 模型,这主要是因为构建的数据集中每个样本包含数据量很少,CNN 模型不能充分发挥其数据信息的融合和提取能力,而GRU 模型可以对样本数据的时序进行分析。
在大多数情况下CNN-GRU 模型在混合数据集上的效果好于GRU 模型,其原因主要如下:①在GRU 模型基础上联合CNN 模型,增加了神经网络模型参数和激活函数,从而增加了神经网络模型的复杂程度、非线性和泛化能力;②虽然不能充分发挥其优势,但在CNN-GRU 模型中,CNN 模型仍然融合和提取了样本数据的一部分信息,有助于GRU和全连接网络对样本进行分类。
CNN-GRU 模型继承了2 种单独模型的优点,其在混合测试集上的表现相对稳定且准确率是极高的;CNN-GRU 模型最高准确率为79.72%(n=8),略小于CNN 模型的最高准确率80.04%(n=25)。此时CNN-GRU 模型在危险数据集和非危险数据集上取得的准确率相差不大,分别为76.11%和81.92%;而CNN 模型在危险和非危险数据集上准确率为68.59%和90.53%,可见CNN 模型对于危险事件的信息提取能力较差。考虑到矿井中对危险微震事件分析准确的重要性,认为CNN-GRU 模型在分析微震危险性方面是性能最好的。
当n=8 时CNN-GRU 模型、CNN 模型和GRU模型的训练损失如图5。收敛速度快慢和模型损失从小到大依次是CNN-GRU 模型、CNN 模型、GRU模型,这可能是因为在训练时CNN-GRU 模型计算参数最多而GRU 模型训练参数最少。经过对比分析发现在分析方法框架中,CNN-GRU 模型取得效果最好,GRU 模型参数最少且计算效果较好,证明GRU 模型的参数使用效率最高。

图5 数据集特征融合前8 次微震事件数据时各模型在训练时损失值Fig.5 The loss value of each model during training when the data set features are fused with the data of the previous 8 micro-seismic events
3.2 微震数据分析中特征选择的重要性
在以往基于机器学习(深度学习)对冲击地压预测的研究中,多数学者忽略微震监测数据的时空特性或前兆特征,且相关研究中也很少将数据集分为训练集、测试集和验证集3 个部分,这也导致了模型完成训练后的泛化能力不能得到很好的保障。为分析方法中根据微震前兆特征对数据处理的重要性,将前8 次微震监测数据的时间、能量和地点(x,y,z)作为1 个样本的特征(尺寸为[5,8]),在时间尺度上按照5∶2∶3 的数量比例将数据集分为训练集、测试集和验证集3 个部分,事件的危险性作为标签。使用如图4 的CNN-GRU 模型(输入特征尺寸和中间参数尺寸有修改)对微震危险事件进行分析,在验证集(危险事件与非危险事件混合)上的最高准确率为97.33%,但在混合测试集上准确率为49.79%,在危险事件测试集上准确率为98.81%,在非危险测试集上准确率为0。尽管该模型在验证集上取得了极高的准确率,但在混合测试集和危险事件测试集上准确率极差,说明不考虑微震前兆特征的危险性分析方法的泛化性能很差,分析的结果不具有参考意义。
1.1 节构建了4 个分析指标,为证明基于学习方法分析微震数据中危险事件规律的可行性,根据以往相关研究选取微震监测事件的时空扩散性ds、时间信息熵Q1、总应力当量Q32作为额外特征,相关计算公式如下:

使用CNN-GRU 模型,取n=1,2,…,30 时各指标组合的训练模型在混合测试集上的最佳效果通过对比发现,能量对于分析本次微震事件的危险性是十分重要的,尽管当指标组合为时序集中度QT、时间间隔ΔT、能量E、能量密集度QE时模型准确率为80.16%,但其在危险和非危险数据集上表现效果相差较大,因此认为时序集中度QT、时间间隔ΔT、空间密集度E、能量密集度QE、时空扩散性QR对分析微震事件都是有贡献的;时空扩散性ds和时间信息熵Q1对于该矿井中微震危险性分析影响不大;Q32特征甚至会严重影响对微震事件危险性的准确分析。
以上分析和比较证明,在可用微震监测数据较少的情况下,结合微震前兆特征对监测数据进行处理,可以明显提高微震危险性分析的准确率。对于统一模型不同分析特征组合会取得不同的效果,有些分析特征会对模型的性能产生负面影响,所以在建立分析特征时需要充分分析危险灾害的发生机理和前兆信息。
3.3 深度学习方法分析微震数据可行性
根据矿井中微震监测信息对危险事件进行分析是十分复杂的,这主要是因为对矿井中危险事件的发生规律缺乏清晰的认知,首先基于深度学习方法对矿井中危险事件的发生的规律性进行研究,然后根据已有研究成果和计算结果讨论深度学习模型研究微震监测数据中危险事件的可行性。
训练的CNN-GRU 联合模型在混合测试集上的最高准确率是79.72%,表明该模型可以迁移应用到其他矿井或同一矿井的不同地点中。若将标签设置为随机产生,且取n=8,其它分析步骤不变,该分析方法得到的模型在验证集上最高准确率为52.30%,在混合测试集上的准确率为50.68%,这一特征间接证明了,对于具体矿井,其微震事件的发生是有一定规律可循的,是可以被学习的。
通过不同模型在3 种测试集上的准确率对比发现,绝大多数情况下模型在危险事件测试集上的准确率最高(多数在85%以上),在混合数据集上的准确率次之,在危险事件数据集上的准确率最低。这可能主要是因为原始监测数据中非危险事件的数量要远远大于危险事件的数量,训练数据可以包含非危险事件的全部类型,在训练过程中模型会抓取到矿井中非危险事件的发生规律;而危险事件发生的数量极少,训练数据甚至是全部监测数据都不能包含危险事件的全部类型。这也说明了矿井中危险事件与微震之间是有一定规律的,利用深度学习方法分析微震事件的危险性是可行的。
4 结 语
1)考虑矿井冲击地压发生的前兆信息,基于CNN-GRU 模型提出了一种微震危险性分析方法;在研究某矿山微震监测数据过程中,该方法首先根据微震前兆特征选取时序集中度、时间间隔、空间密集度、能量和能量集中度作为分析特征;然后建立初始数据集,在时间尺度上将数据集分为训练集、验证集和测试集,并分别处理不平衡样本;最后使用训练集训练CNN-GRU 模型,将在验证集取得最好效果的模型用于测试,取得了79.72%的准确率。
2)不同模型进行对比分析结果显示GRU 模型在测试集上表现稳定,而CNN 模型表现不稳定但最高准确率要高于GRU 模型取得的最高准确率,CNNGRU 模型拥有在测试集上表现稳定且取得了最好效果的优点;在对3 种模型的训练损失对比中,CNN-GRU 模型收敛速度最快且最终损失最小。
3)该方法对分析特征的建立进行研究后发现,能量对于微震事件的危险性分析极其重要。不考虑微震前兆特征,而直接使用原始数据进行样本不平衡处理,并对CNN-GRU 模型进行训练,最终的模型在验证集上虽然准确率较高,但在测试集上准确率极低,而且通过对不同分析特征组合的研究也说明建立正确的分析特征对CNN-GRU 模型准确率的影响很大。
4)对微震监测数据集的标签进行随机生成,然后利用该方法对随机生成标签的数据进行分析后取得的效果极差,证明了在选取合适分析特征的基础上,利用深度学习方法对冲击危险状态进行分析是可靠的。
