机器学习课程实践教学案例设计与分析
——以虚假新闻识别为例
2023-07-26熊蜀峰孙彤刘亮亮孙肖云
熊蜀峰,孙彤,刘亮亮,孙肖云
(河南农业大学 信息与管理科学学院,河南 郑州 450002)
0 引言
机器学习作为人工智能技术的一个重要分支和基础技术被越来越多的人所熟悉,机器学习研究计算机如何模拟人脑和人类的学习机制,组织现有知识以不断提高自身性能,并使计算机智能化。特别是在数据科学和大数据领域,机器学习是最核心技术之一,熟练使用机器学习和其他知识挖掘技术是培养合格数据科学人才的基本要求[1]。因此,越来越多的高校在人工智能、计算机科学与技术、数据科学和大数据技术等本科专业(本文将这些专业称为计算机大类专业)开设机器学习课程。
由于该课程实践性较强,因此在安排机器学习理论知识的讲授外,还同步进行实践教学,使学生通过动手实践加深对理论知识的理解[2]。以河南农业大学为例,其开设的机器学习课程教学计划总学时是48学时,其中理论与实践比例为1∶1,即理论课24 学时,实验课24学时,旨在夯实学生的理论知识,同时培养学生的动手实践能力。
分类问题是机器学习应用中最普遍的任务,具体应用场景包括新闻主题分类、文本情感分析、公文分类、虚假新闻识别[3-5]等。通过实际应用场景任务训练,可以锻炼学生解决实际问题的能力,同时也能激发学生对本课程的学习兴趣[6]。因此本文引入了虚假新闻检测设计实例,作为机器学习课程的项目教学案例进行探讨与研究。
1 机器学习实践教学案例
1.1 案例描述
本案例以社交媒体发布的图文类新闻消息为分析对象,目的是通过应用机器学习相关技术,设计出多模态的虚假新闻检测模型,用于对社交媒体消息进行类别预测(是和否分别代表虚假新闻和真实新闻)。按照机器学习的流程,首先将数据集划分为训练集、测试集和开发集。训练集主要用于机器学习模型的训练从而获得最优权重参数,开发集主要用于模型超参数调优和模型过程验证,测试集用于评估模型的性能。
1.2 数据集
在这个实验中,案例使用相关学术文献公开的多模态社交媒体新闻信息数据集,这个数据集由9 527条记录组成。这个数据集中的所有消息都已标注了类别信息,其中虚假新闻被标记为1 (4 748 条记录),而真实新闻被标记为0 (4 779 条记录)。表1 为数据集的统计信息。
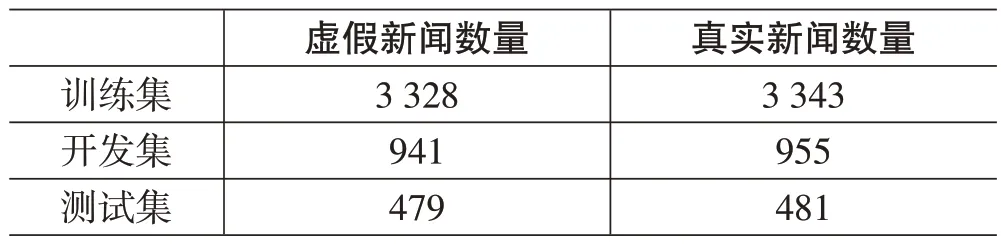
表1 数据集统计信息
1.3 模型设计
本案例训练学生的多模态信息处理能力,因此模型的输入是每条新闻的文本和图像,分别利用BERT 与VGG19提取文本特征与图像特征。第二阶段是特征融合,主要分两次进行。第一次使用Co-Attention捕获文本特征与图像特征之间的关系,第二次则是将第一次融合之后的结果与文本特征进行融合,最终经由带有全连接层的Bi-LSTM网络得到预测结果,即新闻的标签(虚假的或真实的)。模型的整体结构如图1所示。
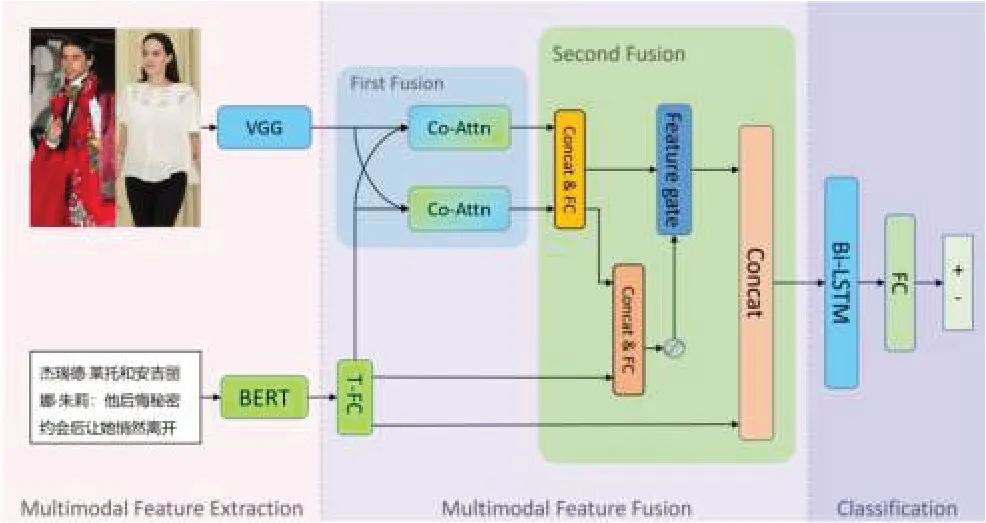
图1 模型总体结构
1.3.1 文本特征抽取
此案例第一部分是使用BERT预训练模型来提取文本特征。此模块的目的是向学生演示如何采用最新的神经网络模型来对特征进行分布式表示。让学生直观地学习传统的稀疏表示与分布式表示之间的差异。BERT 模型是基于Transformer[7]的大规模预训练语言模型,可以独立地在各个大型数据集上进行预训练,然后在特定的任务中进行微调,使其适用于最终的目标任务。BERT利用Transformer编码器构造了一个多层双向的网络,由多层Transformer编码器堆叠而成,每一层编码器由一个多头自注意力子层和一个前馈神经网络子层组成。提取文本特征的过程可以用公式表示为:
其中ti表示输入的第i 个句子,ht i是其经过BERT嵌入后的特征向量。
1.3.2 图像特征抽取
此模块的目的是引入经典的图像特征抽取模型,通过对VGG的模型用法演示,训练学生对图像特征的处理能力。VGG 是代表性的CNN[8]网络之一,VGG19源自VGG 架构,由不同的层组成,广泛应用于图像分析。VGG19共有16个卷积层和3个全连接层,此外还有5个最大池化层分布在不同的卷积层之下。由于网络结构的深化,VGG19模型在进行图像特征提取时具有更强的学习能力。在VGG19网络结构中,卷积核的数量从第一层的64 个开始,逐渐增加到512 个,之后保持不变。此外,由于大量使用小型卷积核(Smallsized Convolutional Kernals) ,VGG19 模型在训练时通常只需要更少的迭代来收敛,从而提高了训练速度。
提取图像特征的过程可以用公式表示为:
其中i表示输入的原始图像,ki是VGG19 提取的图像特征向量。
1.3.3 多模态特征融合
本部分重点演示特征融合方法,特别是图像与文本两大主流特征信息间的融合。案例中的多模态特征融合主要是由Co-Attention层完成的,其包括两个并行的Co-Attention块,Co-Attention块的结构如图2所示。
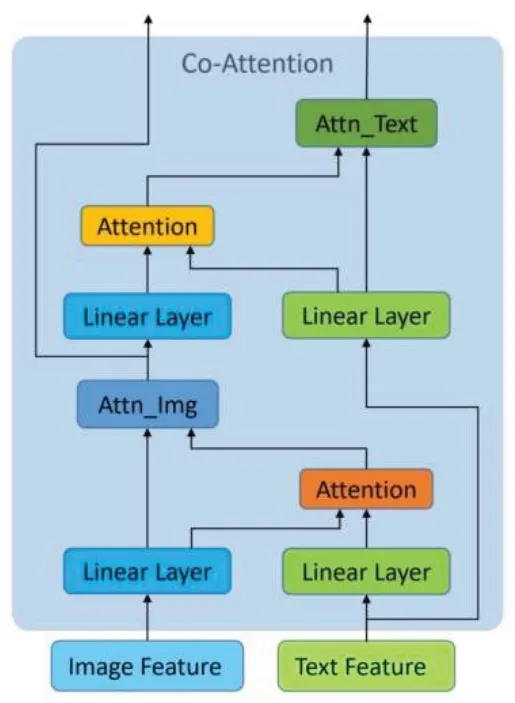
图2 Co-Attention组件结构
Co-Attention块与传统transformer相比,不同之处在于其多头注意力的KEYS、VALUES 和QUERYS 来自不同的地方,即如果QUERYS来自文本,那么KEYS和VALUES则来自图像,反之亦然。如公式所示:
通过将图像特征与文本特征并行排列,组合成一个Co-Attention 层,Co-Attention 块A 以文本特征作为Q,图像特征作为K和V;Co-Attention块B以图像特征作为Q,文本特征作为K和V,这样就实现了文本和图像之间信息的交互学习。
1.3.4 分类模块
此模块是模型的最后一个部分,也是最关键的结果输出层。主要展示目标函数的选择。案例中融合后的特征经过BiLSTM 网络和全连接层处理之后,最终通过Sigmoid 函数预测分类结果,采用二元交叉熵来定义目标函数,如公式所示:
其中,y是新闻的真实标签,y̑是新闻的预测标签。
2 案例仿真与结果分析
此案例模型的构建、训练与测试采用PyTorch 框架进行,仿真数据可视化采用TensorBoard 展示,主要目的是训练学生的仿真实验操作与数据分析能力。PyTorch 是首个运行时定义深度学习框架,与Tensor-Flow 等静态图形框架的功能和性能相匹配,非常适合从标准卷积网络到时间递归神经网络等所有网络的构建。TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,TensorBoard可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),并且很直观地进行参数的选择。它通过运行一个本地服务器,来监听6006端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。
2.1 模型整体性能仿真结果
为了验证所提出的模型的有效性,案例选取分类问题常用的Precision、Recall、F1和Accuracy 四个量化指标检验模型的性能。图3是绘制出的模型性能柱状图,结果表明模型在3个指标均达到了90%以上。
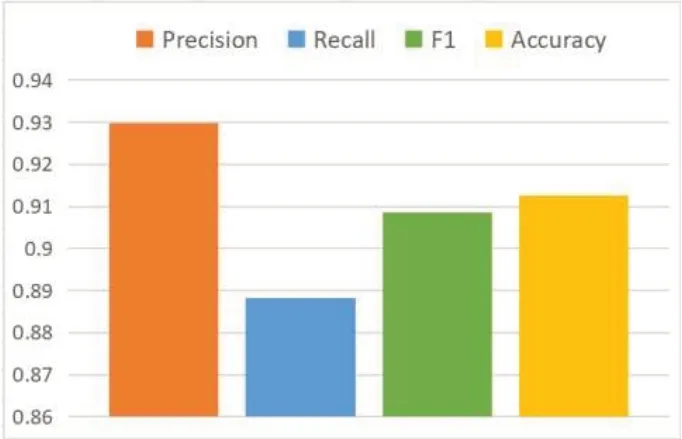
图3 模型性能柱状图
为了培养学生调试模型的能力,案例中采用可视化技术给出了模型训练过程中的Accuracy 变化图与训练轮次-损失值(epoch-loss) 对比图,如图4。随着训练轮次的增加,Accuracy 上升与Loss 下降逐渐平缓,因此在实际工程项目中需要考虑性能与时间耗费上的平衡点。
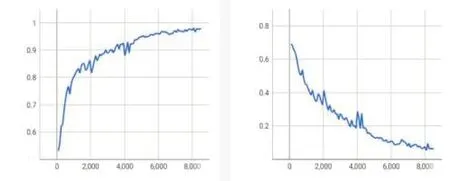
图4 Accuracy与Loss变化图
2.2 融合模块效果分析
在调试模型的过程中,通常需要分析模型中的各个组成部分的重要性以及对性能提升的贡献度,在机器学习理论中引过程被称为消融实验(Ablation study)。本案例在开发集上进行了消融实验,以研究两次融合组件的有效性。图5给出了完整的模型(蓝线)、去除第一次融合后的模型(黄线)和去除第二次融合后的模型(绿线)在每一个轮次训练结束后的性能对比。如图5所示,第二次融合组件去除后,模型性能有很大的下降,从而可知第二次融合组件的贡献大于第一次融合,也反映出文本模态在虚假新闻检测中的主导地位。
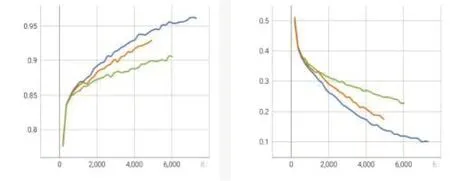
图5 融合模块效果对比(左子图为Accuracy,右子图为Loss)
3 结束语
机器学习课程在河南农业大学开设了多年,教学团队积累了丰富的教学案例资源,根据每一批学生的实际情况和教学重点,设计了不同的教学资源。本文以一个多模态虚假新闻检测任务为例,分别从数据集构建、模型设计、算法实现及结果仿真等几个方面进行了详细描述。通过完整的案例建设流程与仿真操作设计,提供了机器学习实践教学案例构建的全过程,为相关教学机构组织机器学习实践教学提供参考思路。
