基于全局最优的信息启发式Rollout测试序列生成算法
2023-08-03王晓明袁乾臣王婧舒
王晓明,袁乾臣,王婧舒,李 璠
(1.北京宇航系统工程研究所,北京 100076;2.北京质远恒峰科技有限公司,北京 100080)
0 引言
相关性模型(dependency model),也称为相关性矩阵,是测试性建模的经典模型[1-3]。相关性模型是对电气产品的组成、故障模式、故障率、测试点、测试方法以及它们之间的逻辑关系进行描述的模型,其数学表达为依存矩阵(dependency matrix,简称为D矩阵)[2]。以D矩阵为输入,通过分析测试点对故障的检测与隔离的次序能够得出产品测试序列即排故引导树。然而故障模式的故障率不同,不同测试点的测试权重、测试费用、测试时间都是不同,从不同测试点出发所形成的排故引导树也是不同[4]。
在解算复杂电气产品的相关性矩阵时往往消耗的时间巨大[5]。目前,常用的诊断策略构建方法主要包括:目前解决诊断策略设计问题的方法主要有三类:DP算法、群智能算法和启发式搜索算法。
1)DP算法:
DP是一种递归算法,其中故障诊断树形成过程是由上而下,按通过优先方法进行搜索,隔离出全部故障为止[17]。对于诊断策略优化问题,DP算法的储存与计算需求为,其中m为故障数,n为测试数量,因此当n较小时是可行的,而对于大的复杂系统,其储存和计算量将呈指数增长。因而不适合复杂电气产品的诊断策略设计工作。
2)群智能算法:
群智能算法简单来说就是一种一类仿生算法,仿造自然界中某些规律进行优化,常见的有蚁群算法、粒子群算法等。
蚁群算法是一种用来解决多线路最优的概率型算法。Dorigo等[15-16]根据蚂蚁寻找食物过程中路径寻优的行为提出了蚁群算法。目前最常用的解决方式是将测试序贯优化问题转换为搜索最小完备测试序列问题,进而利用蚁群的记忆性与信息素积累反馈机制解决该问题。该算法着眼于每一只“蚂蚁”的搜索,结构简单编程容易,算法具备反馈机制,可通过反馈不断修正缺陷。但测试序列优化问题与搜索最小完备测试序列问题并不完全等同,得到的测试序列与诊断策略存在区别,应用受限。
3)启发式搜索算法:
常用于诊断策略优化设计问题的启发式搜索算法有贪婪算法、AO*算法、准深度算法等。
贪婪算法是快速搜索算法。该算法搜索速度快,采用固定顺序方法构造诊断树。该算法对整个诊断树采取局部择优搜索的策略,搜索速度极快,但效果不佳。
AO*算法被广泛应用于测试性设计中,如TEAMS软件就采用AO*生成诊断树。算法优势是可以找到近似的全局最优解,相比于DP算法效率有所提高,但需要处理的数据非常大,计算复杂,不适合大型系统。
准深度算法可以看成是深度算法的简化,类似于贪婪算法,但考虑更多,每一步考虑的是之后的诊断树的预估值,因而速度较快,大概率可找到全局最优解。但该算法结构复杂,且缺少反馈过程,难以应用于拓展场合。
以上三种启发式搜索算法各有优劣,在解决不可靠测试条件下的诊断策略优化问题过程中可发挥一定作用。
本项目提出了一种结合全局最优的启发式AO*算法的Rollout策略的排故引导策略生成方法,其作为一种近优的结算方法在解的复杂度方面要低于启发式搜索算法,能够确保运算速率。
1 基于全局最优的启发式AO*算法的测试序列生成方法
1.1 AO*算法概述
测试序列的生成方法直接影响故障诊断的准确度和执行效率,基于全局最优的启发式AO*算法所生成的测试序列是一种全局最优的测试策略[6],该算法同三种信息启发式(霍夫曼编码、熵、熵+1)函数相结合,通过向下扩展以及向上反馈修正两个基本操作来得到最优的测试序列,它的计算量小于DP算法和群智能算法,在搜索过程中会进行不断回溯,以实现最优解[7]。
1.2 AO*算法的基本元素及输出策略
AO*算法的输入包括以下内容:
1)系统状态集合:
S={s0,s1,...sm}
(1)
其中:s0为系统的无故障状态,si为故障状态1~m。
2)故障概率向量:
p=[p(s0),p(s1),...p(sm)]T
(2)
其中:p(s0)为系统完好率,p(s1),...p(sm)为各故障模式的频数比*(1-完好率)。
3)测试集合:
t={t1,t2,...tn}
(3)
4)成本向量(时间、人力、其他经济因素):
c=[c1,c2,...cn]T
(4)
AO*算法的输出综合考虑故障发生概率、测试时间,测试费用等的最优诊断树,AO*算法使用启发式评估函数(HEF)指导测试搜索过程[8],其计算公式为:
(5)
(6)
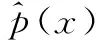
1.3 AO*算法步骤
采用AO*算法实现测试序列的优化的基础是启发式评估函数的构造。AO*算法是基于启发式评估函数h(x),选择最有可能达到目标节点的子节点进行扩展。其基本步骤如下。
Step 1:建立一个搜索图G,使其仅仅包含起始节点S,设F(s)=h(s)。如果S为终节点,则标记S为SOLVED,离开算法步骤。
Step 2:重复以下步骤,直到S己经标记为SOLVED,此时J=F(s)为期望的测试代价,并以标记的解树为测试算法。
Step 2.1:通过跟踪G中从S出发的、有标记的、连接符,计算G中的一个局部解图G′。选择G′中最高h(x)的节点x进行扩展。最初时x=S(x为系统状态集合)。
Step 2.2:扩展节点x,生成它的所有后继节点的二元集合,表示为(xjp,xjf),tj∉Πx。其中,Πx为在通向x的路径上已经标记使用的测试集。初始Πx为空。对于每一个在G中未曾出现过的x的后继节点,设:
F(y)=h(y)
(7)
y=xjp,xjf,tj∉Πx
(8)
其中:如果任意y属于终节点,则标记其为SOLVED。
Step 2.3:建立一个仅包含节点x的节点集合Z。
Step 2.4 :执行以下步骤,直到Z为空:
Step 2.4.1:从Z中移出这样的节点y,这个y在G中的后裔不出现在Z中。(移出当前没有后裔的,最底层的节点进行分析)
Step 2.4.2:修正y的值如下所示:
(9)
其中:p(yip)为相对概率。令k为测试代价最小值的坐标,并对这个具有最小值的连接符加以标记,包括(y,ykp)和(y,ykf)。如果ykp和ykf都已标记SOLVED,则标记此节点y为SOLVED。
Step 2.4.3:如果F(y)≠e,设F(y)=e。(由于测试的选择及向下扩展的节点而导致的成本改变,修正y的值为选择当前最小成本的测试tk的情况下的成本值e。
Step 2.4.4:如果F(y)在2.4.3中修正了值,或己标记为SOLVED,则把沿着标记路径的y的所有父辈节点都添加到Z中,忽略了没有由标记的连接符连接到y的先辈节点。(若y被修正或已下溯到根节点,则将其上游的、当前标记路径中的先辈节点都添加到Z中,对先辈节点进行修正计算,即执行2.4.1到2.4.4的步骤,直到Z为空。(Z为空表示已回溯结束,或已到起始节点,或已到没有发生修正的节点)。
2 基于Rollout策略的测试序列生成方法
2.1 Rollout算法概述
Rollout算法的基本思想是用一个基准策略经过Rollout仿真得到一个更新策略,再把更新策略作为基准策略进行迭代更新,逐步逼近最优策略[9]。该方法能得到比基准策略更加精确的结果,但是不能保证是全局最优解。
2.2 Rollout算法基本元素
设某产品共有(m+1)类状态,故障测试相关矩阵表示为D=[dij],根据测试结果值的不同,可分为二值测试和多值测试,二值测试即dij只有两个状态,比如(0,1)、(通过,不通过),多值测试即dij存在三个或三个以上的状态[9],比如(0,0.5,1)、(0,1,2,3)、(通过,不通过,待定)。
测试序列产生目标是合理规划测试顺序,使得在达到故障隔离目的的情况下测试费用最小。
定义所需测试费用为:
(10)
其中:pi表示隔离故障si所用的测试集合,|pi|表示测试集合的容量。
2.3 Rollout算法步骤
Step 1:初始化创建一个模糊集Z,只包含根节点S。初始化一个图G。如果S是终端节点,则将S加入到G,则G就是问题的解。
Step 2:重复以下操作,直到模糊集Z为空后停止,则G就是问题的解。
Step 2.1:从模糊集Z中移除一个模糊集节点xi,加入到图G中,如果xi是一个已解节点则从模糊集Z中取下一个模糊集节点。对模糊节点xi的可用测试集Tj中的所有测试tj,重复以下步骤。
Step 2.1.1:初始化一个模糊集节点Y′,创建一个图G′,将测试tj加入到图G′中,用tj将xi分解成两个模糊子集,测试通过xijp和测试失败xijf,将xijp和xijf加入到Y′中,重复以下步骤直到Y′为空。

(11)
IG(x,tj)=-p(xjp)log2p(xjp)-p(xjf)log2p(xjf)
(12)
(13)
Step 2.1.2:计算测试的费用开销:
(14)
其中:xl是xijp的模糊子集,lj表示xijp的模糊子集个数,Pq表示隔离的节点到xijp节点的测试序列,|Pq|表示测试序列中的元素个数,cpq[r]表示Pq的第r个测试费用。
Step 2.2:令
htj(xi)=cj+h(xijp)p(xijp)+h(xijf)p(xijf)
(14)
选择t*∈Tj使得:
h(xi,t*)=mintj∈Tjhtj(xi)
(15)
并将节点xi展开。将t*加入到图G中。把用t*拆解的模糊子集xip和xif加入Z中,然后返回Step 2.1。
3 基于全局最优的A0*信息启发式Rollout算法
为了减轻计算量并获得比启发式算法更好的结果,我们将Rollout策略与基于全局最优的AO*启发式方法相结合,以基于错误状态概率,测试成本和依赖矩阵有效地构建测试序列。
3.1 算法概述
此算法中,如果它最大化了以下测试的单位成本信息增益,则从歧义状态中选择测试。
(16)
其中:IG(x,tj)是信息增益,由以下公式给出:
IG(x,tj)=-{p(xjp)log2p(xjp)log2p(xjp)+
p(xjf)log2p(xjf)log2p(xjf)}
(17)
因此,信息启发式是一个具有计算复杂性O(mn)的一步前向程序。其它相关启发式有“分别启发式”,dc(x,tj),(又称为可区分性启发式),定义如下:
dc(x,tj)=p(xjp)·p(xjf)
(18)
选择一个测试tk,以最大化每个歧义节点的可区分性标准。很容易表明,测试成本相等时,信息启发式提供了与可分辨性标准相同的测试树。基于多义的或节点对决策树进行的深度优先扩展,信息启发式(称为多步信息启发式算法)的变体涉及给定级别(基于多步前向)的选择测试。测试给定级别的有效性仍根据其每单位测试成本的信息增益进行评估。
3.2 算法步骤
Step 1:建立一个节点集Z,仅包含根节点S与一个空图形G。如果S是一个终止节点,添加S至图形G中,退出解。
Step 2:重复下列步骤至Z为空集,然后退出,以解决方案树作为测试算法。
Step 2.1:从Z中移出一个或节点i至G。如果i是一个目标节点,继续Z中的下一个或节点;否则,考虑可行测试集Ti中的每一个测试ti,它们将节点i分为通过/失败子集:xijp与xijf(i的直接后续或节点)。创建一个集合Y与图形G′,两者均由i的直接后续或节点构成。重复下列程序(信息启发式)直至Y为空。
Step 2.1.1:从Y中移除一个或节点r。如果这是一个非目标节点,计算该节点每一个可行测试的单位成本信息增益;否则,前往Y的下一个或节点。
Step 2.1.2:选择r中单位成本信息增益达到最高的测试。通过选择最小指数的测试解决关系。将该项测试加入G′。分别根据选定测试的通过/失败结果将r分为通过/失败子集。将获得的通过/失败或节点加入Y与G′。
Step 2.2:基于测试序列(存于G′),计算每个i的后续或节点预期测试成本(如xijp),公式如下:
(19)
Step 2.3:计算或节点i的每个候选测试ti∈Ti的期望测试成本,公式如下:
htj(xi)=cj+p(xijp)h(xijp)+p(xijf)h(xijf)
(20)
其中:h(xijp)和h(xijf)分别对应通过/失败或节点子集xijp与xijf生成测试树中的预期测试成本。
Step 2.4:选择t*∈Ti,获得最小期望测试成本。使用Step 2.1信息启发式,通过有利于测试生成,还有最小指数目标解决关系。将t*加入G,然后分别将t*测试生成的通过/失败结果加入通过/失败或子集G与Z。
3.3 算法实例
表1给出某电气系统的相关性矩阵[10-12]。S(i)为某电气系统的故障模式,TPj为系统的测试项,P(si)为S(i)的故障模式频数比。在相关性矩阵中1代表测试项TP与故障模式S相关,0代表不相关。
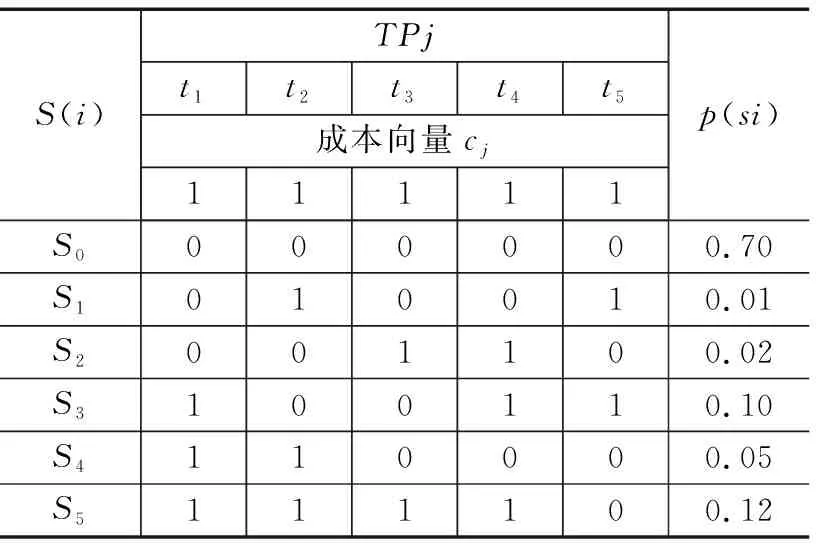
表1 某电气系统相关性矩阵
初始节点S包含所有可能状态s0,s1,...s5。首先,我们采用Step 2.1,应用图1列举的所有5种可行测试将S分为通过/失败节点。
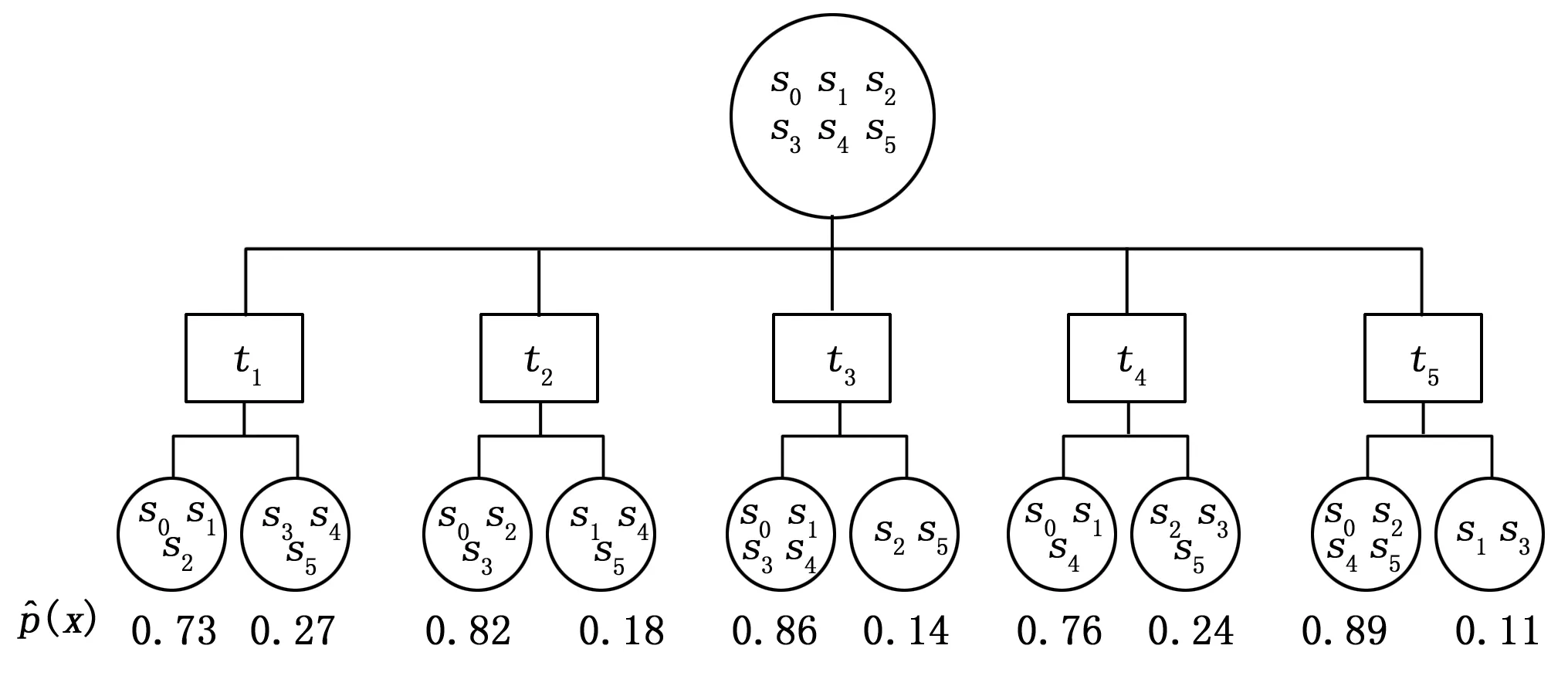
图1 测试分割
对于t1子树,分别有子集{s0,s1,s2}与{s3,s4,s5}对应通过与失败或节点。我们在{s0,s1,s2}上执行步骤Step 2.1.1和Step 2.1.2(即信息启发式)。
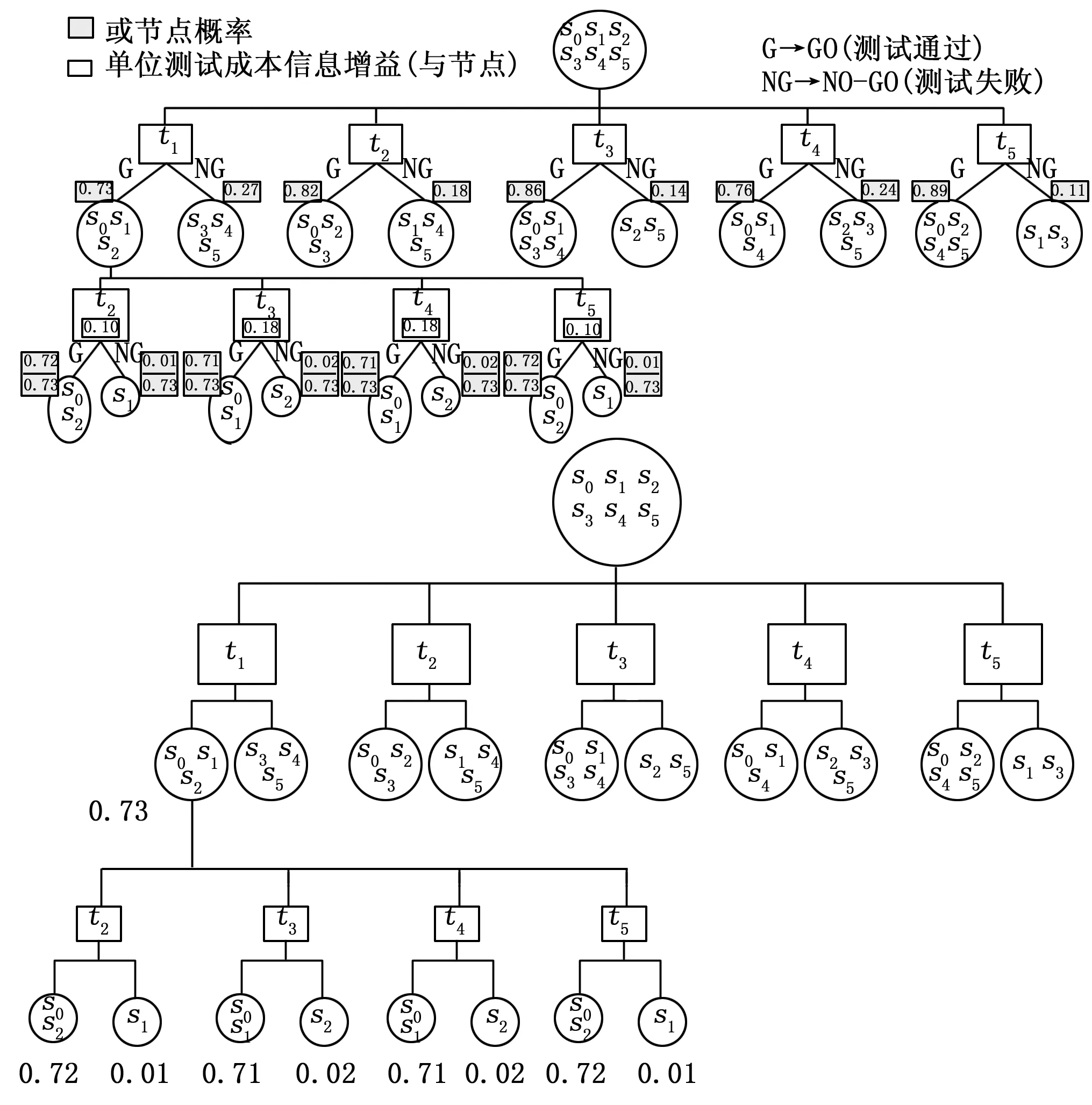
图2 测试t1通过选择第二个测试点
测试t2单位成本信息增益:
IGIG(x,t2)=-{p(x2p)log2p(x2p)log2p(x2p)+
p(x2f)log2p(x2f)log2p(x2f)}=
(21)
测试t3单位成本信息增益:
IG(x,t3)=-{p(x3p)log2p(x3p)log2p(x3p)+
p(x3f)log2p(x3f)log2p(x3f)}=
(22)
测试t4单位成本信息增益:
IG(x,t4)=-{p(x4p)log2p(x4p)log2p(x4p)+
p(x4f)log2p(x4f)log2p(x4f)}=
(23)
测试t5单位成本信息增益:
IG(x,t5)=-{p(x5p)log2p(x5p)log2p(x5p)+
p(x5f)log2p(x5f)log2p(x5f)}=
(24)
根据:
(25)
得到k={3,4}。
t2和t5的单位成本信息增益均为0.104 4,t4与t3的单位信息成本增益最大,为0.181 2。t4与t3的增益相等,选择测试序号较小的测试,则选择测试t3为第二个测试点。
反复应用信息启发式,直到为或节点{s0,s1,s2}构建的测试子树完整,如图3所示。测试t2和t5分割结果相同,选择t2。
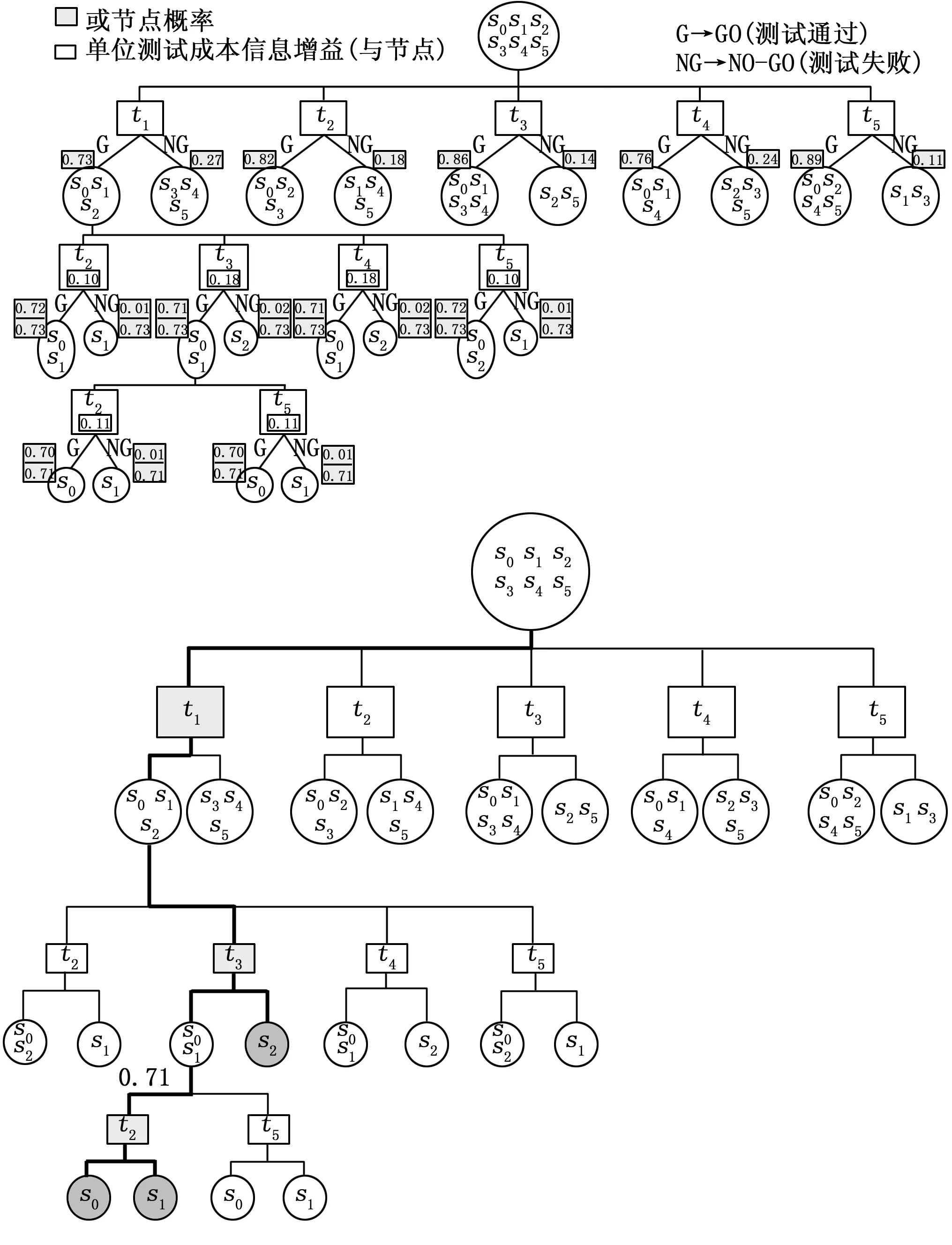
图3 测试t1通过侧生成完整诊断树
对测试t1失败子集或节点{s3,s4,s5}执行相同的过程:我们在{s3,s4,s5}上执行Step 2.1.1和Step 2.1.2(即信息启发式)。
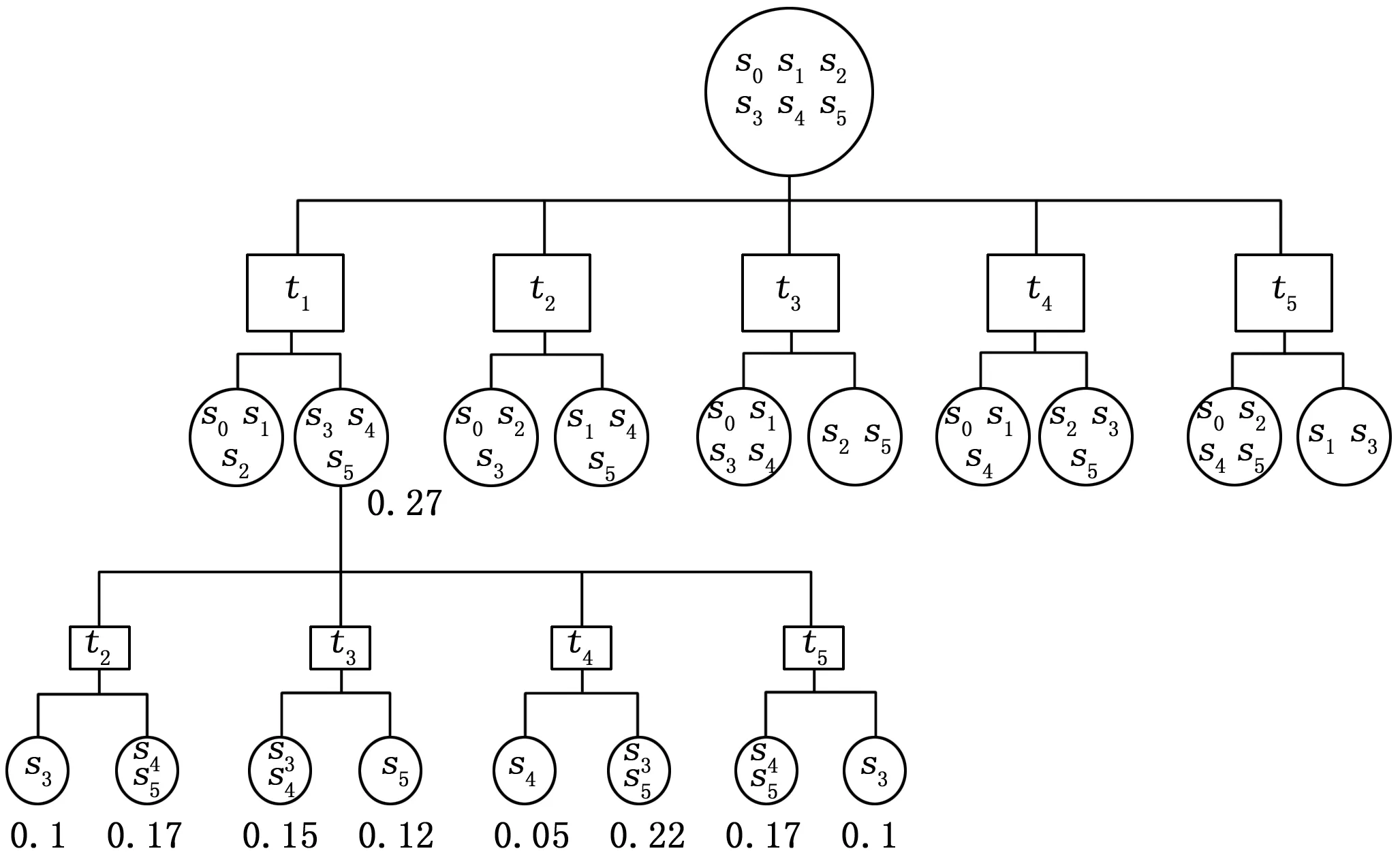
图4 测试t1不通过选择第二个测试点
测试t2单位成本信息增益:
IG(x,t2)=-{p(x2p)log2p(x2p)log2p(x2p)+
p(x2f)log2p(x2f)log2p(x2f)}=
(26)
测试t3单位成本信息增益:
IG(x,t3)=-{p(x3p)log2p(x3p)log2p(x3p)+
p(x3f)log2p(x3f)log2p(x3f)}=
(27)
测试t4单位成本信息增益:
IG(x,t4)=-{p(x4p)log2p(x4p)log2p(x4p)+
p(x4f)log2p(x4f)log2p(x4f)}=
(28)
测试t5单位成本信息增益:
IG(x,t5)=-{p(x5p)log2p(x5p)log2p(x5p)+
p(x5f)log2p(x5f)log2p(x5f)}=
(29)
综上所述,测试t3单位成本信息增益最大,所以选择测试t3为第二个测试点。
在{s3,s4}上执行Step 2.1.1和Step 2.1.2,计算得到,测试t2、测试t4、测试t5单位成本信息增益相同,因此选择测试t2。

图5 测试t1不通过侧生成完整诊断树
最终采用Rollout信息启发式算法选择第一个测试t1得到完整的诊断树如下:
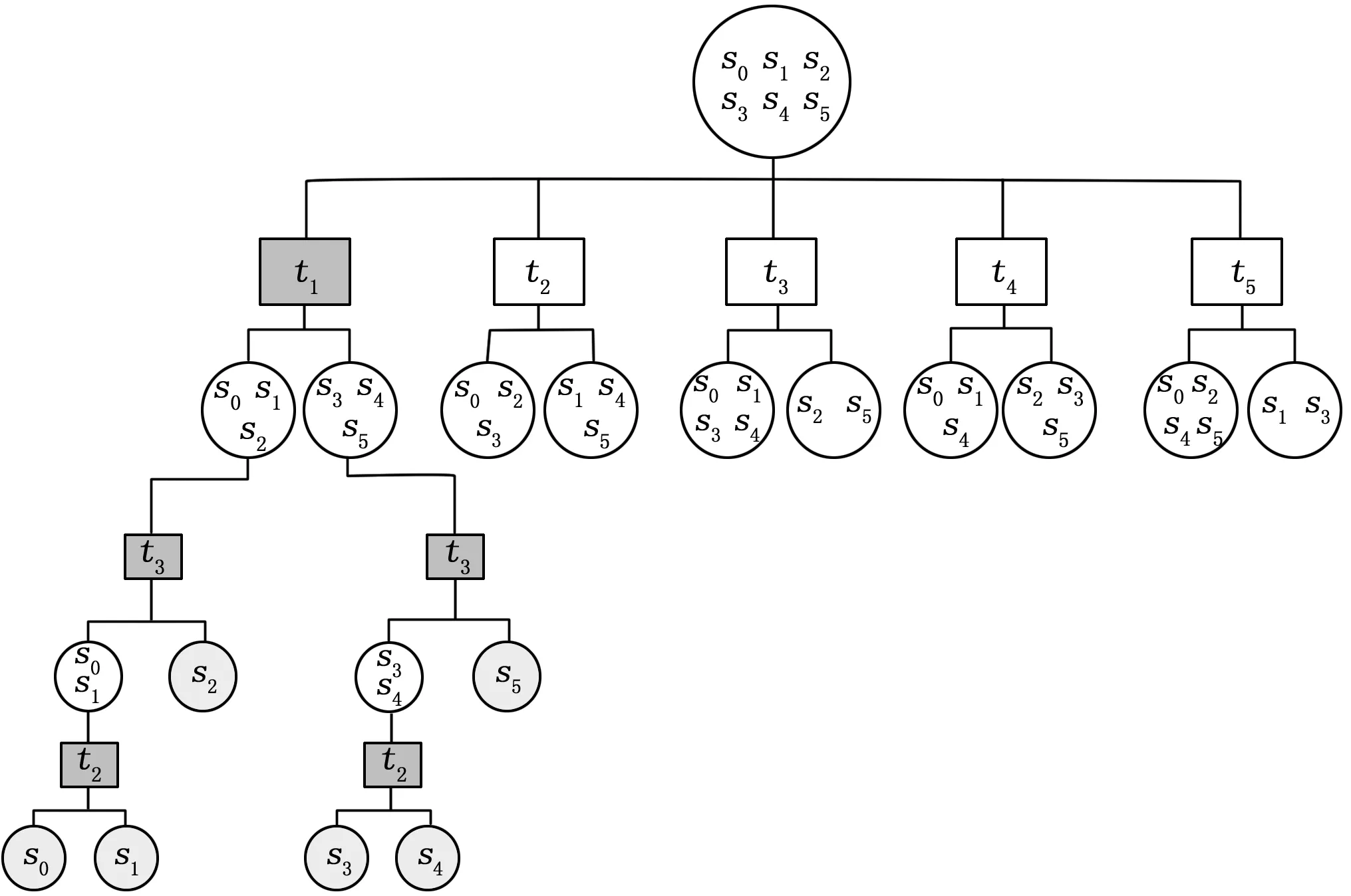
图6 Rollout信息启发式算法完整的诊断树
可见,基于全局最优的A0*信息启发式Rollout算法能够快速得到有效的测试序列树,基于测试序列树可进一步转化为ATE(自动测试设备)中TPS(测试程序集)的测试程序,作为ATE的测试策略,同时,也可以进一步转化为符合S1000D标准和GJB6600的排故引导数据模块,作为IETM(交互式电子技术手册)的重要组成部分。
4 结束语
装备的复杂度与性能一直呈正相关关系,这使得随着武器装备的发展,对装备开展测试性设计的难度也越来越大,需要考虑的因素也越来越多。如何利用现有的数据信息建立精度最高的测试性模型,采用何种算法才能快速有效地解决诊断策略生成问题,是测试性设计的核心问题。
采用基于全局最优的启发式AO*算法的测试序列生成方法可既考虑到可靠性,也考虑测试费用最小。其优点是诊断结果为“全局最优”诊断树。其缺点是由于在搜索过程中需要存储的临时支路和数据非常大[13],一般只用于规模较小的系统[14](故障模式<50)。基于Rollout策略的测试序列生成方法既考虑可靠性,也考虑测试费用最小。其优点是诊断结果为“近似最优”诊断树,诊断效率高。既减轻庞大的计算量,又获得了比次优启发式算法更好的诊断结果。该方法缺点是需要算出全部潜在诊断树之后再进行寻优,不适用于规模过于庞大的系统。
