面向物流管理的区域运力预测模型
2023-08-02杨超王建兵黄暕
杨超,王建兵,黄暕
(安徽港口物流有限公司,安徽铜陵 244000)
0 引言
近年来,物流行业开启了数字化转型之路,全面迈进网络货运时代[1]。在物流信息化平台中,运力库将所有车辆所在地按照行政区域划分为多个流向,对于各个流向承运货物的车辆统称为运力[2]。在现代大规模物流系统中,准确预测区域运力具有很强的经济意义和社会意义。准确的区域运力预测不仅能够预防爆仓、订单延误等风险,还可以在日常的运营中减少运力浪费,提高运营效率。
当前,面向不同应用场景的运力预测已获得学术界广泛关注[3-5]。时间序列模型虽然能够从历史数据中提取出一些时间序列的特征,由于模型复杂度较为有限,所能表征的特征种类也比较单一,导致预测结果准确性较低。为克服现有研究成果应用在区域物流运力预测上的缺陷,本文提出了一种基于熵权法的区域车辆运力预测模型。该模型根据熵权法计算得到车辆运力得分来计算整个区域运力得分,并融合XGBoost 和长短期记忆网络(Long Short-Term Memory,LSTM)模型的预测结果作为区域运力的预测结果。
1 数据处理
GPS 轨迹数据是基于时间和空间对车辆的移动过程进行采用并记录获得的数据,包含了车辆移动的经纬度、时间、车速、方向等信息。GPS轨迹数据蕴含了丰富的运力特征,对这些特征进行分析提取,对后续区域运力预测具有重要作用。
1.1 GPS数据质量评价
本文GPS 数据来自安徽港口物流有限公司运营管理过程中所形成的真实数据。由于GPS数据庞大,因此需要对其进行数据质量评价。本文根据《GB/T 36344-2018 信息技术数据质量评价指标》[6],选取完整性、准确性、冗余性和一致性来评价安徽港口物流有限公司物流车辆GPS 数据,评价指标计算方法如下:
1)完整性
完整性是按照数据规则要求,用于描述数据集中所有元素非空的程度。完整性分为数据元素完整性和数据记录完整性。计算公式如下:
100% -(B/A) × 100%
其中,B 为缺失值数据量,A 为所有字段总数据量。如果只有一条日志记录,则默认100%。
2)准确性
准确性是指待评价数据元素与期望的数据元素之间的真实程度,即待评价数据元素是否错误或异常。准确性指的是数据格式合规性、数据重复率和数据唯一性。计算公式如下:
其中,Ai为第i个待检测字段符合准确性检测函数的行数,待检测字段数为n,B为待测表的行数。
3)冗余性
冗余性主要评价数据集中无意义的冗余记录占整个数据集中记录的程度。冗余性分数由去重后数据集的数据量与总数据量的比例构成,计算公式如下:
其中,A为对数据集进行去重后的总数据量,B为待评价数据集的总数据量。
4)一致性
一致性是指用于描述数据与数据之间在某一特定条件下满足某一相同的条件或状态。一致性指标包括相同数据一致性和关联数据一致性。计算公式如下:
其中,Ai为待评价数据集中符合一致性评价要求的行数,待检测字段数为n,B为待评价数据集中所有数据元素个数。
本文对GPS轨迹信息相关的6个数据项(设备号、时间、经度、纬度、速度、方向)所产生的811 402 条实体数据进行质量评价的结果如表1所示。

表1 GPS数据质量评价结果
从表1可以看出:GPS数据总体准确性得分较好,数据缺失较少,有较高的利用价值,利用GPS 数据可以挖掘运力特征。
1.2 GPS数据降采样
对于一些影响运力的因素(如运营里程、运营天数、运营时长),需要计算相邻经纬度之间的距离差,结合时间戳以统计驾驶员在指定范围内的驾驶情况和停车情况。由于GPS轨迹数据的量级非常庞大,并且存在冗余和异常,因此本文通过对GPS经纬度数据进行数据降采样,剔除GPS 轨迹数据中的冗余数据,从原始数据中提炼出有价值的数据。在保证数据准确性的情况下,减少冗余数据对特征挖掘的影响,同时提高特征提取的效率。
GPS 轨迹数据降采样的主要过程是:首先,对选取的30天内的GPS数据进行处理,剔除GPS数据中的错误数据,同时对各数据字段进行数据整合,包括数据类型统一和数据格式的确定,从而为下一步的数据降采样提供可靠的GPS 基础数据;其次,针对多来源GPS数据频率不一致的情况,使用按时间间隔等距抽样的方法降低高频率数据,实现不同来源数据的频率一致化;最后,选取最优的降采样参数,使用Douglas-Peucker 算法[7]对处理后的GPS 基础数据进行降采样操作,进而实现在保证GPS 数据准确性的情况下,提高数据降采样的精度。
2 运力预测模型
2.1 运力指数
2021 年12 月,福田汽车集团发布了商用车行业首个物流景气指数“智科物流指数”,该指数通过对车辆的运营里程、运营天数、运营时长、运价和货运周转量5个因子进行整合分析,通过设置不同的系数权重,以前一年度数据均值为基准来计算商用车行业景气度值[8]。然而,该指数的计算细节并未公开披露。本文借鉴该指数的5个因子来衡量区域运力,并利用熵权法计算区域运力值。
熵权法充分考虑了系统中各指标的变化程度,根据各指标的差异程度来对其赋予不同的权重[12]。通常来说,一个指标的信息熵越小,说明它在综合评价中所提供的信息量越多,相应的权重也就越高。假设某区域拥有n0辆车,选取m个指标(m=5,分别代表30天内的运营里程、运营天数、运营时长、运价和货运周转量),剔除空值和异常值后随机选取n辆车作为熵权法的输入,假定第i个车辆的第j个指标数值表示为xij(i=1,2,...,n;j=1,2,...,m)。因为m个指标的计量单位存在差异,可能会对最终结果产生影响。因此,需要对这些指标进行标准化处理,将它们的绝对值转化成相对值。指标归一化的方法如下所示:
第j项指标的熵值计算方法如下所示:
其中,k=>0,ln为自然对数,且满足ej>=0。
信息熵冗余度(即各指标的差异化系数)计算方式如下所示:
根据信息熵冗余度计算运力评估指标体系中各项指标的权重,如下所示:
在获得各指标的权重后,各车辆的运力综合得分计算方法如下所示:
因此,该区域所拥有的n0辆车的运力综合得分sall的计算方法如下所示:
可见,基于熵权法可以计算出该区域30天的综合运力得分,也可以计算出该区域历史各个月份的综合运力得分。以该区域历史的综合运力得分作为标签来构建该区域运力得分数据集,并以此作为区域运力预测模型的训练数据。
2.2 天气因素
天气因素(降雨、气温、气压、风速等)会影响车辆运输的时间、油耗等,从而影响运力值的变化,因此天气因素也需要纳入运力预测模型。由于在模型训练阶段采用的是历史已知数据,故此可以直接应用天气数据进行训练。然而在预测阶段,由于未来天气是未知的,只能使用天气预报数据来进行预测,这会导致天气预报的准确性对运力预测模型的准确性产生影响。同时,天气预报的准确性也会随时间衰减,因此本文采用了基于时间衰减的天气因素提取算法来提取天气相关因素。天气因素提取包含训练阶段的天气数据嵌入和预测阶段的基于时间衰减的天气预报数据嵌入。
在模型训练阶段,根据历史30天的降雨、气温、气压、风速的气象数据构建4个天气因素的特征向量,生成30m维向量,m为天气因素个数(本文m取值为4)。这30m 维向量作为区域车辆运力预测模型训练时的天气因素输入特征。在模型预测阶段,本文选取中国气象数据网对评估区域未来30天的天气预报数据(降雨、气温、气压、风速)作为初始数据,并采用时间衰减算法来修正天气预报数据以作为区域车辆运力预测模型的天气因素输入特征。具体算法流程如下:
Step4:如图1 所示,由于预测的是未来30 天的数据,仅需要对30天天气预报数据进行修正,因此采用权值集合的平均数作为修正权值,如下所示:
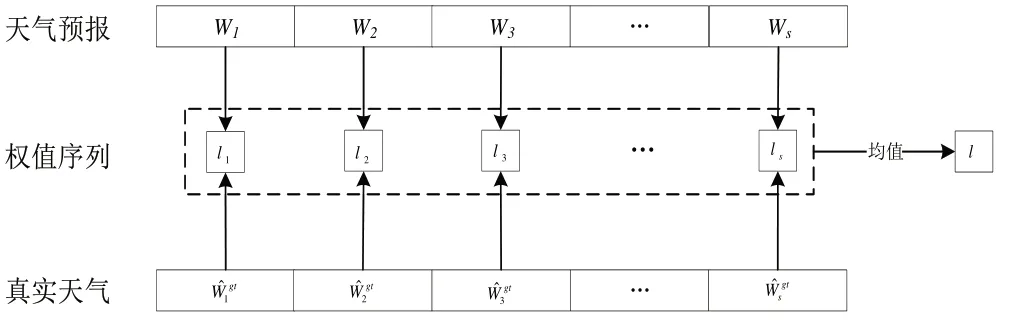
图1 天气因素提取
根据上式可以计算得到未来30 天的天气预报修正结果W={wj},j=1,2,..,30,其中wj=[rj,tj,pj,sj]包含降雨、气温、气压、风速4 个维度数据,共生产成30×4维的输出向量,作为后续区域运力预测模型的入模特征。
2.3 运力预测
为了进一步提升模型的预测准确率,本文将天气变化因素作为特征变量嵌入到预测模型中。给出针对区域所有车辆的运力得分集合D={{xi,yi}}(|D|=n,xi∈Rm,yi∈R),其中xi为车辆运力得分对应的计算指标,yi为对应的车辆运力得分(i∈N表示运力得分集合所覆盖的时间长度,以月为单位)。通过熵权法计算得到区域所有车辆每30天的运力值后,使用大小为Sw步长为Ls的滑动窗口选取数据作为输入数据,滑动窗口的下一个位置为模型label。
如图2所示,选取前1~6个30天的多因素特征ti作为模型的输入数据,以第7个30天运力得分yi为模型label,其中多因素特征ti为第i个30 天的运力值数据和第i个30 天多因素向量融合得到的向量。使用窗口大小为6步长为l的滑动窗口沿时序方向进行滑动,得到一系列数据来构建数据集。将构建的数据集划分为训练集、验证集、测试集对模型进行训练和预测,并采用相应的评价指标进行模型评估。在完成训练集构建后,分别训练XGBoost 模型和LSTM模型,并进行调参,选取最优的模型结果使用投票法进行加权融合,从而得到对区域所有车辆在未来一段时间内的运力趋势预测。
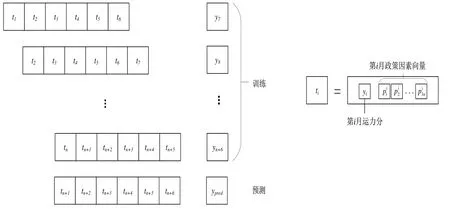
图2 数据分割处理
3 实验分析
3.1 实验环境
本文使用基于CUDA 11.0 的深度学习框架Py-Torch 1.7.1 构建BERT 和LSTM 网络模型,使用scikitlearn工具包进行数据标准化等处理,使用XGBoost 工具包构建XGBoost 模型,实验平台为内存64G,显存24G的Ubuntu 18.04 LTS系统。
3.2 数据集
本文选取了安徽港口物流有限公司铜陵区域2019年6月—2022年5月期间的货运车辆GPS数据和天气数据构建了实验数据集。数据集描述如表2所示。

表2 数据集描述
3.3 超参数设置
XGBoost模型和LSTM模型的超参数如表3和表4所示。
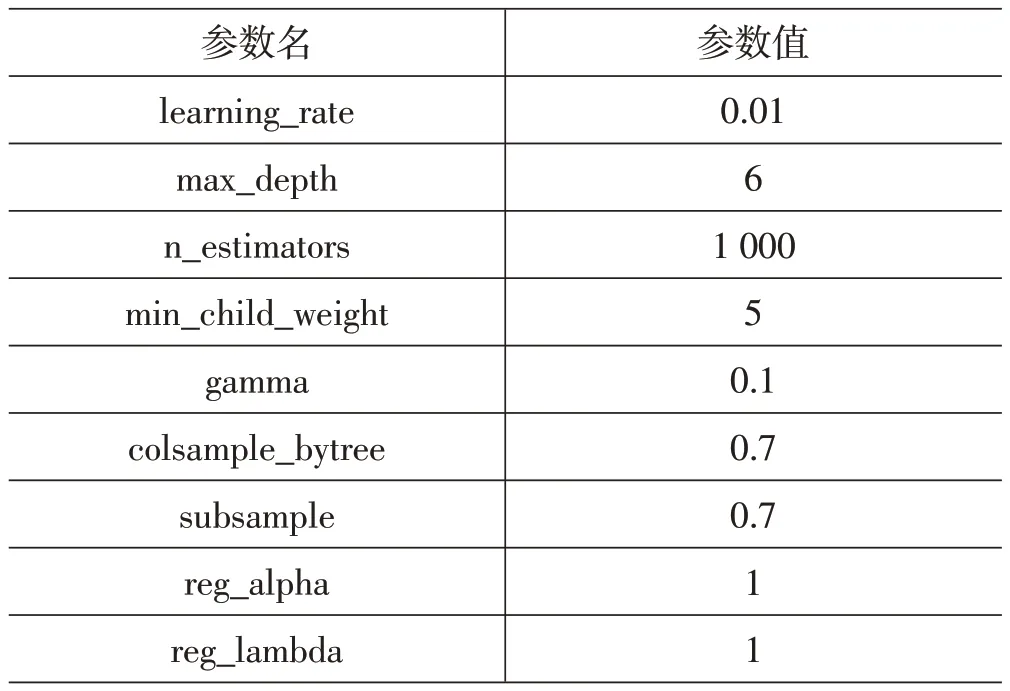
表3 XGBoost超参数设置
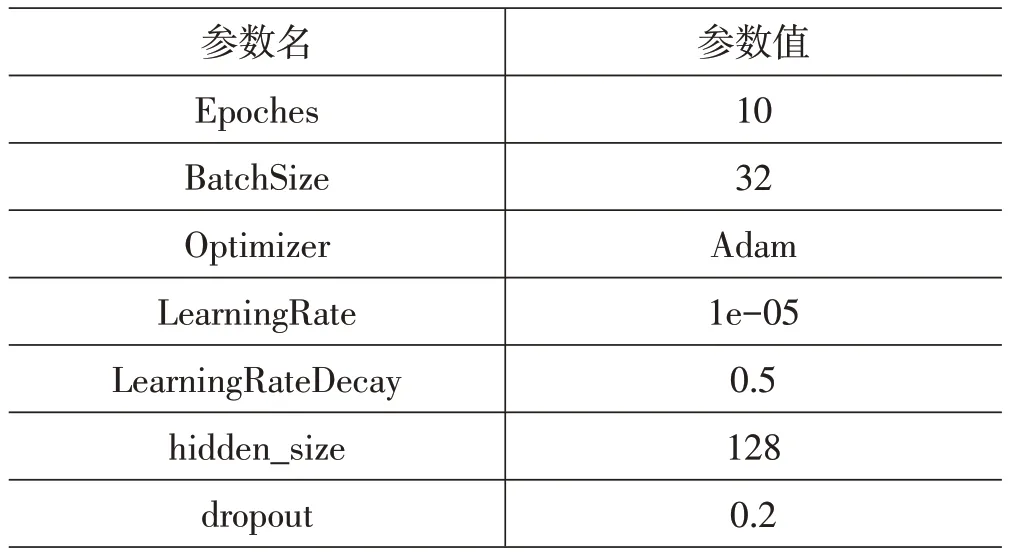
表4 LSTM超参数设置
3.4 对比实验
本文采用常用的回归模型评价指标:平均绝对误差(MAE)、平方根误差(RMSE)和平均绝对百分误差(MAPE)作为模型性能的评价指标。为验证本文提出的区域运力预测模型方法的性能,与多种基线方法进行了对比:
1)SVM(支持向量机):对于构建的数据集去除天气因素,使用运力分和其他数据作为模型入模特征,使用SVM模型进行回归预测。
2)XGBoost:对于构建的数据集去除天气因素,使用运力分和其他数据作为模型入模特征,使用XGBoost模型进行回归预测。
3)LSTM:对于构建的数据集去除天气因素,使用运力分作为模型入模特征,使用LSTM 网络提取输入特征并结合全连接网络实现运力分预测。
对比实验结果如表5 所示。从表5 可以看出,本文提出的预测模型在各项指标上均优于其他基线模型。由于本文是序列预测型任务,而LSTM 模型对于序列预测型任务非常适配,因此取得了较好的效果。本文方法在融合了XGBoost 和LSTM模型效果的同时还加入天气因素,因此取得了最优的预测效果。
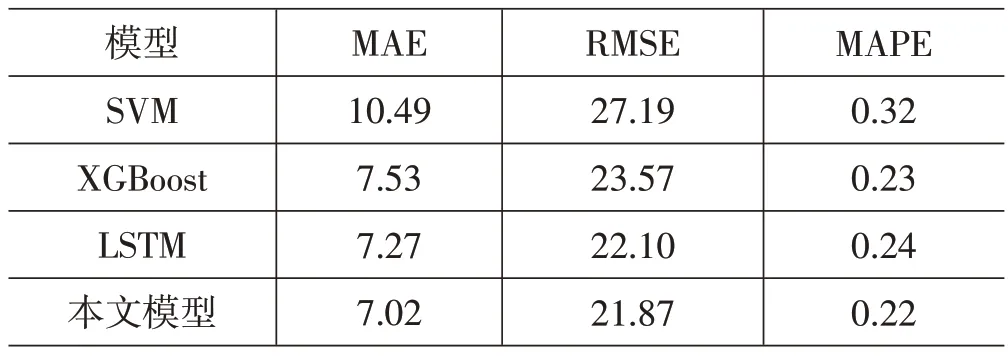
表5 基线对比结果
4 结束语
为提升物流公司应对区域运力变化的预判能力,本文提出了一种区域运力预测方法。该方法利用熵权法获取区域历史运力得分,使用基于权值修正的天气因素生成方法,根据历史天气数据构建修正权值对天气预报数据进行修正,获取天气因素特征并生成对应的向量化特征表示。最后使用XGBoost 和LSTM模型分别进行序列预测,并融合两个模型的预测结果作为区域运力的预测结果。
