神经网络训练处理器的浮点运算优化架构
2023-07-06张立博李昌伟戚鲁凤
张立博,李昌伟,齐 伟,王 刚,戚鲁凤
(1.中国绿发投资集团有限公司,北京 100010;2.山东鲁软数字科技有限公司,济南 250001)
0 引言
随着人工智能(AI)蓬勃发展,网络模型的精准度不断提升,应用场景愈发广泛,但网络模型存储压力不断增加,模型运算量日益增大,资源受限的互联网设备面临新的挑战[1]。AI技术需要利用低能耗的神经网络处理器,但最近的大多数研究都集中在设计仅用于推理的加速器上[2]。然而,为了能够真正利用AI服务于现实需求,还需实现自我监督和半监督学习,这就要求神经网络处理器除了具有推理功能外,还要减少训练过程。
大多数关于神经网络加速器的研究都集中在确定输入数据准确性的正向架构和电路结构上[3]。然而,为了尽可能地模拟人类或动物的神经网络,有必要在反向传播中设计一个通过精度反馈的神经网络电路,从而能够使用尺寸更小且功耗更低的运算_架构。文献[4]指出神经网络的学习可分为芯片外学习和芯片内学习。其中,芯片外学习通过借助互联网设备分散大量运算,文献[5]总结出使用边缘设备收集、处理和分析神经网络类数据更有效。文献[6]验证了与服务器重复交互的边缘设备更能显著减少电能消耗。文献[7]开发了基于树的算法用于预测资源受限的互联网设备。芯片内学习则是通过设计优化的轻量级神经网络模型在低功耗且小尺寸的芯片上实现训练[8]。
为了实现低功耗,必须为所涉及的数学计算选择适当的格式。文献[9]研究表明整数运算足以设计低功耗推理加速器,然而,还需要大量的研究来训练具有合理精度的神经网络。文献[10]的实证结果表明,训练神经网络需要至少16bit精度。文献[11]中实现了使用整数运算的混合精度训练,将两个整数相乘并输出存储到整数累加器中。然而,整数运算符无法代表广泛的数字,严重阻碍了训练引擎中使用。
当用于训练神经网络时,浮点运算比定点运算具有更高的精度[12]。传统的神经网络电路设计研究集中在利用GPU 或定点计算硬件进行浮点运算。然而,大多数现有的基于浮点的神经网络仅限于推理操作,只有少数包含针对高速服务器而非低功耗移动设备的训练引擎[13]。将训练与高精度目标结合起来需要使用浮点运算符。神经网络中的高精度浮点运算结构往往会大量能耗。因此,需要设计出优化浮点运算的加速器。通过计算近似技术可以有效降低计算复杂性,最大限度地减少浮点算子的显著能耗[14]。虽然计算近似技术在能耗和吞吐量优化方面表现出较好的性能,但现有研究热点集中在反向传播期间保持权重更新的精度。文献[15]通过维护浮点权重的主副本来实现混合精度训练,并且在向前和向后传播期间使用浮点的另一副本。然后,权重梯度需要更新浮点运算主副本并在每次迭代中重复该过程。尽管减少了整体内存使用量,但保持权重的副本会将权重的内存需求增加两倍[16],并且由于额外的内存访问将不可避免地导致整体性能发生延迟。
为了能够兼顾神经网络训练中浮点运算的训练过程和高精度,本文设计了一种具有高性能卷积神经网络(CNN)训练处理器的浮点运算优化架构。在不牺牲精度的情况下找到最佳浮点格式。利用混合精度架构,将需要更高精度的层分配了更多的存储,而需要更少精度的层分配了更少的存储。通过评估不同的浮点格式及其组合来实现浮点运算符,从而以更少的能耗实现更高的精度结果。通过CNN 和浮点训练设计一种混合精度加速器实现更高精度的卷积块,并运用MNIST手写数字数据集验证了优化架构的有效性。
1 卷积神经网络(CNN)训练加速器
1.1 CNN架构
CNN 作为人工神经网络(ANN)的分支,最常用于特征提取和分类[17]。使用CNN 训练加速器训练电路,从而高效准确地对输入图像进行分类。CNN 训练加速器的体系结构可在正向传播过程中使用经过训练的权重从输入值推导输出,并在反向传播过程中更新权重,进而提高正向传播中下一幅图像的总体精度[18]。CNN 的总体架构,如图1所示。其中,Conv为卷积,ReLu为线性整流函数。Softmax为归一化指数函数。
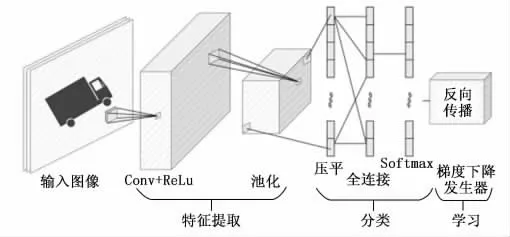
图1 CNN 的总体架构
1.2 Softmax模块
Softmax函数作为激活函数,根据概率分布将网络的输出标准化为输出类。Softmax函数将N个实数组成的向量xi作为输入,由N个概率组成的概率分布建立标准化,且概率与输入值的指数成正比。因此,对每个输入向量应用标准指数函数,每个输入向量指数值除以所有累加指数对每个输入向量进行标准化。则SoftMax函数可以表示为:
从公式(1)可以看出,计算SoftMax值需要1个除法器模块和1个加法器模块。
1.3 梯度下降发生器模块
CNN 训练模型利用反向传播算法将输出层的误差向后传播,并使用基于梯度下降的优化算法逐层更新变量[19]。本文利用加速变量更新收敛方式平滑梯度下降学习过程中遇到的波动,CNN 模块中的权重更新为:
其中:θτ为时刻τ的权重,η为学习率,Δντ为梯度。从公式(2)可以看出,梯度下降权重更新需要1个乘法器和1个减法器模块。
2 浮点运算体系结构
2.1 通用浮点数与运算
根据IEEE 754标准,由3个元素定义浮点格式:1)符号(正/负);2)精度(实数的有效位数,尾数);3)位数(索引范围)。浮点数可以表示:
其中:Sign为符号指数,E为指数的二进制值,eb为指数范围的中值,M为尾数,即小数点后的数字部分。浮点运算的流程图,如图2所示。其中,MUX 为多路复用器,浮点数的每个部分单独计算。
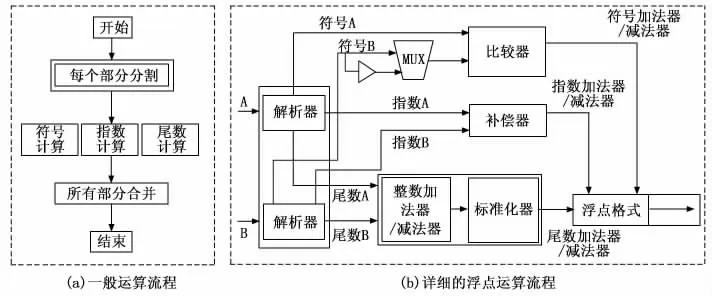
图2 浮点运算的流程图
浮点运算的步骤为:
步骤1:在执行实际计算之前,原始的浮点数A和B划分为{符号A,指数A,尾数A}和 {符号B,指数B,尾数B}。
步骤2:对于每个分离的元素分别进行运算:
1)符号:在加法/减法运算中,通过比较两个输入的尾数和指数来确定输出符号,在输入B 的符号处放置1个非门和1个MUX,使用反向符号在相同模块进行减法运算。在乘法/除法运算,通过异或(XOR)运算得到两个输入符号。
2)指数:如果指数值不同,则在两个输入中选择较大的指数值。对于指数值较小的输入,有效数位右移一位使得两个数字与同一个小数点对齐。两个输入的指数大小之差决定了要执行右移的次数。
3)尾数:通过无符号运算计算尾数的值。尾数位的加法/减法运算结果可能比两个输入的尾数位大1bit。因此,为了获得精确的结果,本文将两个输入的尾数位大小增加了两次,然后根据尾数的计算结果,无论最高有效位(MSB)为0或1,对尾数进行加法或减法运算。如果MSB为0,则不需要标准化。如果MSB为1,则标准化器移动先前计算的指数位和尾数位来得到最终合并结果。
步骤3:每个计算出的元素合并成一个浮点前置模块,从而生成结果以浮点形式输出。
2.2 浮点数格式的变体
本文利用4种不同的浮点格式优化CNN。每种浮点格式的详细信息,如表1所示。
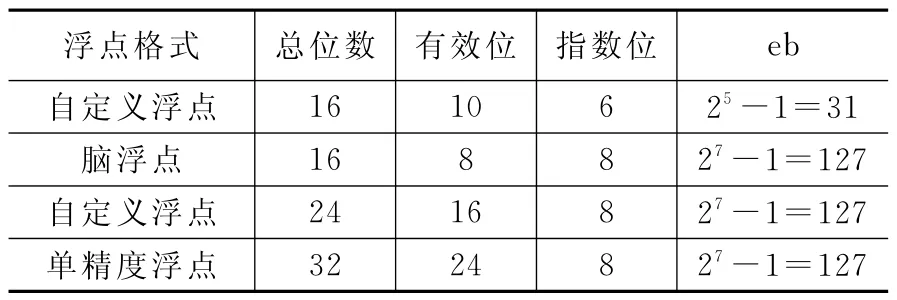
表1 4种不同的浮点格式
表1中的有效位表示位,包括符号位和尾数位。本文中使用的每种浮点格式,如图3所示。
16bits自定义浮点格式用于与现有的16bits脑浮点格式进行比较,24bits自定义浮点格式用于与其他浮点格式进行比较。本文还在16bits卷积块中使用24bit自定义浮点格式进行累加,从而提高网络的精度。
2.3 基于倒数的除法运算
本文使用牛顿迭代法[20]作为除法运算的算法,只需要减法和乘法即可计算出一个数的倒数。在数值分析中,实值函数f(y)近似为一条切线,其方程由f(y)的值及其在初始近似处的一阶导数求得。如果yn是真实值的当前估计值,则下一个估计值yn+1可以表示为:
其中:f′(yn)为f(yn)对yn的一阶导数。
在倒数生成器中有3个整数乘法器,其中两个乘法器负责在多次迭代后生成倒数。为了在倒数生成器中执行快速计算,本文使用Dadda乘法器[21],其中部分乘积在半加法器和全加法器阶段求和,然后使用常规加法器将最终结果相加。基于倒数的浮点除法器的结构,如图4所示。

图4 基于倒数的浮点除法器的结构
3 浮点运算优化架构
3.1 基于符号数组的除法运算
由于基于倒数的除法器需要许多迭代和乘法器,因此,不可避免地受到处理延迟和过多硬件能耗的影响。本文使用符号数组来计算二进制数的除法[22],与使用倒数的除法计算相比,符号数组除法没有重复的乘法运算。为了对分割进行优化,使用专门设计的处理单元,通过减法运算和执行反馈来选择除法的商值。符号数组除法处理单元(PU)的结构,如图5所示。

图5 符号数组除法处理单元的结构
基于符号数组的浮点除法运算符整体结构,如图6所示。其中,LSB为最低有效位。首先计算符号数组模块中的尾数,使用减法器/补偿器计算指数,使用XOR 独立计算结果的符号位。符号数组模块中的每行都计算部分除法(从先前的部分除法中减去),然后将其传递到下一行。每行右移一位,使每个部分除法对应于被除数的下一位位置。数组除法器的每行决定了除法的商值的下一个最高位,将3个元素进行合并得到最终的除法器结果。

图6 基于符号数组的浮点除法运算符整体结构
本文设计的加速器结构将能耗和硬件尺寸降至足以满足互联网应用需求的程度。为了比较硬件尺寸、处理延迟和总能耗,使用设计编译器合成工具和台积电(TSMC)55nm标准单元实现倒数和符号数组这两个除法器。倒数和符号数组进行除法计算的比较,如表2所示。对于50MHz和100MHz的运算时钟,本文所提出的符号数组除法器比基于倒数的除法器分别降低了6.1倍和4.5倍。对于这两个时钟,符号数组除法器的处理延迟分别缩短了3.3倍和6倍。此外,与基于倒数的除法器相比,显著降低了17.5~22.5倍的能耗。因此,在实现CNN 训练加速器的Softmax函数时选择所提出的符号数组除法器。

表2 倒数和符号数组进行除法计算的比较
3.2 浮点乘法器
与浮点加法器/减法器不同,浮点乘法器计算尾数和指数时不依赖于符号位。符号位通过两个输入XOR 门计算。加法器和补偿器块通过将两个输入数字的指数相加并从结果中减去偏移量“127”来计算得到的指数。如果计算的指数结果不在0和255之间,则视为上溢/下溢,并饱和到界限。即任何小于0的值(下溢)饱和为0,而大于255的值(上溢)饱和为255。通过两个输入尾数的整数乘法计算得到尾数输出,使用指数值重新排列尾数位,然后合并生成最终的浮点格式。浮点乘法器的体系结构,如图7所示。

图7 浮点乘法器的体系结构
3.3 CNN加速器的总体架构
为了评估所提出的浮点运算符的性能,本文设计了可支持两种运算模式的CNN 加速器,即推理和训练。加速器配备了用于发送图像、滤波器、权重和控制信号的芯片外接口。CNN 加速器的总体架构,如图8所示。其中,FC为全连接网络,dout为梯度,dW 为权重导数。
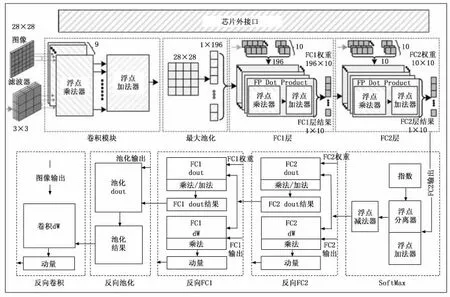
图8 CNN 加速器的总体架构
在发送大小为28×28 的MNIST 手写数字图像之前,通过芯片外接口将大小为3×3的4个滤波器、大小为196×10的FC1和大小为10×10的FC2的初始权重写入芯片内存储器。接收到启动信号后,将训练图像和滤波器权重传递给卷积模块,并根据矩阵的点积计算卷积。最大池模块通过在输出特征数据的每个2×2子阵选择最大值,对卷积模块的输出进行下采样。对FC1和FC2两个全连通层进行SoftMax运算,将预测输入图像的分类作为推理结果。
在训练模式下,反向传播按照CNN 层的倒序计算矩阵点积的梯度下降。Softmax层和反向传播层也用于进一步训练部分权重。从图8可以看出,全连接层分为dout模块和dW 模块,其中,dout模块用于计算梯度[23],dW 模块用于计算权重导数[24]。由于反向卷积为最后一层,因此没有dout模块。通过反复计算dout和dW 来训练每个层的权重值,直至权重值达到所需的精度。经过训练的权重存储在各自的存储器中,并用于训练过程的下一次迭代的推理。
3.4 CNN结构优化
为了找到最佳浮点格式来优化CNN 体系结构,本文计算了不同精度格式的准确率和动态功率,从而找到具有合理精度的浮点,如表3所示。

表3 不同精度格式的准确率和动态功率
本文选择93%的目标准确率,尽管自定义-24 格式满足93%的准确率阈值,但其动态功率为30mW,比单精度-16浮点格式高58%。因此,在满足目标准确率的同时,搜索各个层的最佳浮点格式来实现最小的能耗。本文中设置为单精度-16的初始浮点格式计算准确率,将指数逐渐增加1bit,直至准确率停止增加或开始降低。因此,在第k次迭代中,指数位增加,而随着尾数位的减少,整体数据宽度(DW)保持不变。在确定指数位宽度后,算法使用新的浮点数据格式计算性能指标(准确率和能耗)。在本文实验中,发现尾数优化之前的新浮点格式为(Sign,Exp,DW-Exp-1),DW=16bit,Exp=8,尾数=16-8-1=7bit。通过逐渐将尾数增加1bit对每层的精确度格式进行优化,直至当前DW 满足目标准确率。当所有层在满足目标准确率的同时以最小能耗进行优化时,将为所有层存储最佳格式的组合。然后,将所有层的DW 增加1bit,重复上述过程来搜索其他最佳格式,直至DW 达到最大数据宽度(MAX DW),本文实验中DW 设置为32bit。完成上述搜索过程后,将比较所有搜索结果的准确率和功率,在保持目标准确率的情况下,确定功率最小的格式构建最佳组合。
4 实验分析
4.1 浮点运算符的比较
使用Synopsys软件设计编译器对不同格式的比较进行了评估,编译器可以将HDL设计合成为SoC数字电路。使用台积电(TSMC)55nm 工艺技术和100 MHz的固定频率进行评估。不同位宽的浮点加法器和减法器的比较,如表4所示。
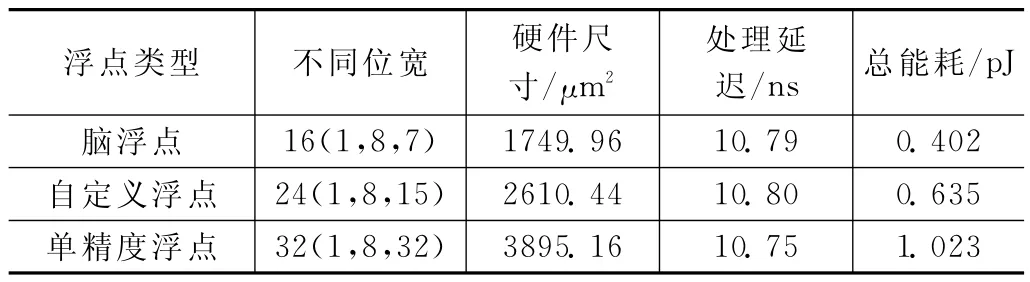
表4 不同位宽的浮点加法器和减法器的比较
由表4可见,浮点加法器/减法器运算的位数越少,硬件尺寸或能耗就越小。每个位宽的浮点格式由N(S,E,M)表示,其中N为总位数,S为符号位,E为指数,M为尾数。使用不同位宽的浮点乘法器的比较,如表5所示。

表5 不同位宽的浮点乘法器的比较
由表5可见,浮点乘法器运算的位数越少,硬件尺寸和能耗就越小。与加法器/减法器不同,乘法器能耗大幅增加。使用不同位宽的浮点除法器的比较,如表6所示。
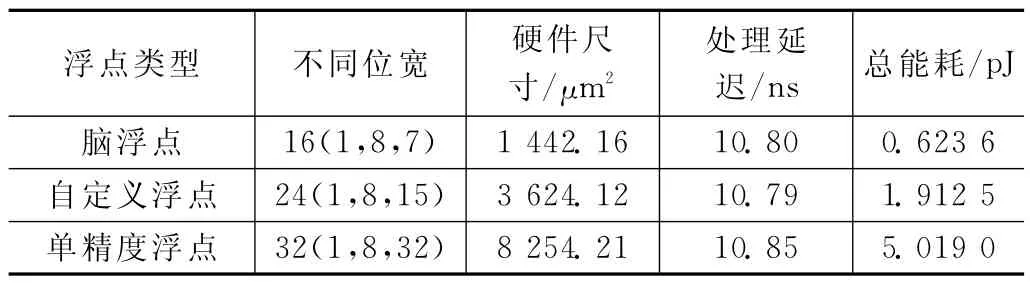
表6 不同位宽的浮点除法器的比较
由表6可见,与其他运算符相比,浮点除法器运算延迟时间是恒定的,但浮点除法运算的位数越少,硬件尺寸和能耗就越小。
4.2 CNN训练加速器的性能评估
本文所提出的CNN 训练加速器使用Verilog在寄存器传输级设计中实现,并使用Vivado Verilog模拟器进行验证。确认结果后在现场可编程门阵列(FPGA)上实现了加速器,并针对50 K 图像训练了所有测试用例模型。训练后,通过将MNIST 手写数字数据集中的10K 测试图像用于训练模型来计算推理准确率。
表7给出了优化算法找到的几个突出的格式组合搜索结果。在格式组合中,混合卷积-24选为准确率和功率方面最优的格式组合。这种格式组合在卷积层(正向和反向传播)中使用24bit格式,同时为池、FC1、FC2和Soft-Max层(正向和反向传播)分配16bit格式。
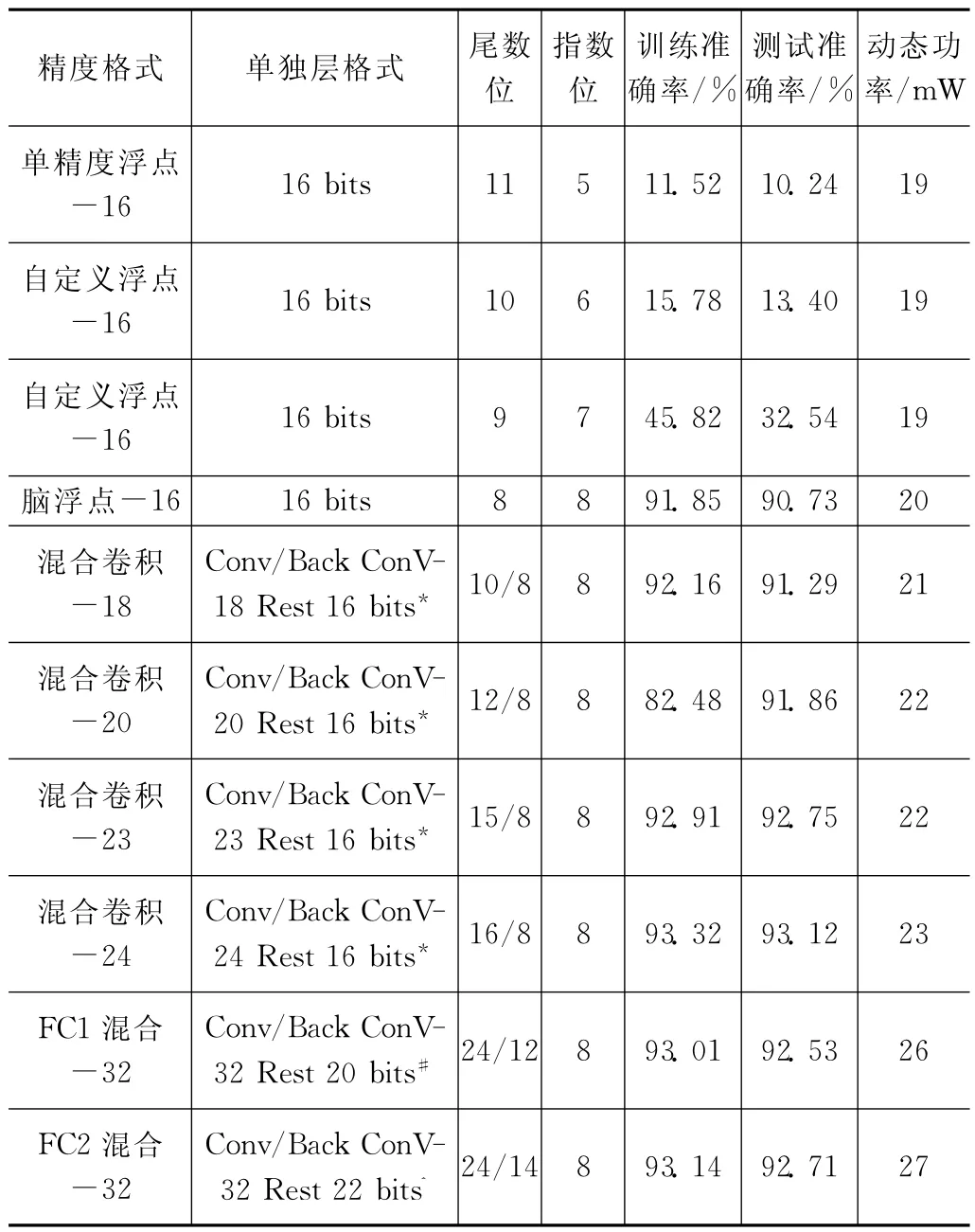
表7 不同精度格式下优化算法准确率和动态功率的比较
4.3 优化架构比较
为了验证本文提出的浮点运算优化架构比现有FGPA加速器大幅减少硬件资源,利用MNIST 手写数字数据集,将本文的最优架构(混合卷积-24)与文献[25]使用的传统CNN、文献[26]采用滑动滤波器进行CNN 和乘与积(MAC)的并行运算、文献[27]提出的基于Spike网络加速器的CNN 等方法进行比较,如表8所示。

表8 优化架构比较
由表8可见,在本文的最优架构(混合卷积-24)加速器中,每幅图像的能耗仅为8.5μJ,每幅图像的能耗分别比传统CNN 方法、CNN+MAC 方法和Spike+CNN 方法低1 140、81和555倍。
5 结束语
本文评估了不同的浮点格式并优化了CNN 训练中的浮点运算符,在高达100 MHz的频率下增加了吞吐量。使用MNIST手写数字数据集进行评估,使用混合精度体系结构实现了93%以上的准确率,并且每幅图像的能耗仅为8.5 μJ,比其他方法显著地降低了能耗。由于加速器仅需55nm芯片即可实现低能耗和高精度,因此,本文设计的加速器适用于现实AI应用。在未来的研究中,尝试在CNN 加速器中添加8bit配置,使其更进一步降低能耗。
