基于自注意力机制的TransNet推荐模型
2023-07-14马宏爽刘其成牟春晓
马宏爽,刘其成,牟春晓
(烟台大学计算机与控制工程学院,山东 烟台 264005)
互联网的迅速发展满足了用户对信息的需求,但用户在面对海量的信息时,找到真正有用的信息非常困难,由此推荐系统[1]应运而生。推荐系统可以从海量的信息中挑选出有价值的信息,为用户提供个性化服务,从而提升用户获取信息的效率[2]。传统的协同过滤(Collaborative Filtering,CF)和基于内容的推荐算法虽简单有效[3-4],却存在冷启动和评分矩阵稀疏的问题[5],使得推荐性能下降。
随着深度学习的发展,一些研究工作将协同过滤算法和深度学习进行融合,文献[6]提出的WRMF模型,考虑了用户的隐形反馈建模的问题,对每个训练样本都加一个权重,来表征用户对物品偏好的置信度。文献[7]把自编码器应用到协同过滤算法中,提出了AutoRec模型,将用户对所有物品的评分向量输入到自编码器中,预测用户物品矩阵中缺失的评分值。针对用户偏好的Top-N推荐问题,文献[8]提出了一种协同去噪自动编码器CDAE,通过去噪自动编码器形成用户项目反馈数据,学习用户和项目的分布式表示。由于传统的CF无法学习到用户之间、项目之间的相似度,文献[9]将CF与度量学习相结合提出一种CML模型来帮助解决数据间的重要关系。文献[10]提出将自编码器应用于基于隐式反馈的协同过滤推荐任务,通过非线性概率模型克服线性因子模型的局限,提出了VAECF模型。这些研究在协同过滤推荐算法基础上进行了改进,虽然在协同过滤中使用深度学习,但是并没有涉及富含用户偏好和项目信息的评论文本,推荐系统的可解释方面存在不足。
相比改进协同过滤算法,使用评论文本来预测评分可以提升推荐系统的推荐可解释性。评论文本可以解释给出评分高低的原因,而且评论中隐含的用户偏好和项目特征可以为推荐模型建模提供丰富的信息,弥补有效信息不足的缺点[11]。深度学习不断发展使得推荐系统使用神经网络处理评论文本成为了可能,文献[12]提出的DeepCoNN模型利用两个并行的卷积结构分别对用户和商品的评论文档建模,最后使用了因子分解机[13]做评分预测。文献[14]指出DeepCoNN模型只有测试样本中包含目标用户对目标项目的评论时,才能获得最好的表现效果,在此基础上提出了一个TransNet模型,该模型扩展一个Transform层,可以将用户和项目评论的潜在特征转换为目标评论的近似表示。最后使用因子分解机做评分预测,从而构建出新的推荐模型。文献[15]提出的CARL 模型利用卷积运算和注意力机制从评论中学习潜在特征,然后将潜在特征与潜在评分嵌入合并,输入到因子分解机模型中以得出缺失的分数。但是DeepCoNN、 TransNet和CARL等推荐模型使用因子分解机处理交叉特征时,对每个特征的选择权重相同,而无用的特征会引入噪声,影响模型推荐效果。
注意力机制自提出以来,最先应用在计算机视觉领域,一些敏锐的学者意识到在推荐系统中应用注意力机制具有重要意义,随后注意力机制在推荐领域广泛应用。文献[16]在因子分解机的基础上使用注意力机制,提出一种注意力机制因子分解机,通过注意力机制学习交叉特征的权重,改善了因子分解机的性能。为了从项目的词序列中学习隐藏表示,文献[17]应用了区分信息词的词注意模块,提出了TARMF模型,更好地理解商品的内容。文献[18]提出了一个新的深度学习推荐模型GATE,通过优化矩阵分解和基于注意力机制的GRU网络,从评分和评论中联合学习用户和项目的信息,提高了模型的可解释性。为了增强推荐模型的可解释性和推荐的多样性,文献[19]使用注意力机制提取有用的评论,提出一种TAFA模型,该模型学习用户评论和隐式反馈,进一步了解用户偏好,为推荐提供可解释性。因此,通过注意力技术对每个特征的重要性进行区分,捕捉更深层的特征信息,以提高模型的可解释性。然而注意力机制的权重参数是固定的,因此可以考虑使用自注意力机制来改善这一问题。自注意力机制是注意力机制的改进,自注意力机制通过输入特征内部的依赖来决定需要关注的特征,对每个输入特征分配的权重取决于输入特征之间的相互作用,因此减少了对外部信息的依赖,数据或特征的内部相关性表达更加准确。
在这种背景下,本文采用深度学习的方法,使用卷积神经网络提取项目和用户评论的特征,利用融合自注意力网络帮助推荐模型处理特征并预测评分。自注意力网络根据特征内部的关系自动分配权重,可以加强特征之间的联系,捕捉特征内部的相关性,提升模型精确度。自注意力机制技术自动学习不同特征的重要性,通过给予特征不同的权重以区分特征的重要性。考虑到自注意力机制技术的众多优点,本文将自注意力技术与真实推荐模型相结合,提出一种改进的SATransNet(TransNet Recommendation Model via Self-Attention Mechanism)推荐模型。
1 相关知识
本节主要介绍卷积神经网络和TransNet推荐模型,并且将这些概念引入SATransNet推荐模型中。
1.1 卷积神经网络
评论文本包含复杂的用户偏好和项目特征,一般使用卷积神经网络(Convolutional Neural Networks, CNN)对评论进行特征提取,避免人工提取的特征精确度不足的问题,而且CNN各个网络层参数共享可以减少计算量[20]。以下将详细介绍CNN的各个组成部分。
1.1.1 嵌入层 CNN模型的嵌入层将包含用户或者项目评论信息映射为一个n×Dk的矩阵M,其中,n为一条评论中的单词数量,Dk为每个单词的词向量维度。模型的评论文本向量化是通过词嵌入工具实现,通过词嵌入工具将词汇信息映射到语义空间。
1.1.2 卷积层 卷积层的目的是对词嵌入矩阵进行特征提取。卷积核的多次有规律的卷积,能够增强有效特征,减少无用特征[21]。设卷积核的宽度是Dk,高度是h,对输入层得到的矩阵的卷积操作可以用公式(1)表示:
ci=f(w·M[i:i+h-1]+b),
(1)
其中,ci是第i个特征,i=1, 2, …,n-h+1,M[i:i+h-1]表示词嵌入矩阵M的第i行到第i+h-1行所组成的窗口,大小为h×Dk。w是h×Dk维的权重矩阵,b是偏置,f是激活函数,表示为f(x)=max{0,x}。由公式(1)可知矩阵M可卷积得到n-h+1个特征。不同的窗口值,可以提取出不同的特征,这些不同的向量构成CNN卷积层的输出。
1.1.3 池化层 卷积层提取的特征将会传输到池化层,最大池化使卷积核一维滑动过程中,筛选出一个最大的特征,其表示形式定义为

(2)
其中,oj是卷积核滑动产生的第j个最大特征,池化层的最终输出O是来自其m个卷积核的输出的连接,由下式表示:
O=[o1,o2, …,om]。
(3)
最大池化可以保证特征的位置与旋转不变性,同时减少模型参数的数量,降低了模型的拟合性[22]。
1.1.4 全连接层 全连接层主要作用是对卷积层和池化层提取的特征进行非线性组合,减少特征信息的丢失。全连接层由权重矩阵和偏置矩阵组成,它将输入池化层的O最终表示为:
X=f(WO+g),
(4)
其中,W是权重矩阵,W∈m×n,g是偏置矩阵,g∈n。评论文本通过CNN的特征提取,得到评论句子的特征矩阵X。
1.2 TransNet 推荐模型
TransNet推荐模型是一个利用评论信息来改善推荐性能的神经网络推荐模型,该模型将用户和项目的潜在特征转换为目标评论的近似表示并使用因子分解机做评分预测[14]。
现实生活中,推荐的常识是一个用户在购买一个商品之前,把商品推荐给他,而此时他还未对该商品进行评价,故预测时不能利用还未作出的评论作为输入。TransNet 推荐模型就证明了用户对目标项目的评论具有很高的预测价值,这些评论应当只在训练时生效而在测试时不可用。因此,TransNet 模型设计了目标网络和源网络。其中目标网络来单独处理目标评论用户A对项目B写过的评论revAB。源网络包含两部分,一部分处理不包含revAB的用户A的评论,另一部分处理不包含revAB的项目B的评论。源网络包含两个CNN,分别处理不包含revAB用户评论和项目评论,另外有一个额外的Transform层。Transform层是一个L层非线性全连接网络,作用是把用户评论文本和项目文本转换成目标评论的近似表示[14],用于后面的因子分解机评分预测。
2 基于自注意力机制的推荐模型SA-TransNet
本节主要对SATransNet推荐模型实现、推荐模型的网络结构以及模型的训练过程进行详细说明。
2.1 SATransNet模型
在现实世界当中,不同的特征往往起到不同的影响,对于一个固定的特征而言,并不是所有特征选择时都有用,这些无用的特征会引入噪声造成干扰,而自注意力机制可以对于那些影响不高的特征进行降权,对重要性高的特征进行自动升权。因此可以考虑在TransNet推荐模型的基础上,通过自注意力神经网络自动学习特征的重要性。
为了更好表达数据和特征的内部相关性,SATransNet推荐模型在卷积神经网络处理评论文本后,在得到的包含用户偏好和项目信息的特征中引入了自注意力机制。自注意力机制在对t位置特征进行特征选择时,可以同时关注前t-1和后t+1位置的特征[23],进而学习特征内部的依赖关系使预测结果更加准确。
使用自注意力机制处理特征矩阵的运算过程可分为两步:计算输入的特征矩阵的注意力分布;根据注意力分布计算特征矩阵的加权平均。
2.1.1 计算特征矩阵注意力分布 对于N个向量{x1,x2, …,xN},为了体现特征的重要性,需要计算每个输入向量的权重。自注意力机制将CNN提取的特征矩阵X={x1,x2, …,xN}线性映射到三个不同空间,分别得到查询矩阵Q、键矩阵K和值矩阵V:
Q=WqX,K=WkX,V=WvX,
(5)
其中,Wq、Wk、Wv是可训练权重矩阵,表示对特征矩阵X不同的权重选择,因此Q、K、V利用公式(5)线性变换的参数W是不一样的。 相比于注意力机制的权重参数是一个全局可学习的参数,对于模型来说是固定的。 而自注意力机制的权重参数是由输入决定,故对于同一个模型不同的输入有不同的权重参数。


(6)

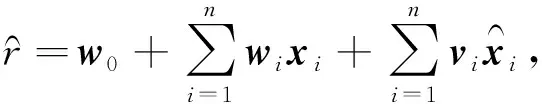
(7)

SATransNet推荐模型在处理特征时,自注意力机制通过将特征矩阵分为键矩阵、查询矩阵和值矩阵,提供了一种捕捉上下文特征的建模方式[25],减少外部信息的依赖,对数据的表达也更为准确。引入自注意力机制推荐模型通过自注意力网络更好学习特征内部相关性,使预测结果更为准确,以此提高推荐准确率。SATransNet推荐模型包含两个网络结构,分别为目标网络和源网络,模型框架如图1所示。

源网络包含两个CNN文本处理层,分别处理不包含revAB的用户A和项目B的评论,经过卷积神经网络的映射,输出词嵌入矩阵MA和MB,经过公式(1)—(4)卷积处理得到源网络的特征矩阵XA,XB。
Z0=[XAXB],
(8)
其中,XA,XB是不包含revAB的用户或项目评论特征矩阵,使用公式(8)将两个特征矩阵XA和XB按照维数横向拼接起来,得到一个新的矩阵Z0。
源网络中还有一个Transform层,作用为将Z0转化成目标网络评论矩阵XT近似。Transform层是一个L层非线性全连接网络,每一层都有一个权重矩阵Gl和偏置gl,权重矩阵初始服从均值为0、标准差为0.1的截断正态分布,所有偏置初始化为0.1。Z0作为Transform第一层的输入,第l-1层到l层的传递公式为
Zl=max(0,Zl-1Gl+gl),
(9)
其中,Zl为Transform层的第l层输出,Gl∈n×n,gl∈n。在训练中,使源网络输出的Zl逼近目标网络卷积输出XT。对源网络中Zl使用自注意力机制线性映射处理,得到源网络的查询矩阵QS、键矩阵KS和值矩阵VS, 根据公式(6)计算注意力分布,得到源网络的注意力分布矩阵对源网络注意力分布使用公式(7)得到预测评分
SATransNet推荐模型使用评论文本反映用户偏好和项目的特征信息,并利用自注意力机制学习了评论特征内部相关性,从而提升了推荐质量。SATransNet推荐模型可以帮助用户来寻找与用户所写内容最相似的评论,最相似的评论又反过来帮助用户做出明智的决定。在现实的推荐场景中,想知道用户A对一个未知项目P的喜好程度,在使用SATransNet推荐模型进行推荐时,首先使用来自用户A和项目P评论文本来构建Zl,Zl是用户项目实际联合评论的近似表示。然后使用目标网络分别来处理其他用户为项目P编写的所有评论,以获得XT。如果目标网络处理的用户评论中,有一个用户所写的评论与用户A和项目P构建的潜在表示最相似,那么这个用户写的评论就可以帮助用户A是否推荐项目P。
2.2 SATransNet模型的训练
模型的训练可以采用不同种类的损失函数,如最小绝对值偏差(L1范数)、最小平方误差(L2范数)、逻辑损失等。在SATransNet模型训练过程中,目标网络和源网络训练的损失函数使用L1范数,模型损失函数定义为

(10)

SATransNet模型的训练分为2个步骤:

(11)

losstrans=∑‖Zl-XT‖2
(12)

(13)
算法1:SATransNet推荐模型训练
输入:用户项目评论文本TextA、TextB,用户A对项目B的评论revAB,用户A对项目B的评分rAB。

源网络的训练1 XA←conv(TextA-revAB) XB←conv(TextB-revAB)2 Z0←[XAXB]3 Transform-input(Z0)4 For lay l∈L do Zl←max(0,Zl-1Gl+gl) Return Zl5 losstrans←‖Zl-XT‖26 更新最小的losstrans,输出Zl7 QS←WqZl,KS←WkZl,VS←WvZl8 X︵S←Softmax(KTSQSDk)9 r︵S←w0+∑ni=1wixi+∑ni=1viSx︵iS10 lossS←∑|rAB-r︵S|11 更新最小的lossS目标网络的训练1 XT←conv(revAB)2 QT←WqXT,KT←WkXT,VT←WvXT3 X︵T←Softmax(KTT QTDk)4 r︵T←w0+∑ni=1wixi+∑ni=1viTx︵iT5 lossT←∑|rAB-r︵T|6 更新最小的lossT
3 实 验
3.1 数据采集
本文选用Amazon数据集(http://jmcauley.ucsd.edu/data/amazon/)进行推荐模型的实验评估。该数据集主要收集的是Amazon网站1996年5月至2014年7月的数据信息,包含用户和项目的评论和评分,总共有1.428亿条评论,1到5的整数评分范围。
本文在Amazon数据集中选择CDs and Vinyl、Video Games、Grocery and Gourmet Food数据集作为实验数据。首先对数据进行稠密度的预处理,使用Skip-gram[26]模型保留用户和项目评论数据中的50 000个最高词频的词,并把预训练出来的词输入到64维词嵌入向量中,从而将词汇信息映射到语义空间。其次对评论文本进行分词,对停用词(the、and、is等)和无用的标点符号进行保留,然后再对这些词进行词形的还原等处理。在深度学习领域,合理划分训练集、验证集和测试集是很重要的,实验过程中参照文献[14]、[19]将实验数据按80%、10%、10%的比例划分成训练集、验证集和测试集。数据集的统计信息和划分信息如表1、2所示。

表1 数据集统计信息

表2 数据集划分信息
3.2 评价指标
由于Amazon数据集都是用户对于物品的显式评分数据,在评分预测类的推荐系统中,常用的评测指标有均方误差(Mean Square Error, MSE),本文使用均方误差作为评测推荐系统的指标,计算方法如下:

(14)

为了衡量模型的推荐结果相关程度,本文还采用归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)作为评价指标,NDCG取值范围为[0,1],NDCG越大代表推荐相关程度越高。计算方法如下:

(15)
其中,reli表示处于位置i的推荐结果的相关性分数,IDCG表示推荐系统为某一用户返回的最好推荐结果列表,p表示要考察推荐列表的长度。
3.3 实验设置
在实验环节,对输入的所有评论文本使用自然语言处理工具包[27]对评论进行处理,然后对其进行降级。评论中的停止词以及标点符号被视为单独的标记,并被保留。模型的评论文本向量化是通过词嵌入工具[28]实现的,通过词嵌入工具将词汇信息映射到语义空间,最终获得一个词向量模型。对于模型的训练优化器使用自适应估计Adam(Adaptive moment Estimation) 进行优化[29]。
实验表明不同的超参数取值对推荐模型的训练造成不同的影响,进而影响推荐效果。表3对本文所使用到的超参数进行了说明。
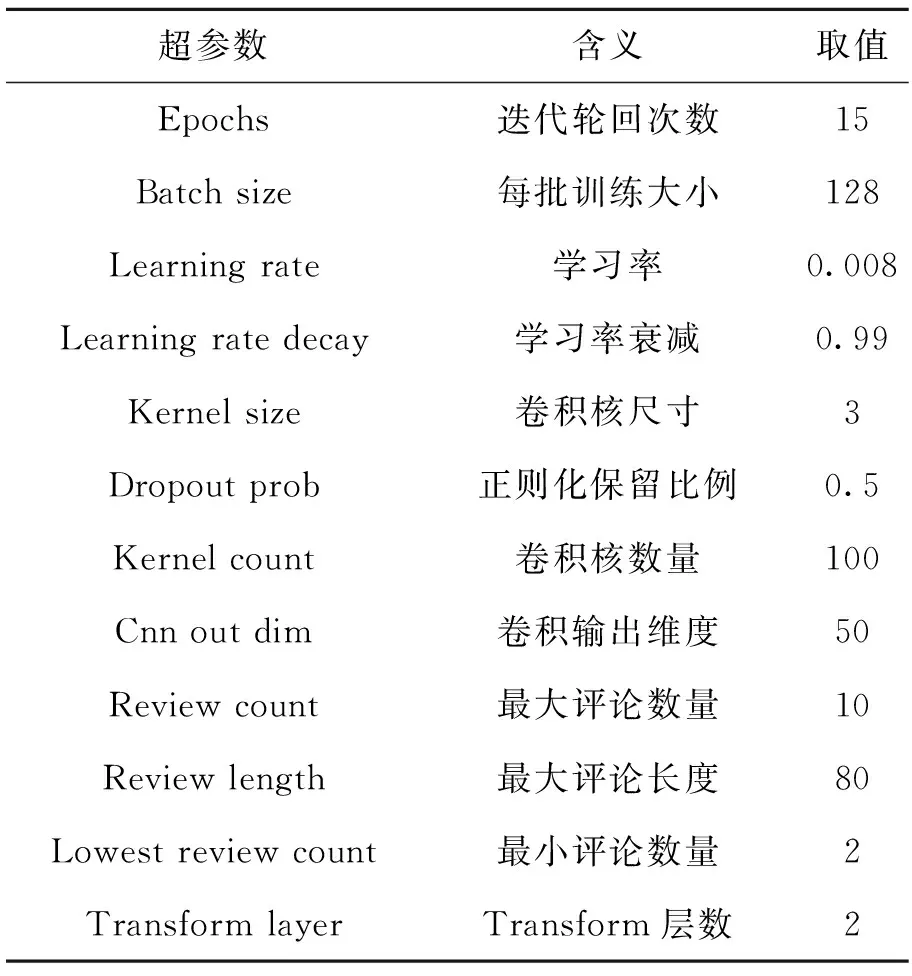
表3 超参数取值
学习率为模型训练重要的超参数,学习率可以控制模型学习的速度,控制分配错误的数量[30]。在每批训练实例结束时,模型的权重都会更新。通常,较大的学习率允许模型更快地学习,代价是会达到次优的最终权重集。较小的学习速率可以允许模型学习更优化或甚至全局最佳的权重集,但是可能花费更长的时间来训练[31]。因此,在训练数据集上为模型找到合适的学习率非常重要。我们在Amazon的Home and Kitchen数据集上测试了不同学习率对SATransNet模型训练的均方误差的影响,发现学习率在0.014时模型具有更好的性能,但为了缩短模型训练的时间,同时控制错误分配的数量,在SATransNet模型和其对照模型训练时学习率设置都为0.008。
3.4 结果与分析
本文通过与真实的推荐模型进行实验对比来验证融入自注意力机制的推荐模型的有效性,实验选取亚马逊的三个类别的数据集,分别对比了SATransNet、TransNet[14]和TAFA[19]模型的预测评分均方误差,如表4所示。同时,为了衡量推荐模型的与真实场景的推荐相关程度,在三个数据集上比较了SATransNet、TransNet[14]和TAFA[19]模型的归一化折损累计增益,在参数相同的情况下进行了多次实验,实验结果如表5所示。

表4 推荐模型的MSE效果
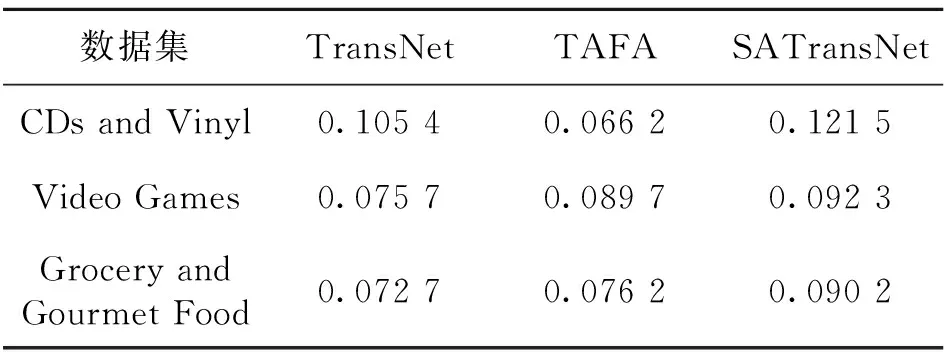
表5 推荐模型的NDCG效果
由实验结果可知,SATransNet推荐模型在不同的数据集上均方误差效果和归一化折损累计增益效果总体呈优。因此,由自注意力网络去获得更多的特征相关性,SATransNet推荐模型可以有较好的预测评分效果和获得更多的推荐相关性。
4 结 论
本文在真实的推荐模型的基础上,提出了一种适于内容表达的SATransNet推荐模型。该模型引入自注意力机制,通过自注意力网络学习输入特征之间的相互作用,并为其分配权重。实验结果表明,在真实数据集上,SATransNet模型能够取得较好的推荐相关性和预测评分结果,推荐准确率具有明显优势,验证了融合自注意力机制因子分解的推荐模型有效性。
另外,由于实验用到的评论文本数据蕴含信息较大,模型在训练时耗费时间较长,效率较低,因此可以探索如何将SATransNet的训练模式适配并行的系统,以便并行地利用GPU集群去处理大量数据。
