基于Doc2Vec和LDA模型融合文献质量的学术论文推荐研究
2023-07-13王大阜邓志文贾志勇王静
王大阜,邓志文,贾志勇,王静
(中国矿业大学 图书馆,江苏 徐州 221116)
图书馆是文化、资源的聚集地与传播中心,为了满足读者泛在化科研、学习的需求,更好地推进高校“双一流”建设,促进学科建设发展,电子资源已经成为图书馆主要引进的文献结构类型.科研大数据时代,面对海量的学术资源,学者难以就其感兴趣的学科领域,进行相关文献的择优选取,从而对学者造成“信息过载”的困扰[1].学者通常借助OPAC系统、中外文数据库搜索引擎,从中检索、选取相关的论文文献.根据美国科学基金会统计,学术人员在开展学术活动的过程中,花费在资料收集上的时间占全部科研时间的 51%,科研效率低下[2].因此,用户更倾向于智慧化的个性化服务,希望系统自动、高效地向读者推荐、呈现感兴趣的优质资源.以满足读者的需求为导向,图书馆亟需利用大数据、推荐算法、机器学习等技术,从用户阅读行为信息、学术成果等信息中,挖掘读者阅读兴趣偏好,为其提供与研究兴趣较匹配、文献质量优越的资源推荐服务,帮助读者从耗时耗力的检索、挑选论文的事务中解脱出来,同时精准的推荐效果亦能够激发读者的学术活跃度和科研创作潜能.
近年来,学界围绕纸本资源、电子资源的个性化推荐开展了大量研究,采用的技术方法主要分为3种:(1)基于协同过滤推荐:刘岩[3]基于传统的协同过滤(Collaborative Filtering,CF)算法实现纸本文献的推荐.协同过滤算法依赖读者对物品的评分数据,大多数读者在使用OPAC系统检索、借阅文献时不关注评分事项,导致用户-项目评分矩阵数据稀疏,推荐精度不理想,为此,有学者研究利用借阅次数、借阅时长计算用户-项目的隐性评分[4].(2)基于内容推荐:论文、专利等学术资源属于典型的文本数据,学者们主要使用信息检索的理论和技术,围绕“语义相关性”展开,结合自然语言处理(NLP)技术对文本进行特征提取和挖掘分析,同时能够缓解物品冷启动问题[1].张戈一等[5]采用TF-IDF算法分别对地质文献进行特征提取、相似度计算及推荐.阮光册[6]构造读者借阅行为共现矩阵,利用Word2Vec的潜在语义分析特性提供多样性的推荐结果.耿立校等[7]针对向量空间模型存在的文本向量维度灾难问题,采用TF-IDF算法提取关键词,再结合Word2Vec模型实现文献推荐.熊回香等[8]从关键词语义类型和文献老化两个维度出发,为用户推荐符合其研究方向且时间价值高的学术论文.陈长华等[9]结合Word2Vec与时间因素进行论文推荐.杜永萍等[10]使用LDA模型对候选文献和用户发表的文献进行建模,根据两者相似度值进行推荐.张卫卫等[11]融合LDA和Doc2Vec模型,利用语料库的全局语义信息和上下文语义信息,分别进行学术摘要聚类、挖掘学者研究兴趣标签,对本文的研究提供了一定的参考借鉴.WANG等[12]基于TF-IDF算法得出学术论文的关键词分布为用户推荐学术论文.KANAKIA 等[13]将Word2Vec模型和共被引方法相结合对微软学术论文进行推荐.(3)基于社交网络推荐:该方法是基于学术社交网络进行社区划分,并对社区内用户进行学术论文推荐[14-15].此外,有学者根据用户基本信息、阅读习惯、阅读行为及情景数据进行用户画像,将用户标签化,并向其提供个性化推荐服务[2,16].随着深度学习技术迅猛发展,CNN、RNN模型应用于论文推荐系统,实现深层次地挖掘文本隐式特征[17-18].
综上所述,学术论文推荐方法主要是采用TF-IDF、Word2Vec、LDA不同模型对论文摘要语料库进行训练,学习得到论文的文本特征向量,再将目标论文与候选论文集进行相似度计算,选择相似度较高的候选论文集作为推荐结果.以上3种模型的推荐结果的精度和效果不理想,原因是存在以下局限性:(1)特征提取信息不完善,TF-IDF仅考虑词权重,存在“词汇鸿沟”现象,认为词语间是相互独立的;Word2Vec获取到上下文语义信息,但缺失词序、全局主题信息; LDA从全局语境挖掘隐性的主题信息,但忽略了局部上下文语义关系.(2)缺乏文献质量因素的度量,仅从文本内容角度作相似度对比,导致向读者推荐过时的、学术质量相对较低的论文.本文研究内容旨在设计学术论文推荐模型,向用户推荐内容相似度高的学术论文,并在此基础之上,引入文献质量权重对相似度进行加权修正,从而使用户获取到高质量的学术论文.
1 相关模型
1.1 词向量模型
文本向量化是从文本中提取特征,将文本表示成可量化、可运算的数字形式.词嵌入(Word Embedding)技术诞生之前,文本向量化通常采用词袋模型(Bags of Words,BoW)中的独热编码(One-Hot)、词频(Term Frequency,TF)、词频-逆文档频率(TF-IDF)3种表示方法.One-Hot方法根据词在字典中的索引位置将文本转化为0或1二值向量,该方法会造成严重的维度灾难和数据稀疏问题.TF和TF-IDF是基于向量空间(VSM)模型,将一篇文本投射成高维空间中的一个点,该点的坐标对应文本的多个特征词向量.词袋模型的缺点在于:假定词与词间相互独立,不考虑词间的语义关系,而且对于大规模语料库而言,仍然存在维度灾难问题.
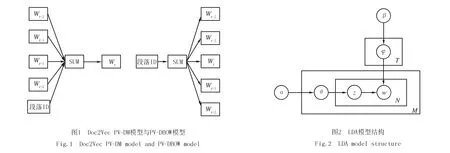
2013年Google公司Tomas Mikolov团队发布了Word2Vec词嵌入模型,Word2Vec认为相似语境的词语语义相近,通过三层神经网络模型训练,将多维词向量映射成稠密的低维向量,从而实现了词的分布式表示[9].2014年Tomas Mikolov提出改进模型Doc2Vec,也称为段落向量(Paragraph Vector),增加了词序语义的分析,用于创建文档向量,文档可以是句子、段落或文章.Doc2Vec模型分为分布式内存模型(PV-DM)和分布式词袋模型(PV-DBOW)两种,架构如图1所示,PV-DM模型是在输入层增加了段落ID作为样本用于预测目标词概率,段落ID类似一个特殊的上下文单词,存储着段落信息,段落向量被该文档所有上下文窗口共享[11].PV-DBOW模型将段落ID作为输入,从文档中预测随机采样的词概率.Doc2Vec模型能够同时训练学习到词向量和文档向量,适用于论文文本向量化高效处理的需求,而且它考虑了词序信息,对词预测也更为准确、灵活.
1.2 LDA主题模型
潜在狄利克雷分布(LDA)主题模型是通过语义分析技术,对上下文理解后,挖掘出隐含的抽象主题[11].LDA模型的基本思想是:一篇文档隐含了多个主题,一个主题由多个词语构成,通过迭代模拟文档生成过程,识别文档和文档集中潜在的主题信息.鉴于此,LDA模型由文档、主题、词组成的三层贝叶斯概率分布生成,α和β是两个Dirichlet先验超参数,θ表示文档到主题之间的多项分布,ψ表示主题和词之间的多项分布.α、β与其他变量之间的服从分布关系为:θ~Dirichlet(α),z~Multinomial(θ),ψ~Dirichlet(β),w~Multinomial(ψ).
对于语料库中每篇文档d生成的过程如图2所示:(1)为文档d选择一个由T个主题混合的概率分布θ,从超参数α吉布斯采样生成;(2)对于文档d每个单词从Multinomial分布中取样生成主题z;(3)从超参数β吉布斯采样生成ψ,以ψ为参数的Multinomial分布中采样生成词w;(4)上述3个步骤重复N次,产生文档d.
LDA模型的作者Blei采用困惑度(Perplexity)评估LDA主题模型好坏,确定最优主题数.困惑度小,说明模型具有更好的泛化能力[19].困惑度(Pe)的计算公式如下:
(1)
式中,M表示文档的数量,wd表示文档d中的单词,Nd表示文档d中的单词数量,P(wd)表示文档中词wd产生的概率.
2 文献质量评估
文献质量的衡量取决于文献老化率、期刊影响因子及作者权威度3个因素,综合3个因素对文献质量进行定量评估.
2.1 文献老化
随着科学技术的不断演进发展,文献随之发生新陈代谢、老化淘汰.对于读者而言,较新的论文能够捕捉某学科的研究热点及其理论技术发展前沿,论文质量、研究价值相对较高.文献老化是科学计量学与文献计量学的重要课题,衡量文献老化速度和程度的主要度量指标有半衰期和普赖斯指数[20].半衰期是指在利用的全部文献中较新的一半是在多长时间内发表的.普赖斯指数(Pr)是指在某一个知识领域内,年限不超过5 a的被引文献数量与引文文献总量的比例,计算公式为:
由于非水库管理单位已经取得水库管理范围内部分地块所有权证书,所以在水库防洪与兴利调度时,为了防止对非权属土地造成淹没、冲蚀等破坏而引发经济赔偿纠纷,水库管理单位不得不额外考虑水库蓄泄水对非权属土地的影响。因而制约了水库的防洪作用,降低了水库的兴利效益,对水库的防汛与供水安全形成了较大的挑战。
(2)
文献老化经典数学模型利用引文共时数据分析法,反映文献引用频率与时间(以10 a为单位)之间的函数关系,揭示某些特定学科领域文献的老化规律.参考文献[21],定义Age(简记为Ag)表示文献老化率,用于进一步区分每篇论文的老化程度,计算公式为:
(3)
式中,T为半衰期,根据文献[21],图书情报类文献的半衰期T值为6 a.t为文献自发表之日起至推荐时间所间隔的时长,计算方式为以d为单位再换算为以a为单位.
2.2 期刊影响因子
论文的质量与期刊影响因子密切相关,期刊影响因子(Impact Factor,IF)是指期刊中论文的平均应用率,等于期刊近两年被引用量与发文量之比,IF直观反映期刊整体的论文质量,利用IF表示同一期刊中每篇候选论文的通用质量.根据CNKI期刊数据统计,2021年图书情报类期刊的IF值区间范围为[0.811,7.343],为抑制IF值过大对整体文献质量的影响,利用离差标准化(Min-Max)方法对特征做归一化处理,IF(简记为I)计算公式为:
(4)
2.3 文献影响力
在同一研究领域,某篇文献被引次数较高,表明该论文更受学者们的青睐和认可,其学术影响力较高,其中可能包括历久不衰的经典文献.定义I′表示文献影响力,取100作为被引次数的阈值,超过100可以当作高影响力文献,计算公式为:
(5)
定义Qa表示候选论文的文献质量权重,该指标综合期刊影响因子、文献老化率以及文献被引次数(I′)3个因素,并取其平均值作为Qa指标值,计算公式为:
(6)
3 推荐模型框架
推荐模型架构如图3所示,本文以CNKI期刊论文的摘要文本作为语料库,融合两种Doc2Vec、LDA模型进行建模,用于训练语料库,利用优势互补来挖掘文本局部上下文语义、词序信息以及隐藏的全局主题信息,扩充了所提取的论文文本的特征丰度和细粒度,为后续的NLP任务处理提升识别及预测能力.大量的文本相似度计算会增加计算复杂度,造成算法运行缓慢,为此通过聚类进行了优化处理,将候选论文集进行聚类,划分出多个类群,然后在类群范围内寻找文献质量加权相似度较高的候选论文集.
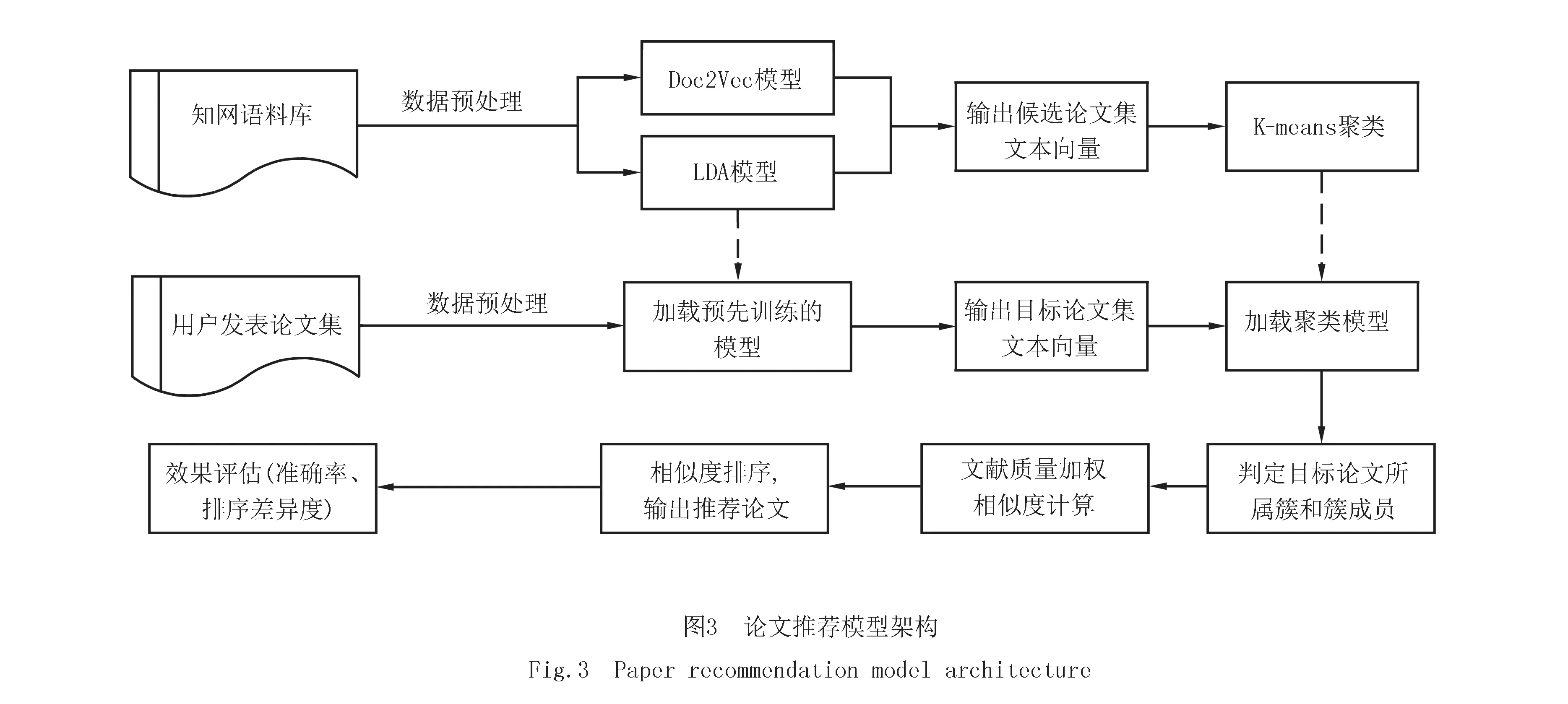
假定语料库是由一系列文档(论文摘要文本)组成的集合D={d1,d2,…,dn},文档d的词集合W={w1,w2,…,wn},LDA模型训练文档D后得到多个隐含主题集合T={t1,t2,…,tn}.推荐模型的推荐结果处理流程如下.
步骤1 对语料库进行分词、去除停用词等数据预处理,利用Doc2Vec模型训练语料库,得到所有词向量和文本向量,假定某篇论文文档d的向量,记作v(d),v(d)=[wd1wd2wd3…wdm],wdi表示文档d的第i个特征值.
步骤2 利用LDA模型训练语料库,得到每篇论文文档的主题概率分布,即文档的主题向量,记作v(d)t,v(d)t=[td1td2td3…tdm],tdi表示文档d在主题ti上的概率分布.
v(d)′=[wd1wd2wd3…wdmtd1td2td3…tdm].
步骤4 采用K-Means经典聚类算法对所有文档进行聚类并保存模型,两篇文档的距离采用余弦相似度进行度量,相似度越高则距离越接近.通过多次迭代计算簇中心,直至簇中心收敛,不再改变位置,最终确定多个聚类簇.余弦相似度计算公式如下:
(7)
步骤5 将用户发表的论文集作为目标论文集,经过分词、去除停用词等数据预处理后,通过步骤1、2训练保存的模型得到文档向量.接着通过步骤4保存聚类模型,计算出每篇目标论文距离最近的簇中心,进而判定目标论文所属簇及簇内的类群成员(即待推荐论文集).
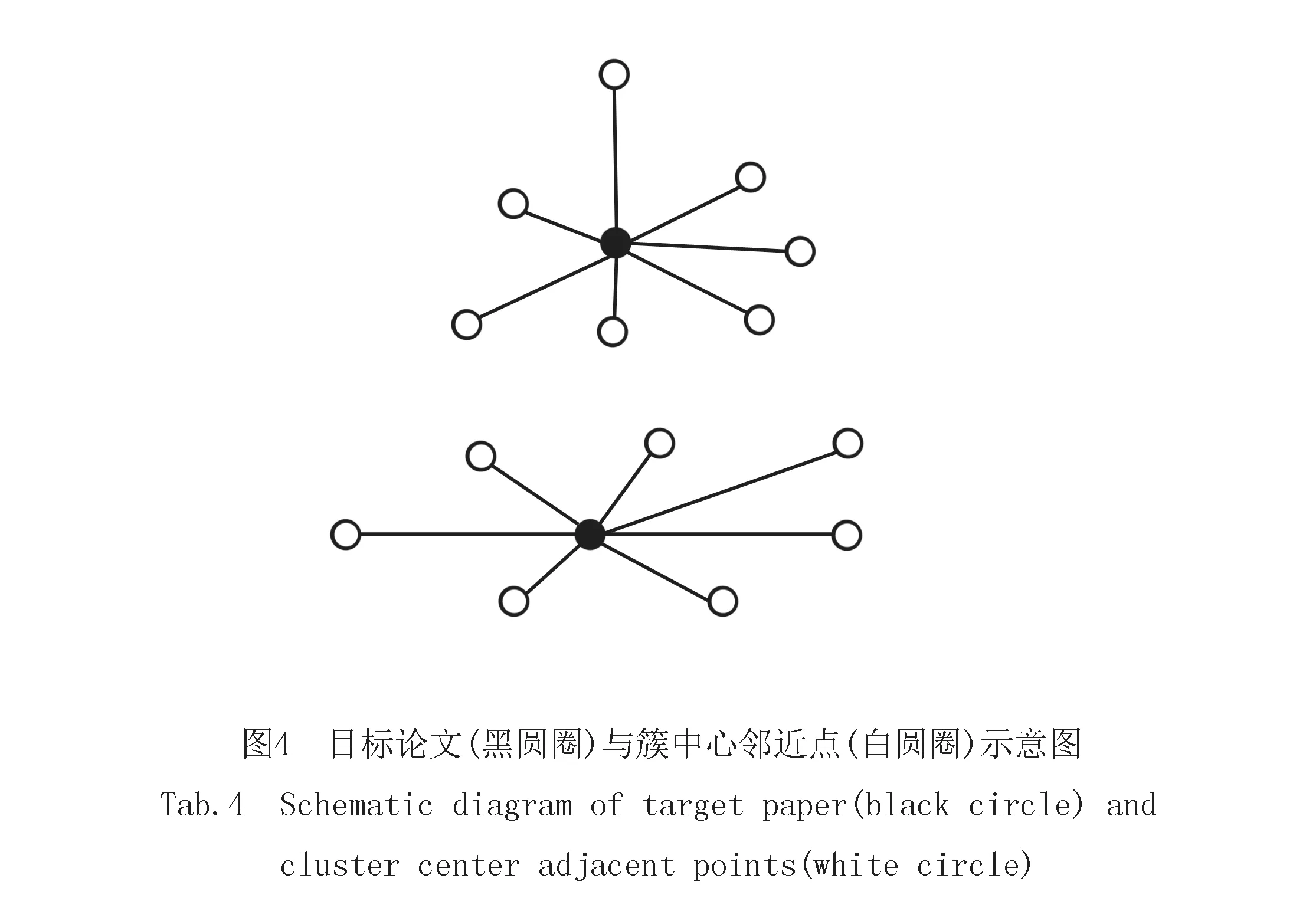
步骤6 修正余弦相似度公式(式8),为其赋予文献质量权重,接着对相似度进行排序,排序后的TOP-N篇候选论文作为输出推荐结果.聚类示意图如图4所示,文献质量(Qa)加权相似度计算公式如下:
sim′(d,d′)=Qa×sim(d,d′).
(8)
4 实证分析
4.1 数据准备及预处理
通过编写Python程序,从CNKI爬取图书情报类期刊论文作为候选论文集,同时将论文摘要作为语料库.期刊论文的检索条件为文献分类:图书情报与数字图书馆,时间范围为2014-2021年(8年),来源类别为北大中文核心期刊和CSSCI来源期刊,清除选题指南、名人专访等无效文献,最终采集总计42 072篇论文.目标论文集选取中国矿业大学10位馆员近5年发表的论文.数据预处理环节采用结巴分词工具进行分词,停用词采用哈工大停用词词典追加部分自定义停用词,比如论文中经常出现的“目的”、“意义”、“过程”等无关词.图书情报学领域具有很多专业术语,为了使得分词更加精准,通过BICOMB工具提取文献关键词,进而构建包含1 724个词的自定义词典.
4.2 混合语义模型训练
采用Python版本的Gensim软件包训练Doc2Vec、LDA模型,Doc2Vec模型的参数设置为:window(窗口大小)设为5,min_count(最小词频阈值)设为5,Dm(模型类别)设为1,即PV-DM模型,Size(段落向量维度)设为100,epochs(迭代次数)设为200.LDA模型的参数设置为:超参数α设为0.05,超参数β设为0.01,iterations(迭代次数)设为200,dictionary(字典)过滤词频小于5的词.
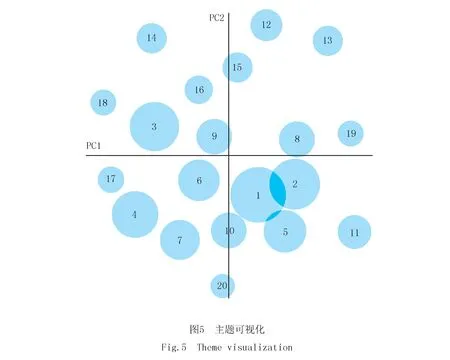
前文提到,LDA模型采用困惑度指标评估最优主题数,本文通过绘制困惑度与主题数间的曲线,结果表明:当主题数为20时,困惑度出现拐点,下降趋势逐渐平缓,另外从PyLDAvis库生成的主题可视化结果(图5)来看,各个圆圈代表一个主题,各个主题之间重合性不高,因此最佳主题数取值为20.根据20个主题对应的高频次出现的词语分布,提取主题所代表的含义标识,其中前8个热门主题分别为:“图书馆服务模式创新”“图书馆建设发展”“用户行为分析”“知识组织与知识服务”“文献资源建设与保护”“科技文献发展”“阅读推广”“高校学科服务”等.图5中圆圈的大小代表每个主题相关的文献数量,圆圈较大的主题即为热门主题.由图5可见,图书情报类论文研究的主题分布整体较为分散,少数主题关系紧密,如主题1与主题2和主题5有部分重合,三者均与图书馆建设发展关联密切.
4.3 推荐实例
时间是一种重要的上下文信息,用户的研究兴趣会随着时间上下文的推移而发生迁移,本文假定读者的研究兴趣5年内不会衰减,以中国矿业大学图书馆某馆员为例,表1是该馆员近5年的发表论文汇总(共5篇),采用K-Means算法对语料库聚类,每篇论文所在簇的成员数侧面反映出该研究主题的发文量及研究热度.

表1 某馆员近5年发表论文列表
以该馆员序号1的发表论文《学科分析中科研合作网络分析方法研究》为例,模型的部分推荐论文如表2所示,序号1~6是按照初始的余弦相似度进行排序.可见,推荐论文的主题与发表论文研究主题均与科研合作网络相关,契合度十分高.在引入文献老化率、期刊影响因子及文献影响力3个因素后,对相似度进行加权修正计算后,重新排序的次序为序号2、序号5、序号6、序号3、序号4、序号1.序号1论文初始排名第1,但是因为其老化率较低,使其最终的推荐结果产生改变,排名转为第6.序号6论文因为老化率和被引次数较高,最终排名转为第3.由此可见,加权后的论文推荐结果不仅保证了内容的相关性,而且在论文质量上得到了很好的保证.
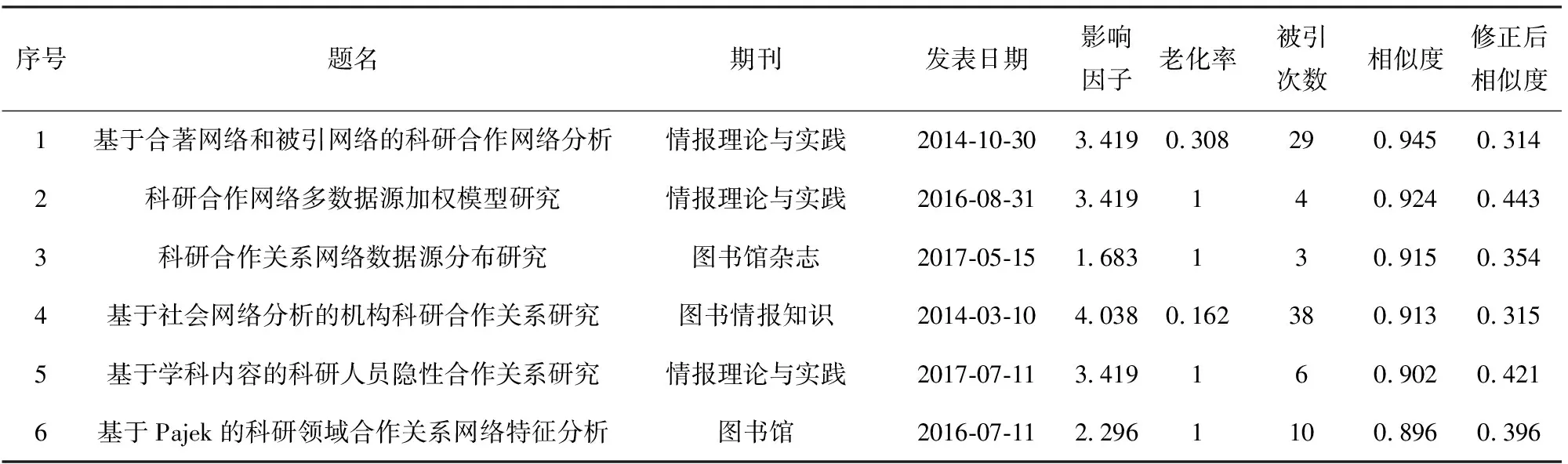
表2 某馆员部分推荐论文列表
4.4 推荐效果评估
本文采用精确率评估本文推荐模型的推荐精确度,方法是采用本文模型与TF-IDF、Word2Vec、LDA 3种模型,分别向10位馆员推荐相似度较高的TOP-N论文,N分别取值10、15、20、25、30,并对推荐论文进行满意度(满意或不满意)评价,精确率(Precision,P)的计算公式如下.
(9)
式中,PT为用户满意的推荐论文数,PN为用户不满意的推荐论文数.
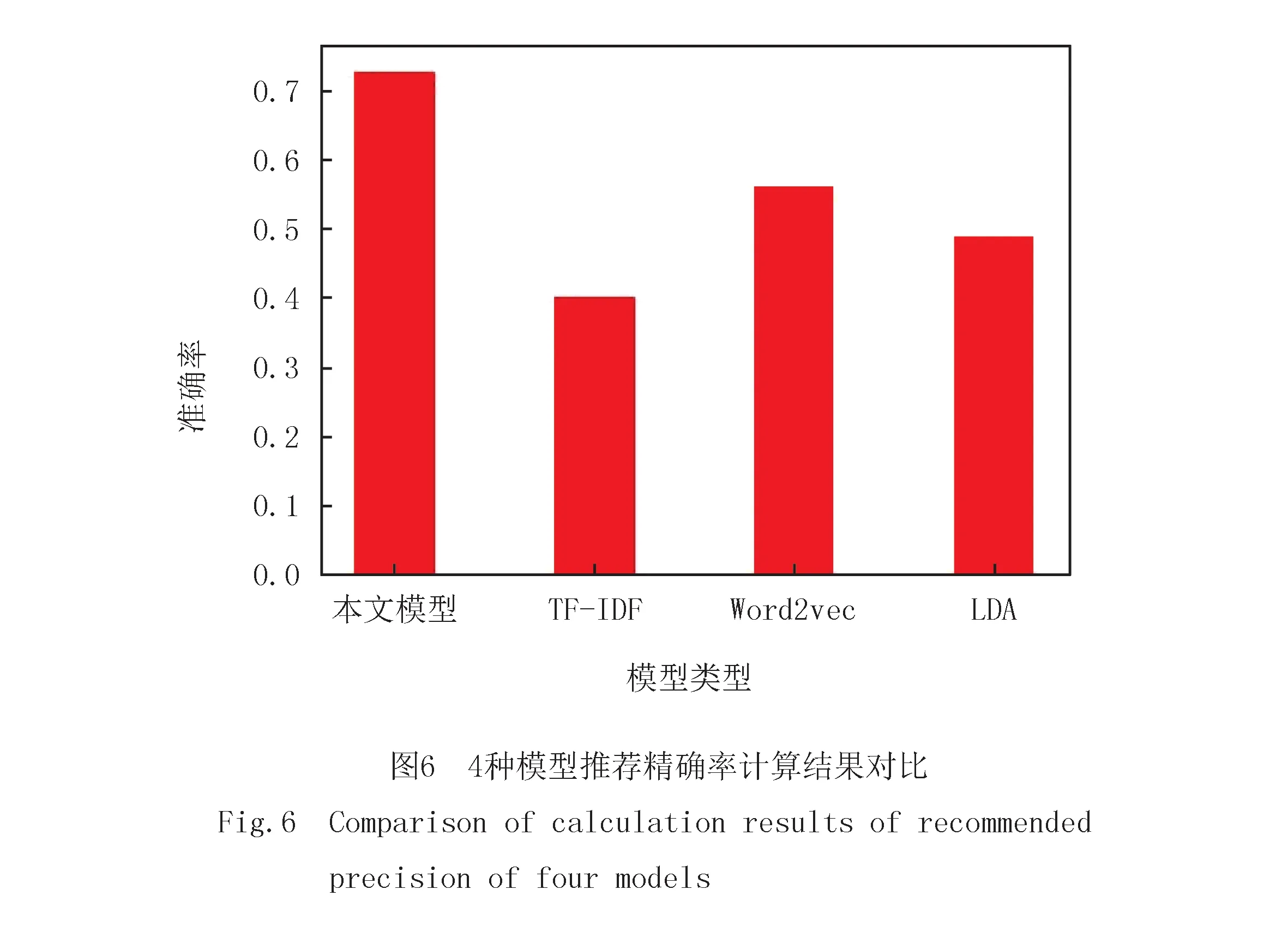
实验结果表明:随着N的增加,精确率逐渐提高,当N=20时,论文推荐的精确率最高(P@20=0.729),随后又发生明显降低.4种模型推荐精确率如图6所示,由图6可见,本文模型与其他模型对比,精确率最高,其次为Word2Vec、LDA及TF-IDF.分析其原因是:TF-IDF模型仅考虑论文的关键词权重,而且文本向量数据稀疏,导致精确率最低.Word2Vec模型考虑上下文语境信息,并且文本向量低维稠密,因此精确率高于TF-IDF,但是文本向量是简单地通过词向量取均值表示,会丢失部分上下文信息.LDA模型是基于论文的词分布提取论文的主题信息,缺乏上下文语义信息,与Word2Vec模型相比,精确率较低.本文模型综合论文的上下文语义、全局语义以及词序信息,更能准确表达论文的内容主旨,因此精确率最高.
为了验证本文文献质量加权计算方法的有效性,即推荐论文的排序效果,需计算推荐论文的输出排序与用户真实排序的差异,该差异值越小,则越符合用户期望的排序结果.定义p为排序差异值,计算公式为:
(10)
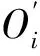
5 结束语
本文采用单机对设计的推荐模型进行实证,语料库使用的图书情报类期刊论文文本,并取得良好的实验效果.同时,本文研究存在一定的局限性,下一步考虑从以下3个方面进行优化改进:
1)处理性能提升方面,在实际场景中,语料库会涵盖各个学科的期刊论文文本,超大规模的语料库在提升模型精度的同时,会造成训练收敛缓慢,并且数以万计的论文相似度计算存在性能瓶颈.采用Spark分布式计算框架作为推荐系统的计算平台,区别于Hadoop的MapReduce框架,Spark将数据集缓存在内存中,避免计算过程中频繁的磁盘I/O操作,从而有效提升推荐系统的处理性能[22].
2)目标论文集数据来源方面,图书馆的机构知识库存储展示学者的学术科研成果,用户发表论文的标题、摘要、作者等元数据可以通过机构知识库定期采集获取,随着用户发表论文量的增多,推荐结果同步发生改变,保证了推荐系统的实时性.
3)论文和图书的资源整合方面,用户发表的论文及图书借阅信息都揭示了用户的阅读兴趣,可以将两者有机结合起来,更精准地提取用户兴趣特征,向用户推荐优质论文.反之亦然,可以为平常更关注论文的学术用户推荐优质书籍,扩充可供学习参考的文献范围.
