海量数据存储中云服务器性能加速方法仿真
2023-07-03危华明廖剑平
危华明,廖剑平
(1. 南宁学院信息工程学院,广西 南宁 530200;2. 南宁师范大学计算机与信息工程学院,广西 南宁 530299)
1 引言
海量数据云存储引领着信息时代的延伸,根据网络技术的整合效果,将海量数据以云存储方式存储,并依据用户的需求完成对海量数据的访问[1,2]。由于数据的种类复杂繁多,数据量较大,所以在日常存储系统中,会影响了数据的存储效率及存储完整度,从而降低数据存储的误差率。为了能够有效的实现海量数据的存储及调度,需要针对这一问题对考虑海量数据存储的云服务器性能加速方法实施详细研究。
针对此问题,魏正等人[3]提出基于近端策略优化的阻变存储硬件加速器自动量化方法,由于现如今的数据存储开销及计算复杂性不断提升,为提升存储数据加速效果,该方法避免出现动作空间转换,基于近端策略优化算法在系统中使用离散动作空间,令数据实现自动学习,通过对系统精度计算的改动,达到数据信息搜索时间短、存储速度快的目的,该方法的改动效果不佳,存在吞吐量低的问题。孙孝辉等人[4]提出基于ARM+FPGA平台的二值神经网络加速方法研究,该方法利用应用的存储平台二值化处理数据,通过设计的二值神经网络减少数据存储需求量,减轻数据存储复杂度,再将卷积转换成逻辑运算,达到提升系统运算效率,降低资源消耗的目的,最终依据二值神经网络数据存储特点,实施了处理改进算法,令数据存储后的网络吞吐量有所提高,该方法的研究效果差,存在加速存储耗时高的问题。陆冉阳等人[5]提出一种用于自适应直方图均衡化的硬件加速器方法,该方法基于直方图均衡化算法设计了一款硬件加速器,利用硬件加速器实现了云服务器的自适应限制对比度拉伸,并采用FPGA设计出并行体系架构,以此有利于对存储资源的加速存储,最终基于规则的模块化设计方法设计硬件加速器,实现了数据存储加速,该方法设计的硬件加速器有缺陷,存在CPU利用率低的问题。
云服务器具有高可靠、弹性扩展的计算资源服务,但随着云数据种类复杂度的增大以及数量的迅速增多,云服务器性能受到直接影响。为了解决现有方法中仍然存在的应用弊端,提出考虑海量数据存储的云存储器性能加速方法。
2 云存储数据小波分解及特征提取
2.1 小波包分解
由于海量数据存储过程中会对云服务器性能产生影响,所以根据小波分析理论,对获取的云服务器海量存储数据采用小波包分解[6],根据被分析信号的特征,自适应地选取最佳基函数,使之与信号相匹配,以提高信号的分析能力,从而有利于加快云服务器的存储性能。
基于小波分析,在海量存储数据中选取任意函数,即h(t)∈L1∩L2,H(0)=0,表达中h(t)表示任意函数,L表示存储函数,H表示傅里叶变换。根据该方程式生成出海量存储数据函数簇{ha,b(t)},定义如下
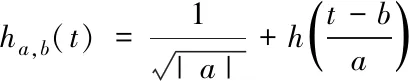
(1)
式中,a表示非零实数,b表示任意实数,t表示时间。那么函数簇经傅里叶变换后,得出

(2)
式中,H(ω)表示h(t)的傅里叶变换,f(t)表示存储数据信号,et表示小波变换,d表示常数。
方程(2)属于连续小波,而h(t)属于基小波。当h(t)表示基小波时,变换f(t)定义为

(3)
式中,wf(a,b)表示信号经连续小波变换后,而a属于尺度因子,b属于时间平移因子,h*表示复共轭。
在上述小波分析的基础上,设定数据全频率范围,将海量存储数据引入到该范围内,并实施频带宽正交分解。基于频带宽正交分解方法,将海量存储数据信号S0分解成高频信号及低频信号两种。那么正交小波包的分解表达式定义为

(4)
式中,u2n(t)表示小波包,其中n属于尺度函数集合,k表示函数系数,hk表示小波包基,gk表示信号时频特性。
由于海量存储数据信号中包含尺度函数及小波母函数,它们在整个集合中具有关联性。所以小波包可以构成不同的小波包基,而信号熵值越小,就属于最优小波包基,可以有效反应出海量存储数据信号的时频特性,有利于消除小波包数据中的噪声[7,8]。
那么基于小波包分解的海量数据存储流程,就如下所示:
1)在海量存储数据中选取几组数据对其开展小波包分解,从中获取数据信号从低频到高频的频率;
2)计算出最优小波包基,从而构建小波最优树;
3)分解各个小波包系数,并采用软阈值方法对选取的系数阈值量化;
4)处理小波包分解系数后,重构小波包,以此消除数据中的高频噪声信号,实现海量数据存储的去噪处理。
2.2 特征提取
1)建立存储分布结构模型
构建海量存储数据模型,利用该模型提取数据关键特征,有利于提升云存储器对海量数据存储的存储性能。
建立海量数据存储属性特征高维重组数据模型为
X=[x(t0),x(t0+Δt),…,x(t0+(K-1)Δt)]

(5)
式中,x(t0)表示时间序列,J表示时间窗函数,m表示嵌入维数,Δt表示采样时间间隔,N表示嵌入组数,K表示分布数据,X表示模型集合。
2)提取海量数据存储关键信息特征
根据建立的模型,采用关联规则方法挖掘海量存储数据的关键信息特征,实现数据特征提取。
令海量数据关键信息熵分布满足S={s1,s2,…,sn}的条件,其中S表示为关键信息请求信号,从中计算出海量数据存储关键信息的自相关函数,计算结果如下所示

(6)

基于计算结果,采用关联规则挖掘海量数据存储关键信息特征[9,10],表示为

(7)

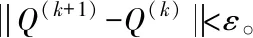
3 云服务器性能加速
3.1 卷积神经网络
卷积神经网络CNN的前向传播主要用来识别及分类物体[11,12],向卷积层中输入q个输入特征,将其转换成p个输出特征,其转换关系表示q×p,主要由q×p个卷积核确定而成,也就是神经网络神经元之间的连接权重。当有单一的输出神经元与输入特征卷积窗口相互连接时,卷积层次之中的特征图尺寸就为K×K。当输入q个特征时,就可以利用窗口对相应的卷积核采取卷积运算,但这时不同的输入特征就要对应不同的卷积核。那么整个过程表述为

(8)
式中,l定义层数,Kernel定义卷积核,Mj定义输入特征,Bl表示层次内存有偏移,f(·)表示激活函数。
3.2 CNN加速存储模型构建
通过对上述卷积神经网络CNN的描述,设计了基于FGPA的CNN云服务器加速存储模型[13,14],如图1所示。
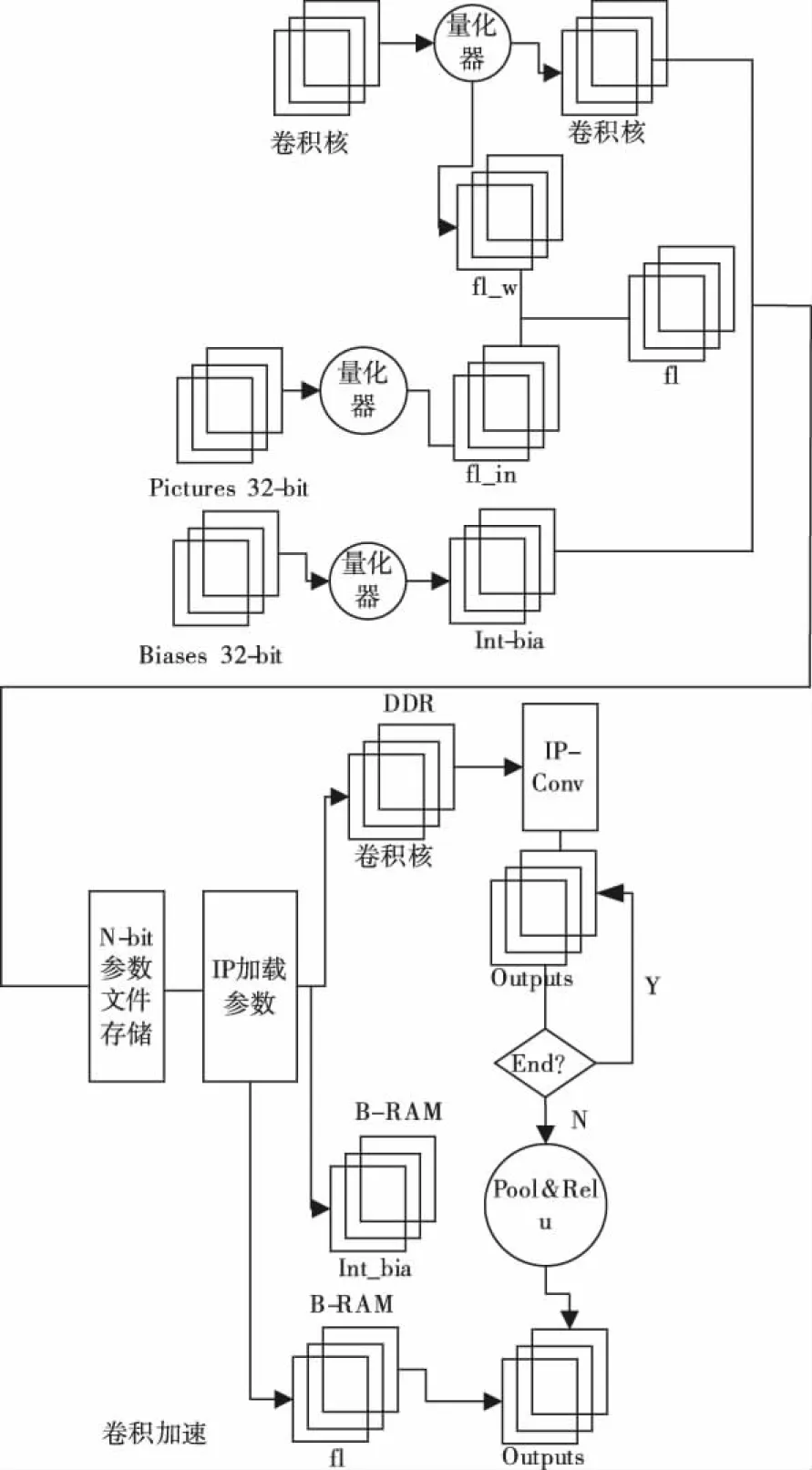
图1 CNN加速存储模型
根据图1设计的CNN云服务器存储加速模型,将其划分成不同的模块,其各个模块的功能分别为:
1)参数量化模块
依据设置的CNN存储加速模型,将海量数据参数存储到文件中,利用卷积计算时,可以直接使用存储后的数据参数文件。在参数量化模块中,利用卷积核量化量化器,从中计算出海量存储数据的n-bit权值参数及各个层次中的参数尺度,即fl-w;再确定出需要输入的量化尺度fl-in;最后对存储数据偏置量化,从中取得数据存储后的偏置。通过以上确定的fl-w及fl-in计算出各个卷积网络层次的海量数据存储尺度,用方程定义如下
fll+1=fl_wl+fl_inl-fl_inl+1
(9)
式中,l表示第l层卷积,fll+1表示数据整体尺度。
2)卷积存储加速模块
由于云服务器内部存储资源有限,所以根据提取的海量数据关键信息特征,将特征输入到卷积存储加速模块中,对其卷积加速计算。
卷积计算前[15],应先对提取的海量数据关键信息特征矩阵实施拆分,从中获取机组加载数据,再次拆分矩阵,形成小矩阵,加载缓存至云服务器FPGA,在提升云服务器加速性能的同时还提升了云服务器的存储效果。
设置模型中各个层次的特征均为16×16的小矩阵,并分批对小矩阵内的3×3卷积核计算,并合并计算结果。合并后形成一个大矩阵,将其用作卷积层的下一层输入特征参数,反复循环计算,最终取得最后一层的计算结果,把最后一层计算结果返回到云服务器中存储。通过以上步骤实现云服务器存储性能的加速。
4 实验与分析
为了验证考虑海量数据存储的云服务器性能加速方法的整体有效性,需要对该方法开展实验对比测试。采用考虑海量数据存储的云服务器性能加速方法、基于近端策略优化的服务器优化方法和基于ARM+FPGA的服务器优化方法完成实验测试。
4.1 不同方法的云服务器的吞吐量对比
本次实验选取通过一台服务器用作测试环境,该服务器配置为intel corei5 4670 3.4GH z四核CPU,千兆网卡。在海量数据中随机选取不同长度的数据,为测试海量数据存储的云服务器性能加速效果,采用提出方法、基于近端策略优化的服务器优化方法和基于ARM+FPGA的服务器优化方法对海量数据加速存储的云服务器吞吐量采取实验对比测试,具体测试结果如图2所示。

图2 云服务器的吞吐量对比测试
分析图2中的数据发现,设置测试时间为25min,吞吐量会随着时间的增长而不断下降。从整体上看,基于近端策略优化的服务器优化方法和基于ARM+FPGA的服务器优化方法的整体在80%-95%之间,下降速度要高于提出方法,且两种方法的吞吐量要低于提出方法。而提出方法在测试过程中吞吐量始终保持在95%-100%之间,下降速度也缓慢,由此可以判定提出方法的云服务器吞吐量最佳。
4.2 不同方法应用下CPU利用率对比
海量数据加速存储到云服务器时,会占据云服务器内部空间,为了测试海量数据加速存储的云服务器整体性能,需要利用提出方法、基于近端策略优化的服务器优化方法和基于ARM+FPGA的服务器优化方法分别对云服务器的CPU利用率测试,CPU利用率越高,说明云服务器的存储性能越好,反之则越差,具体测试结果如图3所示。

图3 云服务器CPU利用率对比
根据图3中的数据发现,随着存储数据的不断增加,三种方法的云服务器CPU利用率均呈现出上升趋势。经对比发现,提出方法与基于近端策略优化的服务器优化方法在整体测试中的CPU利用率均在80%~90%之间,但提出方法的CPU利用率要高于基于近端策略优化的服务器优化方法,可见提出方法的云服务器存储性能要优于当前文献方法的CPU利用率最低,也证明了提出方法的云存储区存储性能要高于基于ARM+FPGA的服务器优化方法。
4.3 服务器负载预测效果
利用提出方法、基于近端策略优化的服务器优化方法和基于ARM+FPGA的服务器优化方法分别记录1分钟内预测服务器剩余负载,并与标准服务器上的结果进行对比,结果如图4所示。

图4 云服务器负载预测对比
通过图4的实验结果可知,三种方法在1分钟内预测剩余负载均不相同。提出方法的云服务器负载预测与标准服务器的预测值几乎一致,而基于近端策略优化的服务器优化方法和基于ARM+FPGA的服务器优化方法则出现不同程度的偏差。由此可见提出方法的服务器负载预测效果更加符合实际结果。
5 结束语
海量数据繁杂的种类会影响云服务器的加速性能,针对这一问题,提出考虑海量数据存储的云服务器性能加速方法。基于小波包分解方法消除了海量存储数据中的噪声,再利用构建的卷积神经网络云服务器加速模型对获取的特征量训练,从而提升了海量数据存储的云服务器加速性能。该方法在海量数据存储的云服务器性能加速方法中发挥着重要作用,在今后云服务器性能优化研究中具有长远的发展前景。
