基于时空双流3D残差网络的服务动作识别
2023-07-07欧阳黎林彤尧彭冰莉
欧阳黎 林彤尧 程 莺 彭冰莉 温 和
1(国网湖南省电力有限公司供电服务中心(计量中心) 湖南 长沙 410004) 2(智能电气量测与应用技术湖南省重点实验室 湖南 长沙 410004) 3(湖南大学电气与信息工程学院 湖南 长沙 410000)
0 引 言
企业的服务质量对客户流量规模有着重大影响。近年来,为了提高企业的自身竞争力,国家电网树立“以客户为中心,专业,专注,持续改善”的核心价值观。围绕该核心价值观,为更好地提升客户满意度,许多供电营业厅采用动作识别技术检测营业人员的服务录像。与常用数据集[1-2]的传统动作识别不同的是,营业厅服务动作识别有着以下两个特点:(1) 大部分的服务动作场景是静态且相似的,无法通过背景信息判别服务动作。(2) 部分服务动作在柜台后进行,存在着遮挡问题,且服务动作的幅度很小,对动作识别方法的灵敏度要求极高。图1展示了传统动作识别的骑马场景与营业厅职业站立与鞠躬服务动作场景的特征。对于骑马动作,动作识别方法可以无须判断人物具体运动轨迹,仅依靠识别草原与马等背景特征就能进行识别。而营业厅服务动作识别的背景基本相同,且营业人员没有明显位移变化,服务动作的幅度较小,动作识别难度较大。因此营业厅服务动作识别有着很大的挑战性。

图1 传统动作识别的骑马场景与营业厅站立与鞠躬服务动作场景的特征
传统的动作识别方法大都是基于手工提取特征,例如HOG[3](Histogram of Oriented Gradients)、SIFT[4](Scale Invariant Feature Transform)和iDT[5](improved Dense Trajecto-ry)等。然而在面对大型数据集时,手工提取特征时间开销太大,同时也缺乏灵活与拓展性。因此手工提取特征的方法逐渐被深度神经网络方法替代。近年来,随着深度学习方法的发展,深度神经网络在金融[6]、水利[7]和计算机[8]等领域取得重大突破。在计算机视觉方面,2D-CNNs(Convolutional Neural Networks)作为深度网络的代表网络之一,因能提取RGB图像的高级特征,迅速成为了目标检测、视觉理解等图像领域的常用方法。Girshick等[9]提出R-CNN(Region Convolution Neural Network)进行目标检测,Donahue等[10]针对计算机的视觉理解提出递归神经网络结构。然而,与图像识别不同,视频动作识别除了空间信息还有时间维度的信息。为了能识别视频中的时空信息,Simonyan等[11]提出了双流网络,其使用2D卷积对RGB图像帧与光流图分别在不同通道进行特征提取。然而在动作识别上,2D卷积无法充分利用时间信息。为此Ji等[12]在2D卷积上拓展了时间维度,引入了3D卷积的方法,随后Tran等[13]提出了当时3D卷积网络的最优结构C3D(3D Convolution Network)结构,其通过将连续的视频帧进行堆叠,使用3D卷积核进行时空特征提取。为了减少3D网络的参数量和计算时间,Carreira等[14]结合inception网络[15]的方法提出了效果更好的I3D网络结构。
但随着深度网络的不断发展,为了应对更大的数据集,需要深度网络层数越来越多,产生梯度消失、过拟合等问题。为了解决这些问题,He等[16]提出了深度残差网络DRN(Deep Residual Network),其使用跨层连接的思想使得网络在加深的同时错误率不降反升。Hara等[17]探索了残差网络与3D卷积结合在动作识别上的性能,3D残差网络(3D-ResNet)即使对幅度较小的动作也有着较高的识别率。但仅使用RGB图像帧作为输入的深度卷积网络存在着过于依赖训练集的目标或场景信息[18]等问题。且在供电营业厅中,服务动作的场景都是静态相似的,视频中包含的场景信息较少且相似,仅使用3D残差网络在服务动作识别上显得十分困难。
考虑到深度卷积网络的识别率依赖于场景信息、服务动作幅度较小和光流图容易受噪声影响等因素[19],本文采用时空双流3D残差网络进行服务动作识别,其采用文献[11]的双流网络结构。第一个RGB通道采用能识别动作幅度较小的3D残差网络从RGB帧中提取时空特征;第二个光流通道采用结构简单的C3D网络从光流图中提取特征作为辅助时间特征。与文献[11]中提到的平均融合法不同,本文根据两个通道对每种服务动作的正确率,采用加权平均法将两个通道的预测分数乘以对应权重,将两个通道分数进行融合得到最终的动作识别预测分数。
1 时空双流3D残差网络模型
1.1 光流法
光流是二维成像中像素点的运动矢量场,常用来检测和估计目标。其主要计算第t帧图像中像素点到第t+Δt帧图像对应像素点的位置变化信息。当营业人员做出动作与摄像头产生相对位移时,便可以产生相应的光流信息。该光流可以有效地消除背景、人物穿着等因素的影响。设图像中像素点在(x,y)位置时的灰度值为I(x,y,t),根据光流亮度值恒定不变的约束可得公式:
I(x,y,t)=I(x+Δx,y+Δy,t+Δt)
(1)
将式(1)右边进行泰勒展开,忽略二阶以后的项,两边再同除dt可得光流公式:
(2)
式中:u、v分别为dx/dt、dy/dt,其代表着水平和垂直方向的光流值。但式(2)有两个未知数,通过一个方程是无法解出的,需要对其附加约束条件,光流约束计算方法通常分为稀疏与稠密光流法两大类。其中LK算法是常用的稀疏光流法,其是对图像帧一个局部像素点进行光流计算,先将式(2)化为矩阵形式:
(3)
记式(3)为AV=b,然后对其进行最小二乘法,再对其进行加权重值W,最后可得LK光流公式:
V=(ATWA)-1ATWb
(4)
Gunnar Farneback[20]算法是稠密光流法,与稀疏光流法不同,其需要对整个图像帧进行光流矢量计算。在得到稠密光流场后,使用孟塞尔系统将其转化为光流图像。不同的运动强度、方向可分别用颜色的深浅、不同颜色表示。其算法简单描述如下:
算法1稠密光流法(Gunnar Farneback算法)
输入:prev为图片帧,V为单个图像中每个像素的参数向量。
1.x←prev
# 图片帧转化为灰度图
2.f(x)←xTAx+bTx+c
# 建立二项式模型
3.将f(x)参数化得到(b1,b2,…,b6)×r
4.B←a×(b1,b2,…,b6)
# 加入权重a
5.G←对B进行对偶转换
6.V←G-1
图2为LK算法与Gunnar Farneback算法光流图。图2(a)为鞠躬服务动作的两个RGB图像帧,图2(b)、图2(c)分别为LK算法光流图和Gunnar Farneback算法光流图。虽然Gunnar Farneback稠密光流法计算速度慢于LK稀疏光流法,但可以看出稠密光流法包含的信息更多。这是因为鞠躬服务动作的动作幅度很小,稀疏光流不能时刻有效地提取运动光流场。因此将稠密光流输入作为融合信息能更好地提取模型的识别率。

图2 LK算法与Gunnar Farneback算法光流图
1.2 2D与3D卷积
传统的2D卷积网络有很强的特征提取能力,其本质是使用不同卷积核得到不同卷积特征图。在第i层的第j个卷积特征图的(x,y)位置的2D卷积计算公式为:
(5)
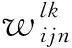
然而,传统的2D卷积网络不能很好捕捉时序上的信息。为了解决2D卷积网络的缺陷,3D卷积网络通过拓展时间维度,使用3D卷积核从连续帧中提取特征,使得每个特征图都包含相邻的连续帧的信息。在第i层的第j个卷积特征图的(x,y,t)位置的3D卷积计算公式为:
(6)

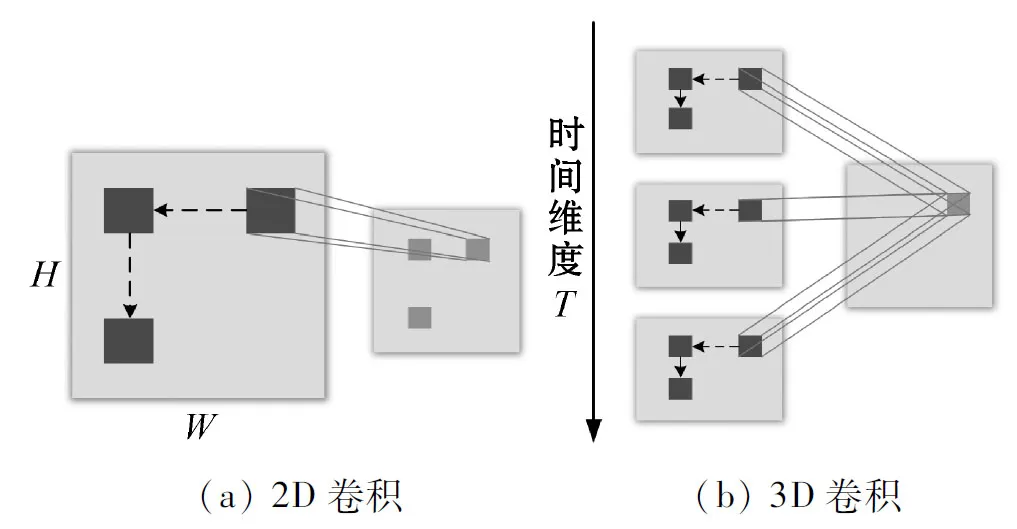
图3 2D卷积与3D卷积对比
1.3 3D残差网络结构
3D残差网络是基于残差网络的跨层连接思想得到的。当输入x进入时,跨层连接结构提供了允许输入x绕过一层而移动到序列中下一层的快捷连接。相比于通过一堆非线性卷积层拟合映射,残差结构的训练目标更容易达到。图4展示了跨层连接结构。

图4 跨层连接结构
图4中BN(Batch Normalization)与ReLU (Rectified Linear Unit)分别为批量归一化和线性整流函数。BN的作用是使得每一层神经网络的输入在深度神经网络训练过程中保持均值为0、方差为1的正态分布,使得网络训练速度加快。其算法如算法2所示。
算法2批量归一化(Batch Normalization)
输入:样本xi,调节参数α、β,yi。
# 求每个样本的均值
# 计算方差
# 对数据进行归一化
# 对输入进行平移与缩放
激活函数为ReLU,运算速度快且能有效避免梯度消失和梯度爆炸等问题,其公式为:
(7)
3D残差网络具有多种不同层数的结构。表1展示了3D残差网络的18层和34层的整体结构。
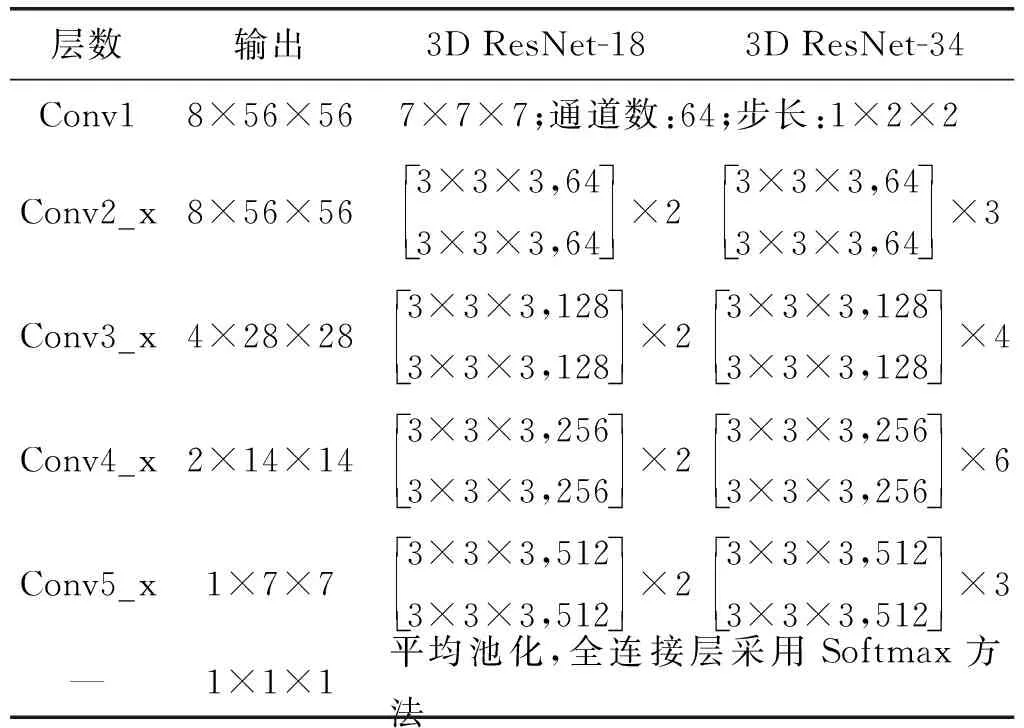
表1 3D残差网络结构
3D残差网络输入为16个像素大小为112×112的连续帧。在卷积层,与C3D[13]类似,采用3×3×3的3D卷积核对其进行特征提取,第一个卷积层在时间维度的步长为1,其他维度的步长均为2。在池化层采用平均池化的方法,使得提取的特征参数减少,保持某种特征图不变(旋转、伸缩、平移等)。在全连接层采用Softmax函数对样本分类进行预测,其公式为:
(8)
式中:Ypq为第p个样本属于第q种动作的预测概率;xpu为第p个样本通过分类层后输出向量中的第u个元素。
当特征图的数量增多时,采用补零方法避免参数增多。在训练模型时采用随机梯度下降法[21],损失函数为交叉熵函数,通过最小化损失函数对模型进行训练,其公式为:
(9)
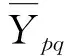
2 实 验
2.1 数据集
本文服务动作数据集由湖南省计量中心提供,拍摄地点为国网湖南省xx市供电营业厅,共有961个服务动作视频片段。数据集是从正面和侧面两个角度拍摄5位服务员做6种服务动作得到的。服务动作分别是坐下、职业站立、鞠躬、递交材料、介绍服务内容和握手。表2为各服务动作的具体视频片段数量。
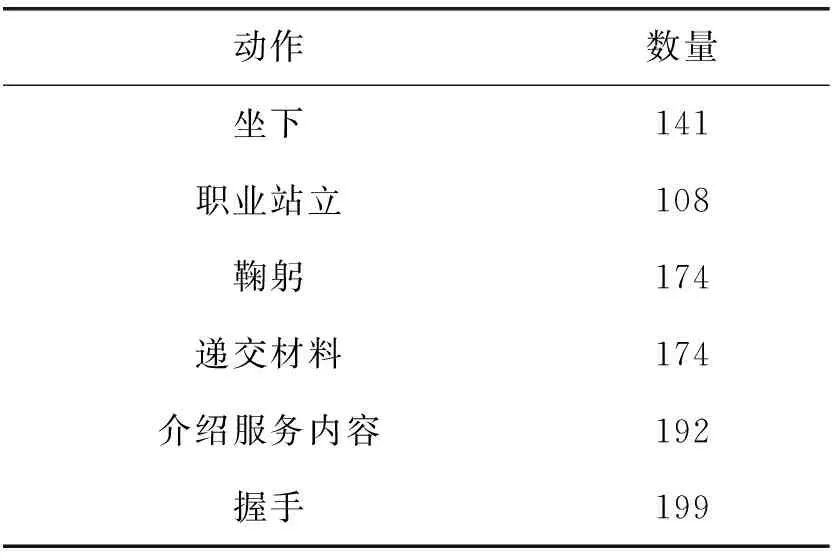
表2 各服务动作的具体视频片段数量
与常用UCF101数据集类似,本文将视频转换成像素大小为320×240的视频文件。为了更好地测试融合3D残差网络,本文随机将961个视频按4∶1的比例分为训练集和测试集。图5为数据集服务动作。

图5 数据集服务动作
2.2 实验过程
实验在Linux平台下完成的,环境变量为Python 3.7,使用1块GPU(2080Ti)训练网络。实验前,分别进行数据集预处理,使用OpenCV从RGB视频中计算光流并用孟塞尔系统进行上色得到光流图;按固定帧数截取视频,将图像帧按照像素大小为112×112进行随机剪裁得到RGB图像帧。
实验中,为了测试不同结构的3D残差网络的识别率,分别对18、34和50层3D残差网络进行训练。首先将连续的16帧RGB图片作为3D残差网络的输入。然后采用Kinetics的预训练模型防止过拟合和更容易训练网络。设置初始学习率为0.1,动量为0.9,权重衰减为0.001,batch size为64,训练持续250个epoch。最后训练完毕后,使用相同的测试集对3种3D残差网络进行测试得到最优网络。为了得到光流通道的识别率,将16帧光流图输入C3D网络结构中,使用初始学习率为0.000 1,移动平均衰减为0.999,最大迭代步长分别设为500、1 000、1 500和3 000步进行训练测试。得到两个通道的最优网络后,使用加权融合方法得到最后的预测分数。
2.3 实验结果分析
为了评估不同结构的3D残差网络在服务动作数据集上的效果,本文分别对18层、34层和50层的3D残差网络进行测试。测试结果如表3所示。
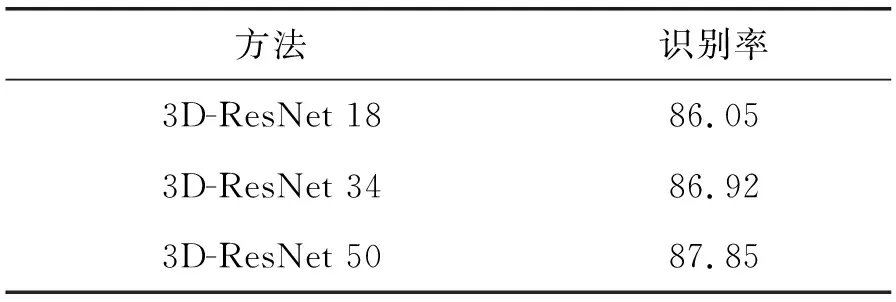
表3 不同结构的3D残差网络识别率(%)
可以看出,识别率随着3D残差网络深度的增加而增加。当测试集的数量足够时,网络的参数越多其学习服务动作的能力越强。因此本文选用50层的3D残差网络作为RGB通道的网络结构。接着为了探究光流通道的C3D网络服务动作识别率,本文分别设置不同的最大迭代步长,测试结果如表4所示。

表4 C3D在不同最大迭代步长下的识别率(%)
可以看出,C3D网络的识别率在最大迭代步长1 000后无明显浮动,因此本文选择识别率最高的最大迭代步长1 500作为C3D网络参数。虽然光流通道的整体识别率低于RGB通道接近10百分点,但在实验中发现,光流通道对肢体动作幅度较大的服务动作比RGB通道更敏感。例如,当营业人员坐下时,光流矢量场在营业人员的上半身产生明显变化。图6为坐下动作的光流图(从左至右为坐下动作开始至结束的过程)。

图6 坐下动作的光流图
这种明显的变化使得光流通道在坐下和介绍服务内容的两个服务动作的识别率高于RGB通道。表5为两个通道分别在坐下和介绍服务动作的识别率。
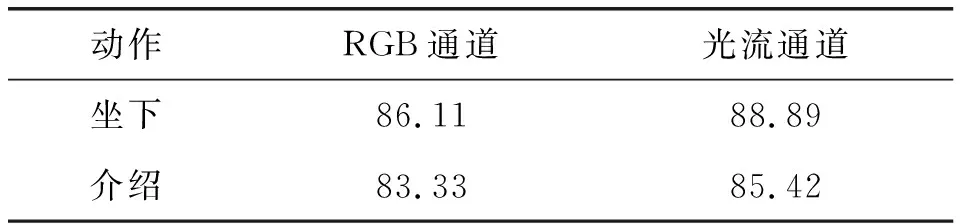
表5 坐下和介绍服务动作的识别率(%)
因此通过加权融合的方式,将光流通道对肢体动作幅度较大的服务动作高识别率与RGB通道拥有稳定的高识别率的两个特点相结合,能有效提高对服务动作的整体识别率。为了说明时空双流3D残差网络的识别效果,将其与其他动作识别方法在本文的服务动作数据集上进行对比,表6为不同方法的识别率对比。

表6 不同方法的识别率对比(%)
可以看出本文方法在服务动作数据集上的识别率为90.65%,高于其他动作识别方法,且仍有不少的提升空间。此结果也证明了时空双流3D残差网络的有效性。
3 结 语
针对供电营业厅服务动作识别存在的难题,构建基于3D残差网络和C3D网络的双流时空3D残差网络融合方法。RGB通道使用3D残差网络提取信息丰富的RGB图像提升对动作幅度较小的识别率;光流通道使用C3D网络提取光流图特征作为辅助特征进行融合。实验结果表明双流时空3D残差网络对服务动作识别有着较高的识别率。但是本文方法也存在不足之处,在后续的研究中还需对光流特征提取的速度进行优化,同时为了将本文模型更好地应用到实际场景中,需要对模型进行更多种类的服务动作测试。
