可持续建成环境研究的机器学习应用进展与展望
2023-08-01刘泽润刘超
刘泽润 刘超*
1 背景
1.1 大数据和物联网加快智能化进程
大数据和物联网的兴起和发展加快了智能化的进程,为建成环境可持续发展带来了新的机遇和挑战。城市涌现海量的数据,对建成环境的认知手段更加智能化,实时的监测和数据收集也丰富了研究和实践的资源,物联网也进一步将人流、物流、能量流和信息流编织到城市系统中,使得建成环境各个维度之间的关系更加紧密[1]。建立在智能化数据和信息基础上的新方法和分析体系蓄势待发,以应对可持续建设中日新月异的问题,响应新的需求和应用场景,实现智能化的建设、改造和管理,推动城市结构的转变,促进建成环境的可持续发展[2]。
1.2 可持续建成环境研究受到更多关注
当前可持续环境的特点和热点的讨论是历久弥新的问题。自第二次工业革命以来,人类活动范围和对环境的影响逐步扩大,随着自然科学体系的蓬勃发展,基于物理、化学、生态、热力学等学科的综合理论推动了对环境经济和人类活动的认知和思考,20 世纪70 年代,对技术发展和资源分配的反思促进了可持续概念的诞生,社会、自然、建成环境的“复杂巨系统”不断扩展了可持续的内涵,涉及财富和社会公平、未来发展、生态系统保护、公众参与及文化的方方面面[3]。进入21 世纪,建成环境和可持续的内涵被进一步扩展[4],建成环境从自然系统发展到人类系统,以及人类的感知和历史维度,可持续的体系也建立在文化性、社会性、生态性、政治性、经济性之上,研究可持续建成环境成为影响人类命运和建设发展的重要问题。
在建筑、城市规划和风景园林领域,这一问题尤为重要。一方面,建成环境中物质空间与建筑师、规划师和风景园林师的实践和工作紧密相关,可持续发展是当下及未来的建设导向。另一方面,建成环境多维度复杂化的性质对可持续提出了更多要求。不止物质空间,空间中人的活动、意识形态和交互关系也是这一领域研究的对象,越来越多的学者投入到相关的工作中,致力于挖掘新的方向。因此,探讨建成环境的可持续发展的研究议题,分析其实践成果并展望趋势,能引起当下建筑、城市和风景园林研究者的共鸣。
为了遴选关键和前沿的可持续建成环境议题,比较联合国可持续发展目标[5]和建成环境概念,发现它们都包含促进健康、气候行动、绿色出行、生态性景观的内容,可以归纳为公共健康、能源碳排放、气候环境、生态系统和绿色出行这5 个议题(图1)。同时,中国知网和Web of Science 数据统计显示,近5 年来,大数据和机器学习(machine learning,ML)的研究在公共健康、能源碳排放、气候环境、生态系统和绿色出行这5 个议题中增长较快(图2),有必要对这几个议题开展深入研究。

1 可持续建成环境概念及重要议题Concept and key topics of sustainable built environment
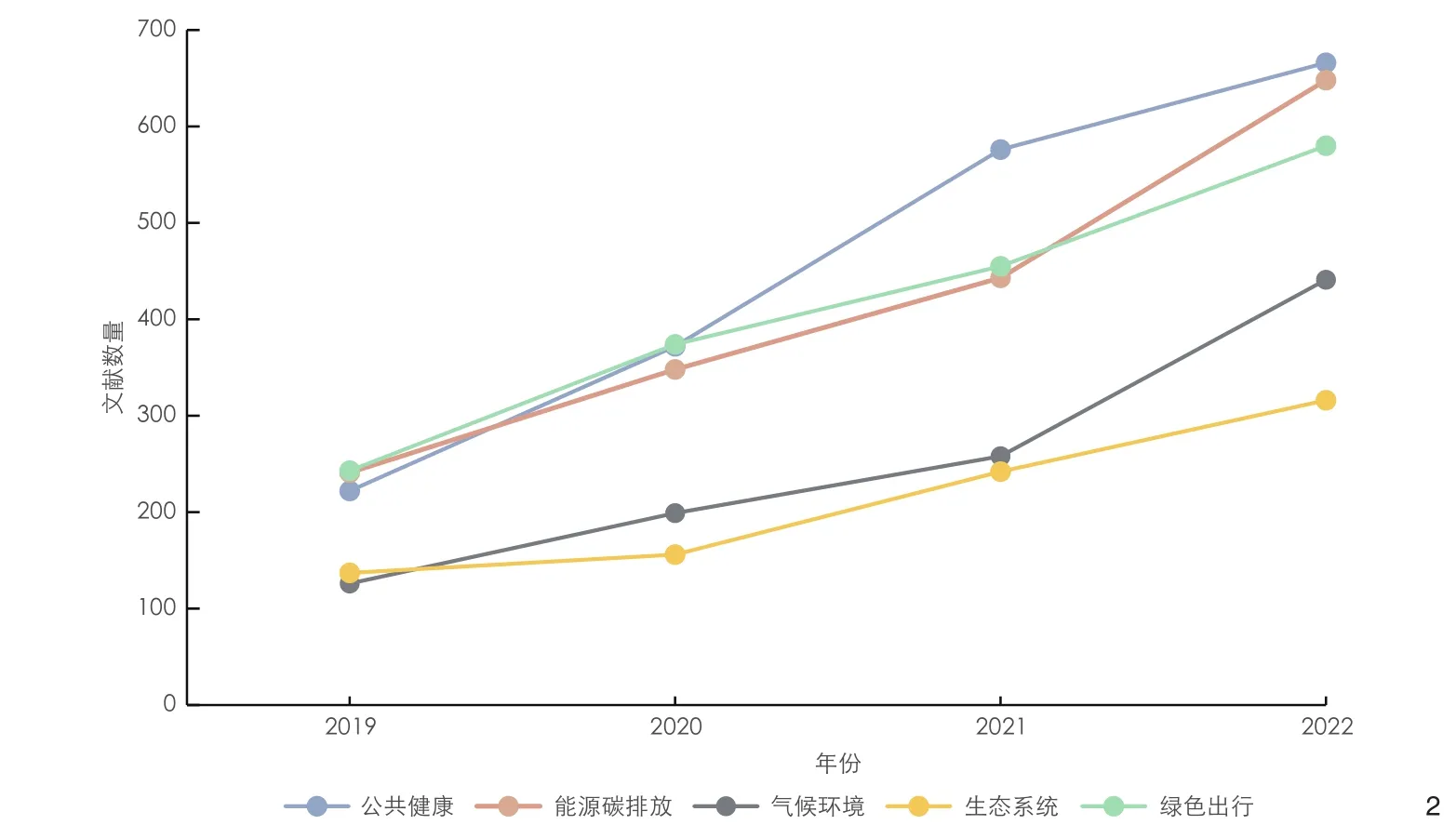
2 重要议题2019—2023 年文献数量变化趋势Quantity changing trend of literature on important topics during the period from 2019 to 2023
1.3 机器学习给各研究领域带来新影响
作为人工智能的一个分支,机器学习在过去几年中快速崛起,并在不同学科领域展示了强大的能力[2,5-6]。数据类型和量级的增长为机器学习奠定了基础,借由计算机硬件的升级,越来越多的复杂算法介入不同研究主题的分析、解读和决策过程。环境的高度智能化和庞大复杂的运算量使得计算机辅助人类成为必然趋势,而机器学习的高效性和可靠性也使得其频繁出现在制造、医学、社交、生物、互联网等各行业中。对于可持续建成环境中的议题,机器学习也依靠其能够处理复杂大量信息的优势,迅速生根繁荣,在实证研究和决策实践中都得到了广泛应用。其中,在智能交通、可持续能源系统等机器学习发展的热门话题下,学者对机器学习方法进行了系统的回顾[7-10],综述了机器学习的范式和分类,分析了机器学习方法对研究产生的影响,总结了不同方向的发展程度,为未来研究提供参考;也有学者讨论机器学习的重要算法对研究的贡献和之后的趋势[11-13]。虽然机器学习愈发重要,但现有的综述多关注到建成环境的某一方面或者机器学习的某类算法,定义机器学习范式、分类和优劣势,缺乏关于可持续建成环境领域的综合性论述,以及机器学习应用于城市研究的解释局限性分析。
因此,有必要分析机器学习对可持续建成环境领域的研究带来的影响。笔者通过对机器学习相关概念的回顾,分析机器学习在可持续建成环境中的应用重点和发展趋势。进一步聚焦公共健康、能源碳排放、气候环境、生态系统和绿色出行5 个可持续建成环境领域核心议题,梳理不同议题用到了何种机器学习方法,以及这些方法如何帮助研究者解决研究问题。虽然本研究综述的文献跨度较大,涉及不同地区和学科背景,但是本研究扎根可持续建成环境领域,紧扣机器学习应用这一核心线索,总结机器学习给可持续建成环境研究带来的影响,包括研究范式的变革、研究方向的创新、研究对象的多元和研究结论的提升。比较分析5 个重要议题的侧重,展现不同议题在目标、方法、对象和发展程度上的差别。本研究的分析内容和结论旨在完善机器学习在可持续建成环境领域研究的应用综述,展望机器学习的方法为研究实践带来的变化,从而促进学科向更科学、更智能、更全面的方向发展。
2 从预测性到解释性:机器学习的发展
2.1 机器学习的概念、分类和方法
在统计学等的基础上,机器学习模拟实现人类的学习过程,从而让计算机能自主从经验数据中学习规律,并用于新的样本和数据中[6,14]。机器学习是人工智能领域最为成功的实践之一。早在1959 年,Arthur Samuel 提出“机器学习是指赋予计算机无须明确编程即可学习的能力”的概念[14],1997 年,Tom Mitchell 提出了更加工程化的定义[14]:“一个计算机程序利用经验E 来学习任务T,性能是P,如果针对任务T 的性能P 随着经验E不断增长,则称之为机器学习。”从最初的简单算法开始,经历概率理论完善、算法升级、数据驱动和算力飞跃几个阶段,机器学习表现不断提高,在预测准确度和自主学习能力上具有巨大提升。在广泛的实际应用中帮助人们解决复杂问题,提升决策效率,适应新数据环境中的波动,洞察大量数据并学习认识新的规律。
根据训练过程中数据集的监督数量和类型的不同,可以简单将机器学习分成有监督学习(supervised learning, SL)、无监督学习(unsupervised learning, UL)、半监督学习(semi-supervised learning SSL)和强化学习(reinforcement learning, RL)4 类。有监督学习通过训练有标记的数据集(labeled datasets)实现算法,这也是目前机器学习领域研究最为成熟的方法,常见的有监督学习算法包括K 近邻算法、线性回归、逻辑回归、支持向量机(support vector machine, SVM)、决策树和随机森林以及神经网络等,这些算法能较为准确地解决回归和分类问题,例如预测公园人流量、提取并分类城市街景元素、进行城市绿视分析、分析社交网络和文本的热点等。无监督学习使用的是未经标记的数据(unlabeled datasets),重要的无监督学习算法有聚类算法、K 均值算法、具有噪声的基于密度的聚类方法(density-based spatial clustering of applications with noise, DBSCAN)、分层聚类分析(hierarchy clustering analysis,HCA)、异常检测和新颖性监测、单类支持向量机(one-class support vector machine,OCSVM)、孤立森林、主成分分析、关联规则学习等,无监督学习善于发现数据未被人类认识的潜在规律,主要解决聚类问题,常被用于城市形态的分类和人群画像等。半监督学习可以处理部分标记的数据,大部分的半监督学习算法是无监督和有监督算法的结合,解决分类、回归和聚类问题。强化学习则强调个体与环境的交互,借由策略(policy)、奖励(reward)、价值(value)和模型(model)要素,进行目标导向的学习和决策过程,常见算法有自适应动态规划(adaptive/approximate dynamic programming, ADP)、时间差分(temporal difference, TD)学习、Q 学习(Q-learning)和深度强化学习(deep reinforcement learning, DRL)等,典型的运用如DeepMind 的AlphaGO 学习围棋的制胜策略,未来能应用到城市管理、土地预测等方面。
2.2 “黑盒”模型的应用瓶颈
随着模型复杂程度和数据量的提升,现有的机器学习模型已经可以达到很高的准确度,但是,仅依靠预测的准确率无法满足实际问题的需求。因为实际问题的应用场景往往不是结果导向的,更多关注到决策的过程和背后的机制,所以,对机器学习的模型解释尤为重要,机器学习的研究导向也从提高预测性转变为优化解释性。通过对模型的解释,可以有效提高模型的可信度,降低决策过程中的偏见和偶然性,改进模型的决策机制。同时,解释的过程可以帮助研究者捕捉潜在规律,探索未知领域,解读海量数据和复杂关系,为学习新知识、建立新体系提供支持。然而,计算机语言的难读性、计算过程的复杂性、决策的不透明性使得机器学习成为“黑盒”模型,为解释机器学习提出挑战。
2.3 解释性机器学习的兴起与发展
为了更好地理解“黑盒”模型的内部工作原理,理解模型的决策过程,提高模型的透明性和可读性,机器学习的解释性方法逐步发展起来。机器学习的可解释性可以被看作对抽象概念的解释、对决策过程的解读和对功能的理解。可解释性的目的在于将复杂的计算机模型映射到人类可理解的领域,从而实现从计算机语言到人类语言的转移,帮助人们读懂模型隐藏的步骤[15-17]。
根据解释发生时间的不同,可以将解释性机器学习(interpretable ML)分为本身可解释的机器学习方法的事前可解释和本身不可解释模型的事后可解释方法[18-20](表1)。前者是相对简单和可读的“白盒”模型,如线性回归、逻辑回归、(浅层)决策树、K 近邻算法、广义加性模型、(朴素)贝叶斯和基于规则的方法等。后者是在完成的“黑盒”模型基础上,进行模型内部关系的解读,也是当下研究的重点。根据解释范围的不同,事后可解释方法可以分为全局可解释和局部可解释[18,20]。全局可解释方法关注对所有输入数据的整体理解,而局部可解释强调对特定样本的解读,能聚焦个性化的差异。目前,常用的全局可解释方法有特征重要性(feature importance)、部分依赖图(partial dependence plot, PDP)、累积局部效应图(accumulated local effect plot, ALE)和全局代理模型(global surrogate model)等,局部可解释方法主要有局部代理模型(interpretable model-agnostic explanation, LIME)、个体条件期望(individual conditional expectation, ICE)和SHAP 方 法(Shapley additive explanations)。

表1 解释性机器学习分类及常见算法总结[18-20]Tab.1 Summary of interpretable ML categories and common algorithms[18-20]
目前,各领域专家学者已对可持续建成环境研究做出了突出贡献,建立了相对完整的方法体系,并综合运用传统统计方法和一般性机器学习方法得出了富有启发性的研究成果。然而,随着数据的多样化和精细程度的提升,一般的机器学习方法已经不能满足复杂机制的模拟需求,如何解释模型背后的原因,推演决策过程成为新的研究难题。传统的统计方法和一般性机器学习的方法无法精确描述多要素之间的复杂关系,难以完成这一复杂框架的评估。为突破方法上的瓶颈,解释性机器学习弥补了传统统计模型精确性不足和一般机器学习解释性不足的缺陷,具有更广泛应用前景。在可持续建成环境领域,亟待引入解释性机器学习的方法,用新技术、新数据来深入挖掘其中的规律和复杂机制,实现模型精度、可信度和可读性的平衡。当前解释性机器学习的探索正处于起步阶段,在健康、节能减排、气候、交通、生态等方面仍需更多实证研究支持和发展。
3 重要议题的机器学习应用
机器学习看似晦涩难懂,但其核心是通过数据对不同议题进行预测和解释。传统的研究过程是通过对理论原理的深度剖析,推导公式或算法,预测事物的运行,解释其背后的原因。然而,机器学习“暴力”地降低了这一过程的难度,通过对数据的推断,机器学习能自己明白其中的方法,将庞大的数据转化为科学知识,数据越多,算法给出的答案也就越准确。这无疑扫清了许多研究上的障碍:一方面,它给了研究者通往未知领域的“钥匙”,借助机器学习,很多过去难以用公式定义的、复杂的、多尺度的、动态的问题得以解决,效率得到极大的提升;另一方面,它打破了知识的壁垒,研究者能够通过机器学习快速入门,甚至跨学科地解决复杂问题。当然,机器学习并不是万能的,数据的体量和质量都极大影响着结果的可靠性和准确度,现阶段,研究者更多地把机器学习作为数据分析的工具,帮助快速识别关键信息,发现其中规律。在可持续建成环境领域的公共健康、能源碳排放、气候环境、生态系统和绿色出行5 个重要议题下,笔者选取近5 年内具有代表性的机器学习研究,选择的范围旨在能覆盖更全面的机器学习方法,包括有监督学习、无监督学习和强化学习的各类算法,力图涵盖算法应用的不同目的,包括是预测导向或是解释导向,以及对数据处理和决策过程的辅助,并按照任务的简单到复杂、单一到多样对不同领域进行整理总结(表2)。但机器学习的发展十分迅速,国内外文献也与日俱增,筛选难免带有一定的时效性、主观性和随机性,但笔者力求能最大程度遵循客观多样性,概括性地分析不同算法的特点、适用的数据和输出的结果,比较分析不同领域的应用侧重,帮助读者快速理解不同机器学习算法如何运用到研究中,如何支持研究结论,以及在不同议题下的发展进展。

表2 可持续建成环境领域典型机器学习研究应用总结[21-60]Tab.2 Summary of typical ML researches and applications in the field of sustainable built environment[21-60]
3.1 公共健康议题有大量的解释性需求
分析国内外较为典型的建成环境与公共健康的研究,并总结相应的机器学习算法,发现对公共健康话题的讨论十分多元,涵盖传染病、慢性病、健康行为习惯、心理健康问题等不同方面,尤其是对慢性病、行为习惯、心理问题的探索不断增多,人们愈发意识到环境对居民行为的塑造作用,对身心健康的潜在影响。伴随健康数据和建成环境数据的增多,机器学习模型被广泛应用于分析建成环境对各类健康问题的影响。在大量经验数据的基础上,有监督学习算法主要应用于挖掘关键的建成环境影响要素,识别建成环境与不同健康风险之间的关系。线性回归模型因其高效、简单和实用性,出现在许多健康问题的研究中,帮助研究者快速分析显著影响因子,而逻辑回归模型多用于健康行为决策的分析。决策树和随机森林能够更有效构建多要素复杂模型,同样帮助理解关键要素,同时,通过部分依赖图的解释性机器学习展示了要素之间的复杂关系。无监督学习主要应用于健康人群划分、健康风险分类和样本地区分类等问题,K 均值、主成分分析等聚类算法频繁出现,为健康与建成环境的研究提供分类依据。强化学习主要应用于与健康有关的传感器,通过对传感器具体流程的学习,帮助传感器更好地收集数据并实现交互。总的来说,对于建成环境与健康关系的解释探索仍是当下和未来的热点,该议题的研究将面临数据更多元化和模型更复杂化的形势,现有研究对机器学习的解释度挖掘有限,可解释机器学习的应用较少,尤其是基于临床实验的因果机制挖掘,随着各类健康问题理论的完善,亟须结合病理的可解释的机器学习算法来帮助人们梳理其中的关系和决策。
3.2 能源碳排放议题更多关注预测与决策过程
建成环境与能源方面的研究主要关注到区域尺度、城市尺度和建筑尺度,包括燃料消耗、能源消费、电网负荷等。而碳排放方面的研究,多是在国家、城市和家庭层面,综合运用多种机器学习方法,对碳排放量进行计算。基于燃料、能源消费、灯光影像、遥感、环境要素和天气等数据,多种有监督学习算法可以用来预测能源消耗量和碳排放计算,同时分析不同要素的影响程度。包括K 均值聚类算法等在内的无监督学习主要应用于对城市进行分类、对类别划分和对特征类型的提取。此外,也有研究综合有监督学习和无监督学习算法,在集成树模型的基础上,借助SHAP 的解释性机器学习方法,理解机器学习的决策过程。强化学习在能源和碳排放领域被应用于寻找最优节能减排的各场景中,包括但不限于生成对成本、舒适度、收益、满意度和可持续性的平衡多目标最优策略。考虑到能源和碳排放有科学详细的量化基础,结果与因素往往可通过公式推理,有迹可循,机器学习算法多用于对结果的预测,通过算法和数据的“暴力破解”,节省公式计算的成本和时间。面对更为精细的系统,可解释性方法也能帮助人们捕捉数据背后隐藏的线索。总体来说,该议题之下机器学习的预测性应用更多,解释性应用较少,但解释性方法探索已初见成效。此外,寻找发展和保护的平衡是该议题下机器学习的另一个主要应用方面,基于决策过程并结合各种深度学习算法的强化学习能有效助力这一过程,提高与能源碳排放相关决策的效率和合理性。
3.3 气候环境议题兼顾预测性与解释性
对于建成环境中气候、空气质量和热岛效应等话题的研究主要关注到时空变化和驱动力分析,在数据监测和量化体系逐步完善的当下,多元数据处理、多情景估算和影响要素分析愈发丰富,虽然传统的统计分析、空间分析和空间模型应用已比较成熟,但机器学习仍展现出优势和潜力,兼顾预测问题和解释问题。多元线性模型、支持向量机、随机森林等有监督学习被用于预测估算和要素的识别上,基于梯度提升的树模型和神经网络、实施特征重要性和部分依赖图等可解释性方法来解释因子的非线性关系和交互作用,同时神经网络模型也被用于对图像数据的处理。无监督学习的聚类算法用于评价中的分级分类过程,而深度强化学习协助监测系统完成对数据采集处理的优化,提高预测准确度。该议题下,机器学习应用更多体现在预测和模拟的环节,解释性能力发展相对较慢:一方面气候环境的复杂性导致数据难以收集,建立解释性机器学习模型的数据基础较薄弱;另一方面,原有的气候模型与机器学习各种算法的结合尚未成熟,仍需更多的探索实践。伴随数据和监测手段的多元化,机器学习方法会越来越多地参与到数据处理和预测模拟的过程中,解释应用的场景也将更加多样。
3.4 生态系统议题处于解释性初步探索阶段
实测、模型和遥感技术的发展使人们对生态系统和生物的认知更全面和详细,机器学习参与到对生态演化驱动力、物种分布、生态足迹和生物量的分析中,提供预测和解释的能力支持。对于有监督学习,逻辑回归模型多用于生态演化驱动力的量化分析,线性模型、树模型和各种集成算法用于对生物分布的模拟和生物量的估算,借助神经网络也实现了对生态足迹的预测和重要因子的筛选。对于无监督学习,诸如主成分分析等算法用于特征的提取和综合指标体系的建立,K 中心聚类等聚类方法用于对生态单元的划分。而强化学习更多用在生物行为模型、生物动力分析等方面,通过对动态数据的挖掘,模拟实时交互过程。目前,预测估算和模拟工作是该议题下的主流,解释性方面,驱动力分析的量化较为简单,对模型的解读也比较初步地停留在重要因子的识别上,仍需更多的探索挖掘。
3.5 绿色出行议题发展成熟且应用前沿
机器学习在有关绿色出行的研究应用上积累了丰硕的成果,在数据处理、预测、模拟、决策、解释方向都有前沿性的探索和突破,涵盖的话题包括但不限于出行行为、出行安全、交通流、出行工具、拥堵风险、道路网络等的研究。对于有监督学习,各类模型应用于对指标影响的分析和结果的预测估算,在集成树模型的基础上,特征重要性、部分依赖图、SHAP、LIME 等全局和局部可解释方法被用来理解要素的贡献度和相互关联作用,并对具体实例做出解读,更为复杂的神经网络模型用于异常的识别和图像信息的提取,帮助理解决策过程、提高预测精准度,同时基于神经网络建立的更为透明的算法被应用于决策解读和因子识别中。而无监督学习算法被用于压缩、评估和分类的多元问题中,兼容对静态和动态数据的挖掘。强化学习的应用场景也十分广泛,利用丰富的动态数据,路径规划、信号灯控制、智能交通仿真、无人驾驶安全的任务可以被高效实时处理,不断趋近交通的可持续性理想目标,而约束法则的架构也提升了复杂任务的解释度,使得决策生成更为透明。不难推测,对可持续交通问题的研究是过去、当下和未来的热点,面向未来的多样场景,机器学习的应用仍有更大的潜力和更多可能的探索方向,机器学习本身已成为可持续智能交通体系不可或缺的一部分,二者是相互依存共同促进的关系,预测与解释将会更加精细和深入,为更为智能的决策提供基础。
4 讨论
总的来说,机器学习的发展和应用对可持续建成环境的研究方法、研究方向、研究对象和研究结论均产生了重要影响。机器学习解释能力的提高显著促进了研究方法的变革,越来越多的研究者实践基于机器学习的研究框架,应用各种机器学习模型,发展具有专业特色的可操作方法路径。机器学习日渐强大的性能极大拓宽了研究方向和研究对象,机器学习擅长处理复杂的、多元的、动态的、大规模的数据,以往被认为难以解决的复杂问题成为机器学习的破译对象。这为解答多地区、多尺度、长时间跨度的动态复合问题提供了新视角和可能。同时,机器学习自身不断向着智能化、透明化、可解释化发展,通过对以往经验和人类思路的学习,机器学习能帮助研究者得出最优决策方案,揭示决策机制,发现潜在规律,研究结论也愈加科学、动态、智能。
对于可持续建成环境的各重要议题,研究者都注意到机器学习在预测和解释上的强大能力,并开发了基于具体场景和问题的解释性方法和可读模型,研究目的也逐渐侧重于决策的理解和规律的挖掘,但不同议题的发展程度不同,同时基于实证研究的因果机制探索仍有大量空白。对于公共健康,解释建成环境对健康效应的影响是核心论点,但解释性机器学习的应用相对简单初步,解释性方法的实证探索较少,缺乏对病理的解释和临床实验,需要更多理论的完善和方法的探索,以理解其中的复杂因果机制。而机器学习在能源碳排放、气候环境领域的应用通常兼顾预测和解释的问题,也在一定程度上展开对潜在规律的讨论:一方面,通过对数据处理的升级和算法的综合,提高估算预测的准确度;另一方面,结合算法的特点和对原理的解读,模型的决策过程也得以解释。对于建成环境与生态系统,机器学习的预测应用更多,解释力相对不足,由于分析过程中涉及的要素庞杂,模型的设计与实施仍需完善。对于绿色出行问题,机器学习应用已有成熟的发展,兼具前沿性和多样性,在预测能力和解释能力发展的同时,不断转向对智能决策的探索,在分析解释的基础上寻找改进优化策略。
5 结论
本研究从现有的研究应用出发,提出机器学习预测性有余而解释力不足的特点,总结各类机器学习算法对研究的影响。有监督学习被用于数据较全的回归和分类问题上:线性回归应用最广泛,适用于简单的预测;集成算法发展迅速,随机森林、集成的树模型适用于复杂的预测任务,并结合多种可解释性方法,揭示内在规律;神经网络也日趋复杂,但目前可读性不高。无监督学习被用于陌生数据或缺失数据的聚类和降维问题上,且常与有监督学习结合应用:K 均值聚类是最常用的聚类算法,能快速实现数据的分组;主成分分析是较为常用的降维方式,能高效凝练关键信息。强化学习被用于优化和动态规划问题上,且往往是经过有监督学习或无监督学习的数据处理后的最后一步,算法通常会结合具体问题而调整,有很强的针对性。机器学习的理论和方法日新月异,本研究仅提及最为主流且应用广泛的方法,为学者了解相关研究和涉足该领域实践提供初步的图景。
未来,随着数据和模型的发展日趋完善,机器学习应用的资源和场景也更丰富多元,可持续建成环境的研究将更多依赖并受益于机器学习的发展。不同议题的发展程度不同,将来可能有不同的侧重。绿色出行等交通问题的机器学习应用更为前沿,未来将持续探索从预测、解释到智能决策的完整体系,更多关注动态数据,更多开发人机互动场景;对于能源、碳排放和气候环境,解释性的应用将不断增多,方法将会更加多元化和专业化;而生态系统和公共健康的机器学习应用将进一步普及,此外,这2 个议题也存在大量的解释性需求,可解释的方法和模型亟须大量实证探索,相关的研究将成为下一步的热点。当然,本研究仅在文献综述的基础上关注重点议题,对较为典型的应用进行了总结分析,并未对机器学习方法本身的原理、技术和道德问题做更深入的探索。总之,机器学习对可持续建成环境的研究方法、研究对象和研究结论带来的影响和变革毋庸置疑,有效推动了该领域更定量、更多元、更智能、更科学的发展,可以预见,这一领域的机器学习研究应用正在且将不断快速发展,且具备长久广阔的发展前景。
图表来源(Sources of Figures and Tables):图1 由作者绘制,其中可持续发展目标部分来自参考文献[3];图2 由作者绘制;表1 根据参考文献[18]~[20]整理;表2 根据参考文献[21]~[60]整理。
