大数据平台下容器资源调度的优化算法研究*
2023-07-03刘翔李海荣
刘翔,李海荣
(1.内蒙古科技大学 信息工程学院,内蒙古 包头 014010;2.内蒙古科技大学 工程训练中心,内蒙古 包头 014010)
随着第3次以原子能、电子计算机、空间技术和生物工程的发明和应用为主要标志,涉及信息技术、新能源技术、新材料技术、生物技术、空间技术和海洋技术等诸多领域的一场信息控制技术革命浪潮的兴起,人类迎来了信息化时代[1].据IDC研究报告指出,在2021年全世界数据资料的存储大小已达到1.2 ZB,各行各业越来越趋向于数字化.
在过去十几年的数字化浪潮中,大数据技术[2]已经经历了几次更新升级.从专注存储的数据库,到面向统计分析的数据仓库,再到面向大数据分析应用场景的Hadoop/Spark为核心的大数据平台,都在不断地提升数据分析利用能力.当然,随着大数据平台的发展,一系列围绕着大数据平台而产生的问题也越来越多.如:应用OpenStack构建实验平台,其搭建和维护过程复杂[3];使用VMWare构建大数据实验平台,其价格昂贵[4];针对目前的Docker Swarm内置的调度策略无法很好地实现Docker集群的负载均衡,提出动态加权调度算法,其不能满足大数据实验平台下的资源调度.现可从2个方面来改进现有的大数据实验平台[5].
③Jack L.Walker,“The diffusion of innovations among the American States”,The American Political Science Review,1969,63(3),pp.880 ~899;Shipan,Charles R.,Craig Volden,“Policy diffusion:seven lessons for scholars and practitioners”,Public Administration Review,2012,72(6),pp.788 ~796.
一方面,针对大数据平台部署时不仅硬件设备昂贵,而且相关工具及系统体系庞大,部署过程复杂.在此提出一种基于Docker[6]容器虚拟化技术的一键式部署集群.
另一方面,针对Docker Swarm[7]原生3种调度算法Random, Spread, Binpack并不能满足大数据平台下的调度策略,在此提出了一种基于用户的动态更新集群节点信息的资源调度策略.
1 模型构建
1.1 问题描述
现有的Docker Swarm集群只考虑了CPU和内存2个维度,这样势必会造成资源利用的不合理.且它将每个容器的资源分配看作是独立的事件.但实际情况下,容器之间的关系并非如此.这样会造成同一集群间容器响应速度慢.针对以上问题,提出一种面向用户容器管理,从CPU、内存、磁盘I/O、网络I/O 4个维度考虑,在保证系统负载均衡[8]的前提下,最终使同一用户下的容器部署在同一个物理节点上.
式中:w为回归系数;b为常数项;ε为随机误差项.通过式(6)得到第i个节点的一元线性回归模型式(7):

表1 符号与说明
(1)
1.2 目标函数
为使大数据实验平台在负载均衡的情况下可以保证每个用户的集群环境保持高效快速的响应速度,需要全面考虑容器及物理节点4个维度的状态,实时监控整个大数据实验平台的负载率,最终使其保持在最小值.由上一节定义可知,第i个物理节点的负载率ALoadRate,i可以由4个维度的加权表示如式(2)所示,系统负载率ALoadArg如式(3)所示:
(2)
(3)
首先,通过动态更新集群节点信息算法得到预测模型的回归方程,再以式(2)为目标函数,通过RSFU算法找到使其最小值的物理节点i.
2 基于容器的动态更新集群节点信息算法
2.1 算法思想
通过4个维度来考虑1个服务的容器资源,分别是CPU、内存、磁盘I/O、网络I/O,每个节点通过Sigar[9]所提供的API接口实时获取系统信息,并通过式(2)得到每个节点的实时负载率.再通过Docker Engine API[9]获取每个节点上的容器数量.将容器数量作为自变量,负载率作为因变量进行记录.由单个节点负载率求得整个系统的负载率.
在系统负载率小于等于50%时,分为2种情况:第1种情况:所有节点负载率小于50%,此时在资源分配时直接选择负载率最低的节点.第2种情况:一部分节点负载率大于50%,一部分节点负载率小于50%,且负载率小于50%的节点更多.此时负载率大于50%的节点以记录的数据为样本值,采用一元线性回归分析[10,11]方法进行模拟,建立数学模型,求出回归参数,并得到一元线性函数.负载率小于50%的节点会在资源分配时被优先选择.
2)综合土地利用动态度,表示某一研究样区土地利用的整体动态[10],其值越大,说明区域土地利用变化越剧烈,反之变化越弱。图2为巢湖流域综合土地利用动态变化图。
在系统负载率大于50%时,也分为2种情况:第1种情况:一部分节点负载率大于50%,一部分节点负载率小于50%,且负载率大于50%的节点更多.此时会对超过负载率50%的节点进行一元线性回归建模,求出一元线性函数.对不超过负载率50%的节点在资源分配时会被优先选择.第2种情况:所有节点负载率大于50%,此时每个节点都已经完成了一元线性回归分析,并得到了一元线性回归函数.在进行资源调度的时候,基于回归方程将容器数量作为自变量输入,预测出所需负载率.筛选出满足条件的节点,在负载率不大于90%的情况下,选取负载率最小的节点.算法流程图如图1所示.
按照新课标要求,小学1-2年级语文每周安排8课时;3-4年级语文每周安排7课时;5-6年级语文每周安排6课时。但通过调研,我发现,农村学校对考试学科普遍重视,语文、数学、英语、科学等主要学科全部超课时。因为每周总课时固定,所以,非考试科目在一定程度上受到挤压。按照课标规定小学音乐每周都是2课时,实际开课1课时。
未来,相信“嘉电”会继续秉承以消费者为中心、洞察消费体验的宗旨,继续为广大消费者甄选出最优质的家电产品,同时,还能为家电企业的产品转型升级提供指引方向,并在规范行业发展的同时,不断推动整体家电行业向着高质量、高水平、高规格的方向前进!

图1 基于容器动态更新集群节点信息算法流程图
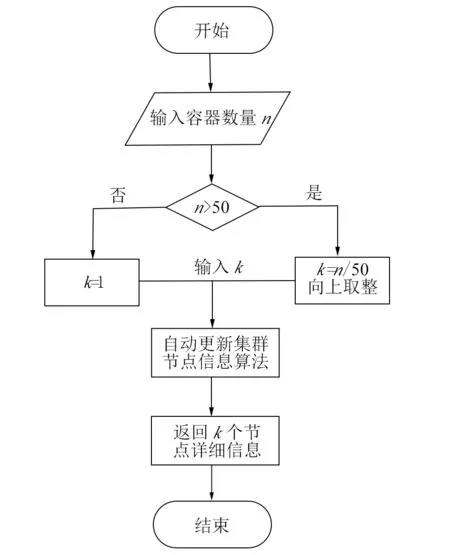
图2 基于用户的资源调度策略流程图
2.2 动态更新集群节点信息设计与实现
根据式(2)定义,当ALoadRate,i>50%的时候,返回1,反之当ALoadRate,i≤50%的时候,返回-1.得到字典函数f(ALoadRate,i),用式(4)描述为:
(4)
当f(ALoadRate,i)=-1时,此时节点会将容器数量和负载率一一映射并更新节点信息,为以后节点的模型建立提供样本集.得到映射函数fi,用式(5)描述为:
fi∶Num,i→ALoadRate,i.
(5)
当f(ALoadRate,i)=1时,此时就需要考虑每个节点是否还有充足的资源来分配给容器.采用一元线性回归模型的方法来进行节点资源的预测.此模型有实用性强,预测结果精确和使用方法简便的优点,可以很好地适应大数据平台的轻量级与时效性.具体操作如下:
Tss=Rss+Ess.
步骤2:建立模型.一元线性回归模型表示为式(6):
由于文言文在语言形式上的阻隔,如今的学生对古籍文献有一种天然的抵触心理。教师必须带着耐心和技巧来手把手教学生熟悉如何深度阅读这些具有重要学术价值而又不易理解的服饰文献,从而赋予学生的“学术性学习”以坚实的学术基础。为了营造课堂气氛,笔者在课堂上谈了明代《舌华录》记载的姚广孝和王宾的对话。姚广孝看到王宾住在西山里不出来就好奇地问:“寂寂空山,何堪久住”。王宾答复:“多情花鸟,不肯放人”。笔者向学生解释,文言文古籍资料就像这西山,刚开始接触时你会觉得“何堪久住”,但如果耐心专研,就会领悟其中的妙处,因其中的“多情花鸟”而不想离开。
y=wx+b+ε.
(6)
资源调度问题可以描述为:设大数据实验平台有n个节点,每个节点由一个五维的向量组成,则第i个节点可以表示为Li=(Pi,Mi,Oi,Ni,Num,i),引入权重Wi=(Wp,i,Wm,i,Wo,i,Wn,i,0),且权重之和等于1.上述各参数名称及其含义汇总如表1所示.第i个容器可以表示为Ci.假设第Uj个用户创建了m个容器,则最终的资源调度QRS可以表示为用户Uj将m个容器映射到Lk上,如式(1)所示:
yi=wxi+b+ε.
式(16)中:Ess为残差平方和.
(7)
(8)
(9)
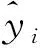
R2是回归平方和Rss与总平方和Tss的比值,用式(16)描述为:
(10)
(11)
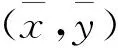
(12)
(13)
再让其等于0,即可求出w,b的值.如下式所示:
(14)
(15)
步骤4:模型评估.从2个维度来评估模型的好坏,分别是判定系数R2评估和相关系数r评估.
步骤3:确定回归参数.此时有2种方案可选,第1种是解析法,使用最小二乘法[12]估计.第2种是梯度下降[13]的方法进行估计.鉴于所设计的大数据平台样本量较小、样本属性单一,选择第1种解决方案,即使用最小二乘法估计回归参数.由步骤2可知,此模型的损失函数/代价函数SLoss用式(10)表示为:
R2=Rss/Tss=1-Ess/Tss.
王祥见老道所言非虚,一时间有些害怕,急忙问道:“要是真的如道长所言,该如何消弭此劫呢?”他也是看了不少古装剧,临时拼凑起的台词和老道士倒是很搭调。
(16)
2010年3月,肇庆市城建投资开发集团有限公司(以下简称“城投公司”)成立,城投公司是肇庆市国资委属下的全资国有企业,是根据市委、市政府对市属国有经济阶段性整合的工作部署,以市房地产开发总公司为主体,将市属房地产、建设、建筑等十多家国有企业的优质资产整合而成,是一家集城市建设、土地综合开发、市直保障性住房建设等职能为一体的国有投融资平台和建设载体。城投公司成立后,当年才48岁的邓强(正处级),顺利当上了集团董事长、党委书记,可谓是春风得意,前途无限。
(17)
(18)
(19)

(20)
r是R2的算术平方根,符号与自变量x的系数w一致.得到函数f(w),用式(22)描述为:
对于一些重点税源企业的纳税评估案件往往涉及几个管理片区甚至多个省、市,跨区域税务核查协作制度一直是征管工作的难题。纳税评估对于税源管理的作用日益凸显,在核查大型企业集团、重点联系企业以及建安房地产企业异地项目涉税问题上,跨区域协作问题变得更为突出。跨区域协作制度完善应包括涉税信息的交换,评估文书开具的主体,以及评估税款后续由谁来追缴等细节性问题,对跨区域协作起到规范化指导作用。
(21)
(22)
Policeman:Why didn't you shout for help when youwere robbed ofyourwatch?
步骤5:将预测模型所得到的回归方程与其所对应的节点绑定,并更新集群信息.
3 RSFU
3.1 资源调度思想
基于Docker的大数据平台的本质是给用户提供一个集环境、分析、结果于一体的实验平台.但每个用户所创建容器的数量是不确定的.平台本身并不能提前知道每个用户会创建几个容器.如何基于用户所要创建容器的多少来进行资源的调度呢?大数据平台常见的集群环境[14]包括Hadoop, Yarn, HBase, Hive, Storm, Spark等.一般地,小于20个节点的集群属于小规模集群,20到200个节点的集群属于中等规模集群,大于200个节点的属于大规模集群.针对这一规律,以50个节点作为基准.当1个用户所创建的容器不超过50时,尽可能保证所创建的容器在一个节点;当一个用户所创建的容器超过50时,按照每50为分割点,一个分割点分配一个节点.这样就可以基于用户来进行资源的调度,并应用动态更新集群节点算法来保证负载均衡,这样会较大程度地提高同一用户的集群内容器之间网络数据交换的效率.
其中J=3, γs为球坐标空间球面RT不稳定性线性增长率, 函数,θ,t)和φj(r,φ,θ,t)分别为j阶扰动界面和j阶流体扰动速度势函数. 速度势函数φ(r,φ,θ,t)满足Laplace方程(1)以及边界条件▽φ|r→+∞=0. 按照初始条件, s1,1,1=-1和s0,0,0=r0. 在Fourier谐波扰动幅值中的相合系数sj,n,m(j,n,m=1, 2, 3)和γs为关注的待求量.
3)数据融合:考虑到系统数据融合的需求,簇头担负节点信息收集与数据融合的任务,从而提高网络的检测精度。
3.2 资源调度设计与实现
用户通过Web界面输入创建容器数量,当用户输入n≥50时,返回1,当用户输入n<50时,返回[n/50].得到函数k(n),用公式(23)表示:
(23)
得到k,然后基于动态更新集群节点算法,根据得到的k值,来进行k次的节点分配.首先当有满足k个节点负载率不大于50%时,直接返回k个节点.当只有l(l∈[0,k])个节点负载率不大于50%时,余下的k-l个节点将通过每个节点绑定的一元线性回归方程确定.先确定容器数量50,输入回归方程得到将要增加的负载率.然后计算出预测后节点负载率是否超过90%,如果超过90%就舍弃,通过排序返回前k-l个节点信息.经过上述操作得到的结果就是最优的资源调度策略.
4 配置信息表
实验采用Cloudsim4.0仿真平台进行实验,相关配置和指定范围如表2、3所示:

表2 符号与说明

表3 指定范围表
且采用系统负载率作为评价指标,计算公式为公式(3).分别与Docker Swarm 3种调度算法进行实验测试,实验结果如表4所示:
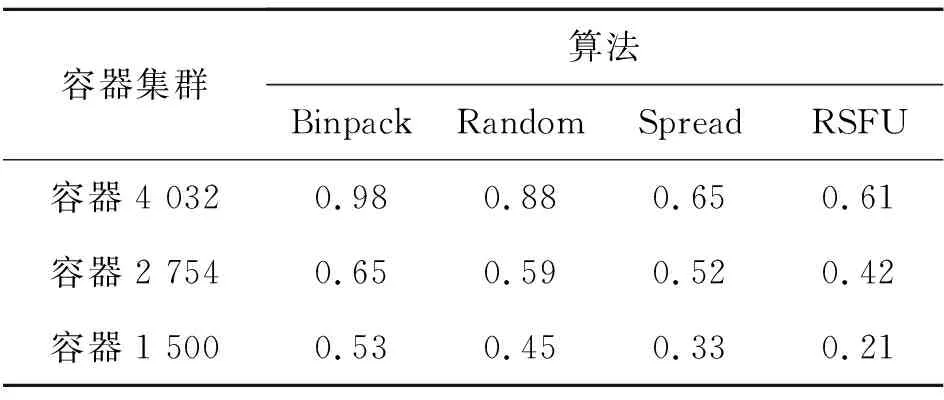
表4 各集群系统负载率
在容器集群规模4 032,2 754,1 500下,Binpack算法得到的系统负载率分别为0.98,0.65,0.53;Random算法得到的系统负载率分别为0.88,0.59,0.45;Spread算法得到的系统负载率分别为0.65,0.52,0.33;RSFU算法得到的系统负载率分别为0.61,0.42,0.21.对比实验数据可知,RSFU算法在不同的集群规模下,大数据平台容器资源调度性能皆优于Docker Swarm原生3种算法,且随着集群规模的变化,算法表现出较强的鲁棒性.
随机选取其中5个节点,RSFU算法部署下容器分布情况如表5所示:
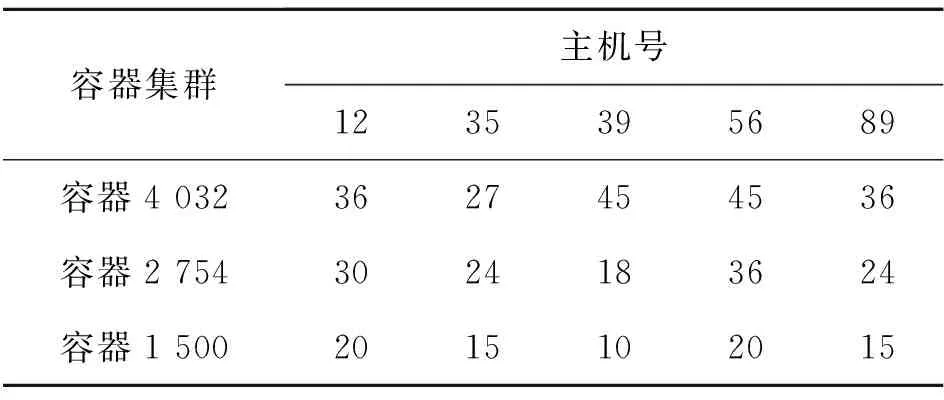
表5 RSFU算法下容器分布情况表
从上表可知,当容器为4 032个时,每个节点分布的容器数量都是9的倍数;当容器为2 754个时,每个节点分布的容器数量都是6的倍数;当容器为1 500个时,每个节点分布的容器数量都是3的倍数.不难看出,RSFU算法表现出良好的特性,即将同一用户下同一集群部署到同一台物理主机上,很好地解决了Docker Swarm 3种算法不能考虑到容器之间的依赖性而随机部署容器的弊端.
很快,我发现雪花飘的担心是多余的。没等李献武走出牢门,田青青就迈进了北京大学的校门。作为有重要贡献的青年干部,她被组织上推荐为大学的工农兵学员。这是组织上对忠诚的战士最好的呵护与鼓励,我望尘莫及。田青青临走前来与我话别,说,你要努力啊,争取早日在城里与我会合。我说,顺其自然吧。
现阶段大数据实验平台更多的使用的是Kubernetes进行容器的管理.相较于Docker Swarm原生的解决方案,因为资源调度策略单一而不能满足特定场景下的调度策略.现提出的RSFU算法在大数据实验平台的特定场景下.很好地解决了面向用户的资源调度策略.其部署方便,与Docker容器契合度更高、学习成本更低、且实验结果较好,能够在这一场景下提供一种不同于以往的解决方案.
5 结论
已有研究表明,对Docker Swarm集群管理引擎深入研究发现,其原生的3种算法考虑维度不足,特定情况下调度效果不好.基于此,提出优化算法,采用一元线性回归模型,使用各物理节点实时数据,对物理节点未来情况进行预测.通过CPU利用率、内存利用率、磁盘I/O占用率、网络I/O占用率4个维度对容器进行优化调度.最后以系统负载率作为评价指标.实验证明,在容器集群规模4 032, 2 754,1 500下,RSFU算法分别得到系统负载率0.61,0.42,0.21的结果,皆优于Docker Swarm原生算法,表现出较强的鲁棒性.且在容器依赖性上,摒弃了随机部署容器的弊端,从用户的角度出发,将同一用户下的容器部署在同一节点上.既能保证系统负载率最小,又考虑了容器之间的依赖性.
