一种基于STI-YOLO的锌花背景干扰下带钢表面缺陷检测方法
2023-07-13魏明军陈钊纪占林周太宇闫旭文刘铭
魏明军,陈钊,纪占林,周太宇,闫旭文,刘铭
(华北理工大学 a.人工智能学院;b.河北省工业智能感知重点实验室,河北 唐山 063210)
钢材表面缺陷检测经历了人工检测、传统光电检测和机器视觉检测3个主要发展阶段[1-2].从20世纪60年代以来,机器视觉技术的出现使得工业上的缺陷检测有了质的提升.与国外相比,国内对于缺陷识别的研究起步较晚.1991年华中理工大学的罗志勇[3]将线列CCD用于检测钢板的孔洞缺陷.1996年,又再次研究出由许多面阵CCD和DSP、PC机相结合组成的一套新的图像检测系统[4],实现了对冷轧带钢表面缺陷进行检测.2011年,杨永敏等[5]研究了基于机器视觉的冷轧带钢表面缺陷检测系统.2022年,布申申等[6]提出一种用于带钢表面缺陷检测的深度神经网络模型Ds-DenseNet,该模型主要解决现有带钢表面缺陷检测方法准确率低、特征泛化性不强、参数多、识别速度慢等问题.但其缺点是只针对以前无花的普通带钢进行检测,对于具有锌花纹理的新型镀层钢板无专门的训练检测.在检测过程中锌花会对产品表面缺陷的检测造成干扰,从而使检测的精度受一定影响.目前,国内未见公开发表的针对锌花背景干扰下带钢表面缺陷检测的研究成果,本文针对某钢厂镀锌生产线采集的真实缺陷图谱展开研究,通过STI-YOLO模型抑制锌花背景的干扰,同时增大预测特征图的感受野,从而提高检测精度,改善漏检.
YOLOv5算法与之前的YOLO系列算法[7-9]相比较,仍由主干特征提取网络、特征融合网络和回归预测三部分组成,主干特征提取网络使用的是CSP-Darknet53[10]网络,不同的是加入了Focus网络结构,使输入的通道数快速扩张4倍,并且将空间金字塔池化结构(Spatial Pyramid Pooling,SPP)加入到主干特征提取网络中,增大感受野的尺寸.在特征融合网络结构部分,依然采用了路径聚合网络(Path Aggregation Network,PANet),达到了提取上下文特征的目的.PANet网络结构通过自下而上的路径缩短了底层和最顶层之间的信息路径,避免信息丢失问题,同时融合后的特征图既包含底层位置信息也包含较强的语义特征.YOLOv5总共包含s、m、l、x 4个算法模型,YOLOv5s网络最小,速度最快,平均精度也最低.其他的3种网络,在s基础上,不断加深加宽网络,平均精度也不断提升,但速度的消耗也在不断增加.本文以YOLOv5s算法为基础,在特征图输入到特征融合网络PANet之前先引入通道注意力机制(Squeeze-and-Excitation Network,SENet)[11],抑制锌花背景的干扰,提高有效特征的利用率,滤除冗余的锌花背景信息.再将进行特征融合之后的3个不同尺度的特征图输入到金字塔卷积(Pyramidal Convolution,PyConv)[12]网络中,提取更加丰富的缺陷信息,使得用于预测的特征图具有更好的鲁棒性.
1 STI-YOLO算法
1.1 STI-YOLO模型网络结构
STI-YOLO模型的输入是分辨率为640×640的图片,其网络结构如图1所示.
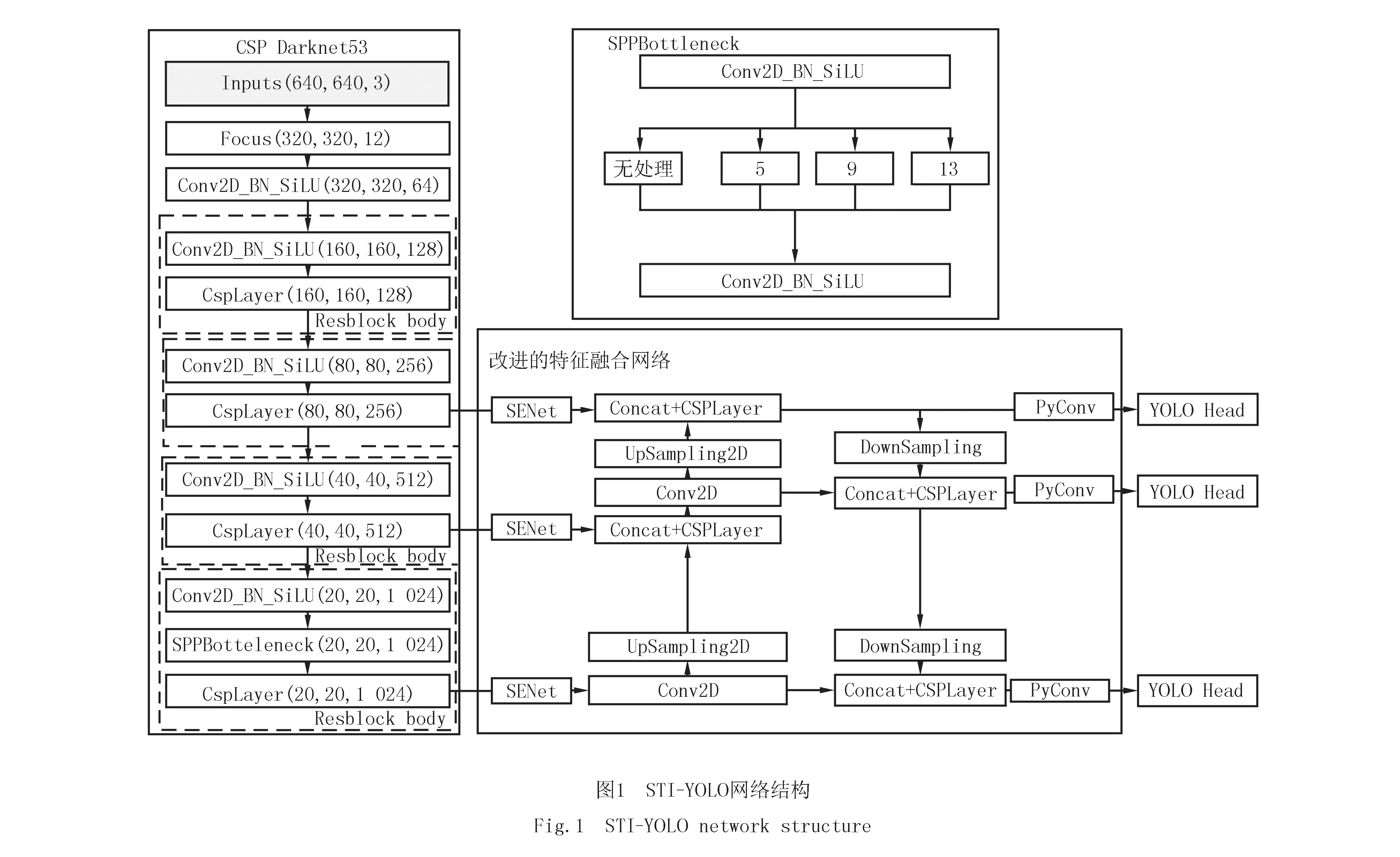
算法执行的具体步骤如下:
1)输入尺寸大小为640×640、通道数为3的图片.经过Focus网络结构,将输入通道扩充了4倍;
2)经过DarknetCon2D_BN_SiLU模块通道扩充为64;
3)经过4个Resblock body模块,提取到低层、中层和高层特征图,其尺度大小分别为80×80、40×40和20×20;
4)将主干特征网络提取到大小20×20、40×40和80×80的特征图分别输入到SENet网络中抑制锌花背景的干扰;
5)利用PANet进行特征融合,获得3个不同尺度的特征图.然后将上采样和下采样产生的新特征图利用横向连接进行Concat连接;
6)对生成的新特征图输入到金字塔卷积网络中,进行多尺度特征处理,产生更丰富的特征信息,增加预测特征图的鲁棒性;
7)生成的特征图输入到YOLO Head中进行预测;
8)生成预测框.
1.2 改进的特征融合网络
在深度卷积神经网络中,高层特征图包含更多有利于目标分类的强语义信息,但分辨率低,位置信息粗糙.低层特征图包含更多有利于目标定位的位置信息和轮廓细节,但其分辨率高,语义信息弱.YOLOv5s算法使用PANet进行加强特征融合,在主干网络提取的特征图里包含了部分锌花背景干扰造成的冗余特征.为了解决这一问题,抑制锌花背景对缺陷检测的干扰,引入SENet.如图2所示,具体操作是将主干特征网络提取的特征图输入到SENet中突出重要特征,减少锌花背景的干扰.从而有利于PANet得到更有效的特征,提高缺陷识别的准确率.并在预测之前加入金字塔卷积,从而使得增加感受野的同时获取更丰富的上下文特征.
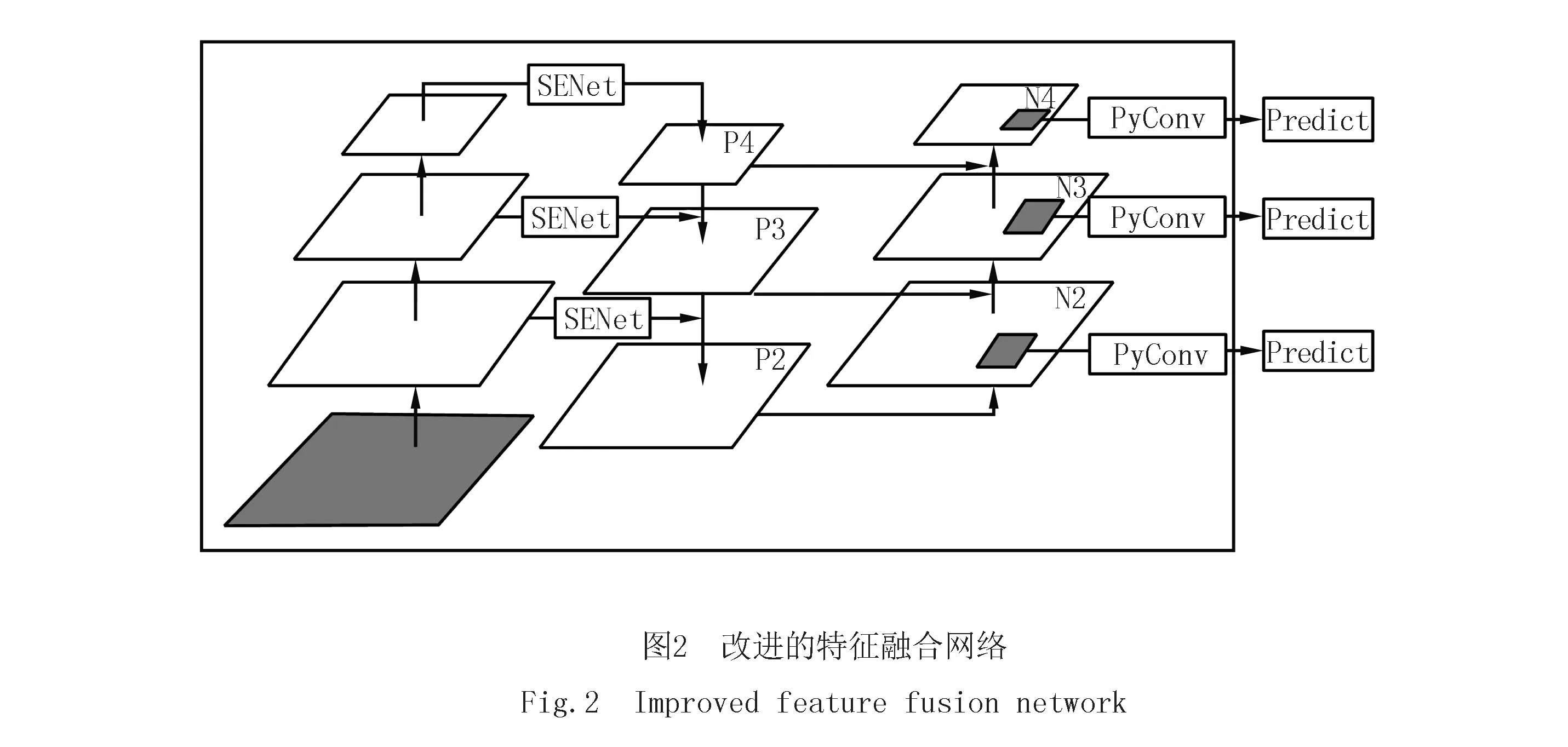
1.2.1SENet模块
SENet通过对通道关系进行建模从而提升网络性能,主要包括Squeeze(压缩)和Excitation(激发)两个关键操作.模型通过学习自动获取每个通道的重要程度,然后根据每个通道的重要程度提升有用特征的权重并抑制对当前任务有干扰的冗余特征.
如图3所示:输入通道数为c1的特征x,通过一系列卷积操作(Ftr)将特征通道数变为c2.然后再进行压缩(Fsq)操作和激发(Fex)操作.
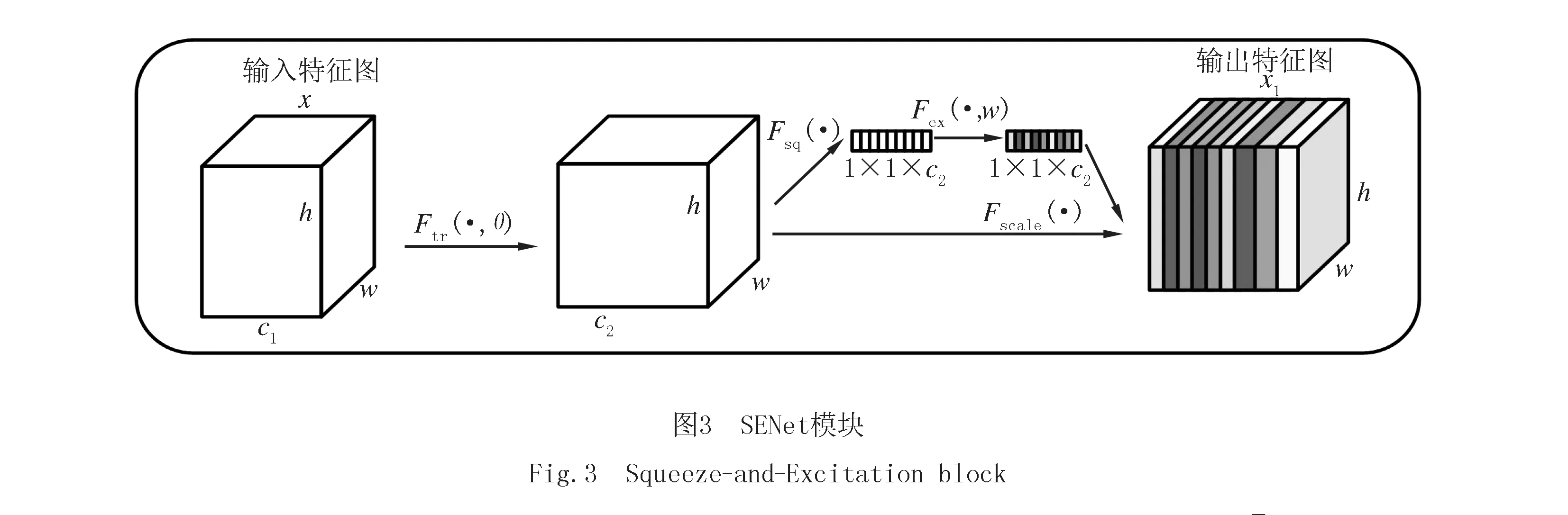
SENet通过网络学习特征权重,获取到每个特征图的重要程度,然后按照重要程度对每个特征通道赋予一个权重值,对任务重要的特征图赋予较大的权重,对不重要的特征图赋予较小的权重,从而使模型达到更好的训练效果.SENet的结构如图4所示.图4中表示输入一个大小为H×W×C的特征图,共C个通道数.然后进行一次空间的全局平均池化,每个通道得到一个标量,输出为1×1×C,然后再送入两层的全连接神经网络,同时保持特征图大小不变,然后再通过一个Sigmoid函数得到C个0~1之间格式为1×1×C的权重,作为C个通道各自的权重,然后将对应通道的每个元素与权重分别相乘.其中H代表特征图的高,W代表特征图的宽,r表示降维系数.
1.2.2PyConv模块
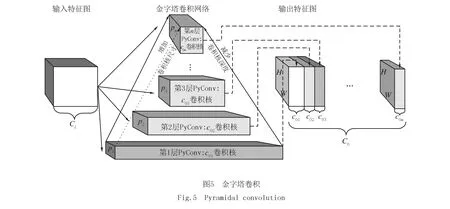
PyConv中包含不同大小和深度的卷积核,以此捕捉不同尺度的细节信息.原PANet网络中的下采样操作会造成输入特征图的信息损失,影响模型性能.而使用PyConv模块可以在不增加额外计算量的同时扩大感受野,通过采用不同尺寸的卷积核捕获多尺度的细节信息.
如图5所示,金字塔卷积网络包含一个具有n个不同大小卷积核的金字塔网络结构.在不增加计算成本或模型复杂性的情况下,以不同的卷积核大小处理输入.每个卷积核都包含不同的空间大小,从金字塔的底部到顶部卷积核大小逐渐增加,随着卷积核大小从1到n逐渐增加,卷积核的深度从n到1逐渐降低,形成互为反向链接的金字塔结构.
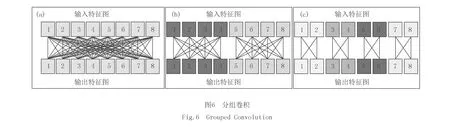
通过分组卷积,对每个级别使用不同深度的卷积核.如图6所示,输入8个特征图,(a)为标准卷积,(b)和(c)分别表示group为2和4的分组卷积,(b)和(a)相比核的深度减少2.当卷积组的数量增加到4时,卷积核的深度减少,参数量和计算成本减少.
在进入到YOLO Head进行分类预测之前,根据不同的特征图尺寸对输入的特征图进行分组卷积以扩大感受野.PyConv网络结构如图7所示.
以通道数Ci=256的特征图为例,首先经过1×1的卷积将输入特征通道数由256减少到64,经过PyConv模块分组卷积,4个卷积核的大小分别为:9×9、7×7、5×5、3×3.此外,卷积核的深度在每个级别上都有所不同,从G=16(分组为16)到G=1(标准卷积的分组).每个卷积核输出的通道数为16,最后输出的特征图通道数为64.然后用1×1卷积恢复输入的通道数256.每个1×1卷积前后都有标准化函数BN和ReLU激活函数.右侧为快捷连接,可以有效回传梯度.
1.3 先验框的优化
YOLOv5s算法一共生成3个特征图,每个特征图对应3种不同类型的先验框,所以YOLOv5s算法一共生成9个先验框.YOLOv5s算法的9个默认先验框由K-means算法对MS COCO[13](Microsoft Common Objects in Context)数据集的目标框聚类得到.根据本文缺陷数据集用K-means算法重新聚类得到新的先验框尺寸,使得先验框与真实框更加匹配,以减少默认先验框对检测精度的影响.大、中、小目标分别对应20×20、40×40、80×80的特征图.默认先验框和调整后先验框与预测特征图大小的对应关系如表1所示.

表1 预测特征图与先验框的对应关系
2 实验设计
2.1 平台搭建
硬件环境:CPU:Intel(R)Core(TM)i5-11400F;显卡:NVIDIA GeForce RTX 3050;内存:16 GB RAM.
软件环境:操作系统:Windows10;编程语言:Python;运行框架:PyTorch.
2.2 数据集构建与模型训练
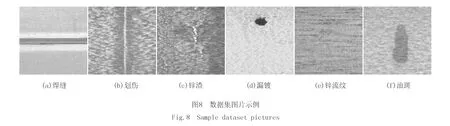
本文使用自制带钢表面缺陷数据集,其中图片来源于某钢厂镀锌生产线采集的真实缺陷图谱.本文自制数据集包含常见的6种缺陷图片3 190张,训练集图片与测试集图片数量的比例为9∶1,标签分为焊缝(We)、划伤(Sc)、锌渣(Zn)、漏镀(Sk)、锌流纹(Fo)、油斑(Sp)6类,其中主要缺陷图片如图8所示.对数据集用Labelimg对目标缺陷进行标注.训练参数为迭代300个epoch,学习率设置为0.01,前150次进行冻结主干网络训练,batch_size设置为16,后150次解冻训练将batch_size设置为8.
2.3 评价指标
本文以平均精度均值(PMA)和平均精度(PA)来评价算法的缺陷检测识别效果,PMA和PA的值越大表明检测效果越好.采用单位时间内检测的图片数量(SFP)作为模型检测速度的评价标准,单位时间内检测的图片数量越多,模型的检测速度越快.计算公式如下:

(1)
(2)
(3)
式(1~3)中:p为查准率,r为召回率,p(r)表示某个r对应的p的值;PA为平均精度值,k表示缺陷的种类数;Fc表示检测的图片数量,Tt表示检测所消耗的总时间.
2.4 优化实验
确定使用的模型后对SENet的降维系数以及SENet的位置进行实验,调整先验框尺寸,以使得改进后的网络效果更优,前两个实验结果均基于默认先验框得出.
2.4.1SENet模块降维系数实验
通过对数据集训练显示平均精度均值并不是随着SENet的降维系数r的增长而增长,当降维系数r=16时,平均精度均值最高为94.73%,因此设定降维系数r的值为16.
2.4.2SENet模块位置实验
将SENet分别添加在两次上采样之后、一次上采样之后和一次下采样之后、PANet网络之前,经过实验对比显示将SENet添加在PANet网络之前平均精度均值为94.73%,优于其他位置.虽检测速度略有下降,但本文更多考虑精度需求,因此将SENet添加到PANet网络之前.
2.4.3先验框的优化实验
通过实验对比,YOLOv5s模型根据本文数据集重新聚类调整先验框之后比调整之前PMA提高了0.53个百分点.STI-YOLO模型调整先验框之后比调整之前PAM提高了0.36个百分点,重新聚类后取得的先验框尺寸对提高模型的检测精度有效.
2.5 消融实验
为了验证改进点对于网络模型的作用,通过消融实验进行对比,只添加PyConv模块和只添加SENet模块相较于原模型分别提升了0.50个百分点和0.59个百分点,使用所有改进之后提升了1.54个百分点.
3 实验结果与分析
使用本文数据集训练SSD300(输入图片尺寸大小为300×300)、YOLOv3、YOLOv4、YOLOv5s以及STI-YOLO模型(本文模型),并进行效果对比.
如图9所示,5种算法模型均能检测出焊缝(We)缺陷,SSD300模型的置信度为1.00,YOLOv3模型置信度为0.97,YOLOv4置信度为0.97,YOLOv5置信度为0.90,STI-YOLO置信度为0.92.所有模型检测焊缝缺陷的置信度均在0.90以上,但YOLOv4和YOLOv5s在检测过程中出现锌流纹(Fo)的错检情况,STI-YOLO模型未发生错检.

图10所示为划伤(Sc)缺陷的检测结果,YOLOv3和YOLOv5s分别出现划伤缺陷的1处漏检,YOLOv4出现油斑(Sp)1处错检.相比其他模型,STI-YOLO模型对缺陷检测的边界框更加准确,精准识别出2处划伤缺陷和2处锌渣(Zn)缺陷.

图11所示为锌渣(Zn)缺陷的检测情况,SSD300、YOLOv3、YOLOv4、YOLOv5s均有漏检的情况,STI-YOLO模型对锌渣缺陷没有发生漏检.
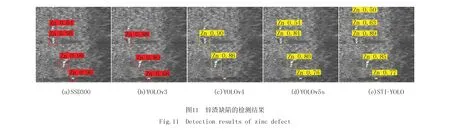
图12所示为漏镀(Sk)缺陷的检测结果,SSD300、YOLOv3、YOLOv4、YOLOv5s均出现漏检,YOLOv3、YOLOv4和YOLOv5s仅检测出较大漏镀缺陷,对于较小的漏镀缺陷无法识别,STI-YOLO模型基本将带钢表面的漏镀缺陷检出.
图13所示为油斑(Sp)缺陷的检测结果,除了YOLOv5s模型的置信度相对较低为0.83,其余4种模型在检测油斑缺陷的置信度上均在0.9以上.
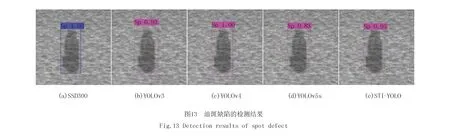
图14所示为锌流纹(Fo)缺陷的检测结果,5种模型均能检测出锌流纹缺陷,SSD300、YOLOv3、YOLOv4检测结果的置信度均在0.95以上,YOLOv5s检测的置信度较低为0.76,STI-YOLO模型检测的置信度为0.85.
综合分析可知:STI-YOLO模型在有锌花背景干扰下对于缺陷的检测效果更好,对于被锌花背景干扰严重的锌渣和划伤缺陷的检测效果有较大的提升,与其他主流算法相比整体的检测效果更符合检测要求,对于容易出现漏检的锌渣、漏镀缺陷以及出现容易被错检的锌流纹缺陷均能识别.
不同模型对于缺陷检测的性能如表2所示.从表2可知:SSD300和YOLOv5s的检测速度分别为58.69、60.88 frame/s,检测速度较快,STI-YOLO模型虽然检测速度低于SSD300和YOLOv5s,但速度优于YOLOv3和YOLOv4,为54.14 frame/s,仍能满足缺陷检测的要求.STI-YOLO模型较YOLOv5s的平均精度均值PMA提高了2.07个百分点.虽然STI-YOLO模型在锌流纹(Fo)缺陷上的平均精度稍逊色于SSD300,但差距仅为0.04个百分点.但STI-YOLO模型对于较难检测的划伤缺陷和受锌花背景干扰严重的锌渣缺陷表现比较优秀,通过对比,对于划伤(Sc)缺陷,STI-YOLO模型的平均精度较SSD300、YOLOv3、YOLOv4以及YOLOv5s分别提高了7.37个百分点、22.12个百分点、12.75个百分点和4.03个百分点.对于受锌花背景干扰严重的锌渣(Zn)缺陷,STI-YOLO模型有大幅度提高,STI-YOLO模型较SSD300、YOLOv3、YOLOv4以及YOLOv5s分别提高了16.62个百分点、33.56个百分点、36.12个百分点和4.52个百分点.油斑(Sp)和焊缝(We)的检出率为100%.同时漏镀缺陷的检出率为98.26%,较好解决了漏检问题.
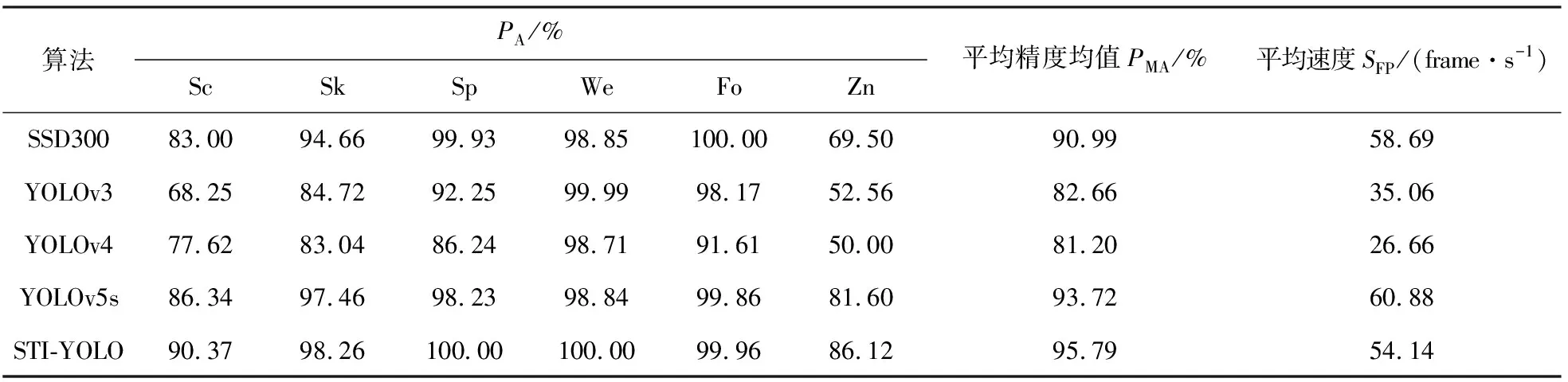
表2 模型性能对比

这是因为STI-YOLO模型在主干特征网络提取到有效特征图之后,在特征图输入到特征融合网络之前添加了SENet通道注意力机制,在不损失重要位置信息和语义信息的前提下提高有效特征信息的利用率,同时抑制由于锌花背景干扰产生的冗余信息,在进入PANet之前更高效地利用有效信息,滤除冗余信息,提高了网络的检测精度.同时在进行特征融合之后的3个不同尺度的特征图输入到金字塔卷积网络中,提取更加丰富的缺陷信息,使得预测的特征图具有更好的鲁棒性.
4 结 论
针对原始YOLOv5s算法在有锌花背景干扰下对划伤缺陷和锌渣小目标检测效果欠佳的问题,根据本文缺陷数据集进行重新聚类调整先验框的尺寸,在特征融合网络PANet之前引入通道注意力机制SENet,增强特征图有效信息的提取,突出重要特征,抑制锌花复杂背景对缺陷检测的干扰,从而减少冗余特征的影响,同时增加金字塔卷积网络丰富预测特征图的感受野,提取更有效的语义信息.STI-YOLO模型有效提高了YOLOv5s算法在有锌花背景干扰下的缺陷检测精度,同时进一步改善了原模型存在漏检以及错检的问题.
