考虑主体失望情绪的分布语言自信群决策方法
2023-07-04张善丽张世涛刘小弟
张善丽,张世涛,刘小弟
安徽工业大学 数理科学与工程学院,安徽 马鞍山 243032
1 引 言
语言型多属性群决策指多个决策者在多个指标下利用语言术语评估可能的备选方案。如某人对学校食堂的饭菜味道进行评价,“食堂的饭菜味道很好”,“很好”就是语言型评价信息。然而,“很好”的程度究竟是多少,或者多少人认为它“很好”,这种表达形式并不能完全反映事物的更多信息。为此,人们尝试利用较为复杂的语言表述而非单一语言术语表征其判断或评价。受比例二元语义表示模型[1]的启发,Zhang等[2]提出语言分布评估(LDA)概念。分布式语言表征是语言决策中反映偏好信息不确定性和复杂性的有力工具[3]。鉴于语言分布评估比语言评估能够更真实地模拟定性决策偏好,减少原始信息损失,近年来,基于分布语言评价信息的多属性群决策(MAGDM)问题已成为研究热点。例如,Yao等[4]提出一种基于分布语言的多属性群决策共识模型;Li等[5]针对不完全语言分布群决策提出了一致性驱动的访求 来管理未知信息和个性化语义。针对不平衡语言信息,Zhang等[6]提出具有多粒度不平衡犹豫模糊语言信息的大群体多属性决策模型,其所有不平衡的犹豫模糊语言信息都被转换为在一个平衡的语言术语集上定义的分布语言,并设计了一种基于分布语言的聚类算法。
在决策问题中,借助偏好关系表征决策者关于成对方案比较的偏好十分常见。在一个完整的偏好关系中,通常假设所有的偏好值都具有相同的自信水平。在一个不完全的偏好关系中,使用了两个自信级别:一是决策者对所提供的偏好元素有自信;二是决策者对未给出值的偏好元素没有自信[7]。在偏好结构上考虑到多重自信特点,Liu等[7-8]提出一种新的偏好关系,即具有自信的模糊偏好关系。自此,基于自信偏好的决策研究得到了重视。Liu等[9]研究了带自信水平的模糊偏好关系的加性一致性;Gou等[10]基于优先级排序理论,建立了基于自信双层语言偏好关系的群体共识模型;Liu等[11]提出自信积型偏好关系的群体共识模型;Zeng等[12]提出基于决策者自信毕达哥拉斯模糊集的MAGDM框架。Z-number[13]和语言型Z-number[14]与自信偏好表达的方式类似,一定程度上考虑到评价信息的模糊性限制和可靠性限制。Z-number的计算相比自信偏好较为复杂,相关的研究也间接论证了决策过程中考虑专家信息可靠性是非常重要的。然而,现有关于自信偏好的研究大多基于自信偏好关系结构,具有多重自信水平的语言型MAGDM的研究仍不多。
在实际决策中,决策者的心理情绪(如欣喜、后悔、失望等)隐含于决策判断或评价,对决策结果有着重要影响。为模拟涉及主体的心理情绪而不是最优决策(如效用最大化)的现实生活选择,学者们相继提出了一些经典的行为决策理论(如前景理论、累积前景理论、后悔理论和失望理论)[15]。其中,失望理论最初由Bell[16]提出,Bell指出计算主体实际效用的函数应该结合主观效用值和失望欣喜值。进一步,Loomes和Sugden、Delquie和Cillo分别提出了存在先验期望与没有先验预期的失望理论[15]。Zeelenberg等[17]指出后悔和失望是两种不同的情绪,它们来自于不同的前期条件,并与不同的评估模式有关,会产生不同的结果。后悔被认为是事实决定结果和可能选择不同的反事实结果之间的比较;失望通常是对由无法控制的情况或其他人引起的意外负面事件的反应[17]。在某些实际决策情况下,与前景理论、累积前景理论和后悔理论相比,失望理论在一定程度上可以更好地模拟一个人的真实情绪[15]。比如,在商业与金融中,失望情绪似乎是一种常见的感觉,因为公司的经理通常具有效用功能,同时包含风险厌恶和失望厌恶。在实际的双边匹配问题中,心理行为(例如,对匹配结果的失望或欣喜)是广泛且真实的[18]。考虑双边主体的失望心理行为,Fan等[18]提出一种新的满意双边匹配决策方法。近十年来,针对不同决策情境,考虑决策者不同心理行为的多属性(群)决策研究受到了广泛关注。例如,针对带方案比较混合型模糊真度的异质多属性群体决策问题,Wan等[19]提出一种新的基于前景理论的决策方法;Zhang等[20]基于后悔理论提出了多维偏好和不完全权重信息的群决策方法;刘洋等[21]基于后悔理论提出了事前-事中两阶段突发事件应急决策方法;Zhang等[15]。提出了基于失望理论的犹豫模糊语言应急共识模型。
通过梳理既有文献发现,目前关于分布语言多属性群决策的研究取得了较为丰富的成果,包括分布语言的比较和集结方法、距离测度、决策方法、分类等。自信偏好结构的相关研究也进行得如火如荼。同时,考虑到人是有限理性的,其行为受到多类型心理情绪的影响,为此,学者们相继提出对应的行为决策理论,这些均为不确定环境下构建合适的行为多属性群决策模型和方法提供了坚实的理论基础。然而分布语言评价信息下的多属性群决策仍有以下不足:现有的分布语言多属性群决策中考虑主体失望情绪的文献较少,而在实际决策中,主体的失望情绪会对决策结果产生影响,忽略主体失望情绪定会导致决策偏差;决策者在实际决策中因为背景、经验、知识等原因会对自身给出的评价信息有着不同水平的自信程度,这也反映了决策者给出评价信息的可靠性,会对决策结果产生重大影响。然而,现有关于分布语言多属性群决策的文献甚少考虑决策者具有这种多重自信水平的特征。鉴于此,本文在分布语言评价下,结合决策者内心的多重自信水平,定义了一种新的评价形式,即分布语言自信评价。同时,在决策过程中考虑主体失望情绪,提出了一种基于分布语言自信评价的行为多属性群决策方法,并将其应用于循环经济背景下生态工业园区的优选评估。主要创新点在于:将主体失望情绪融入基于分布语言自信评价的群决策过程,给出分布语言自信评价下测算主体感知效用的新方法;构建一种新的Dice相似测度来测度自信效用向量的相似性程度;集成新Dice相似测度和属性不兼容性程度构建优化模型确定属性权重。
2 预备知识
2.1 基本定义
定义1[22]设S={sα|α=-τ,…,-1,0,1,…,τ}是一个预先定义的以0为对称中心、奇数个语言术语的语言术语集,其中τ为正整数,sα表示一个语言变量的可能值,且对于∀si,sj∈S,当且仅当i>j时有si>sj。
定义2[23]设S为一个语言术语集(见定义1),定义语言标度函数g:[s-τ,sτ]→[0,1],sα→δ,这里
定义3[2]设S为一个语言术语集(见定义1),称
L={(sα,p(sα))|α=-τ,…,-1,0,1,…,τ}
定义4[2]分布语言的比较算子和负算子定义如下:
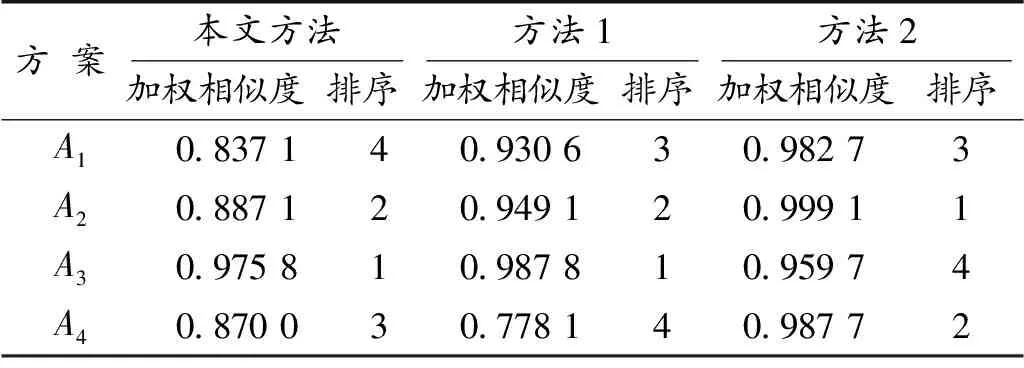
(1) 比较算子:设L1与L2是在S={sα|α=-τ,…,-1,0,1,…,τ}上的两个分布语言,若E(L1) (2) 负算子: 定义5[9]如果一个矩阵P=(pij,lij)n×n的元素由两部分组成,其中第一分量pij∈[0,1]表示方案xi与xj相比的模糊偏好程度值,第二分量lij∈SSL={sα|α=-υ,…,-1,0,1,…υ}表示与第一分量相关联的决策者的自信水平,称P=(pij,lij)n×n为自信偏好关系,其中对于∀i,j∈N={1,2,…,n},均满足pij+pji=1,pii=0.5,lij=lji。 定义6[9]对于自信偏好关系中的两个元素(pi,li)与(pj,lj),其中pi,pj分别是模糊偏好值,li,lj分别是其相对应的自信水平,li,lj∈SSL,λ∈[0,1],则有下列运算法则: (1) (pi,li)+(pj,lj)=(pi+pj,min{li,lj}); (2) (pi,li)-(pj,lj)=(pi-pj,min{li,lj}); (3) (pi,li)λ=(piλ,li); (4)λ(pi,li)=(λpi,li); (5) (pi,li)-λ=(pi-λ,li)。 定义7[24]设两个向量分别为A=(a1,a2,…,an)和B=(b1,b2,…,bn),且向量的分量均为正实数,则向量A和B的Dice相似测度定义为 j=1,2,…,n Bell[16]于1985年提出失望理论,指出主体的实际效用应是主观效用和失望-欣喜值的综合。随后,Loomes和Sugden、Delquie和Cillo分别提出了有先验预期和没有先验预期的失望模型[15]。Loomes、Sugden通过实验验证决策者在实际决策中除了对最终的结果有所预期外,会把实际的决策结果与期望值进行比较,当实际决策结果没有达到期望值时,决策者会感到失望;反之,则会感到欣喜[18]。对于实际结果和预期结果之间的相同差异,失望通常比欣喜的程度更大,这种现象被称为失望厌恶[25]。 u(xi)=v(xi)-D(v(xi)-ε[v(X)]) 由于先验期望较难确定,则当不考虑先验期望时,Delquie和Cillo指出主体的失望感与其他可能的所有结果都相关[15,18]。与其他更好的结果相比,任何结果都可能引发失望情绪;与其他更糟糕的结果相比,任何结果都可能导致欣喜感。将结果按照主观效用值大小进行降序排列,得到x1≥x2≥…≥xm,则修正后的主体感知效用定义如下: (1) 其中,v(xi)是决策者从结果xi得到的主观效用值,D(·)是一个单调不减的失望函数,且满足D(0)=0;E(·)是单调不减的欣喜函数,且满足E(0)=0。 需要解决的主要问题是:针对带有自信水平的分布语言评价信息,考虑决策者的失望心理,设计一种行为多属性群决策方法,最终对备选方案进行排序择优。这类问题的难点包括:如何将失望情绪融入到决策过程中;如何测度带自信水平的主体感知效用的相似性;如何构建合适的优化模型求解分布语言自信评价信息下的属性权重。 考虑决策过程中决策主体的失望情绪,研究带有自信水平的分布语言多属性群决策问题,本文的基本思路:首先利用失望理论,将具有自信水平的分布语言评价信息转化为具有自信水平的效用信息,然后定义自信效用向量的Dice相似测度,再构建确定属性权重的优化模型,最后设计一种类TOPSIS的行为群决策方法,对备选方案排序择优。 (2) (3) (4) 由文献[18]可知,失望函数D(·)为 D(x)=1-δx,x≥0 (5) 其中,δ为失望参数,满足0<δ<1,δ越大表明主体的失望感知越小。欣喜函数E(·)为 E(x)=φ(1-βx),x≥0 (6) 其中,β为欣喜参数,0<β<1,欣喜感知程度随β的增大而减小。φ是失望规避参数,0<φ<1,主体失望厌恶程度随φ的减小而增大。失望参数δ满足0.7≤δ≤0.9,欣喜参数满足0.7≤β≤0.9[15,18],将失望函数式(5)与欣喜函数式(6)代入式(4)中,可得专家ek在属性Cj下关于方案Ai的主体感知效用: (7) 进一步,基于定义10,可对两个带自信水平的效用值进行比较,具体运算法则如下: (1) 若SCUE1 (2) 若SCUE1=SCUE2,当ACUE1 考虑自信效用值与定义5中自信偏好值的涵义类似,本文借用自信偏好值的运算法则(见定义6)对自信效用值进行运算。 首先,构建一种新的Dice相似测度来测度自信效用向量的相似性程度。 定义11 设CUi=((ui1,li1),(ui2,li2),…,(uin,lin))(i=1,2)是两个n维自信效用向量,则CU1和CU2间的Dice相似测度为 (8) 特别地,当u1jg(l1j)=u2jg(l2j)=0,j=1,2,…,n时,定义DSM(CU1,CU2)=0。从而,定义11的Dice相似测度DSM满足以下性质: 性质1 (a) 0≤DSM(CU1,CU2)≤1;(b)DSM(CU1,CU2)=DSM(CU2,CU1);(c)当u1jg(l1j)=u2jg(l2j),(j=1,2,…,n)时,DSM(CU1,CU2)=1。 (b) 得证。 (c) 当u1jg(l1j)=u2jg(l2j),j=1,2,…,n时,(u1jg(l1j))2+(u2jg(l2j))2=2(u1jg(l1j))(u2jg(l2j)),则有 得证。 定义12 设CUi=((ui1,li1),(ui2,li2),…,(uin,lin)) (i=1,2)是两个n维的自信效用向量,w=(w1,w2,…,wn)是自信效用向量里元素对应的权重向量,则CU1和CU2间的加权Dice相似性测度为 WDSM(CU1,CU2)= (9) 特别地,当u1jg(l1j)=u2jg(l2j)=0,j=1,2,…,n时,定义WDSM(CU1,CU2)=0。 同理,定义12的加权Dice相似性测度满足以下性质: 性质2 (a) 0≤WDSM(CU1,CU2)≤1;(b)WDSM(CU1,CU2)=WDSM(CU2,CU1);(c)当u1jg(l1j)=u2jg(l2j),(j=1,2,…,n)时,WDSM(CU1,CU2)=1。 证 明类似于性质1的证明,在此从略。 (10) 在决策过程中,由于知识缺乏、时间压力等原因,属性权重往往未知或不完全确定,其对最终决策结果有着较大影响,因而受到较多关注。特别地,文献[27]指出属性的权重可通过利用属性的决策不兼容性程度来确定,决策不兼容性量化了备选方案在属性下的评估与综合评估之间的差异[27],则属性Cj的兼容性程度可通过对每个备选方案在属性Cj下的评估与综合评估之间的相似性来描述。受此思想的启发,同时考虑到本文决策问题的特点,以专家自信效用向量的Dice相似测度为基础,构建确定属性权重的优化模型,下面简述其具体的构建过程。 首先,通过所构建的新Dice测度设计一种衡量属性不兼容性程度的方法。为此,先定义备选方案的综合自信效用向量以及在属性Cj下的自信效用向量。 定义15 称DSM(Vj(G),V(G))= 这里属性Cj的兼容性程度由群体关于方案在属性Cj的自信效用向量与方案的综合自信效用向量的Dice相似度确定。其值越大,说明属性Cj的兼容性程度越大,即该属性能被其他属性替代的可能性越大,重要性越低。 然后,据各个属性的不兼容性程度来确定其权重,基本思想:某属性的决策不兼容性程度越大,说明此属性越不容易被其他属性替代,占据的重要性越大,应赋予更大的权重。从而理想的属性权重为 然而,在实际情况中,由于每个专家的知识储备、经验等各不相同,对属性分配的权重有着不同的偏好,导致上述等式一般不成立,存在些许误差,因此引入一个偏差变量如下: 最后,利用属性决策不兼容性程度来反映属性的重要性程度,得到的偏差变量值ej越小,说明效果越好,得出的结果与实际越相符。基于偏差和最小准则,构建如下非线性优化模型来确定最优属性权重: (11) 其中,w=(w1,w2,…,wn)表示属性的权重向量,Ω是不完全属性权重信息集。对于此优化模型式(11),可以利用LINGO软件进行求解。 针对分布语言自信评价信息下的多属性群决策问题,考虑主体的失望情绪,本文提出了一种新的行为多属性群决策方法。具体决策步骤如下: 输出:属性权重向量w=(w1,w2,…,wn);每个方案与正理想解的加权Dice相似度WDSM(Ui,U(+)),i∈M;备选方案的排序Oc。 步骤4 构建属性权重优化模型式(11),并求解模型得属性权重w=(w1,w2,…,wn)。 步骤5 借鉴TOPSIS思想[28],确定以自信效用向量表征的正理想解: (12) 步骤6 据式(9)计算方案Ai与正理想解的加权Dice相似性测度,即 WDSM(Ui,U(+))= (13) 步骤7 据相似度WDSM(Ui,U(+))值的大小对方案排序择优,获得备选方案的排序Oc,即WDSM(Ui,U(+))的值越大,说明方案Ai越接近正理想解,则方案Ai越优。 表1 政府部门e1给出的分布语言自信决策矩阵Q(1)Table 1 Distributed linguistic decision matrix with self-confidence (Q(1)) given by government department e1 表3 政府部门e3给出的分布语言自信决策矩阵Q(3)Table 3 Distributed linguistic decision matrix with self-confidence (Q(3)) given by government department e3 表4 政府部门e4给出的分布语言自信决策矩阵Q(4)Table 4 Distributed linguistic decision matrix with self-confidence (Q(4)) given by government department e4 输入专家主体分布语言自信偏好决策矩阵Q(1),Q(2),Q(3),Q(4),不完全属性权重信息集Ω,专家初始权重λ=(0.25,0.25,0.25,0.25),风险厌恶系数μ=0.88,失望规避参数φ=0.5,失望参数δ=0.8和欣喜参数β=0.8[15,18]。 CUM(1)= CUM(2)= CUM(3)= CUM(4)= 步骤3据式(10)得群体自信效用矩阵为 CUM(G)= 步骤4构建属性权重优化模型式(11),解得属性权重w=(0.196 0,0.357 1,0.278 0,0.168 9),偏差变量e=8.969 4×10-16。 步骤5据定义10得群体自信得分矩阵为 进一步,据式(12)得以自信效用向量表征的正理想解: 步骤6据式(13)得每个方案与正理想解的加权Dice相似性测度为WDSM(U1,U+)=0.837 1,WDSM(U2,U+)=0.887 1,WDSM(U3,U+)=0.975 8,WDSM(U4,U+)=0.870 0。 步骤7由WDSM(U3,U+)>WDSM(U4,U+)>WDSM(U2,U+)>WDSM(U1,U+),则A3≻A2≻A4≻A1,说明生态工业园区A3的发展最好。 为了说明本文提出的行为多属性群决策方法的有效性和优势,将本文方法与以下两种MAGDM方法进行比较,它们分别为分布语言自信评价信息下考虑主体后悔情绪的MAGDM方法(记为方法1);分布语言评价信息下考虑主体失望情绪的MAGDM方法(记为方法2)。下面简要叙述这些MAGDM方法的决策步骤,并给出具体的比较分析过程。 方法1的决策步骤简要描述:首先,基于给出的分布语言自信评价信息,利用后悔理论将分布语言转化为效用值,进而得到主体自信效用矩阵,接下来决策过程与本文提出的步骤3—步骤7一致。 进而,可得修正后的主体感知效用为 uij=v(dij)+R(v(dij)-v(dj+)),i∈M,j∈N 于是类似可获得考虑主体后悔情绪的新的主体自信效用矩阵。 最后,类似可建立非线性优化模型式(11),获得新的属性权重为w=(0.200 5,0.369 4,0.280 8,0.149 3),再执行类似于本文决策方法的步骤5—步骤7,获得最终的方案排序。 方法2的决策步骤简要描述:首先,按照本文步骤1—步骤2进行处理,利用加权平均算子集结得到群体的效用矩阵,接下来过程除了将自信效用向量的Dice相似测度换成经典的Dice相似测度(见定义7)外,其余与本文提出的决策步骤一致。 将方法2应用到本文算例,得到群体的效用矩阵为 最后,类似于本文提出的属性权重确定思想建立优化模型式(11),求得属性权重为w=(0.268 6,0.493 6,0.157 1,0.080 7),再执行类似于本文决策方法的步骤5—步骤7对方案排序择优。 上述3种群决策方法的排序择优对比结果如表5所示。 表5 3种群决策方法的结果对比Table 5 Comparison of the results of three group decision-making methods 由表5可看出:考虑主体失望情绪与后悔情绪的两种心理行为得出的方案排序并不完全相同,但最优方案都是A3。两者都是利用优化模型式(11)获取属性权重,且得到的属性权重差异较小,采用的决策方法也是相同的,唯一的区别就是效用值的转化方法,一个是利用失望理论,另一个是利用后悔理论,最终的排序结果不完全相同,说明了不同的心理行为会对决策结果产生不同的影响,失望与后悔是两种不同的心理行为,但两者的最优结果是一致的,说明了本文提出的群决策方法在表征决策主体行为方面的有效性。 表5还可以看出:本文方法与方法2的排序结果存在较大差异,本文方法里的最优方案在方法2中是最差方案,导致这种差异的原因是由于方法2中没有考虑决策者的多重自信行为。在实际决策中,由于专家的知识、背景、经验等各不相同,对评价的属性等情况掌握程度各不相同,从而导致专家对自身给出评价信息的自信水平不同,这也反映了决策者给出的评价信息的可靠性。考虑决策者的多重自信水平更加符合实际。另一方面看,对于没有自信水平的评价信息可以看成是决策者对自身有着最高自信水平时给出的评价信息。这样会导致本文方法里的信息可靠性比方法2里的低,两者的评价信息会有较大差异,最终导致决策结果不同。这说明在决策过程中考虑专家的多重自信水平是非常重要的,分布语言评价信息可以看成是分布语言自信评价信息的一种特例。 针对分布语言自信评价信息下的多属性群决策问题,提出了一种考虑主体失望情绪的行为多属性群决策方法。与已有群决策方法相比,本文提出的方法有以下特点:考虑了决策主体在决策时可能存在的失望心理行为,并将其融入语言群决策过程,更加反映实际决策情境;提出了决策者带有多重自信水平时的属性权重确定新方法。下一步的研究方向是将该决策问题扩展至异质语言自信评价信息下的多属性群决策问题,并探讨在社会网络环境下,专家权重的确定以及主体或子群体失望情绪对社会网络群决策的影响。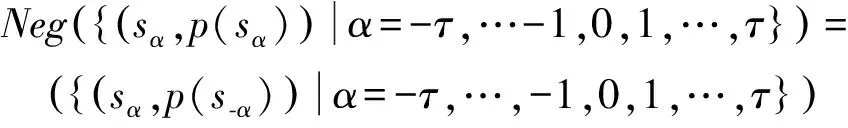

2.2 失望理论

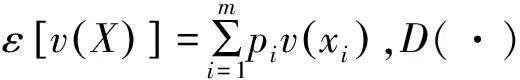
3 问题描述




4 主要模型与方法
4.1 基于分布语言自信评价信息的主体感知效用
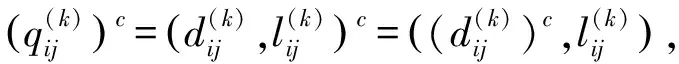

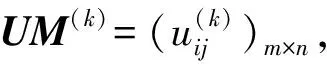




4.2 集成新Dice相似测度和属性不兼容性程度的属性权重优化模型




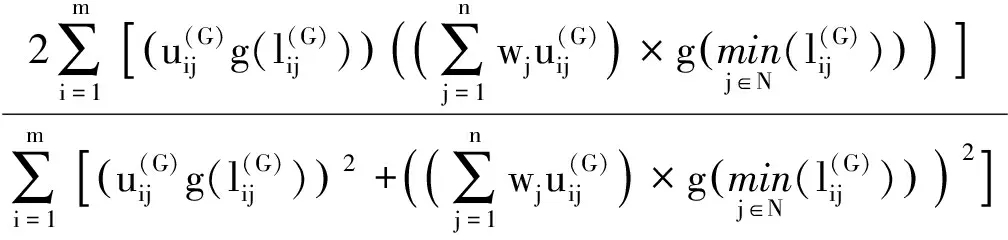

4.3 群决策方法




5 算例分析




5.1 决策过程及结果

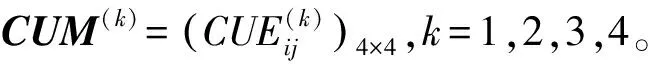
5.2 结果分析与比较



6 结 论
