基于AST的程序代码抄袭检测方法研究
2023-07-26朱良梅洪晓彬
朱良梅,洪晓彬
(广州工商学院 工学院,广东 广州 510850)
0 引言
代码抄袭是指复制或拷贝代码而不做任何改动或只是进行适度的修改,代码抄袭问题在高校程序设计类课程中普遍存在。对学生的调查研究表明:33%~75%的学生承认在学习期间至少抄袭过一次[1-2],抄袭导致考试出现更高的不及格率和较低的考试成绩,考试不及格的学生中大约有84%曾经抄袭编程作业[3]。代码抄袭现象泛滥已经严重影响学生能力的培养和教师教学的效果,然而在众多作业中,依靠人工方式分辨出每份作业是否抄袭和作业中哪些地方涉及抄袭是一件费时费力的事情。为了更高效地检测作业抄袭问题,出现了一大批程序代码抄袭检测工具,这类工具通过测量代码对的相似度来判断是否涉及抄袭,相似度越高则抄袭的可能性越大,较低的相似度则意味着两份作业没有抄袭。代码相似度检测是代码抄袭检测的核心,代码相似度检测技术的研究具有重要意义。
目前常见的相似度检测系统采用较为简单的文本或者词法分析,抗混淆能力较弱,无法检测控制结构等价替换等抄袭行为;一般在整个代码提交集合中进行检测,缺少有效筛选检测候选集的方法,计算量较大。本文提出了基于抽象语法树(AST) 的Java程序代码抄袭检测方法,首先通过语法分析生成程序的AST,然后遍历AST,过滤不重要的节点,对选择和循环结构语句进行语义转换,赋予节点语义信息,构造程序的特征序列;统计特征序列的节点频度,生成特征向量,通过聚类分析将同一批次作业划分为若干较小的“抄袭团伙”;在“抄袭团伙”内使用贪婪字符串匹配算法比对特征序列计算程序相似度。
1 相关工作
早期的代码相似度检测技术的研究主要基于属性计数的方法,其基本原理是从源代码中抽取各种属性度量元作为相似度评判的依据。该方法与所用的程序设计语言无关,实现较为简单,但是不能分析部分程序段的抄袭,而且增加向量维数并不能改善检测效果。
后期的研究主要考虑的是代码的结构信息,目前基于结构度量的相似度检测方法被主要包括:基于文本、基于词法、基于语法、基于语义的检测方法。基于文本的检测方法将源代码看作字符序列,比较代码字符序列相似度并且返回字符串匹配结果集。这类方法易于实现,而且与语言无关,但是不能很好地检测出在句法和语义层面上的代码修改。基于词法的检测方法将代码转换成token(符号、词汇)。将token 序列视为抽象的代码表示。相比于基于文本的代码表征方法来说,这种方法能够匹配到代码的特有信息,但从本质上没有考虑代码中所包含的结构信息,对代码语句修改比较敏感。基于语法的检测方法考虑源代码语法规则,将源代码转换。
为其对应的抽象语法树。基于树的方法可以避免由于格式和句法问题引起的问题,能够考虑到源代码的结构特性,其缺点是不能识别出标识符和文本值的不同,并且计算开销大。基于语义的方法不仅希望获得代码之中的结构信息,还试图获得代码中的语义信息,复杂度非常高。除此之外,还有学者提出了新的检测方法,比如,基于深度神经网络的Oreo[4]、基于递归自编码器和程序向量树的检测方法[5-6]等。
2 基于AST 的程序代码抄袭检测方法
2.1 生成程序AST
依次读取程序代码集中的一个个代码文件,利用Eclipse 平台的JDT(Java Development Tool) 工具套件自动化抽取代码集中Java 程序的抽象语法树。图1 所示为由Java 语言编写的一段示例代码及其对应的AST,AST 自动去除了原代码中的注释、空格、换行等,为抄袭检测降低了干扰;此外,AST 中除了与原代码相对应的叶子节点外,新增了大量非叶子节点,使得整个AST的节点序列长度相比原代码长度有明显增长。
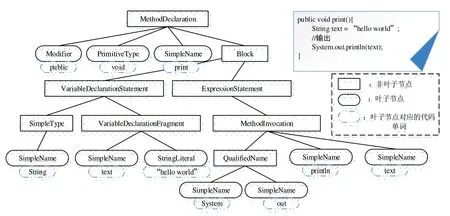
图1 Java示例代码和抽象语法树
2.2 构造特征序列
基于树进行子树匹配,计算开销较大,本文对AST进行深度遍历,将节点序列转换为字符串特征序列。由于AST 的节点序列长度相比原代码长度有明显增长,本文在遍历过程中通过节点过滤,有效缩短序列长度;此外,通过对等价控制结构进行转换、对语义模糊节点赋予语义信息、运算符分类等,达到提取AST的结构和语义特征的目的。
2.2.1 节点过滤
1) 过滤函数外节点
由于一个类所实现的功能主要是由其行为即函数所决定的,其他节点与类功能没有直接联系,并且这部分节点极易被修改,以达到躲避抄袭检测的目的。因此,本文在遍历AST 节点序列时,忽略除函数以外的其他节点,只对文件内的若干函数及其内部节点进行遍历,从而自动排除一系列简单的代码修改所带来的噪声影响。
2) 过滤无具体语义的节点
通过对AST包含的各种节点类型进行比较分析,发现其中有一些节点并不包含具体的语义信息,如图2 中的节点ExpressionStatement、QualifiedName,这些节点对于代码相似度检测意义不大,本文予以过滤。
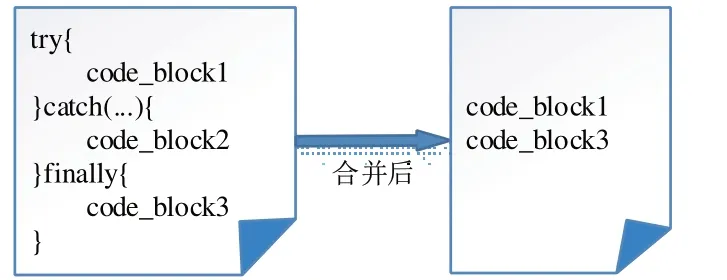
图2 合并try-catch-finally语句
3) 过滤输出日志相关的节点
对于常见的通过增加输出日志的代码以改变原程序结构的抄袭行为,获取METHOD_INVOCATION类型节点的被调用的函数名,过滤掉与输出日志相关的函数调用,如println、print、debug、info、error、log等。
2.2.2 等价控制结构转换
1) 选择结构
对if-else、switch-case 和条件判断语句三种选择结构进行等价处理,转换为SELECT_CONDITION 和SELECT_BODY两类节点。
2) 循环结构
对while、do-while 和for 三种循环结构进行等价处理,转换为LOOP_CONDITION和LOOP_BODY两类节点。
2.2.3 赋予语义信息
有些节点包含的语义信息模糊,需要结合上下文为这些节点进一步赋予语义信息。如将Block类型的节点分为:METHOD_BODY、LOOP_BODY、SELECT_BODY。
2.2.4 运算符分类
对前缀、中缀、后缀表达式按照运算类型分为NUM_EXPRESSION、RELATION_EXPRESSION、LOGIC_EXPRESSION、BIT_EXPRESSION和ASSIGN_EXPRESSION,需要注意a++、++a、a=a+1,这三类语句虽然写法不同,但是实现的功能都是自增1,统一记为ASSIGN_EXPRESSION。
2.2.5 声明语句拆分
变量声明语句转换为节点VAR_DEF,将合并的多个变量的声明语句拆分成多个单独的变量声明;对带有初始化值的变量声明语句拆分为变量声明VAR_DEF和赋值ASSIGN_EXPRESSION。
2.2.6 try-catch-finally语句合并
对try-catch-finally 语句进行合并,如图2 所示,只关注与函数功能相关的代码段code_block1 和code_block3,忽略与对异常的处理相关的代码段code_block2。
经过对节点的过滤、合并、分类、转换后共汇总得到18种节点类型,同时为了进一步缩短节点序列的长度,分别使用一个唯一的字母代替原节点类型,每个程序文件由这18个字母的不同组合表示,最终形成程序的特征序列。节点类型与对应字母关系如表1所示。

表1 抽象语法树节点类型和对应的字母
2.3 聚类分析和抄袭检测
为了更高效地筛选抄袭检测候选代码集,使用聚类算法将代码集划分为若干“抄袭团伙”。统计程序特征序列中不同节点类型的频度,将程序特征序列构造为一个18维的整型特征向量,向量中的每一维代表一种节点类型,每一维的值代表该节点类型的频度。例如,图2 中示例代码的节点类型序列为:METHOD_DEF、METHOD_BODY、VAR_DEF、ASSIGN_EXPRESSION,特征序列为:NPJI,特征向量为(0,...,1,1,...,1,0,1,0,0) ,其中第9、10、14、16维的值为1,其他维的值为0。
程序代码作业集被转换为特征向量的集合,使用K-means 算法完成向量聚类,找出代码作业集中的“抄袭团伙”。K-means算法将一组特征向量划分为K个无交集的簇,具有原理简单、收敛速度较快的特点,但需要用户指定聚类个数K。为了确定较为合适的聚类个数,使用轮廓系数作为选择聚类个数的依据。根据“簇内差异小,簇外差异大”的原则,整个数据集的平均轮廓系统越接近1,聚类效果越好[8]。依次计算当聚类个数在【2,α×N】范围内对应的轮廓系数,其中N为向量集合中的总的向量个数,α(0<α<1) 为范围系数,轮廓系数最接近1处对应的聚类个数则为合适的K值。
在各个“抄袭团伙”内使用贪婪字符串匹配算法(GST)[7]两两比对程序的特征序列,尽可能找出两个特征序列中的匹配。GST算法运行结束后,会得到最大匹配集合,通过该集合可以进行两个程序的相似度计算。
3 实验与分析
高校中比较流行的程序代码抄袭检测系统主要有德国Karlsruhe 大学的JPlag[9]和美国Stanford 大学的Moss系统[10],其中Moss系统稍逊色于Jpalg系统[11]。目前还没有一个公开且真实的包含大学生抄袭作业用例的数据集,因此本文从学生提交的Java编程作业中挑选具有典型抄袭手段的代码进行聚类和相似度检测,并与JPlag系统的检测结果进行对比分析。
本文选取“求最大公约数”的若干程序代码进行实验,作业总计39 份,其中有3 份不同版本的原始程序代码,分别是A1、A2、A3,其余36 份作业是在原始程序代码基础上使用抄袭手段[12]后得到的抄袭代码集,抄袭代码集与对应的抄袭类型如表2所示。
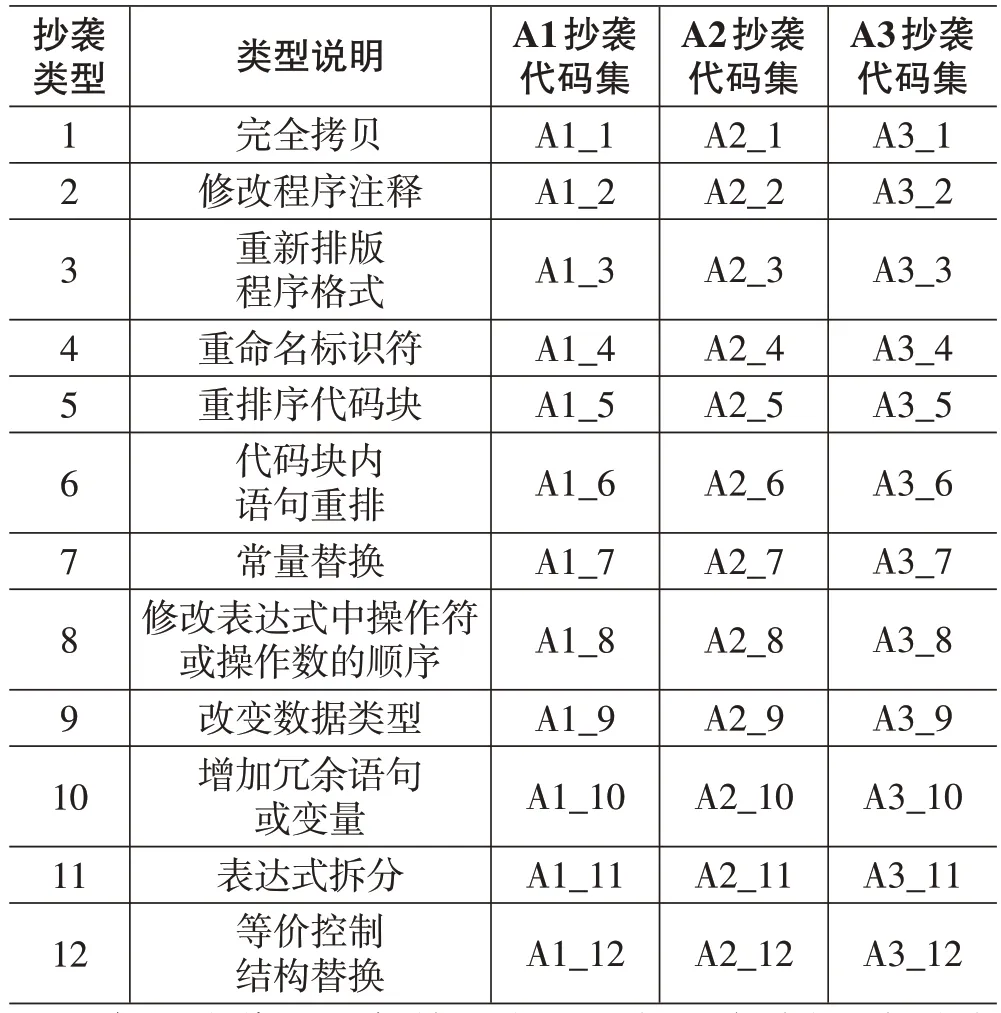
表2 程序代码集与对应的抄袭类型
将39个代码文件特征向量进行聚类分析,实验中指定轮廓范围系数α=0.3,对比不同聚类个数下的轮廓系数,发现当聚类个数为3 时,轮廓系数最接近1,聚类算法准确找到了A1、A2、A3共3个“抄袭团伙”。
3.1 代码相似度计算结果对比分析
本文在A1、A2、A3三个代码集中,分别计算12种抄袭行为相对于原始程序的相似度,并将计算结果的平均值与JPlag系统的计算结果的平均值,以及3份原始代码之间的相似度进行对比,对比结果如图3所示。
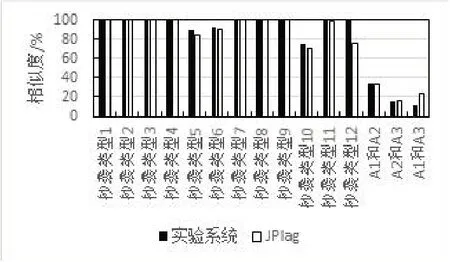
图3 相似度计算结果与JPlag系统的对比
结果表明,实验系统对于存在抄袭行为的代码对,能够得到较高的相似度,对于不存在抄袭行为的代码对,能得到较低的相似度,而且所有存在抄袭行为代码对的相似度明显高于不存在抄袭行为的代码对的相似度;对各种抄袭行为具有鲁棒性,尤其是对于抄袭类型12(等价控制结构替换),实验系统相似度结果明显高于JPlag系统;对于抄袭类型10(增加冗余语句或变量)的计算结果不够理想,因为冗余语句的插入有可能切断原有的匹配字符串使其低于最小匹配长度,导致匹配串变少。
3.4 抄袭检测结果对比分析
实验代码总计39份,JPlag系统检测共产生741个代码对,相似度分布范围较广,其中大部分代码对的相似度低于40%;实验系统对39 份代码进行聚类,代码被分成3个“抄袭团伙”,分别在抄袭团伙内部计算相似度,共产生234 个代码对,代码对数量相较JPlag系统有明显减少,并且相似度低于40%的代码占比为0,可以避免低阈值下出现误判现象。相似度检测结果分布对比如图4所示。
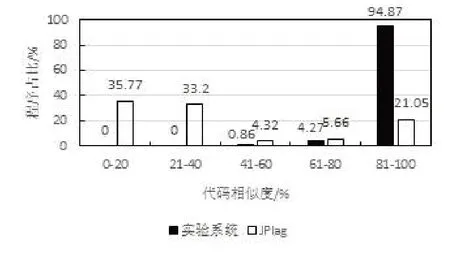
图4 相似度分布与JPlag系统的对比
4 结束语
提出的基于AST的程序代码抄袭检测方法,以文件内的函数集合而不是整个文件作为检测对象,过滤掉与功能关系不大而极易被修改产生噪声的大部分代码,对AST节点进行过滤、合并、分类、转换,对语义模糊的节点结合上下文赋予语义信息,提高了对等价结构转换抄袭类型的检测灵敏度;使用聚类分析将原本较大的代码集划分为若干小的“抄袭团伙”,减小计算量的同时,解决低阈值下抄袭检测误判的问题。然而,实验部分所使用的数据集较小,还需要使用更大的数据集对文中方法进行验证。另外,实验系统仅实现了对Java代码的抄袭检测,后续考虑扩展到多语言的抄袭检测。
