基于粒子群算法的压气机热力学模型研究
2023-07-03单纯正张吉山唐少华
单纯正 郭 晶 宋 帅 张吉山 唐少华
(1. 海军装备部驻上海地区第四军事代表室 上海 201108;2. 中国船舶集团有限公司第七一一研究所 上海 201108)
0 引 言
压气机是涡轮增压发动机的重要部件,其特性曲线的主要参数是流量和效率。特性曲线的精度会很明显地体现在增压发动机的稳态、瞬态仿真过程中,同时还会直接影响发动机与增压器匹配计算的精准度[1-2]。在增压发动机数值仿真研究中,精准建立压气机特性模型尤为重要。在发动机动态仿真中,采用实验图谱构建各种基于插值法的模型是常用方法[3]。但是,实验图谱不能覆盖柴油机动态运行中的整个区域,扩展性较差,且当发动机运行在负荷及流量较低或者负荷产生突增/突降时,有一定概率在计算过程中出现仿真数据不收敛的现象。基于热力学的压气机模型可以避免当发动机低负荷时出现的数据不收敛问题,而且计算速度快,具有较高的应用价值[4]。然而,模型所需的压气机参数不易获取或者获取的代价过高,阻碍了其在发动机仿真中的应用。因此,将实验数据与热力学模型结合,通过实验数据辨识热力学模型参数,可以利用两者的优点,得到更实用的模型。
压气机具有高度的非线性特征,采用经典的参数辨识方法(如最小二乘法、极大似然法等方法)往往效果一般。因此,智能算法(如神经网络、遗传算法、粒子群算法等)被广泛应用于系统建模中。其中,粒子群算法有收敛速度快以及原理相对简单这2 个主要优点,在建模方面有大量的研究及应用。一些学者利用粒子群算法对机床热误差建模,有效降低了在数控机床加工中热误差因素的干扰,提高了加工精度[5-7]。在水轮机调速系统研究应用中,还有一些学者利用基于粒子群的智能优化算法对前期建立好的水轮机调速系统模型进行识别和分辨,从而得到调速器的模型参数,在相同条件下,将仿真得到的数据与实测参数进行比较,结果反映该模型能够很好地模拟水轮机调速系统[8-9]。
就某种意义而言,压气机的结构参数对于模型而言仅代表热力学模型的某些参数,可以采用参数辨识方法获取。本文在压气机热力学模型基础上,基于实验图谱,使用粒子群算法,采用目标函数优化方式替代原有的参数辨识方式,对热力学模型所需模型参数进行优化建模,获取最优参数,从而建立压气机的热力学模型。通过本文的方法可以解决压气机热力学模型参数获取困难的问题,但辨识获取的参数不能代表压气机的实际参数,仅用于提高建模效率和模型的仿真精度。
1 离心式压气机热力学模型
涡轮增压器是由涡轮、转子和压气机这3 个主要部件组成,其中涡轮通过转子驱动压气机运转。目前压气机的主要种类是单级离心式,结构示意如图 1 所示。压气机的主要组成是进口流道、压气机叶轮、蜗壳和扩压器。

图1 离心式压气机截面图
压气机热力学模型的核心是根据转子上传递给叶轮的功,减去各种损失后计算得出压气机的出口空气流量、压力以及温度值。
新鲜空气被压气机叶轮压缩后,由压气机叶轮所得到的能量主要转换为增加空气的动能及增加空气的温度,消耗的功率主要转换为叶轮出口处空气的动能及空气的流动损耗,见式(1):
式中:Δhs为空气获得的总焓;Δhu为叶轮出口的空气比焓;Δhli为叶轮出口前的流动损失比焓。
叶轮出口处的空气比焓见式(2):
式中:U2为叶轮出口处的切向速度,m/s;σ为滑失系数,按照后弯叶片估算。
叶轮出口前的流动损失比焓包括冲角损失、摩擦损失、回流损失和蜗壳损失等;进口流道摩擦损失较小,可以忽略;叶轮进口处的空气参数可视为环境空气参数。蜗壳损失和回流损失的具体数据目前尚无可进行精准计算的公式,在实际应用中,一般将其视作关于流量平方的相关函数。各种损失的具体计算方法可参考文献[4]。
2 基于粒子群算法的多参数辨识
粒子群算法是模拟生物在自然界进化过程中形成的自适应全局优化群智能算法,能够具备全局寻优能力,同时还能够在一定程度上增加运行时的精度和收敛速度。
本文基于改进的粒子群算法进行模型参数辨识,其算法思想是给更新粒子位置增加1 个扰动,使粒子在寻优时,降低其陷入局部收敛的可能性。为了提高收敛速度,通过改变各阶段粒子速度来提高算法整体运行速度。本文用优化问题代替了原有的参数辨识问题,利用粒子群算法可以优化计算设定的目标函数,从而得到参数辨识的结果。
2.1 基于粒子群算法的多参数辨识原理
粒子群算法的基本原理如下:假设有n个已赋予初始值的粒子在d维解空间内搜索最优解,将全部粒子记为1 个种群X=(X1,X2, ...,Xn);第i个粒子在d维的解空间内记为1 个d维的向量Xi=(xi1,xi2, ...,xin),i=1, 2,…,n;第i个粒子飞行的速度记为Vi=(νi1,νi2, ...,νin)。第i个粒子随着迭代次数不断更新自身位置,目前搜索到的最佳位置可记为Pi=(pi1,pi2, ...,pid),整个种群目前搜索到的最佳位置可记为Pg=(pg1,pg2, ...,pgd)。
粒子群算法的核心是速度公式和位置更新公式,见式(3)和式(4):
式中:c1为个体学习因子(或称个体加速常数);c2为社会学习因子(或称社会加速常数);r1、r2为取值在[0, 1]之间的随机数;t为迭代次数;w为惯性因子,表示粒子的惯性。
学习因子的存在,体现了粒子间互相学习交流的能力。学习因子应具有合适的取值:当学习因子过小时,粒子偏离目标值较小;而学习因子过大时,粒子可能会因移动过快而跳出目标区域。
研究发现,当w<0.8 时,粒子群算法与局部搜索算法类似,局部搜索效果显著,可以使寻优过程迅速收敛,得到全局最优解;当w>1.2 时,粒子群算法与全局搜索算法类似,全局搜索能力强,且能够使寻优过程处于更广阔的搜索区域,但收敛速度减慢且不能找到全局最优解的可能性变大;当0.8<w <1.2 时,粒子群具有最佳的寻优性能,与前2 种情况相比,更易搜索到全局最优解且收敛速度适中。
将粒子群算法用于参数辨识,需将算法的适应度函数设置为实验数据与模型计算数据间总误差最小;算法中每个粒子表示要辨识的参数,如果有多个参数,则采用多维数据表示1 个粒子。算法的最优解就是所辨识的参数。
2.2 适应度函数
优化的目标是在满足压气机实验图谱工况压比和转速的基础上,使经压气机热力学模型计算所得的质量流量、压气机效率与实验图谱上的真实值差值最小。将优化所得的压气机参数代入热力学模型即可得到最优计算结果,并扩展压气机工况范围。
在遵循一定的基本原则下,为使优化方案更贴近实际,建立以仿真质量流量、压气机效率与实验真值差值平方和最小的目标函数模型,见式(5):
式中:ss为优化目标函数值;y'm,i为第i个工况质量流量的模型计算值;ym,i为第i个工况实验质量流量的真值;y'η,i为第i个工况压气机效率的模型计算值;yη,i为第i个工况实验压气机效率的真值;n为工况点数量(本文中为54 个工况)。
y'm,i和y'η,i的值是通过压气机热力学模型计算所得,模型的优化变量如下页表1 所示。压气机热力学模型在Matlab/Simulink 软件中建立。在优化过程中,每代入1 组压比、转速工况,可通过模型获取相应的压气机效率和质量流量,并以此计算目标函数。把全部工况代入计算后,便可得到整体误差,然后根据粒子群算法调整优化参数。
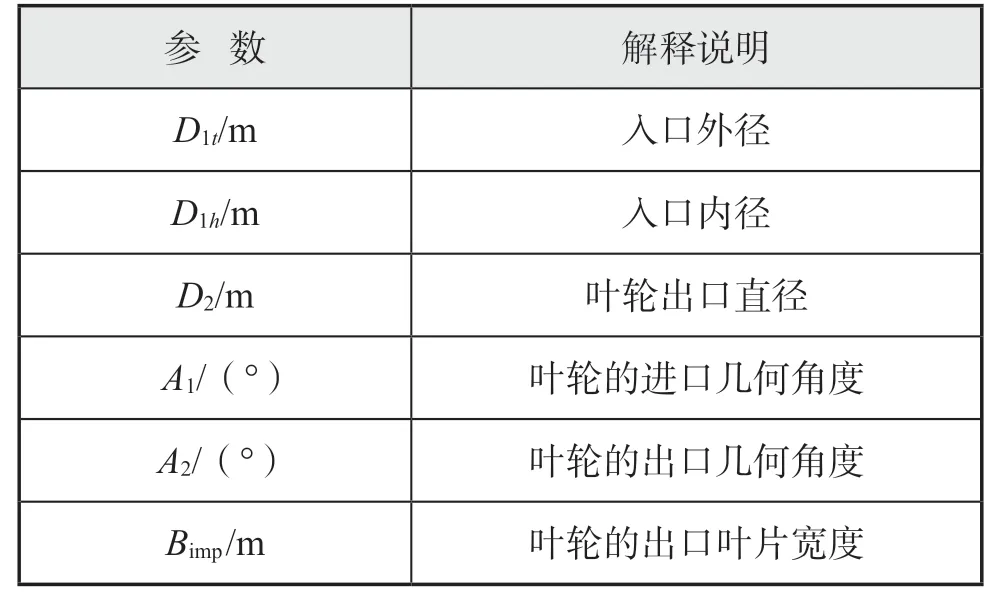
表1 优化变量说明
2.3 约束条件
约束条件是优化过程中优化变量必须满足的限制条件,一般是根据实际问题的要求提出。本文在优化过程中涉及6 个参数约束,根据压气机的实际情况给出约束条件,见式(6):
2.4 工况分析
在实验图谱上选取54 个工况点。由于实验图谱中有8 个不同的转速线,为了使优化参数合理,并使仿真结果更接近实验曲线,在等转速曲线的有限工况下选取合理的5 ~ 8 个不同工况点(尽量不要在小部分曲线上密集,以免影响优化结果)。
本文针对实验图谱工况,确定压气机54 个合理的工况点,同步对应该工况下的流量、效率、压比与转速,流量所对应工况如图2 所示。
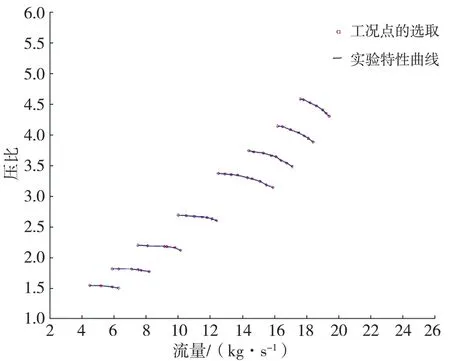
图2 工况选取
2.5 记录未辨识的输出特性曲线
为了验证优化方法的有效性,需同时记录采用初始模型参数而未经优化的热力学模型所仿真的压气机特性数据。在给定转速下,通过调节纵坐标压比,得到横坐标质量流量随压比的变化数据,记录初始模型参数的压气机热力学模型仿真结果。不同转速下的实验与仿真值对比结果如图3 所示。
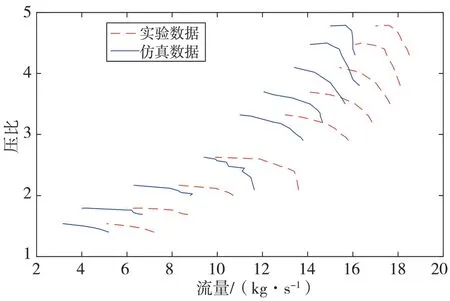
图3 初始模型参数仿真结果对比图
由图3 可见,在未经辨识热力学模型参数情况下,等转速、压比所对应的质量流量值相差较大,而且随着转速的增大,质量流量值相差也越来越大,初始模型参数仿真曲线整体相较实验曲线离坐标轴更远。
2.6 辨识流程
下页图4 为优化后的辨识流程:首先,进行参数初始化,确定粒子群中的相关参数;然后,对应确定热力学模型将要优化的尺寸参数入口,使用sim 函数调用SIMULINK 仿真模型,对结果数据分析并判断是否满足终止条件;若不满足,则经过粒子群算法继续优化参数,再将优化后的参数导至模型入口,直到满足终止条件; 最后,记录数据并输出优化结果。

图4 优化后的辨识流程
3 辨识模型计算结果与分析
本文针对实验室内的MAN B & W 6S35ME-B型低速柴油机所使用的MAN TCR 22 型涡轮增压器,进行模型参数辨识。柴油机的主要参数见表2。
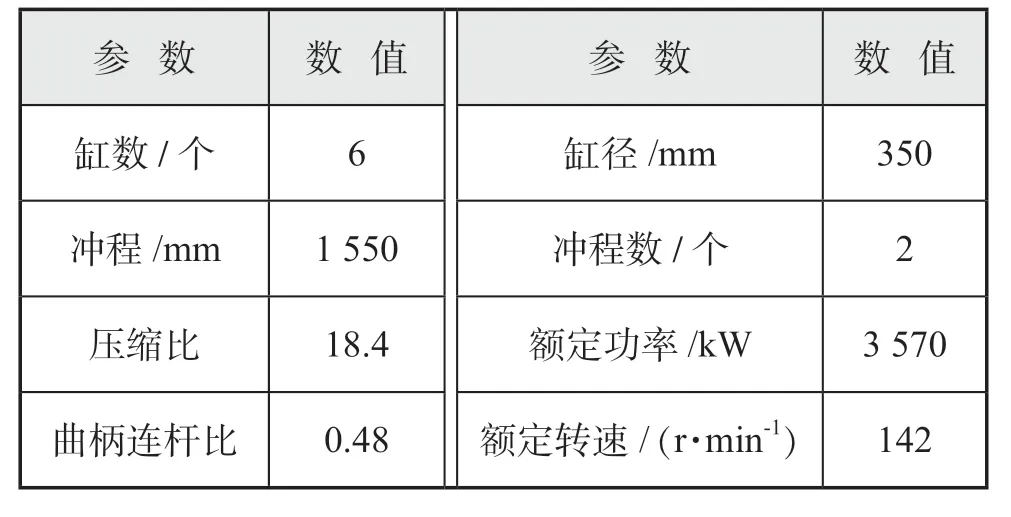
表2 柴油机主要参数
3.1 压气机模型参数
使用粒子群算法及压气机图谱对热力学模型进行了优化,得到压气机的优化参数如表3 所示。
废水流入絮凝池A,加入絮凝剂使沉淀絮凝,沉淀物聚集成大颗粒即可。然后废水流入斜管沉降池A,沉淀物沉入沉降池的底部。用污泥泵将沉淀物抽入板框式压滤机,压滤后得到含镍滤渣。滤液又回到废水调节池。

表3 辨识参数对比
将辨识结果代入热力学模型,利用模型进行计算,可以得到仿真的压气机流量特性曲线,仿真模型的计算结果与实验特性曲线对比如图5 所示。

图5 仿真模型的计算结果与特性线对比图
图5 中压气机的每个转速均用1 条对应的曲线表示。仿真转速与图谱的数据变化范围为15 000 ~31 500 r/min,压比变化范围为1.4 ~ 4.6,压比每次变化均以0.1 的步距增加。由该图可见,数据仿真结果与试验结果基本一致。因此,通过粒子群算法的辨识参数达到了此次优化目的,由此也验证了本方法的有效性。
在试验图谱区域内,仿真结果变化连续且与试验值吻合良好。由于压气机真实工作中流动情况过于复杂,热力学模型无法完全模拟出流动的真实情况。通过辨识参数调节了整体误差,在高压比、低转速的情况下,仿真模型可以稳定、平滑地计算,验证了基于粒子群算法建模的有效性。在压气机小流量工况下,虽超出试验图谱的范围,但由于热力学模型的连续性,所以仍能计算出仿真结果,在柴油机仿真模型中起到较好的作用。
3.2 柴油机整机计算结果
在Matlab/Simulink 软件中,采用平均值模型搭建了该型机的仿真模型,分别采用优化后的热力学模型和基于实验图谱的插值模型构建压气机模型。螺旋桨作为柴油机模型的负载源,在进行仿真时按照特定的推进特性进行运转,仿真模型的初始状态负荷与转速均为0。
在模型初始运行时,柴油机的转速值设定在124.9 r/min;在柴油机仿真进行到600 s 时,柴油机转速设定在142 r/min。柴油机模型动态仿真结果如图6 所示。

图6 柴油机模型动态仿真结果
由图6 可得:在2 种压气机模型的计算中,柴油机转速变化基本相同,在动态过程中数据差异较大的主要是柴油机排气、扫气压力值以及增压器转速值。在柴油机转速加速到124.9 r/min 的过程中,基于压气机热力学模型的仿真中,增压器转速、扫气压力和排气压力的变化过程逐步增加,未发生突变;而基于试验数据插值法模型的变化过程相对特殊。其原因是热力学模型能够有效扩展工作范围,具有更好的工况适应性。
仿真结果表明,在2 种模型中,热力学模型的变化规律更接近实际情况。优化后的热力学模型更加符合客观物理规律并具有更高精度,在柴油机低转速、低负荷情况下能保证正确性。
4 结 论
本文基于实验图谱,使用粒子群算法研究并建立具有相对最优参数的压力气热力学模型,得到如下结论:
(1)采用改进的粒子群算法,基于压气机特性图谱,可以对涡轮增压器中压气机的热力学模型进行参数优化,获取最优参数且提高热力学模型的计算精度;
(2)采用粒子群算法优化建模方法可以省略获取压气机模型参数的测量与实验过程,降低建模难度;
(3)利用优化后的热力学模型能够进一步改善柴油机模型在低负荷以及低转速工况下的性能。
