复合可靠性分析下的不平衡数据证据分类
2023-07-10田鸿朋张思源肖宗荣董佳兵
田鸿朋, 张 震, 张思源, 肖宗荣, 董佳兵
(郑州大学 电气与信息工程学院,河南 郑州 450001)
不平衡数据是指数据集不同类间的数据分布不均衡,其中某一类或多类的样本数量远远超过其他类[1]。例如,在网络安全中,异常行为通常只占一小部分,而大多数行为都是正常的。一般来说,相较于大类中的样本,小类中的样本可能携带罕见但更有用的信息[2]。然而,一些基础分类模型,如支持向量机(SVM)分类器[3],致力于最大限度提高整体分类精度,大多数小类样本被分配到大类,因此对不平衡数据分类的性能较差[4]。
近年来,不平衡数据分类问题备受关注,研究成果丰硕,大致可以分为3类:采样方法[5]、代价敏感学习方法[6]和集成学习方法[7]。采样方法侧重于对不平衡数据进行预处理,使类间数据达到均衡,然后就可以用基础分类模型分类。代价敏感的学习方法是对小类样本分配较高权重,这样可以减小对其分类的错误率。集成学习方法结合了不同子集训练的多个分类模型,相互间提供了互补性信息,解决了单一分类模型对不平衡数据分类性能较差的问题。
虽然以上的不平衡数据分类方法在一些场景中具有一定的有效性,但是这些方法只考虑全局最优,并不一定适合每个测试数据。例如,位于不同类别重叠区域的数据就难以准确划分,这些数据分布的特殊性导致其类别存在一定的不确定性[8],因此容易被错误分类。
针对上述问题,提出了一种复合可靠性分析下的不平衡数据证据分类方法。首先,为了评估分类模型的整体性能,本文设计了一种全局可靠性评估策略,在对大类多次降采样的基础上,分别训练多个分类模型,通过计算采样前后数据分布的差异性来评估不同分类模型的全局可靠性。其次,为了提升分类模型对每个测试数据的局部分类性能,本文设计了一种局部可靠性评估策略,通过评估分类模型对测试数据邻域分类结果的性能来量化该测试数据被正确分类的可靠性,这样能够使分类模型对每个测试数据实现局部最优。最后,在证据推理框架下[9],结合全局可靠性因子和局部可靠性因子对不同分类模型的结果做折扣融合并决策分析。
1 相关工作
1.1 基于采样的方法
采样方法侧重于对输入数据进行预处理,以解决不平衡的问题,大致可以分为过采样和降采样两种方法。过采样方法[10-11]致力于生成数据来增加小类中的样本数量。例如,随机过采样方法(random over-sampling approach, ROS)[10]通过随机抽样的方式选取少量数据,然后将所选样本添加到原始小类中。降采样方法[12-13]致力于去除一部分样本来减少大类样本的数量。例如,随机欠采样方法(random undersampling approach, RUS)[12]随机选取一些与小类样本数量相同的大类样本,去掉其他样本,可能会丢失一些重要信息。
1.2 基于集成学习的方法
与采样方法不同,集成学习方法是将多个互补分类器组合在一起,以提高分类模型的整体性能。EasyensEmble是Liu等[14]提出的一种带双层结构的集成学习算法,先将大类进行欠采样,采样出多个子集分别与小类结合成多个子训练集,再以AdaBoost算法对每个子训练集进行训练从而生成基础分类模型。
2 本文方法
2.1 全局可靠性分析
假设测试集X={x1,x2,…,xH}在辨识框架Ω={ωmin,ωmaj}下被训练集Y={y1,y2,…,yG}训练得到的模型分类,Ymaj、Ymin分别表示数据量多的大类样本集合和数据量少的小类样本集合。

T=[IR];
(1)
(2)
式中:IR为可用于测量不平衡数据不平衡程度的不平衡比率;|· |表示势,用于统计集合中元素数量;[·]为四舍五入符号。
每个子集的样本数与Ymin的样本数相同,并与Ymaj组合生成新的训练子集{Y1,Y2,…,YT}。每个训练子集训练一个基本分类模型可用于对待测样本xi分类,定义为
(3)


(4)
(5)

可以看出,训练子集与原始数据分布间的差异性越大,对应分类结果的全局可靠性αit越小。
全局可靠性反映的是分类模型的全局最优化性能,但是由于不同模型对于特定测试样本的分类结果不同,因此还需要评估模型对每个测试样本的局部性能,这将在下一节中详细介绍。
2.2 局部可靠性分析
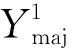

图1 不同分类模型的可靠性示意图Figure 1 Illustration of the reliability of different classifiers
(6)
(7)
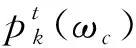
可以看出,分类模型Γt分类xi近邻的分类性能越好,其分类xi得到分类结果的局部可靠性也就越大。
至此,样本xi分类结果的全局可靠性以及局部可靠性都已计算得到,在下一节中会详细介绍如果有效地利用这些可靠性因子并融合多个分类结果。
2.3 复合可靠性折扣融合

(8)
式中:αit和βit分别为xi第t个分类结果的全局可靠性和局部可靠性。
在获得复合可靠性因子后,用折扣融合方法将xi的T个分类结果进行折扣融合,被折扣的分类结果定义如下:
(9)
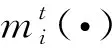
通过折扣融合可以将xi分类结果的部分概率值分配给完全未知类来表征数据类别的不确定性。复合可靠性因子越高,说明该分类结果越可靠,不确定性越小,被折扣掉的信息也就越少。经过折扣后的证据之间的冲突程度变小,在这种情况下就可以用基础的DS融合规则[15]结合多个折扣后的结果:
(10)
经DS融合后的结果mi中还包含有完全未知类的基本信任值,为了便于决策,本文将mi转换成pignistic概率[16]BetP(·)进行最终决策,定义如下:
(11)
式中:|Ω|为Ω中元素的数量。最后,测试样本xi可以分配到概率最大的类别。
本文所提出算法的计算步骤如下。
输入:测试集X={x1,x2,…,xH}、训练集Y={y1,y2,…,yG}、辨识框架Ω={ωmin,ωmaj}、小类样本集合Ymin和大类样本集合Ymaj;
输出:测试集类别。
① fort=1 toT
对训练集的大类数据Ymaj降采样;
用Ymaj训练分类模型测试样本分类;
依据式(4)、(5)计算分类的全局可靠性;
② endfor
③ fori= 1 toH
样本xi在训练集中搜索近邻并分类;
④ fort= 1 toT
分类模型Γt对xi的近邻分类;
依据近邻分类结果计算局部可靠性;
根据式(8)计算复合可靠性因子;
⑤ endfor
根据式(10)融合多个分类结果;
根据式(11)做最终决策;
⑥ endfor
3 实验
将本文方法与其他几种相关的典型方法进行比较。本文中的所有实验都是在配备英特尔酷睿i7-9750H芯片和16 G运行内存的计算机上进行。主要用两个常用的不平衡分类指标FM和GM评价不同方法的性能。FM和GM的值越高,该方法的性能就越好。
3.1 数据集
使用KEEL库和UCI数据库的12个不平衡数据集来测试和评估不同方法的性能。每个数据集使用五折交叉验证进行实验,能有效避免偶然性对结果的影响。这些数据集的基本信息如表1所示,包括数据集、数据库、样本数量、属性个数和不平衡比例IR。

表1 不平衡数据集基本信息Table 1 Basic information of imbalanced datasets
3.2 对比方法
采用一些典型的不平衡数据分类方法做对比实验。ROS和SMOTE是最具有代表性的过采样方法,被用来生成数据集来增加小类样本的数量,然后利用平衡训练集对基本分类模型训练。RUS和CBU是欠采样方法,采用随机策略和聚类方法从大类样本中抽取一些样本来平衡数据集。RUSBOOST和EasyEnsemble是集成学习方法,对原始数据集进行多次采样,并训练不同的分类器做出决策。此外,EATWSVM[17]在TWSVM公式中引入了内核增强,从而对不平衡数据进行分类。
3.3 本文方法对比相关不平衡数据分类方法
实验中将本文方法与其他对比方法相比较。不同方法分类结果的FM值和GM值分别见表2和表3,其中最后一行分别代表不同方法在不同数据集上得到的FM和GM的平均值。从实验结果可以看出,在大多数情况下,本文方法性能比其他不平衡数据分类方法更好;从平均值来看,本文方法的整体性能要明显优于其他方法,FM和GM值相较于其他最优的不平衡数据分类方法分别高出8.1%和4.99%。此外,不同方法在分类部分数据的ROC曲线和PR曲线如图2和图3所示。结果表明,本文方法的ROC曲线[18]和P-R曲线下方面积要大于其他方法,这进一步证实本文方法在分类不平衡数据的有效性。分析原因是本文方法在处理数据不均衡问题时不仅能够评估不同分类模型的全局性能而且量化了这些模型对每个测试样本的局部分类性能,从而提升了模型的分类性能,并在一定程度上避免了错误分类的风险。因此,本文方法相较于其他方法获得了较好的分类性能。

表2 不同方法分类不同数据集的FM值Table 2 FM values of different datasets classified by various methods
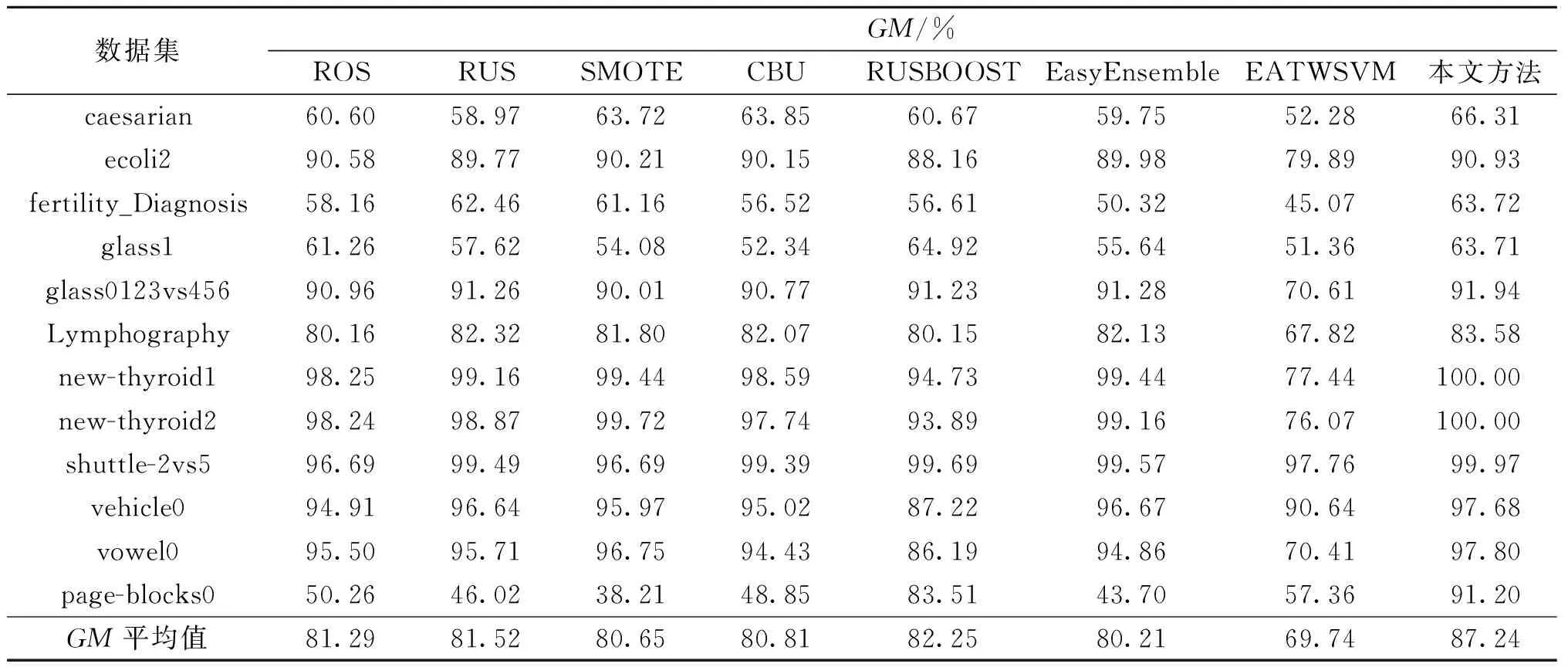
表3 不同方法分类不同数据集的GM值Table 3 GM values of different datasets classified by various methods

图2 不同方法分类不同数据集的ROC曲线Figure 2 ROC curves of different methods in classifying various datasets

图3 不同方法分类不同数据集的P-R曲线Figure 3 P-R curves of different methods in classifying various datasets
3.4 参数讨论
K值是影响本文方法性能的关键参数,K表示本文方法在评估模型局部可靠性时所需要找的近邻个数。图4所示为K值变化对本文方法在不同不平衡数据分类中性能的影响。其中横坐标为K的值,取值为3~15。实验结果表明,随着K的增加,本文方法在不同不平衡数据上分类性能的变化较小,这表明本文方法对K值具有一定的鲁棒性。在实际应用中推荐K∈[3,15]作为该参数的取值范围,默认值为7。
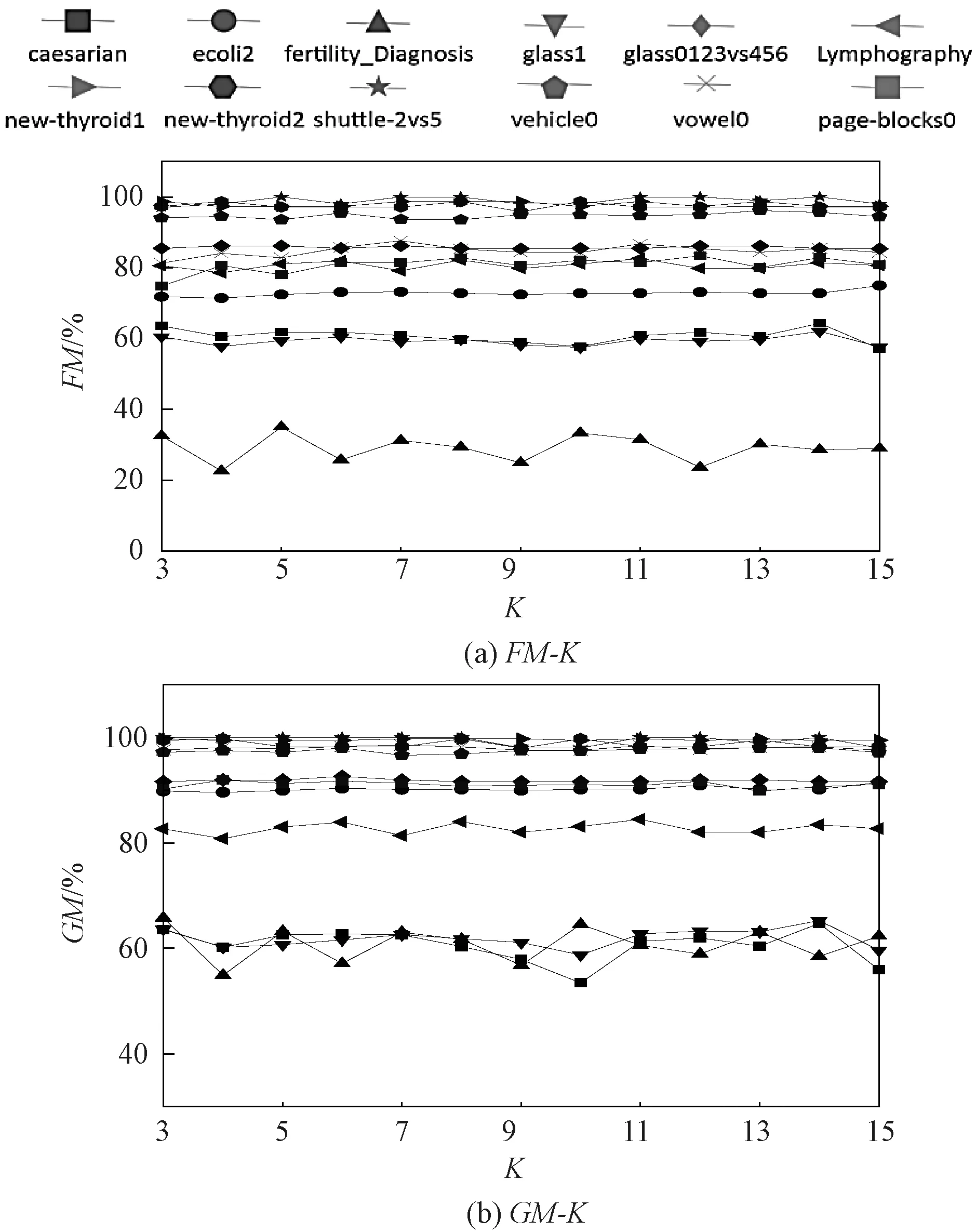
图4 本文方法在K取不同值时的分类结果Figure 4 Classification results of the proposed method with different K
4 结论
(1)提出了一种复合可靠性分析下的不平衡数据证据分类方法,该方法通过评估分类模型的全局可靠性和局部可靠性来提升模型对不平衡数据的分类性能。
(2)实验用公开的不平衡数据集验证了本文算法的有效性,FM值和GM值相较于其他不平衡数据分类方法分别高出8.1%和4.99%。
(3)在未来的研究中,将尝试利用集成学习的思想结合不同采样方法的优势,研究更高性能的不平衡数据分类方法。
