面向运输风险识别的高速公路货车用户画像方法
2023-07-26林培群龚敏平周楚昊
林培群 龚敏平 周楚昊
(华南理工大学 土木与交通学院,广东 广州 510640)
2021年我国全年公路营业性货运量为391.39亿吨,约占货运总量的75.04%,年末拥有载货汽车1 173.26万辆,共17 099.50万吨位[1]。然而,由于高速公路货车非法改装、疲劳驾驶、超限超载等现象长期存在,不仅严重破坏了公路交通设施和桥梁设施,安全也成为困扰行业良性发展的痛点。据统计,我国货车保有量占全部机动车保有量比重不足10%,但导致的事故占1/4,导致一次死亡3人以上事故约占1/3,导致一次死亡10人以上事故占40%[2]。因此,交通管理人员必须应用更有针对性的、精细化的交通管控方法来提高货运行业安全水平。
随着交通大数据获取设施不断完备以及大数据技术的快速发展,研究人员可基于交通大数据进行出行特征画像和出行群体分类辨识模型研究,现有研究多侧重于利用交通大数据对出行客车或全车型进行出行特征画像和分类,如畅玉皎等[3]基于上海快速路牌照识别系统采集的数据,通过K-means聚类进行数据挖掘,提取通勤特征车辆;蔡素贤等[4]基于车辆运行数据,提取了18项与驾驶行为相关的特征,并采用随机森林算法对疲劳驾驶进行识别;魏广奇等[5]基于高速公路流水数据,利用聚类方法进行通勤车辆识别;徐进等[6]以重庆市包茂高速某路段的电子不停车收费数据为基础,分析了一般路段和连续上坡路段不同车型的速度分布特征。
另外,对于高速公路货车货运安全的研究中,侧重风险量化评估和货运安全指标构建的较多,如裴爱晖等[7]构建运输企业与从业人员的安全评价指标体系,基于评价指标体系,提出面向评价对象的安全量化评估方法及分级管理方法;宿硕等[8]构建了以驾驶员超速驾驶行为和疲劳驾驶行为信息为基础的公路货运安全指数,从时间序列角度分析了公路货运安全状况的变化规律;张坤等[9]应用长大下坡风险指数评价方法,研究货车及大货车等载重汽车在长纵坡条件下车辆行驶过程中多项指标与事故发生频率的相关性,进而选定判定指标,得出风险指数模型。同时,也有研究者基于驾驶员生物特征对驾驶员危险驾驶行为进行监测和预警:如闵建亮等[10]提出基于前额脑电(EEG)信号多尺度小波对数能量熵的驾驶疲劳检测方法;王红君等[11]提出一种基于计算机视觉的面部多特征疲劳驾驶检测算法,在此基础上提出4个反映驾驶员疲劳状态的指标,据此对驾驶员疲劳状态进行分级;Zhao等[12]提出了一种基于人脸动态融合信息和深度信念网络(DBN)的驾驶员瞌睡表情识别框架;Gao等[13]基于多通道脑电图(EEG)信号的时空结构,开发了一种基于EEG的时空卷积神经网络(ESTCNN)来检测疲劳驾驶。从已有研究来看,利用交通大数据,应用用户画像和群体分类理论提高货运安全水平的研究较少。
因此,基于对上述问题的思考,本研究基于高速公路收费数据,提出基于货运风险特征画像的货车运行风险等级识别模型。首先,从驾驶行为和营运状态两方面制定面向货运风险识别的用户画像标签体系;然后,利用K-means++算法获得货车货运风险特征画像分类结果;最后,使用熵权法对各类货车进行货运风险评分,确定各类别货车的风险等级。进一步分析各类别货车的出行特征,据此为不同风险等级货车车辆提供精细化管理建议,以期能够提升行业安全管理水平,推动我国道路货运市场健康发展。
1 模型与方法
1.1 基础数据
随着高速公路逐步实现联网收费,每年会生成海量收费数据,联网收费数据样本量大,且是全样本统计,数据内容丰富,应用价值高,具有典型的大数据特征。高速公路收费数据字段如表1所示。
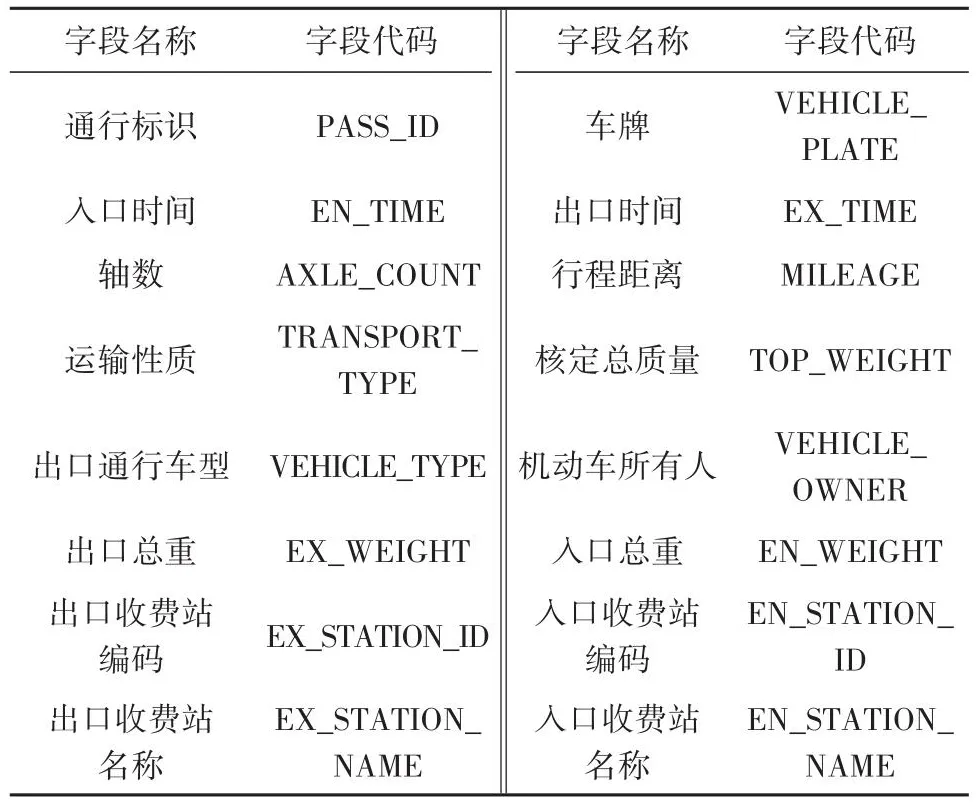
表1 高速公路收费数据字段Table 1 Fields of freeway toll data
1.2 面向货运风险识别的用户画像标签体系
本研究遵循科学性、全面性、发展性、可操作性的指标选取原则,将从基于货运行业属性与数据的质量属性以及货车货运风险识别等方面考虑,选取货车司机货运风险特征画像标签指标。货车货运风险特征画像标签体系如图1所示,主要包括:驾驶行为(超速系数、夜间驾驶系数、超载系数)、营运状态(运输距离(加权)、车货总重、驾驶时长(加权)、起讫点(OD对)稳定系数、出行端点稳定系数)。

图1 货车货运风险特征画像标签体系Fig.1 Portrait label system of truck freight risk characteristics
(1)超速系数
车速是衡量驾驶员驾驶安全的重要标准之一,也是描述交通流状态的重要指标。
首先,计算进、出口收费站时间差得到行程时间ti,再根据行程距离si与ti的比值,得到货车单趟行程的行程车速vi,即
其次,交通管理部门常以85%位地点车速作为某些路段的限制车速,即在该路段行驶的所有车辆中,有85%的车辆行驶速度在此速度以下,只有15%的车辆行驶速度高于此值。考虑到收费数据得出的是行程车速,因此,本研究将样本的所有行程车速的85%位车速作为超速阈值vm,行程车速vi超过该阈值的行程认定为超速。
最后,统计每辆货车超速次数Nsp和统计时间内上高速总趟次Nsum,使用式(2)计算二者的比值,结果即为货车超速系数Fsp。
(2)夜间驾驶系数
首先计算统计时间内货车总行程时间Tsum,本研究将货车在凌晨0:00—5:00行驶定义为夜间行驶,然后对货车每趟行程的夜间驾驶时长求和得到总夜间驾驶时长Tni,使用式(3)计算二者的比值,结果即为货车夜间驾驶系数Fni。
(3)驾驶时长(加权)、运输距离(加权)
对于疲劳驾驶的评价,本研究提出驾驶时长(加权)与运输距离(加权)两个指标作为衡量,驾驶时长权重系数hi据单趟行程时间ti取值,运输距离权重系数yi据单趟行程距离si取值。
《中华人民共和国道路交通安全法实施条例》规定连续驾驶机动车超过4 h应停车休息,所以将行程时间ti在1~4 h之间的行程,权重系数hi取1,小于1 h的取0.5。根据相关研究得到的连续驾驶一段时间Tc后驾驶员的驾驶特性测评结果[14],再考虑中长途货车的双司机的情况,对测评结果中的时间乘2,以此对应不同的权重等级,最后根据测评结果得分赋予权重。另外,根据相关数据,城市通勤半径一般不超过50 km,2021年公路货物运输平均运距为176 km,再借鉴上述权重分级级差为运输距离赋予相应权重,驾驶时长权重系数hi和运输距离权重系数yi取值如表2所示。
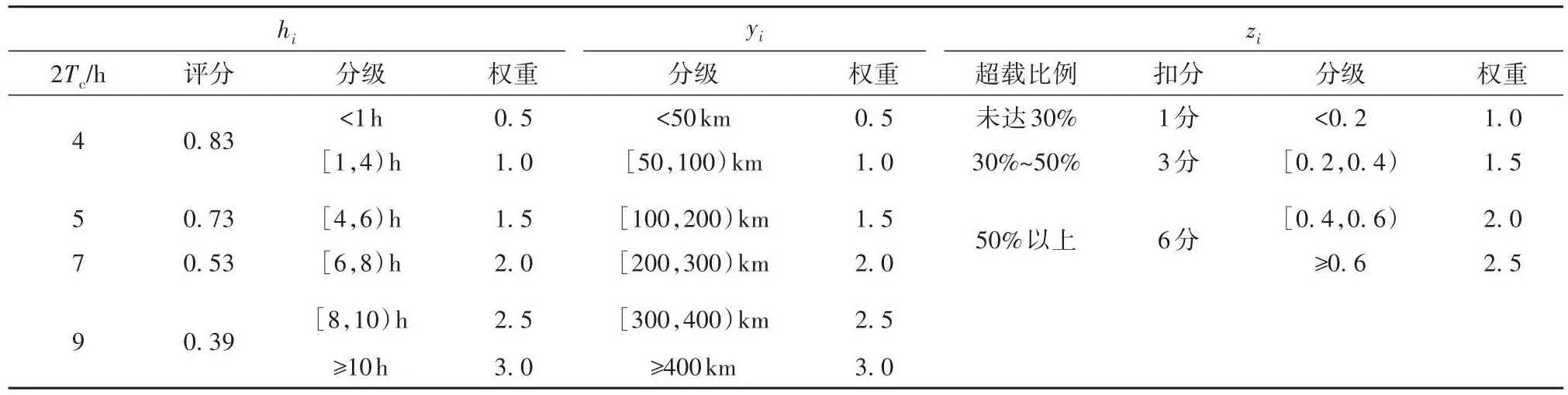
表2 驾驶时长、运输距离、超载次数权重分级Table 2 Weight classification of driving time, transportation distance and overload times
驾驶时长(加权)计算方法如式(4)所示,运输距离(加权)计算方法如式(5)所示:
(4)超载系数
首先,本研究以收费数据的入口总重作为单趟行程车货总重,计算车货总重Wi与核定总重W'i的比值k,若k大于1,该次行程ri为1,反之为0;其次,根据k的所属等级,为该次行程ri赋予权重zi;最后,计算每辆货车加权之后的超载次数Nload与统计时间内上高速总趟次Nsum的比值,结果即为货车超载系数Fload,即:
其中,超载次数权重zi的取值以《道路交通安全违法行为记分管理办法》中根据驾驶载货汽车载物超过最大允许总质量的百分比规定的扣分标准为依据,如表2所示。
(5)OD对稳定系数、出行端点稳定系数
本研究提出OD对稳定系数和出行端点稳定系数两个指标来衡量道路熟悉程度。两个指标采用信息熵来计算,先计算OD对Di出现的频率pi以及出行端点Yi出现的频率p'i,然后利用信息熵公式(8)计算二者的信息熵。其中,出行端点统计,即不分起、讫点,货车的所有出、入口收费站都统一统计。
计算OD对稳定系数时,式(8)中的Pi为OD对Di出现的频率pi,计算出行端点稳定系数时,式(8)中的Pi为出行端点Yi出现的频率p'i。
(6)车货总重
本研究用车货总重指标来衡量货车重量对于路面与行车安全的影响,以收费数据的入口总重作为单趟行程车货总重,统计样本时间内的总和作为车货总重指标。
1.3 基于货运风险特征画像的货车运行风险等级识别模型构建
如图2所示,基于高速公路收费数据挖掘、特征指标提取,将指标作为K-means++聚类算法的输入,通过肘部法则[15]确认最佳分类簇,然后获得货车货运风险特征画像分类结果,再利用熵权法对货车货运风险进行打分,最终确定各类别的风险等级。
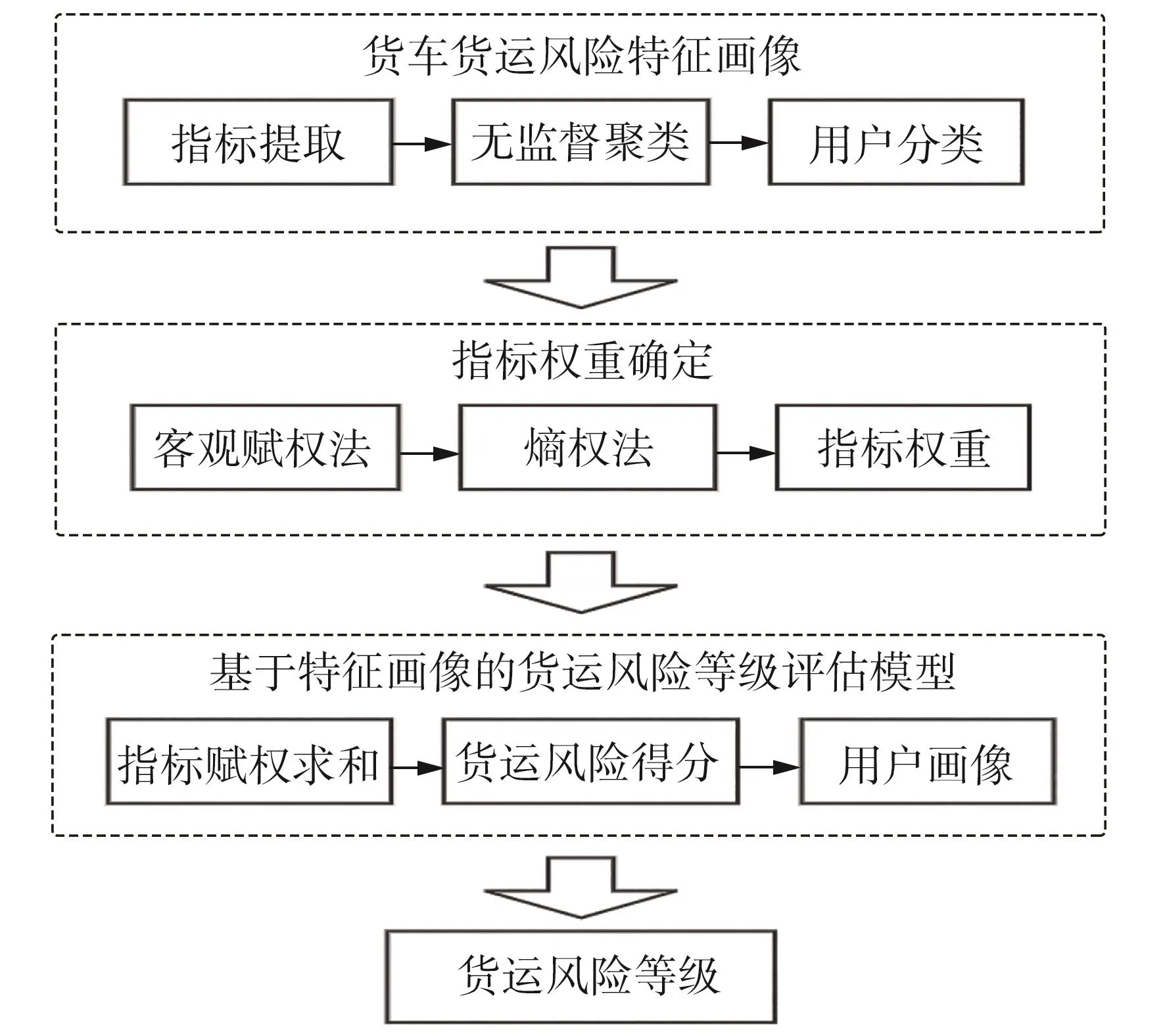
图2 风险等级评估模型示意图Fig.2 Diagram of risk level assessment model
1.3.1 基于K-means++的高速公路货车分类算法
K-means++聚类算法[16]对初始质心的选择进行了优化,使得各初始质心分布尽可能远,以消除K-means因生成较近的初始质心而产生局部最优解。本研究应用K-means++聚类算法对货车货运风险指标进行聚类,将车辆划分到不同类别。K-means++算法步骤如下:
(1)在数据集X中随机选取一辆货车作为第1个聚类中心c1。
(2)计算每个数据点x与已有聚类中心C之间的最短距离Dx,这个值越大,被选取作为聚类中心的概率就越大,接着计算每个样本点被选为下一个聚类中心点的概率P'x,最后按照轮盘法选择下一个聚类中心,即:
(3)重复步骤(2),直至选出所需的k个聚类中心点。
(4)针对数据集中每个样本x,计算它到k个聚类中心的距离并将其分到距离最小的聚类中心所对应的类Li中。
(5)针对每个类别Li,重新计算它的聚类中心ci(即属于该类的所有样本的质心),即
(6)重复步骤(4)和步骤(5)直到聚类中心的位置不再变化。
K-means++聚类算法需先确定最优的聚类数k,使聚类产生高的簇内相似度及低的簇间相似度。本研究将使用肘部法则保证选择最优的k值。
1.3.2 基于熵权法的货运风险评分模型
熵权法的基本原理是根据指标的可变性确定目标权重,目前已广泛用于多目标系统评价之中。本研究将采用熵权法对货车的货运风险评价打分,熵权法的计算步骤如下所示:
(1)数据归一化处理。将不同量纲的8个指标的数据aij同量纲化,得到同量纲化后的指标a'ij,即
式中,aij为第i辆货车的第j个指标,aj为所有货车的第j个指标。
(2)计算指标信息熵,其计算公式为
(3)计算各个指标权重,其计算公式为
(4)计算货车货运风险得分,即
2 基于广东省高速公路流水数据的高风险货车特征研究
2.1 数据准备
本研究的数据来源于广东省全网高速公路2022年3月1日—2022年5月31日货车收费数据,由于设备问题或人工操作失误等原因,收费数据可能包含个别错误数据。为提高研究精度,降低错误干扰,将存在车牌号错误、入口总重小于1 000 kg、行程距离小于1 km或大于2 100 km、行程时间小于2 min或大于2天、行程车速小于3.6 km/h或大于151.2 km/h、轴数大于6等情况的错误数据删除,保留数据118 558 117条,再排除上高速趟次少于4次的车辆对应的收费记录,最后保留2 018 082辆货车的收费记录。
2.2 指标提取与分析
基于广东省全网高速公路2022年3—5月共2 018 082辆货车的所有收费数据,提取8个货运风险指标。部分指标分布情况如图3、图4所示。
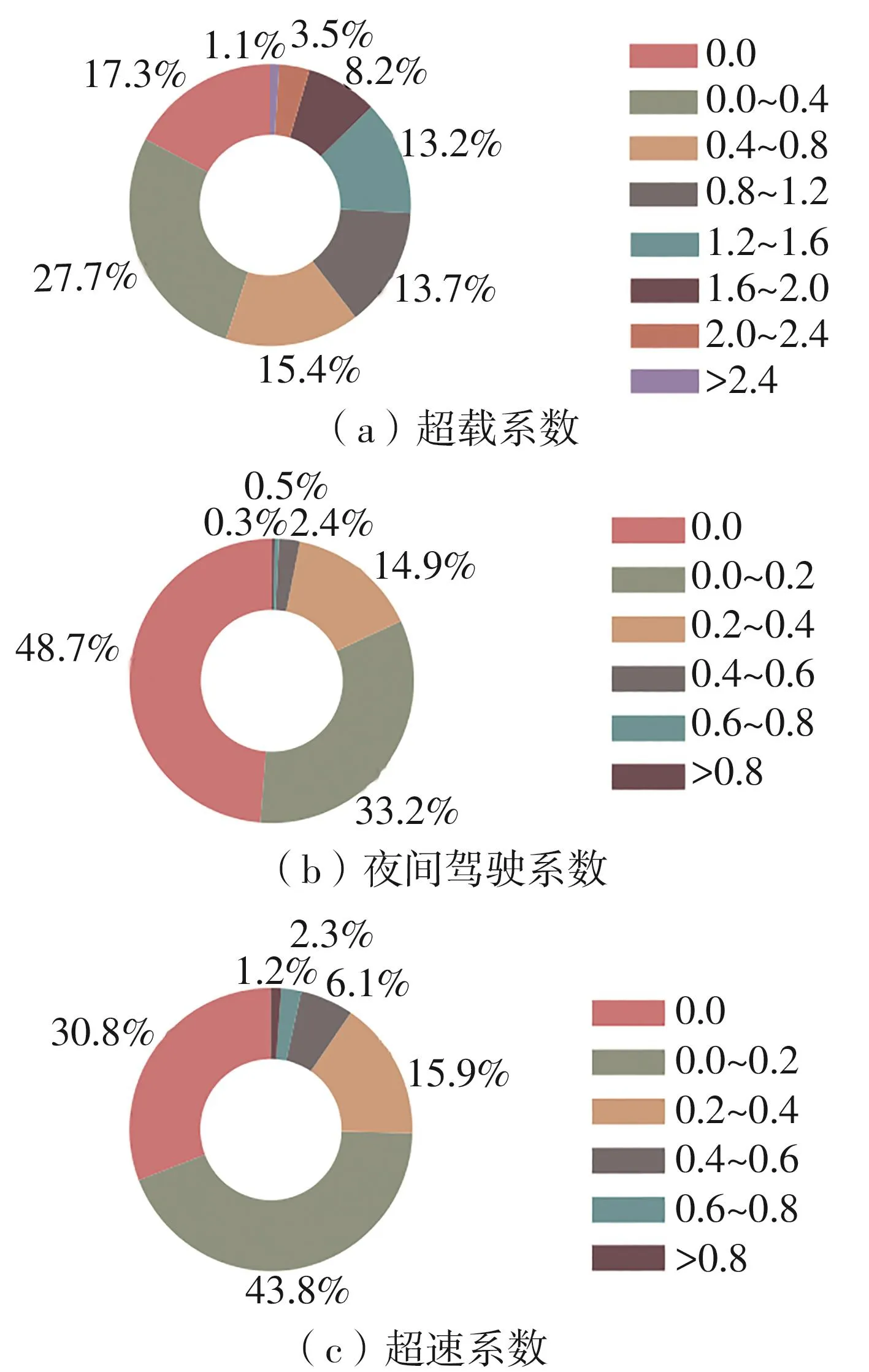
图3 超载、夜间驾驶、超速情况分析图Fig.3 Situation analysis diagram of overload, night driving and overspeed
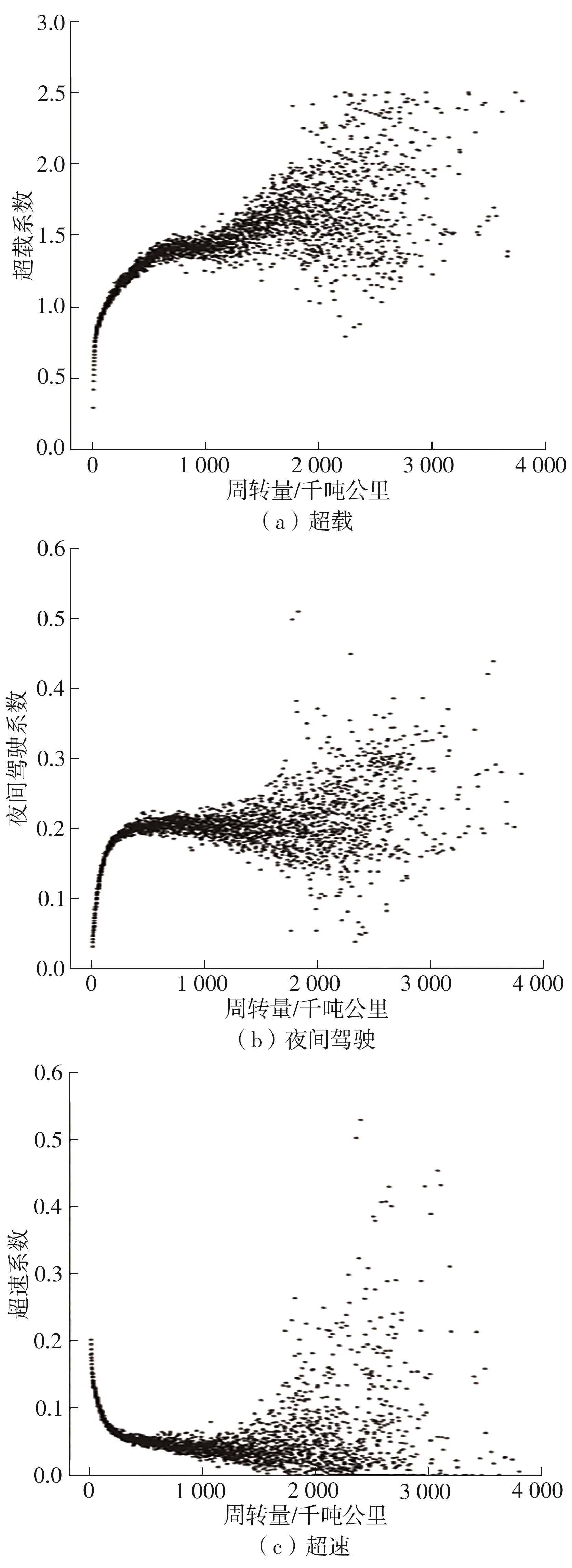
图4 超载、夜间驾驶、超速情况与周转量散点图Fig.4 Scatter plot of overload, night driving, overspeed and turnover
样本数据中,货车超载现象是比较严重,超载系数在0.0~0.4范围内的车辆占比45.0%,超载系数大于0.8的占比39.6%,周转量越大,超载系数均值越高,超载现象多发生在高运距、运输强度大的货车中。夜间驾驶系数在0.2以下的占比81.9%,说明大部分货车还是选择白天出行,夜间驾驶主要发生在高运距、运输强度大的货车中。无超速行为的货车占比为30.8%,占比最大的是超速比例在0.0~0.2之间的货车车辆,共43.8%;超速比例大于0.6的货车车辆占总货车的3.5%,该部分货车属于严重超速车辆,且超速行为主要发生在短途货车中。
2.3 聚类结果
为提高聚类准确性,避免各指标数量级不同对聚类结果造成影响,首先利用Z分数(Z-score)算法将指标标准化;然后根据肘部法则[15]确定类别数k为5时获得最优聚类效果;最后将8个指标放入K-means++聚类算法模型中,并将聚类k值设为5,最终聚类结果见表3。
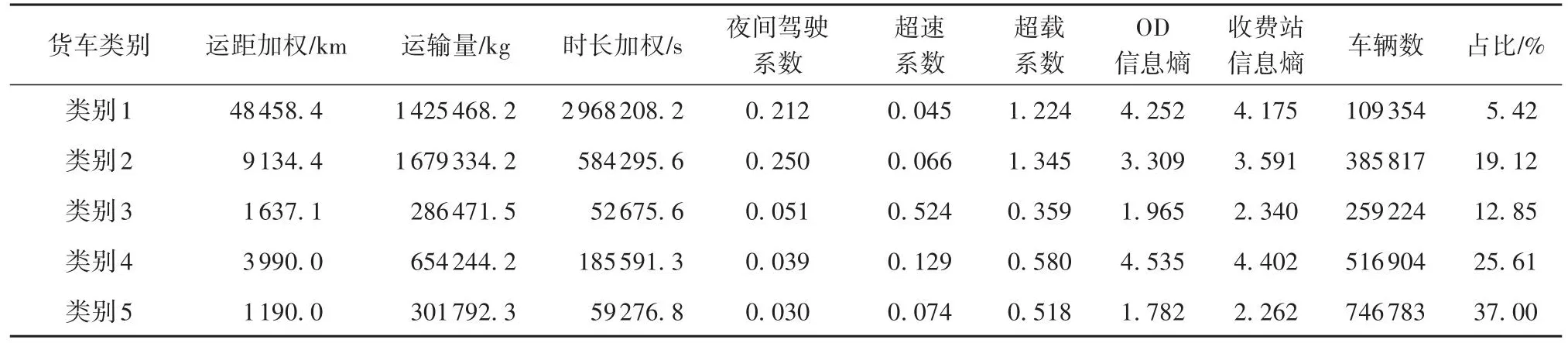
表3 聚类分群结果Table 3 Clustering results
再根据分类结果,统计各类车辆上高速趟次、T12(载重12吨及以上货车)占比、W(危险品运输货车)占比、货车私有占比、货车公司或单位所有占比和周转量等指标,结果如表4所示。
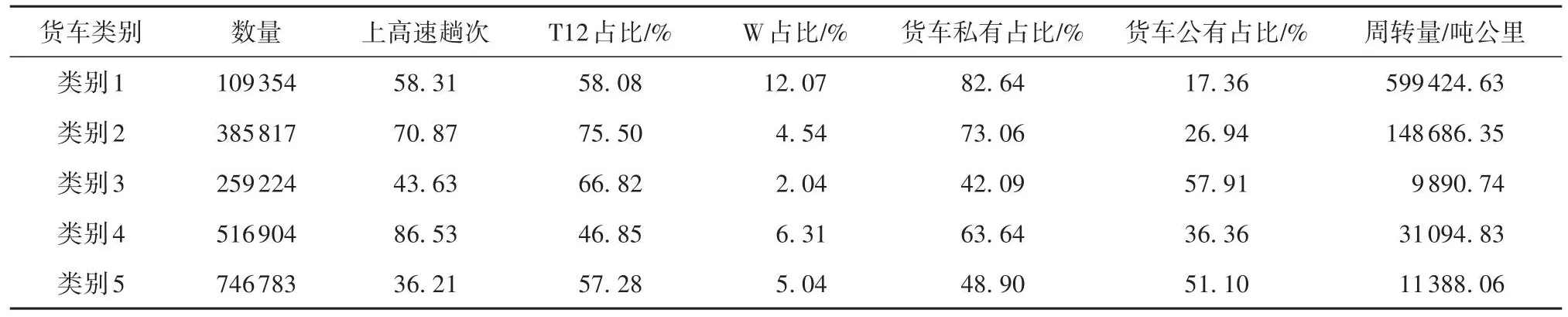
表4 各类货车相关指标Table 4 Relevant indicators of various types of trucks
2.4 风险等级评估
使用熵权法计算各个指标权重,结果如表5所示;权重结果基本符合实际公路货运情况。再利用式(15)计算每个司机的货运风险得分,结果如图5所示。
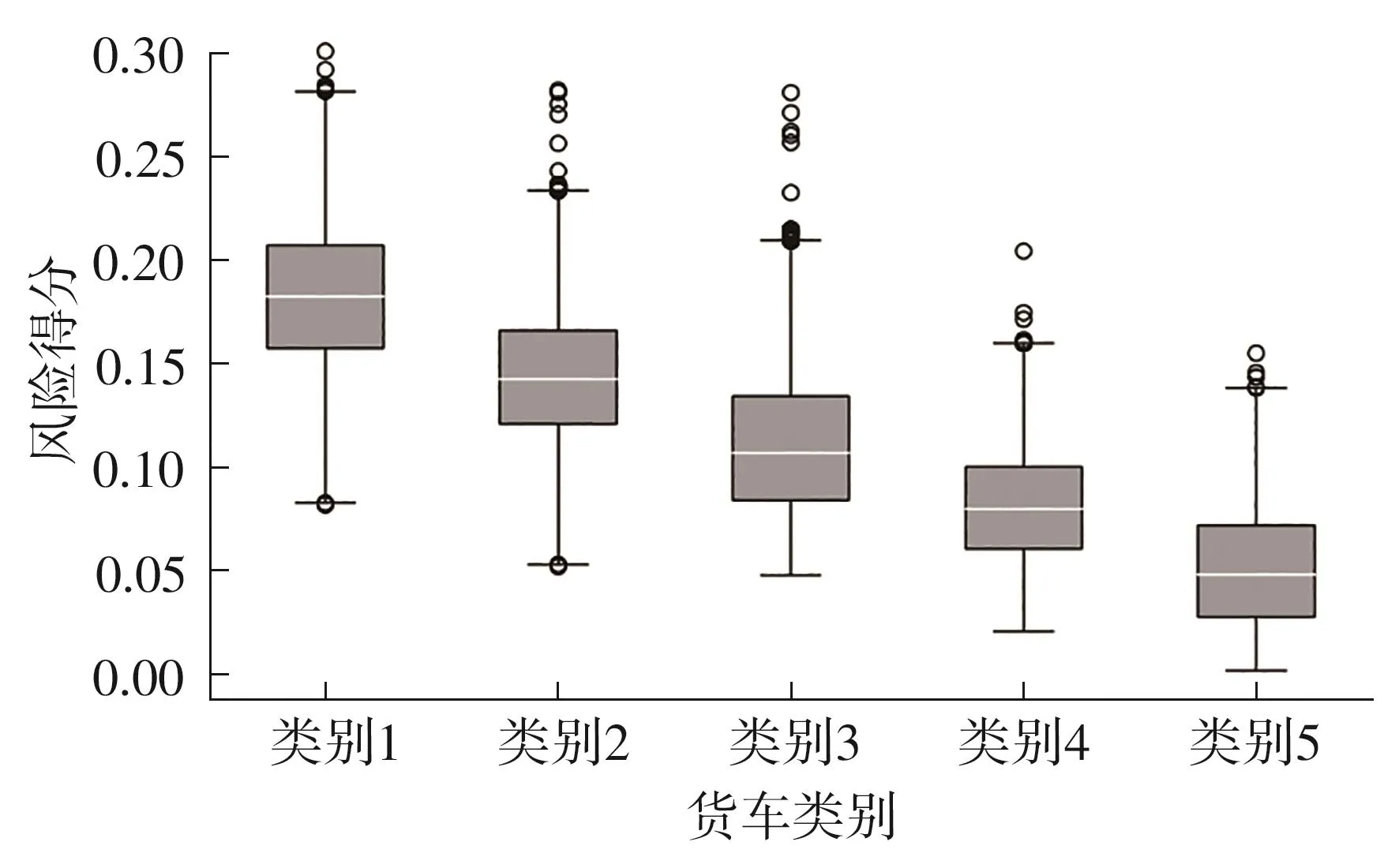
图5 5类货车货运风险得分箱型分布图Fig.5 Box type distribution map of freight risk score of 5 types of trucks
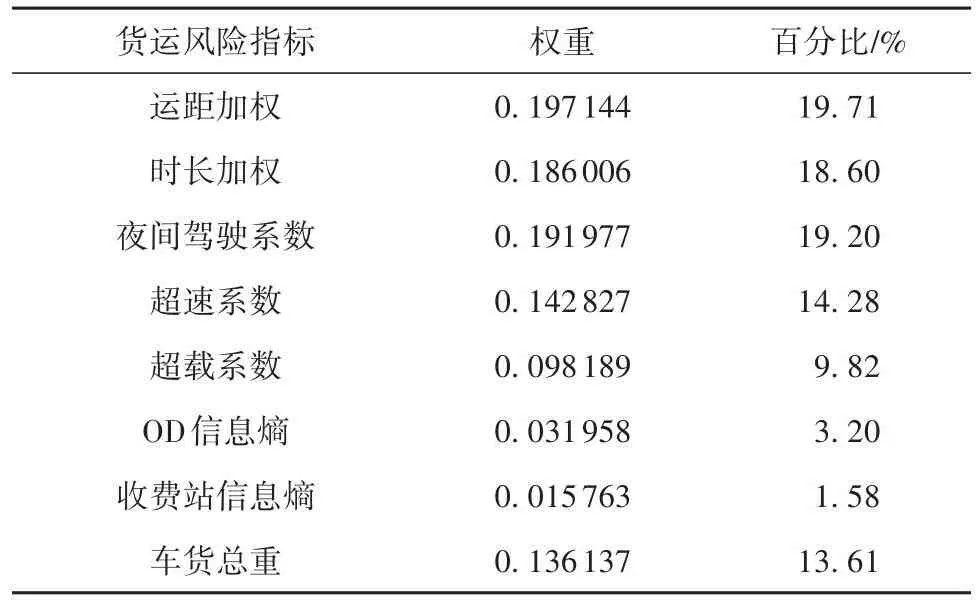
表5 指标权重Table 5 Weight of indicators
2.5 各风险等级用户分析
基于上述聚类结果和货运风险得分情况,以及相关指标数据,分析不同类别车辆的货运风险特征,并结合实际对各类群体进行定义。
(1)类别1货运风险特征明显,如图5所示,该类货车货运风险得分最高。从表3、表4可知,该类货车平均运距和平均驾驶时长远高于其余4类用户,运输强度高,运输范围广,超载系数均值也处于很高水平,超载行为普遍,夜间驾驶系数较高,道路熟悉度很低,危险品运输货车和私营货车占比均是5类货车中最高的,分别达到12.07%和82.64%。结合实际将类别1定义为“高风险高强度货车”,其在所有货车中占比为5.42%。
(2)类别2相比与3、4、5类车辆,也拥有较高的运输强度,夜间驾驶系数和超载系数均是5类用户中最高的,分别为0.25、1.345,夜间驾驶行为和超载行为普遍,拥有最高的载重12吨及以上货车和危险品运输货车总占比,私有属性也较为明显,结合实际将该类定义为“较高风险夜间驾驶超载货车”,其在所有货车中占比为19.12%。
(3)类别3与类别5货运风险特征大体相似,运输距离、运输量、驾驶时长均属于较低水平,运输强度不高,夜间驾驶和超载行为也属于正常水平,道路熟悉程度和公营货车比例均较高,运输路线重复率高,货车公有属性显著;但类别3的货运风险得分比类别5的高,原因是类别3的超速系数均值远高于其余类别,达到0.524,超速行为普遍,类别5在统计周期内上高速趟次均值最少,为36.1。结合实际,将类别3定义为“中风险超速货车”,其在所有货车中占比为12.85%,将类别5定义为“低风险低频货车”,其在所有货车中占比为37.00%。
(4)类别4上高速趟次均值为86.53次,但道路熟悉程度低,载重12吨及以上货车和危险货物运输总占比与其余类别相比较低,夜间驾驶行为少,超速现象少,超载行为不普遍。结合实际,可将该类用户定义为“低风险高频货车”,其在所有货车中占比为25.61%。
3 模型效果评估
为对文中提出的模型进行效果评估,查询同期广东省某事故数据库,查询5类风险等级货车中发生事故的货车占比,以此作为风险系数,并以第5类车为基数1,其余风险类型货车相对风险系数如图6所示。
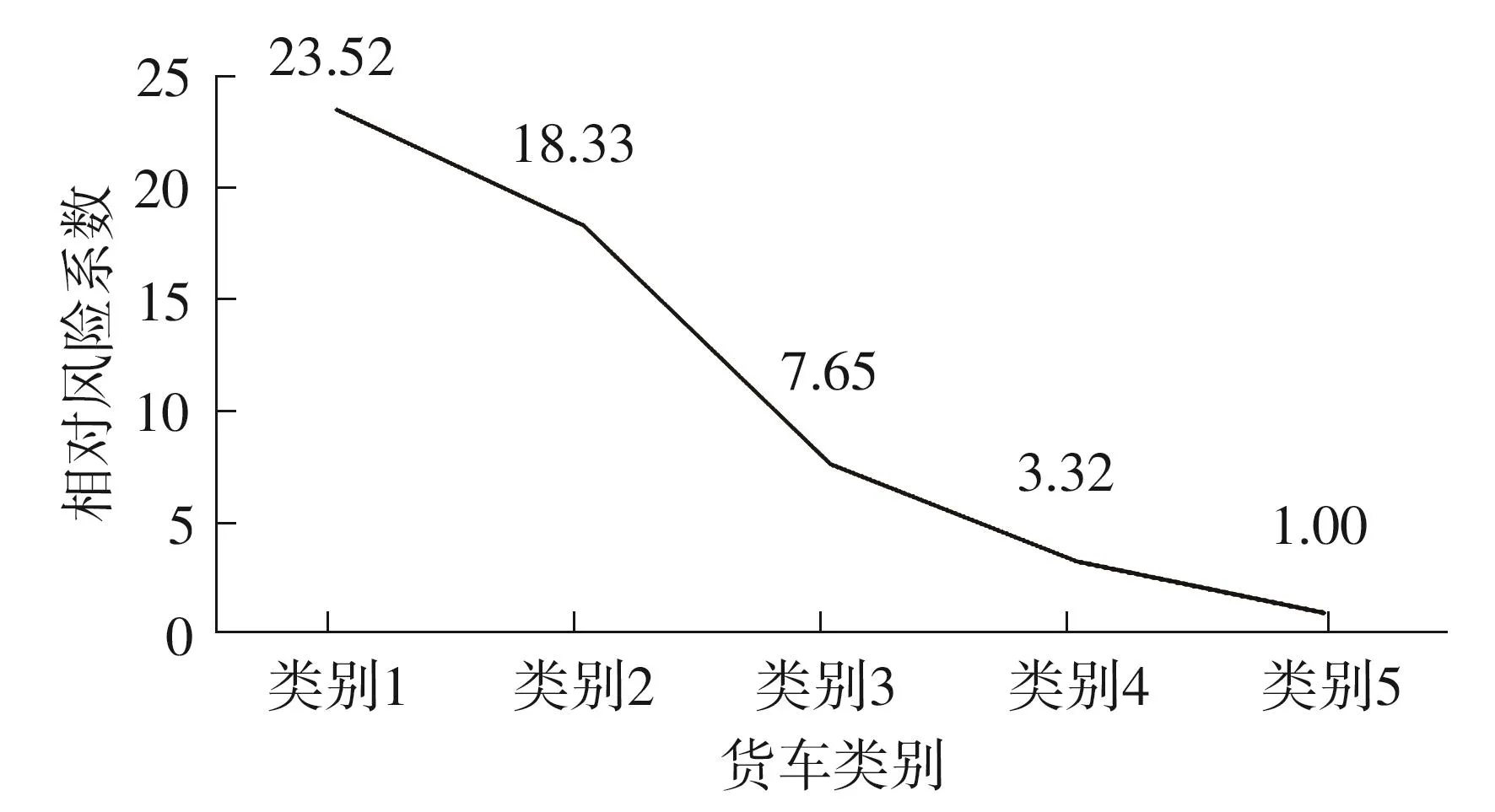
图6 5类货车相对风险系数折线图Fig.6 Box type distribution map of freight risk score of 5 types of trucks
由此可知,相对风险系数与模型识别结果是一致的,可以验证本文货车货运风险等级识别的有效性。
4 分类结果分析及应用
本研究最终将车辆划分为5类,并分别定义为“高风险高强度货车”“较高风险夜间驾驶超载货车”“中风险超速货车”“低风险高频货车”“低风险低频货车”车辆群体,进一步分析各类别的出行特征,高速公路交管人员可基于此针对不同风险等级车辆进行精细化管理。
对于运输强度高、运输范围广、超载行为和夜间驾驶行为均较为普遍、危险品运输货车占比高的“高风险高强度货车”,可通过监管平台为其设置疲劳驾驶语音提醒功能,并加强货车载重监管力度,关注夜间灯光操作规范,针对该类货车密集区域或时段,加强高速公路巡逻、检查力度,以强化事前预防。
对于夜间驾驶行为和超载行为普遍,载重12吨及以上货车和危险品运输货车总占比大的“较高风险夜间驾驶超载货车”,加强高速入口货车载重核查,强化夜间行车灯光使用监管,结合重点货车监管、优惠政策,重点关注、统筹运营管理。
对于道路熟悉程度高,货车公有属性显著,超速行为普遍的“中风险超速货车”,可进行企业安全驾驶宣传,加强超速监测。
5 结语
本研究基于高速公路收费数据,以货车为研究对象,应用K-means++算法和熵权法,构建了基于货运风险特征画像的货车运行风险等级识别模型,基于广东省全网高速公路2022年3个月的货车收费数据,利用所提出的模型,提取出5.42%的“高风险高强度货车”车辆和19.12%的“较高风险夜间驾驶超载货车”,并使用同期广东省某事故数据库数据验证了模型的有效性。基于风险等级识别结果,交管部门可进行高风险车辆识别、超载超限重点监查、特定消息推送引导车辆安全驾驶等工作,以提升行业安全管理水平。
本研究只基于高速公路收费数据获取“过程”指标对货车进行货运风险标签体系构建,未来可利用全球卫星定位系统(GPS)轨迹数据等来补充更多“瞬时”指标,丰富标签体系;货运风险还会受公路管理、交通安全设施、照明系统等交通工程设施的影响,在未来研究中,可以综合考虑此类因素;还可以从重点物资运输、经济效益等角度,构建重点货车标签体系和识别模型。
