DropoutVNS:基于变领域搜索的dropout方法
2023-08-02甘桃菁朱文斌
甘桃菁,朱文斌
(华南理工大学工商管理学院,广东广州 510000)
0 引言
近年来,深度学习网络在机器翻译[1]、图像分类[2]等领域都有很好的表现。但是深度学习网络具有复杂结构,有数量众多的节点和参数,面临着过拟合的问题。Dropout 是由Hinton 等人[3]提出的一种正则化算法,通过随机丢失一些网络节点,将节点的输出置为0,以减轻过拟合问题。名词dropout指将神经网络中的神经元去除,同时也会暂时移除该神经元的所有输入和输出连接。
在一个完全连接的神经网络中,一层网络的定义如下:
其中,φ是一个非线性激活函数,如ReLU、tanh和sigmoid 等。xj是一个神经元的输出,y是该层神经元的输出,w和b分别是权重和偏差。
若增加标准的dropout,则一层的定义如下:
每个rj服从概率为p的伯努利分布,其值为0 或1。使用rj对每一个神经元的输出xj进行控制。只有当rj=1时,该神经元才会输出,否则为0。
在图1 中,网络一为标准的神经网络。网络二是在网络一的基础上运用dropout,丢弃左边的输入节点,此节点的输出连接均失效。网络三是在网络二的基础上再丢弃隐藏层的两个节点,此两个节点的输入和输出连接都失效,无法再传输任何信息。
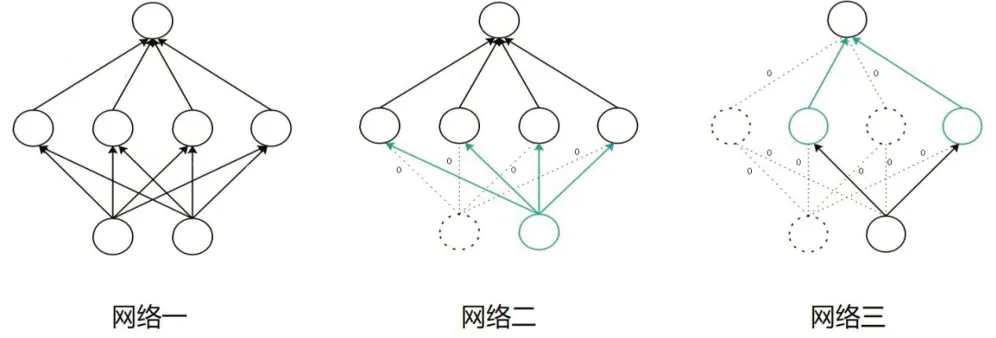
图1 标准网络和运用dropout后的网络示例图
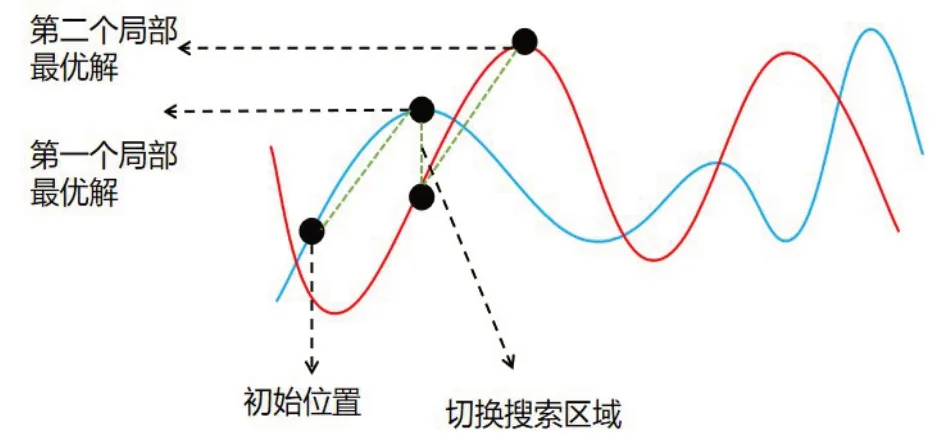
图2 变领域搜索算法的示例图
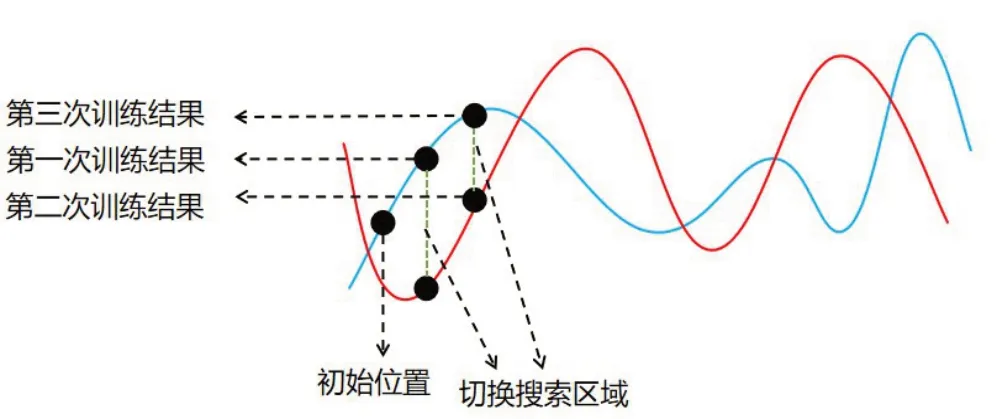
图3 使用变领域搜索的思想看Dropout
自从dropout提出以来,它已经被成功地应用于许多深度学习模型[4-5]。人们也基于dropout 提出许多变体[6-9]。Dropout在训练网络的每次迭代中,会以概率p随机丢弃节点。因此有学者提出自适应调整丢弃率p的方法[6],不需要再提前固定概率p。Wan 等人[8]提出DropConnect,不再是随机丢弃某个神经元,而是随机丢弃某个神经元的某个连接权重。
为了探究Dropout 良好表现的原因,各个研究者从不同的角度对其进行分析。Wager等人[10]将dropout视为一种自适应L2 正则化技术,并提出dropout 和自适应优化算法AdaGrad[11]相关。还有一些研究试图用不同的理论去解释dropout。Gao 和Zhou[12]表明dropout 可以帮助降低深层神经网络的拉德马赫复杂性。而Gal 等人[13]则从贝叶斯的角度讨论dropout,把它当作深度高斯过程的近似。
在dropout 被提出的原始论文中,Hinton 认为dropout 随机使一些神经元的输出变为0,打破神经元之间的固定联系,可以防止神经元之间的协同适应[3-5]。协同适应可以解释为一个过程,通过这个过程,多个节点的表现会趋向一致,互相之间更加依赖。这种现象也称为共同适用问题[13-14]。与此同时,Hinton 还将dropout 描述为一种集成技术,用共享参数集成许多子网络。因此,Hinton认为在训练过程中丢弃神经元实际上是训练指数数量的稀疏网络,并在测试阶段对这些网络的结果进行平均,这个过程也称为模型组合。
1 Dropout与VNS
Dropout是一种模型组合方法,这与求解组合优化时常用的一种算法有相似之处:变邻域搜索算法(Variable Neighborhood Search,VNS)[15]。VNS 是Mladenovic和Hansen 提出的一种改进的局部搜索算法。局部搜索算法是一种近似算法,其基本原理是在邻近解中不断迭代,使目标函数逐步优化,直至不能再优化为止。爬山法、模拟退火算法都属于局部搜索算法。在搜索过程中,VNS是在不同的领域中交替地进行局部搜索,因此更容易跳出局部最优解。若用爬山的思想来解释变领域搜索,相当于爬到最高的山峰后,再变化到另一个爬山地形,继续爬到该地形的最高点。
Dropout 在每次训练时会随机丢弃神经元,相当于每次训练时随机切换一个新的训练网络。因此可以将不同的训练网络视作不同的搜索区域,每次的训练过程视为在当前搜索区域上寻找最大或者最小值。因此,可以用变领域搜索算法的思想来解释Dropout。
通常用于训练神经网络的数据集较大,所以在每次训练时只会选择一部分的数据用来训练。人们通常将这称为批训练法,其中批也称为batch。若一个完整的数据集有100个数据,每个批次的大小为5,则整个数据集会分为20 个batch 数据。因此Dropout 是使用不同的网络去训练不同batch的数据。
但使用Dropout算法后的训练时间通常是具有相同架构的标准神经网络的2~3 倍。这可能是因为每个网络在一个batch 的数据上训练一次后,就被随机替换成下一个网络。这个过程相当于爬山还没爬到局部最高点,仅仅是在最高点的方向上前进一步,就切换成下一个爬山地形。因此标准的Dropout 与VNS有一定差别。参照VNS 的思想,可以提出一个基于Dropout的算法:DropoutVNS,其与标准Dropout的不同点在于切换训练网络的标准不同。
2 DropoutVNS
不同于Dropout 随机切换训练网络,DropoutVNS使用多个batch 数据训练到稳定时再切换网络。“稳定”被定义为相邻两次batch 数据得到的训练指标相近。若训练时使用的评判指标为a,第i次训练得到的指标结果为ai,则第i次训练稳定的公式表达如下:
其中,ε称为稳定参数,可以选择10-5、10-6等。在后续实验中会评估不同的ε对模型结果的影响。若可随机丢弃的神经元个数为N,则dropout算法在每次切换网络时,可以在2N个网络中选择,定义这些网络的集合为D。若整个数据集可以分为M个batch数据,则标准dropout 会切换M 次网络,而dropoutVNS 的切换次数会小于等于M。
为了更好地解释dropoutVNS,这里定义三个训练算法:标准算法、dropoutVNS以及dropout。
1)标准算法:一直使用一个完整网络来训练。
2)dropoutVNS:使用多个batch数据训练同一个网络到稳定时,再随机选择下一个网络。其中每个网络都是属于集合D,每个网络会以一定概率丢弃节点。
3)dropout:每输入一个batch的数据就切换一个网络来训练,每次会随机删掉完整网络中的某些节点。其中每个网络都是属于集合D。
DropoutVNS 与dropout 最大的不同在于,切换网络时dropoutVNS是使用多个batch数据训练到稳定后再切换下一个网络,而dropout 是每个batch 数据都随机切换一个网络。
在图4 中,每个算法都训练5 个batch 的数据,而标准算法的切换次数为0,一直使用完整网络训练。Dropout 算法的切换次数为5,每训练一个batch 数据就会随机切换一个网络,DropoutVNS的切换次数为2,只在训练稳定时才会切换网络。
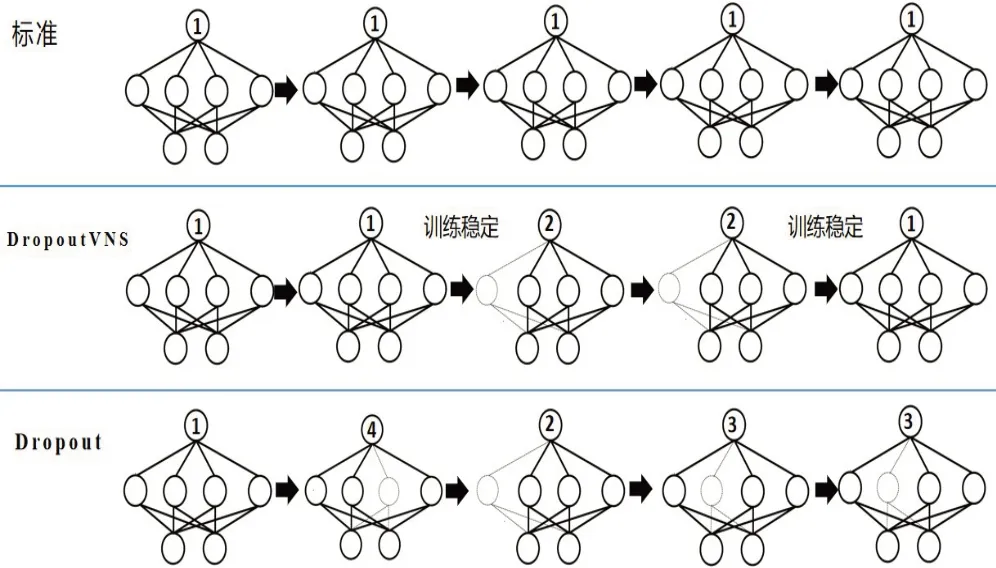
图4 不同算法的训练示例图
3 实验分析
为了评估dropoutVNS对模型性能的提升效果,在三个图像分类数据集上分别进行实验分析:MNIST[16]、CIFAR-10、CIFAR-100[17]。
与Hinton等人[3]在2012年发表的论文中采用的网络结构一致,在MNIST上使用只有全连接层的神经网络,在CIFAR-10、CIFAR-100 上使用卷积神经网络。在这些实验中,目标是研究dropoutVNS相较于标准算法和dropout算法,是否能够提高模型的预测性能。
3.1 MNIST数据集
本次实验数据集使用MNIST 数据集。网络结构为784-1024-1024-1024-10,有三个节点数为1 024的隐藏层,输入和输出节点数分别为784和10。激活函数使用ReLU。训练时使用批训练方法,每个batch有60个数据,共有1 000个batch。最后使用整个数据集训练100次,即epoch为100。一共重复5次实验,每次实验取最后一个epoch 在测试集上的error 值,然后计算5次实验的error的平均值和标准差。
选择3 个稳定参数ε,从0.000 01,依次减少100倍,直到0.000 000 001,目的是观察其对模型性能的影响。表1 总结了3 种算法,以及dropoutVNS 中不同稳定参数在MNIST 数据集上的测试集error 值以及训练时间。

表1 不同算法在MNIST数据集上的测试集error值以及训练时间
其中,测试集error 值的单位为%,测试集error 值为1.89,指的是有1.89%的图像被错误分类,剩下的图像被正确归类。因此error也称为分类错误率,而准确率=1-错误率。在测试集error 值中,±符号后面的数字是相应的标准差。丢弃概率p固定为0.5,即网络中的每个节点有50%的可能被丢弃。稳定参数为0.000 01 指的是稳定条件为两次训练的error 之差的绝对值小于0.000 01,当达到稳定条件时dropoutVNS 会切换一次网络。
从表1 可知,在模型性能方面,当稳定参数为0.000 000 1时,dropoutVNS与dropout的预测性能相差不大。而在其他的稳定参数下,dropoutVNS均比dropout 在模型预测性能方面有略微提升。总体而言,dropoutVNS 相比dropout 可以提升模型的预测性能。而dropoutVNS 也比标准的算法网络提升约3%的准确率。
在训练时间方面,无论选择哪个稳定参数,dropoutVNS 的训练时间都比dropout 算法的训练时间少。即在MNIST数据集上,dropoutVNS使用更少的训练时间,就达到与dropout相同甚至比其更好的预测性能。
3.2 CIFAR-10数据集
本次实验使用CIFAR-10数据集。网络结构则为卷积神经网络,共有三个卷积层,卷积核分别为96、128、256,后接两个节点数为1 024 的全连接层,最后的输出节点数为10。在每个卷积层和全连接层后面均加入dropout或者dropoutVNS,激活函数为ReLU,学习率为0.001,使用Momentum 优化器并且momentum值为0.9。在批训练参数方面,每个batch 有64 个数据,因此共有781个batch,并使用整个数据集训练300次。其余实验设置与使用MNIST 数据集的实验设置相同。
从表2可知,在不同的稳定参数下,dropoutVNS均比dropout 可以更好地提升模型预测能力,其中,最好的是稳定参数为0.000 01 的dropoutVNS,其error 相较于dropout 减少约1%。而dropoutVNS 也比标准的算法网络提升约4%的准确率。
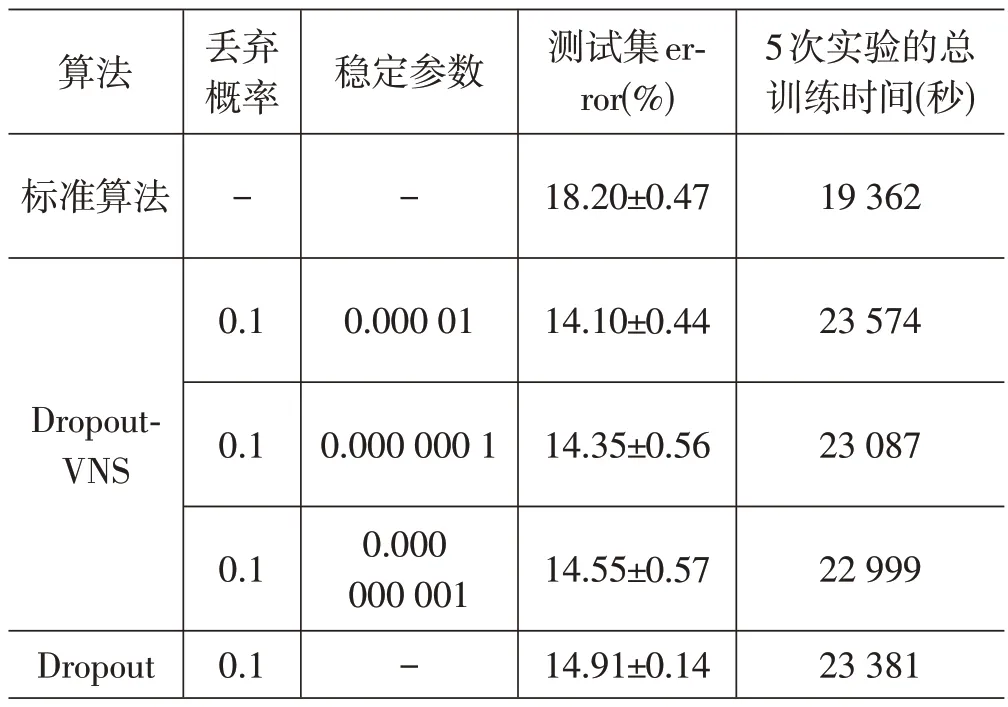
表2 不同算法在CIFAR-10数据集上的测试集error值以及训练时间
在训练时间方面,两者相差不大。即dropoutVNS使用几乎相同的时间,就比dropout 算法提升约1%的准确率。
3.3 CIFAR-100数据集
本次实验使用预测难度更大的数据集CIFAR-100,CIFAR-100 相比CIFAR-10 拥有更多的图像类别。网络结构同样选用卷积神经网络,有三个卷积层,卷积核分别为96、128、256,两个节点数为1 024的全连接层,输出节点数为100。在卷积网络的卷积层和全连接层后面均加入dropout或dropoutVNS,激活函数为ReLU,学习率为0.001,使用Momentum优化器且momentum值为0.9。在整个数据集的训练次数上,因为CIFAR-100 更难训练,所以epoch 增大到700。其余实验设置与使用CIFAR-10 数据集的实验设置相同。
从表3可知,在不同的稳定参数下,dropoutVNS均比dropout在模型预测性能方面有较大提升。其中,最好的是稳定参数为0.000 000 1的dropoutVNS,相较于dropout 减少约2%的测试集error 值。而dropoutVNS也比标准的算法网络提升约6%的准确率。

表3 不同算法在CIFAR-100数据集上的测试集error值以及训练时间
在训练时间方面,相较于dropout,dropoutVNS 使用的训练时间更少,可以减少约20分钟的时间。即在CIFAR-100 数据集上,dropoutVNS 使用更少的时间,就可以比dropout算法提升约2%的准确率。
3.4 实验总结
分别在三个常用的图像分类数据集中,比较dropoutVNS、dropout 和标准网络的性能。同时,在使用dropoutVNS算法时选取不同的稳定参数,分析稳定参数对模型性能的影响。以上实验结果说明,dropout-VNS相较于标准网络能大大提高模型的预测能力,其中在CIFAR-100 数据集上可以提升约6%的准确率。而dropoutVNS 相较于dropout 也能实现更好的模型预测性能。在MNIST数据集上,dropoutVNS使用更少的训练时间,就达到与dropout相同甚至比其更好的预测性能。在CIFAR-10 数据集上,dropoutVNS 使用几乎相同的训练时间就可以获得更小的错误率。在CIFAR-100数据集上,dropoutVNS使用更少的训练时间就获得更小的错误率。
4 结束语
Dropout 切换训练网络与VNS 变化领域搜索有相似之处,可以将Dropout 看作是一种特殊的变领域搜索算法。但Dropout 在切换训练网络时是完全随机的,而VNS 是在找到局部最优点后才变化领域。因此,在标准Dropout的基础上进行改进,将切换训练网络的标准改为稳定后再切换,从而提出一种新的正则化方法:DropoutVNS。在三个图像分类数据集的实验结果均表明,DropoutVNS明显优于标准的网络,在CIFAR-100数据集上可以提升约6%的准确率。与此同时DropoutVNS 也优于Dropout,可以提升模型预测性能,提高图像分类的准确性,减少训练时间。
