基于HAO 治理模型的钢铁企业数据治理平台应用研究
2023-07-13郑银巧
□郑银巧 王 璇 王 蕾
一、引言
数据作为新型生产要素,是钢铁企业数智化深入发展的新引擎。2020年4月《中共中央国务院关于构建更加完善的要素市场化配置体制机制的意见》正式发布,提出了土地、劳动力、资本、技术、数据5个要素领域改革的方向,明确了完善要素市场化配置的具体举措[1]。数据作为一种新型生产要素被写入正式文件,充分突出了数据的资源价值,也为钢铁企业的数智化转型提供了方向。
近年来,钢铁企业逐步认识到数据资产的重要性,如何发挥企业数据价值,成为钢铁企业智改数转的重要目标。数据治理是充分发挥钢铁企业数据价值的必由之路,是助力钢铁企业转型升级的有力保障。钢铁企业可利用体系化方法实现企业数据的可得、可信、可用、好用,解决企业数智化转型的诸多数据问题。在数据治理的基础上,钢铁企业沉睡的数据得以被唤醒,数据价值得以充分释放。
二、钢铁企业数据治理面临挑战
第一,数据多源异构使数据集成共享存在壁垒。由于钢铁企业的信息化大多是随着技术发展、业务需要逐步实施完善的,所以企业内部通常拥有多种业务系统和数据库,并且由于使用场景和创建时期不同,计算环境和系统平台各有差异,现有的数据库和系统组成了一个庞大、异构的信息源,数据传输和共享受到制约。
第二,数据质量难以满足企业需要。钢铁企业内部多系统并存,服务各自的主管部门。同样的数据在不同的信息系统中重复录入,甚至不同信息系统中同一数据的值却不一致等情况均有发生。此外,因缺乏问责机制,各系统之间甚至同系统内的数据标准不统一,“一物多码”问题十分严重,对企业上下游之间的数据协同、业务协同造成了较大影响。
第三,钢铁企业数据文化建设薄弱。目前,钢铁企业数据战略目标不明确,缺乏对企业级数据综合治理体系的指导。数据作为一种新的生产要素,在企业中应作为一种战略资产进行管理。数据从业务中产生,要对数据进行有效治理,需要业务充分参与,但是由于业务部门认识不足,或信息化部门协同能力不足,导致数据治理脱离了业务。此外,企业数据治理缺少体系支撑,导致管理责任不清、原则和依据不明、流程和操作不规范,同时,人才、组织、预算保障未能到位,数据治理相关工作难以开展。
综上,树立正确的企业数据建设工作思路有助于成功实现企业数据治理。钢铁企业作为非数字原生企业,数字化转型的关键要素之一是在现实世界的基础上构建一个跨越孤立系统承载业务的数字世界。通过在数字世界汇聚、联接与分析数据,并对其进行描述、诊断和预测,最终指导业务改进。在实现策略上,企业需要构建以云为基础、以数据为驱动的新型信息架构。一是要充分利用钢铁企业现有各类型信息系统产生的数据资产,二是构建一条从企业各业务过程感知、采集、汇总数据的通道,不断完善企业生产经营过程的数字化和规范化,实现企业数据可视、可控、可用和可信。
三、HAO治理模型架构
近年来,随着对数据治理研究的深入,出现了多种治理模型。2019年,吴信东等人在《数据治理技术》一文中提出了大数据 HAO治理模型[2],模型架构见图1。

图1 HAO治理模型架构
HAO治理模型以人类智能(Human Intelligence)、人工智能(Artificial Intelligence)和组织智能(Organizational Intelligence)三者协同为目标,主要目的:一是建立一种全面、动态、可配置的数据接入机制,实现数据采集、汇聚、任务配置、调度、数据加密和断点续传等功能;二是实现数据处理流程的规范化和标准化,对数据进行规范化处理、清洗、关联、比对等,以便组织的数据融合和建库;三是建立多元融合的数据组织模式,按照业务类型、数据敏感度等内容对不同数据分级分类建库、管理,并通过数据标签等方式将数据关联融合;四是按照组织的业务内容构建知识图谱,对数据进行全方位、多维度管理,数据使用者可依托知识图谱进行简单的查询检索和对比排序等,专业人员可进行数据挖掘、建模等数据处理;五是通过知识图谱,实现人类智能、人工智能和组织智能协同交互,利用治理过的融合数据,通过数据模型、云计算、雾计算等处理机制,实现数据深层次应用。
四、钢铁企业数据治理架构
在HAO治理模型的基础上,结合钢铁企业的业务特点,围绕企业数据来源、数据处理、数据存储和数据服务4个层次,设计钢铁企业数据治理架构,如图2所示。
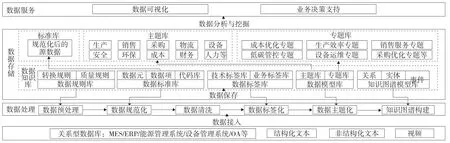
图2 钢铁企业数据治理架构
1.数据来源
钢铁企业数据来源包括各类现存信息系统,如过程控制系统(PCS)、基础自动化系统(PLC/DCS)、生产制造执行系统(MES)、企业资源计划(ERP)、设备管理系统、能源管理系统等;还包括各类结构化文本、非结构化文本、视频等。其中,对有数据库的可开发接口直接进行数据抓取;对于非结构化文本、视频等,可利用深度学习技术,如语音识别、图像识别、视频处理等进行数据提取。
2.数据处理
(1)数据预处理
数据采集后,要达到可使用,首先要按照钢铁企业业务特点制定数据规则,并根据规则对数据进行预处理。数据规则要提前定义好并存放在数据规则库中。数据预处理主要分2步:第一步,对当次采集的数据进行质量评估,包括数据空值率计算、数据可信度分析、数据完整性分析等,判断数据是否有深层次处理应用价值,若判断此次采集数据质量太低,或因个别底层业务系统数据处理未能满足要求,设置重新采集机制;第二步,根据元数据库、基础数据库信息,对各业务系统采集数据进行统一编码转换,过滤掉脏、乱、差数据,保留需要治理的数据内容。
(2)数据规范化
数据规范化是对数据进行标准统一的过程,钢铁企业数据标准来源为国标、省部级标准及行业标准等,应提前建立好数据标准知识库,对数据的名称、字段、单位等设定标准化要求。经数据预处理后,按标准库的相关要求,对数据进行统一处理,提高数据的共享性和复用性。
(3)数据清洗
数据清洗是将前面处理过的数据进行筛选,将重复、多余的数据清除,将缺失的数据补充完整,对错误的数据进行纠正,最后整理成为可以进一步加工、使用的数据。
(4)数据标签化
数据标签主要分技术标签和业务标签。技术标签主要是基于数据表和字段设计的技术元数据,记录数据的技术内容,包括数据条目数、更新时间、更新频次、数据格式、数据类型、访问频率、空间占用等。业务标签是基于表、字段的业务定义,描述其具体代表的内容,包括数据来源、数据种类(如客户、供应商等)和数据内容(如客户名称、客户编码、客户联系人姓名、客户联系人电话、客户银行账号等)。
(5)数据主题化
按照钢铁企业业务特色和数据特点,将数据按照业务类型进行主题划分,包括生产、销售、采购、成本、财务、设备、物流、安全、环保、人力等。各主题覆盖全业务范围的最细颗粒度数据,便于满足后期各种统计形式需要。
(6)知识图谱构建
知识图谱的构建主要依赖于知识图谱模型库,模型包含3个要素,即关系、实体和事件[3],通过这3个要素将钢铁企业各类型数据进行抽象化的内在联系,以可视化的形式有效表现出来,便于实现关系的检索、推理、计算和分析。钢铁企业的实体指钢铁行业涵盖的各种对象,包括人、财、物料、库房、厂区、装备、部门等。图3是一个简单的废钢关系图谱,以废钢为中心,建立废钢与公司部门、废钢与供应商、废钢与仓库存储、废钢与转炉投料、废钢与轧钢厂的关系等。
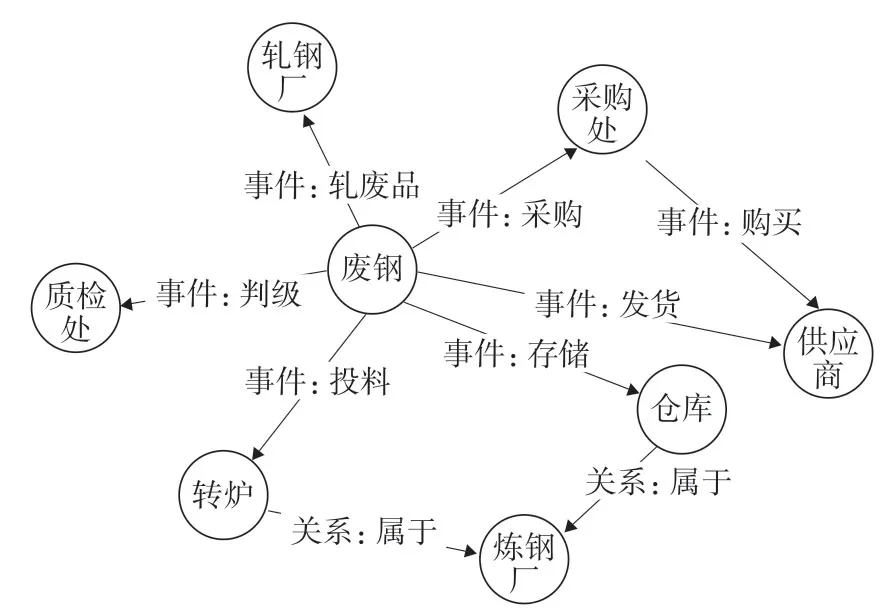
图3 废钢关系知识图谱
3.数据存储
数据存储的内容主要有4种:一是数据知识库,主要是数据处理的规则、标准、数据标签、主题分类、专题分类、知识图谱模型等,作为数据处理的依据;二是标准库,包括元数据、主数据等,实现数出同源,统一标准;三是主题库,主要是各个业务主题的各类型最细颗粒度数据;四是专题库,是为了解决某些特定业务,对主题库数据进行统计、挖掘、分析后形成的数据。
考虑到钢铁企业数据量大、数据更新频次快,数据存储需要一定的扩展能力,建议将数据布置到分布式的大数据平台上,以便应对企业越来越多的数据积累和越来越严苛的算力要求。
4.数据服务
对处理后的主题库数据,设计算法模型,对数据进行统计分析、关联分析、对比碰撞、深度挖掘等,深度总结业务经验、分析业务现状、预测未来趋势,为钢铁企业各专业部门提供定制化的数据服务。
五、钢铁企业数据治理实施建议
一是提高数据治理战略高度,从思想上深刻认识数据治理对企业数据价值释放的重要性。数据治理基本涵盖了钢铁企业的全域数据,单纯从业务层面或某个部门出发,是做不好数据治理工作的,只有企业高层高度重视,将数据治理提升到战略高度,才会统筹全局资源力量,实现数据治理,将数据变为资产。
二是建立完善的工作制度,为数据治理过程提供保障。钢铁企业底层数据来源繁杂,数据周期、粒度也不尽相同,必须建立一套完善的数据治理工作制度,统一数据标准,实施责任制管理,才能驱动钢铁企业数据的有效治理。
三是要明确数据治理是一个长期、系统的工程。数据治理需要长期循序渐进地总结、复盘、优化,其终极目标绝不仅是单纯业务数据的治理,而是通过数据治理驱动业务优化,只有通过持续和动态的全生命周期数据治理过程,数据才能持续释放价值。○
