基于人体骨架数据的动作识别研究
2023-08-02李海涛范文杰李孟琳魏显隆程宇飞丁习原张庆李策
李海涛,范文杰,李孟琳,魏显隆,程宇飞,丁习原,张庆,李策
(中国矿业大学(北京)机电与信息工程学院,北京 100083)
0 引言
近年来,随着深度学习技术的发展,视频动作识别已成为计算机视觉领域的一个热门研究方向,基于骨架的动作识别[1-3]已经被广泛应用于许多领域,例如人机交互、健康监测、安防监控、体育训练等。基于骨架的动作识别技术利用传感器(如RGB-D相机、惯性测量单元等)捕捉人体关键点的位置信息,然后通过算法对关键点的位置进行分析,从而识别人体的动作。
在视频动作识别任务中,空间时序卷积神经网络(STCNN)[4-6]和其变种模型是一种常用的架构,它们使用三维卷积来捕捉视频中的空间和时间信息。然而,STCNN 模型的局限性在于只能捕捉固定长度的时间段内的动作信息,难以适应不同长度的视频输入。此外,传统的STCNN 模型也难以处理由于复杂背景、遮挡和噪声等因素导致的动作识别中的困难情况。为了克服这些限制,近年来提出了许多改进STCNN模型的方法,其中基于多阶邻接矩阵[7-9]的方法表现出了很好的性能。多阶邻接矩阵方法是一种将不同时间段的信息相互交互的方法,它通过考虑不同时间段之间的空间-时间关系来建立图结构,并利用图卷积神经网络(GCN)对这些关系进行建模。多阶邻接矩阵方法已经被证明可以显著提高视频动作识别的准确性。但GCN和GTCN模块[10-12]提出的多尺度的邻接矩阵并没有考虑对于相同的动作,全局运动的尺度可能不完全相同。有些可能更快,有些可能更慢。为了学习鲁棒的全局运动特征,应该考虑快运动和慢运动两者。
本文旨在进一步提升视频动作识别的准确率,提出了一种新的MS-G3D-L 模型,该模型基于MS-G3D模型[13-15],通过扩大MS-GCN块的多尺度的邻接矩阵,进而扩大模型的感受野,使得模型的准确率有了稳定的提升。具体来说,本文采用的方法是扩大其保留阶次,使得快运动和慢运动的特征都能被模型学习到,然后将快慢运动矩阵拼接起来,得到一个包含综合特征的矩阵。从而允许模型更好地利用不同的信息。实验结果表明,MS-G3D-L模型在多个公共数据集上都取得了良好的表现,相比于现有的模型,准确率得到了提高。本文的主要贡献是提出了一种新的基于MS-G3D 的MS-G3D-L 模型,并证明了该模型在视频动作识别任务中的有效性。通过实验证明了其对模型准确率的影响。这些结果有望为视频动作识别任务的研究提供新的思路和方法。
1 相关工作
1.1 基础模型介绍
目前的一些方法如AS-GCN[16-18]利用高阶多项式表示与中心节点相聚几跳的邻近节点,但是高阶多项式会出现有偏权重问题,即由于物理距离的原因,相近的节点无论在哪个阶次都占很大的权重,这对相距比较远的邻近节点不太友好。为了解决偏权重问题,MS-G3D 模型提出一种多尺度的邻接矩阵,如公式(1),通过设置不同的k得到不同尺度的邻接矩阵。
这里的k代表的是不同的阶数,i是初始骨骼邻接矩阵的行,j是初始骨骼邻接矩阵的列,vi和vj代表第i和第j个关节点,d(vi,vj)表示vi和vj之间跳数的最短距离。
也可写作如下公式(2):
这里的k代表的是不同的阶数是k跳的邻接矩阵,这里+1和-1的操作分别表示保留需要的阶次,去掉多余的阶次。如图1所示,关节点距离其他关节点的距离即k的取值范围为1到12。
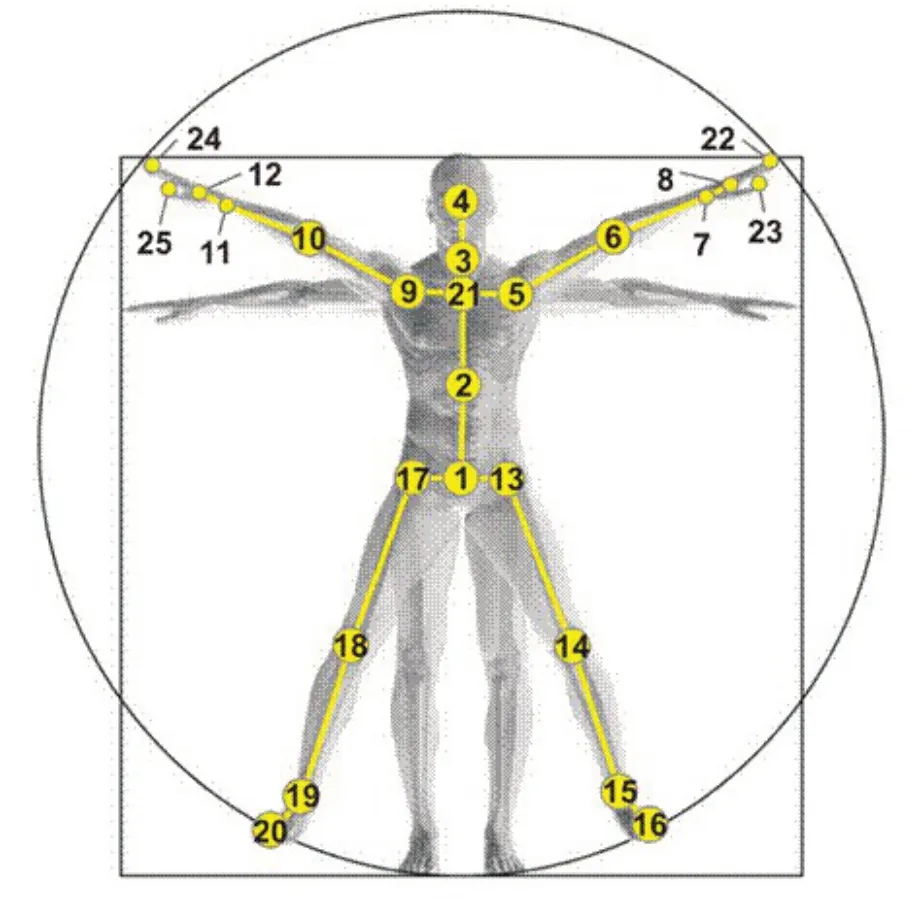
图1 人体骨架关节点图示[19]
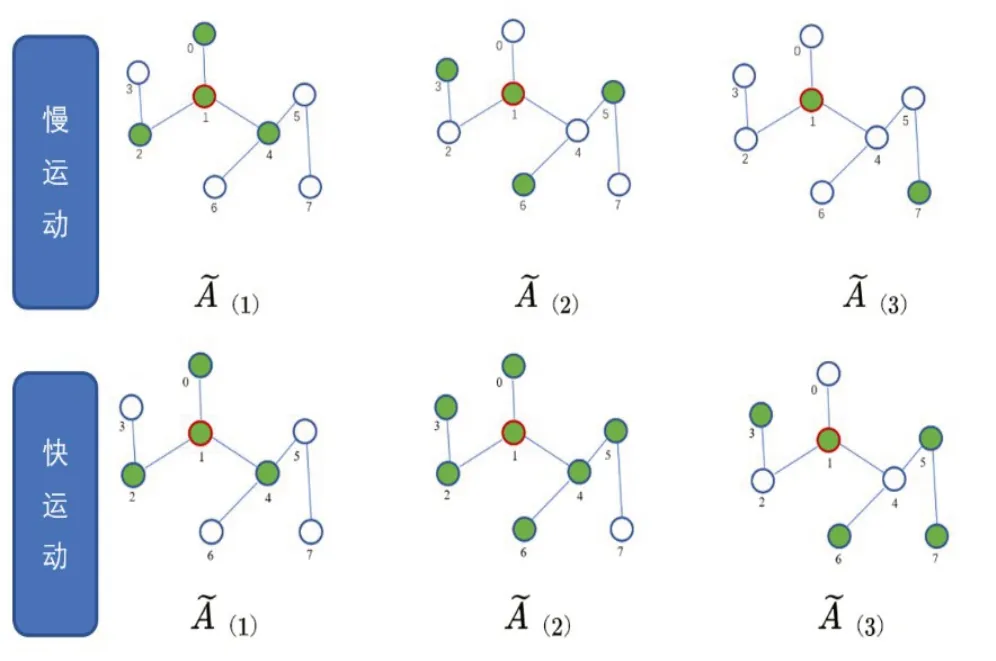
图2 快慢运动多尺度邻接矩阵选取的邻居节点对比图
1.2 改进方法
然而,对于同样的动作,全局运动的尺度可能不完全相同。有些可能更慢,有些可能更快,为了学习到鲁棒的全局特征,应该扩大其保留阶次,使得慢运动和快运动的特征都能被模型学习到。将这种直觉赋予本文现在的网络模型,本文使用快速全局运动和慢速全局运动来形成两个尺度的全局运动特征,然后将快慢运动矩阵拼接起来,得到一个包含综合特征的矩阵。本文希望通过这种拓展多尺度邻接矩阵的方式,使得模型的感受野得到提升,能够学习到相同动作的不同尺度特征,进而提升模型的准确率。从技术上来说,两个尺度的运动可以通过以下两个公式(3)(4)产生:
多尺度图卷积公式(5)如下:
MS-G3D-L模型的结构如图3所示。
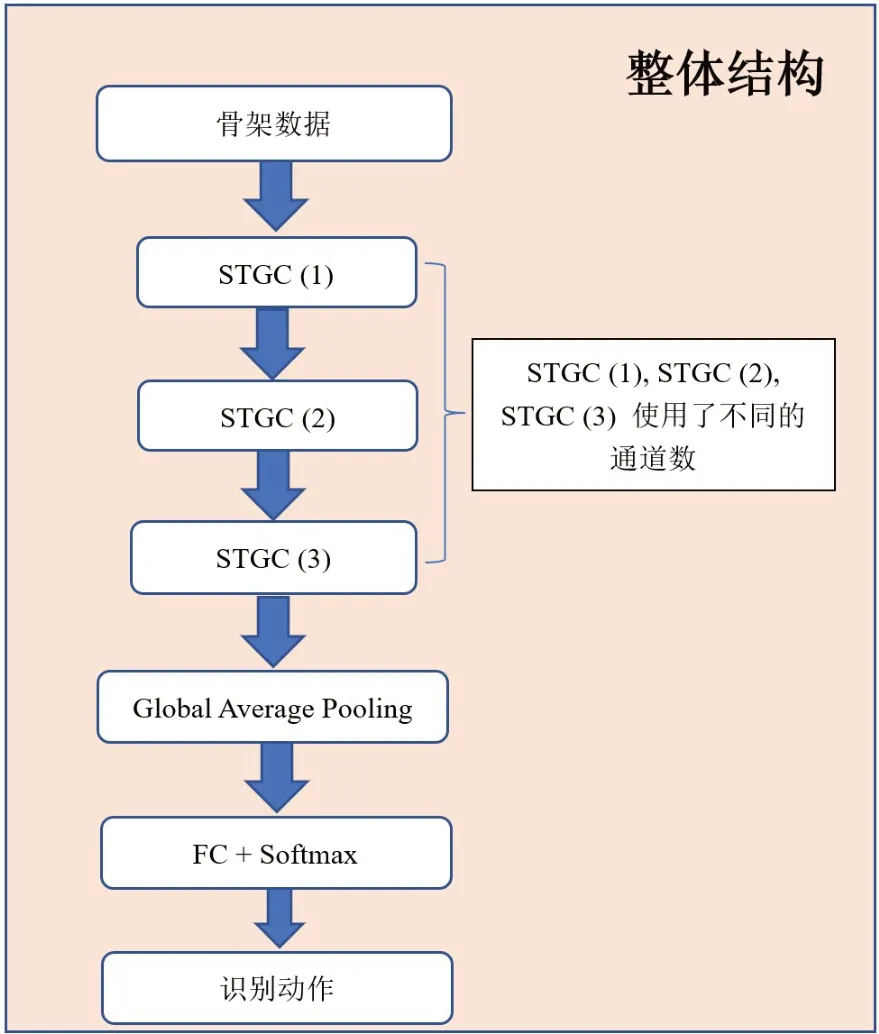
图3 整体结构
STGC块的主要作用是从时间和空间维度提取人体骨架特征,其结构如图4所示。

图4 STGC模块结构
MS-GCN 用于提取不同尺度的邻接矩阵,Sliding Temporal Window 是在时间维度滑动大小为τ,空洞间隔为d 的时间窗,滑动步幅stride=2,最后输出一个由τ×τ 个邻接矩阵铺成的τN×τN 的矩阵,MS-TCN 是在TCN[20]基础上进行的多尺度时间卷积模型。
2 可视化
2.1 系统设计
系统总体上分为数据管理、可视化管理、视频信息管理、GUI四个模块。如表1所示,数据管理模块用于实现数据读写,可视化管理模块通过数据模块所读入的数据来进行骨骼绘制和视频生成,视频信息管理模块通过同时呈现抽象骨架图和原视频来进行视频基本操作和信息展示,GUI则为用户提供交互界面。

表1 系统主要模块的功能和各模块的依赖关系
下面详细叙述用户界面模块及各管理模块的开发所实现的功能:
1)图形界面:基于PyQt5开发,应当具有较好的使用逻辑,美观实用,能够展示清楚模型处理结果。
2)工程管理:实现对工程的打开、新建、保存等操作,能对现有工程导入新的视频信息,允许用户编辑工程信息。
3)视频管理:基于cv2/pillow 库,将视频看作图片流来开发。实现对排水管道视频的基本操作,包括播放、暂停、切换视频、快进等功能。实现视频信息的输出与修改,允许用户手动编辑视频信息,操作视频播放状态。
4)数据管理:基于Python库开发本软件的数据。
2.2 系统环境
软件的正常运行需要合适的运行环境,本文软件的环境配置步骤为,首先配置PyTorch环境,软件检测模型是基于GPU 的,因此软件的使用需要依赖GPU版本的PyTorch;之后利用pip 安装库文件;然后使用Anaconda 进行环境配置,Anaconda 具有可视化界面,可以直接操作添加所需库,方便用户使用;最后是用PyQt5 库可实现基本窗口设计,可创建GUI 应用程序的跨平台工具包,它将Python 与Qt 库融为一体,保留了Qt高运行效率的同时,大大提高了开发效率。
2.3 模块结构
对于管理模块的设计,本文软件主要分为三个方面,一是数据管理,二是可视化管理,三是视频信息管理。
1)管理模块设计——数据管理
在数据管理模块中,本文软件实现的具体功能是通过mmcv.load,将文件读入内存,按照key:value 的方式组织;通过decord.VideoReader 读取目标视频;通过tqdm 实现视频生成过程的进度条;通过moviepy.editor.ImageSequenceClip 实现根据一系列按序排列的图片生成视频;通过cv2将视频看作图片流来开发;最后通过pyqt5实现界面可视化。
2)管理模块设计——可视化管理
可视化管理模块首先读取骨骼数据文件,获取骨骼每一帧的数据;之后读取视频文件,将视频文件转化成按序排列的图片,并将图片转成numpy形式进行处理;然后再绘制骨骼数据,连接对应关节起始点,在转化成numpy的图片数据上画出;最后生成视频并储存,将绘制好的系列图片转换成按序播放图片的视频并存储。
3)管理模块设计——视频信息管理
在视频信息管理模块中,本文实现的主要功能为定义视频存储类,属性包括视频文件、视频帧文件夹,视频读取路径,识别处理后视频存储路径。具体功能有读写视频信息、选择视频帧、实现视频帧的骨骼数据提取、实现骨骼数据和RGB视频融合。
软件界面如图5所示。

图5 软件界面展示
3 实验
3.1 评价指标
实验通过比对同一数据集模式下,相同参数设置,以及相同轮次下训练出的Top1 的值进行评判。同轮次下Top1的值越高代表模型训练效果越好。
3.2 数据集
实验采用NTU RGB+D 60[7]的joint 在Cross-Subject(X-Sub)模式下做数据集。
NTU RGB+D 60 是一个大规模的动作识别数据集,包含56578个骨架序列,超过60个动作类别,从40个不同的对象和3个不同的相机视角捕获。每个骨架图包含N=25 个身体关节作为节点,它们在空间中的3D 位置作为初始特征。动作的每一帧包含1 到2 个主体。
Cross-Subject 按照人物ID 来划分训练集和测试集,训练集40320 个样本,测试集16560 个样本,其中将人物ID 为1,2,4,5,8,9,13,14,15,16,17,18,19,25,27,28,31,34,35,38 的20 人作为训练集,剩余的作为测试集。
3.3 实验环境与参数设置
实验选用的GPU为两张NVIDIA A16,PyTorch版本为1.9.1,训练采用的BatchSize 为16,初始学习率设置为0.05,optimizer 选用SGD,且milestone 设置为30,40。
3.4 实验一训练模型并对比分析其训练效果
为了对比MS-G3D-L 模型相对MS-G3D 模型的训练效果,本文的实验内容为在相同环境、参数设置、数据集模式下训练MS-G3D模型与MS-G3D-L模型,记录其Top1数值。
图6 记录 了30 轮至43 轮MS-G3D 模型和MSG3D-L模型采用NTU RGB+D 60的joint在Cross-Subject(X-Sub)模式下训练出的Top1数据。
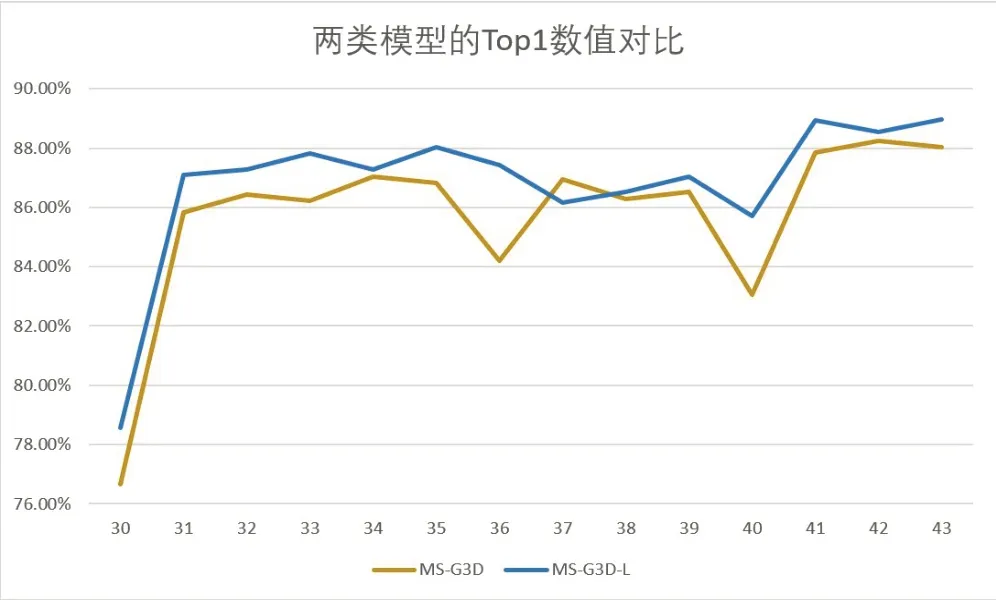
图6 Top1 数值对比折线图
31轮和41轮的Top1值之所以有明显的上升是因为调用了optimizer,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。整体上,在加入针对不同速度的运动的考量后,模型的正确率在30至43 轮稳定提升了0.5%至2%,收敛速度也加快了,说明相同运动的全局运动尺度的快慢确实对模型的准确率有影响,而本文加入的整合了快慢运动的多尺度邻接矩阵正好将这一因素纳入了考量。
3.5 实验二探索MS-G3D-L相对MS-G3D在哪些动作分类准确率得到了优化
由于MS-G3D-L 模型相对MS-G3D 模型的主要优化为容纳更多动作特征的邻接矩阵,故本文认为Top1 数值的提升原因在于对运动较快的动作的分类准确率的提升。为验证这一猜想,本文从数据集中选取了71个人体骨架数据,这些数据都有相同的特点,即人体在做指定动作的过程中,其运动速率多变,时快时慢时,比如穿衣、踢击、跳跃、醉酒等动作。将这71个骨骼数据组合成一个测试集,分别带入两模型进行验证,测试效果如图7所示。
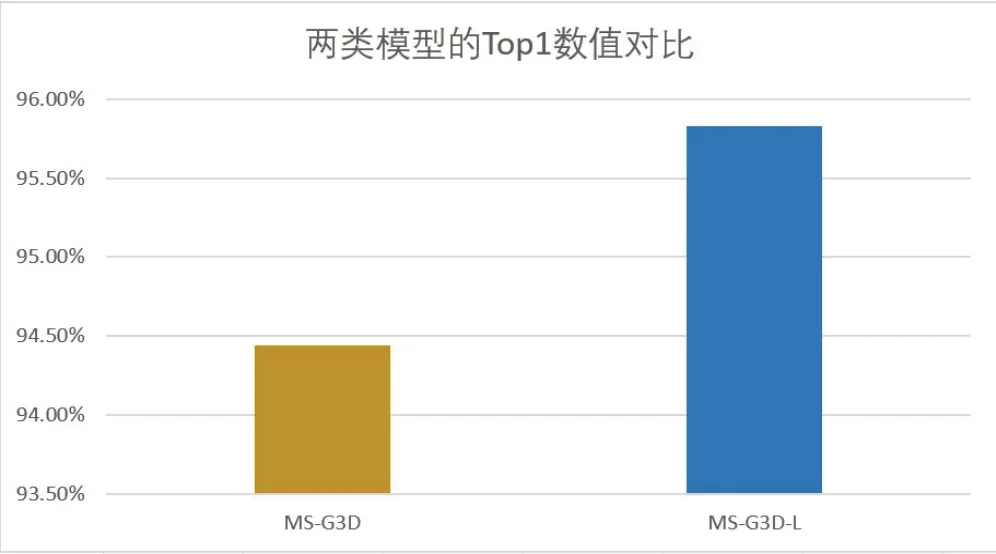
图7 在指定数据集下的Top1数值对比
在这些类别中,MS-G3D-L 比原模型提升了约1.4%的正确率(95.83%~94.44%),证明MS-G3D-L模型在生成多尺度邻接矩阵时采用的合并快慢速率运动的邻接矩阵针对运动速率较快的动作能够捕捉到更多的特征,使得模型的感受野得到提升,从而进一步提升了模型识别分类的准确率。
4 结论
4.1 原因分析
MS-G3D 模型的邻接图只能观察单个跳数骨骼点运动的信息,相同运动的全局运动尺度的快慢无法得到考量。在保留原模型图的基础上,本文扩展了相隔两跳的邻接矩阵并将之与之前的拼接在一起。
本文提出的MS-G3D-L 模型相对MS-G3D 模型的提升在于既保留了原先观察单个跳数的运动信息,还增加了同时观察两个跳数的骨骼点运动信息,通过这种手段,模型可以学习到快慢运动的多尺度特征,拓展了邻接矩阵的感受野,增加了模型的鲁棒性。而两跳之差相当于一个骨骼,所以同时观察两个跳数的骨骼点相当于观察一个骨骼的运动信息。这样使得提取出的信息更加全面,同时也让模型收敛的速度更快。
4.2 后续改进方向
在拼接了相隔两跳的邻接图之后,整个图相当于扩大了一倍,这使得模型的参数也大幅度增加,从而对显存的要求也更大。后续准备控制在矩阵大小的同时,来增加对于不同运动速度的考量,也就是说对于运动速度快的动作应该将时间窗口调小。对于运动速度慢的动作相反。这是考虑训练时间维度上卷积步长。MS-G3D-L 和MS-G3D 均使用的空洞卷积扩大感受野,其实现的方法是隔d帧选取一个图片,而两模型所使用的d 值均为1,本文认为这种方法存在一定局限性,因为针对不同动作所选用的d应该有所不同,为提高模型的鲁棒性,应该将d 设置为可训练的。
