基于Azure AutoML的泥沙预报模型构建与应用
2023-06-27曹辉陈柯兵董炳江
曹辉 陈柯兵 董炳江

摘要:泥沙预报是开展水库泥沙实时调度的前提,而水沙作用机理和演进规律的复杂性又导致开展高效、精准的泥沙预报较为困难。基于微软在2018年发布的Azure AutoML自动化机器学习技术,进行了泥沙预报模型构建与应用的探索。选取三峡水库泥沙重要控制站——寸滩、清溪场、万县、黄陵庙站构建了含沙量预报模型,并从模型构建与评估、预报精度、输入因子重要性等角度开展了分析。研究结果表明:Azure AutoML技术可便捷地进行自动化机器学习模型的构建,基于该技术建立的预见期为1~3 d的模型针对沙峰消退阶段和含沙量较小阶段预报效果较好;预见期为1~2 d的模型可以对沙峰开展较为准确的预报;寸滩、清溪场站含沙量主要受到上游来沙的影响,而万县、黄陵庙站的含沙量自相关性较强。
关 键 词:泥沙预报; 沙峰传播; 含沙量; Azure AutoML; 自动化机器学习; 三峡水库
中图法分类号: P338+.5
文献标志码: A
DOI:10.16232/j.cnki.1001-4179.2023.04.014
0 引 言
泥沙预报是水库开展泥沙实时调度的前提[1-2]。由于下垫面条件的差异和水沙产输机理的复杂,泥沙预报一直是一个世界性的技术难题。许多学者采用水文学和水力学的方法对此开展了研究[3-5],近20 a来也有学者将人工神经网络等机器学习方法运用于河流的泥沙预报。苑希民等[6]阐述了人工神经网络方法对多泥沙洪水演进的辨识机理,通过模型联想实现水沙演进预报,研究结果与实测结果吻合良好,体现了人工神经网络的应用价值和发展前景。李义天等[7]将神经网络理论应用于河道水沙运动规律的模拟与预报,并与传统回归模型进行了对比分析,回归模型具有数学表达直观、易于理解的特点,而神经网络模型在模型结构确定、模型容错性能等方面较优,但在模型学习速度、算法复杂程度、实用性和直观性等方面逊于回归模型。
利用机器学习开展研究工作,一般均包含数据清洁、特征选择、模型选择、参数优化以及最终模型验证等几个步骤。这些步骤当中仍然包含大量既耗时又重复的手动操作流程,且往往需要具有经验的专家来开展这些工作,特别是根据特定的问题选取最合适的机器学习算法。
自动化机器学习(AutoML)则通过技术手段,将机器学习专家的经验固化下来,使机器可以自动建模、自动调参,将整个机器学习过程自动化,减少专家在整个机器学习过程中的参与[8]。谷歌、微软、百度等纷纷在该领域发力,并提供了零门槛AI开发平台,实现零算法基础定制高精度AI模型。Azure AutoML是微软在2018年发布的自动建模技术,支持模型结构搜索和超参数搜索,在算法上支持分类、回归和时序预测的常用算法。相较于同类型的Google AutoML、Baidu EasyDL,它具有网络易于访问、低代码(Low-Code)的特点,大部分的计算与操作可以在Web浏览器中完成。
随着长江上游大型梯级水库群的开发与建成,以三峡工程为核心的干支流控制性水库群已形成规模[9-10],三峡水库入库泥沙特性大幅改变[11],针对三峡水库开展高效、精准的泥沙预报也就极为关键[12]。为探索Azure AutoML技术在泥沙预报领域的运用效果,推动基于机器学习方法的泥沙预报模型应用于三峡水库的泥沙预报生产实践,本文基于Azure AutoML技术,以三峡水库入库、出库沙量重要控制站——寸滩、清溪场、万县、黄陵庙站为例,开展泥沙预报研究。
1 研究数据与方法
1.1 研究数据
收集的数据资料为2010~2021年(7~9月)朱沱、北碚、寸滩、武隆、清溪场、万县、庙河、黄陵庙站的水沙整编资料,各站点的位置分布如图1所示,数据时间间隔为1 d。收集的水沙要素为:各站的水位、流量、含沙量、输沙率。此外,也收集了三峡水库坝前水位(茅坪站)的同期数据。
研究对寸滩、清溪场、万县、黄陵庙站含沙量开展预报模型建模,使用数据如表1所列。以清溪场与黄陵庙两站为例,具体说明如下。
(1)清溪场站。构建机器学习模型时,考虑寸滩、武隆至清溪场站的水沙传播时间,选定21个水沙要素作为模型输入因子(自变量,又称为特征因子),分别为:当天与前一天的寸滩站水位、流量、含沙量、输沙率,武隆站水位、流量、含沙量、输沙率,清溪场站水位、流量;前一天的清溪场站含沙量。
为了探索预报模型性能受预见期时长的影响,共建立3种不同预见期的模型,模型输出因子(因变量,又称为标签变量)为不同时段的清溪场站含沙量。举例说明,如表2所列,若模型输入为7月17日清溪场站日均含沙量,以及17,18日的日均寸滩站水位、流量、含沙量、输沙率,武隆站水位、流量、含沙量、输沙率,清溪场站水位、流量,则3种模型输出分别为18日清溪场站日均含沙量(清溪场模型1)、19日清溪场站日均含沙量(清溪场模型2)、20日清溪场站日均含沙量(清溪场模型3)。
(2) 黄陵庙站。与清溪场站原理类似,选定15个水沙要素作为模型输入因子。若模型输入为7月17日黄陵庙站日均含沙量,以及17,18日的日均庙河站水位、流量、含沙量、输沙率,茅坪站水位、黄陵庙站水位、黄陵庙站流量,则3种模型输出分别为18日黄陵庙站日均含沙量(黄陵庙模型1)、19日黄陵庙站日均含沙量(黄陵庙模型2)、20日黄陵庙站日均含沙量(黄陵庙模型3)。
寸滩站建模过程与清溪场站类似,将清溪场站输入的寸滩、武隆、清溪场站数据,对应替换为朱沱、北碚、寸滩站数据即可。万县站建模过程与黄陵庙站类似,将黄陵庙站输入的庙河、茅坪、黄陵庙站数据,对应替换为清溪场、茅坪、万县站数据即可。
1.2 Azure AutoML计算流程
本文采用微软Azure机器学习平台(microsoft azure machine learning studio,Azure ML)中的AutoML功能对水沙数据进行建模。Azure ML是一种面向机器学习与大数据分析的云服务平台,能够有效提升采用机器学习方法进行数据分析的效率[13]。該平台的优势主要有[14]:能够在单个实验中一次性尝试多种模型并比较结果,有助于找到最适合的解决方案。具体即:在同一个实验中建立多算法模型,对预测结果进行对比分析,通过选择合适的学习算法和海量数据的训练,从而达到建立预测模型的目的。
基于Azure AutoML的数据分析流程如图2所示,主要由选择数据资产、配置作业、选择任务和设置、超参数配置(仅计算机视觉,本次研究不涉及)、验证和测试等步骤组成。下文将结合清溪场站含沙量预报进行简要介绍,详细流程可参考相关链接[15]。
(1)选择数据资产,即导入数据,可以采用4种方式将数据导入到实验中:①从本地文件导入;②从数据存储导入;③从Web文件导入;④从开放数据集导入。本次研究采用从本地文件导入数据的方式,数据格式必须预先处理为CSV格式。在数据导入过程中,可以对数据的表头与字段等进行设置,并通过数据预览功能确认上传数据的正确性。
(2) 配置作业,从云平台中选取不同的计算实例或计算集群运用到本次机器学习模型的构建中。算力越高,模型建模越快,收费也相应增加。在此步骤中,需选取用于执行机器学习模型预测的目标列,即本次研究中的清溪场站含沙量。
(3) 选择任务和设置,为实验选择机器学习任务类型,并配置机器学习任务的控制参数(见图3)。在本次研究中,由输入因子预测清溪场站含沙量属于回归问题(预测连续数值)。
进一步在查看其他配置设置选项中,可以进行个性化设置,如选择对模型进行评分的主要指标标准均方根误差、平均绝对误差、相关系数R2等,用来更好地控制训练作业。已阻止的模型选项可以主动排除Azure AutoML中内置的部分模型,以加快整体的计算过程。退出条件为满足设置中的任一条件,则会提前停止训练作业。
(4)验证和测试,选取不同数据的比例用于模型构建、调整。精度分析(测试)样本在模型构建过程中不会使用,可作为全新样本资料,用于分析精度指标。
1.3 Azure AutoML内置模型介绍
Azure AutoML中内置了大量不同的机器学习算法。其中,部分模型的算法名称相同,如表3中出現了多次StandardScalerWrapper,ElasticNet,由于算法超参数设置有差异,可将其视作不同模型。现将部分算法简要介绍如下,详细说明可参考相关链接[16-17]。
(1) VotingEnsemble算法。该算法是一个集合算法,它包含多个基本回归模型,并对这些模型结果进行加权平均,以形成最终预测。
(2) MaxAbsScaler,ElasticNet算法。MaxAbsScaler(绝对值最大标准化)将输入数据除以最大值,缩放至[-1,1]。以本次研究为例,即将原始的21个水文要素除以其各自的最大值后,作为ElasticNet算法的输入。ElasticNet算法是一种线性模型,又叫弹性网络回归,它在目标函数里同时使用L1、L2惩罚项。
(3) StackEnsemble算法。此算法是一种简单的集成学习算法,首先构建多个不同类型的一级学习器,并使用它们来得到一级预测结果,然后基于这些一级预测结果构建一个二级学习器,来得到最终的预测结果。Stacking的动机可以描述为:如果某个一级学习器错误地学习了特征空间的某个区域,那么二级学习器通过结合其他一级学习器的学习行为,可以适当纠正这种错误。
(4) StandardScalerWrapper,ElasticNet算法。StandardScalerWrapper是一个用来将数据进行归一化和标准化的方法,将输入数据删除平均值和缩放到单位方差来标准化特征。得到的结果是新的输入数据集方差为1,均值为0,随后输入到ElasticNet算法中。
(5) RobustScaler,ElasticNet算法。
RobustScaler利用中位数和四分位距缩放特征,对于给定的特征,每个观测值先减去中位数,再除以四分位距,能够在某种程度上抵消异常值的影响,随后输入到ElasticNet算法中。
2 结果分析
在寸滩、清溪场、万县、黄陵庙站泥沙预报模型构建过程中,选取的主要指标为R2,退出条件设置为训练作业时间0.5 h。
研究中选定了2010~2021年的数据作为数据源。将数据系列分为两大部分:2010~2019年样本资料作为模型构建样本(供训练和验证过程使用),2020~2021年的资料作为模型精度分析样本(供测试过程使用)。在模型构建过程中不会使用精度分析样本,可将其作为全新样本资料,用于分析精度指标。
2.1 模型构建与评估
以清溪场站为例,Azure AutoML利用2010~2019年样本资料建立了3种不同预见期模型,对应效果较好的算法与R2如表3所列。可以发现:3种预见期下效果最好的算法均为VotingEnsemble,笔者对该算法在2010~2019年、2020~2021年两时期的详细指标进行分析(见表4),值得注意的是这些指标均由Azure AutoML系统自动计算,无需额外设置。指标的具体说明可参考相关链接[18],如解释方差是(explained_variance)衡量模型对目标变量变化的解释程度,它是原始数据方差与误差方差之间的递减百分比。
由表4中数据可以发现:模型1在两个时期均能得到较好的结果;而模型2在进行模型构建的2010~2019年可以取得不错的结果,但在进行测试的2020~2021年效果稍差,两时期具有一定的性能差异;模型3则在两时期的效果均较差。此结果表明,预见期是影响清溪场站泥沙预报精度的重要因素,模型在1~2 d预见期下能取得较好的结果,证实了已有研究对寸滩、清溪场站间输沙规律的探索[19],寸滩站到清溪场站沙峰时间传播约为1 d,考虑到含沙量资料为日均数据,实际寸滩站到清溪场站沙峰时间小于2 d。
完成余下寸滩、万县、黄陵庙站的预报模型构建后,选择各站点效果最好的算法为研究对象(如清溪场站的VotingEnsemble算法),表5给出了这些站点的模型R2的对比情况。可以发现寸滩、清溪场站模型的性能受预见期的影响较大,尤其是模型3,而万县与黄陵庙站模型的性能衰减幅度相对较小。
2.2 2020年和2021年预报精度分析
图4展示了研究各站点含沙量整编值(可反映实测情况)与3种不同预见期的模型模拟值(可反映模型的预报性能)在2020,2021年的对比情况,可以发现如下特点:
(1) 2020年,本文研究的4个站点在8月中下旬出现了两次较大的沙峰,所有模型均能一定程度上判断沙峰的变化趋势,尤其针对沙峰消退阶段和输沙率偏小的稳定阶段。但寸滩、清溪场站的模型3对第二次沙峰预报值明显偏小,无法对沙峰的量级开展较为准确的预报。
(2) 2021年,沙峰出现次数较2020年更为频繁,对于本文研究的4个站点,模型3的效果较差,无法对快速变化的含沙量波动做出有效反馈,寸滩、清溪场、万县站沙峰量级的预报值均有较大的误差。但对于沙峰消退阶段(如清溪场站7月下旬至8月上旬、万县站7月下旬至8月上旬、黄陵庙站8月上中旬),模型3同样可以得到较好的结果。
模型1与模型2可对大多数沙峰的量级开展较为准确的预报,而对寸滩站7月10日左右发生快速涨落的沙峰(1.4 kg/m3),预报误差则相对较大。
2.3 输入因子重要性分析
此外,Azure AutoML在构建模型的过程中,能提供量化的输入变量间相对重要性,通过观察输入变量的使用次数对模型性能的影响来衡量其重要性,可以帮助建模者对输入变量更好地进行评估,其原理详见相关链接[20-21]。
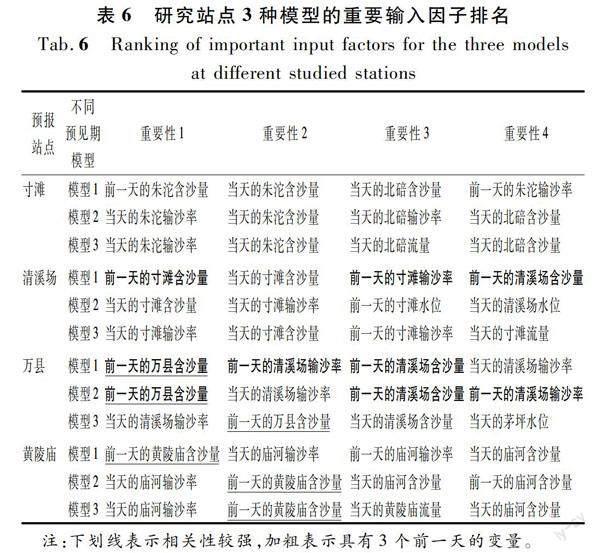
表6利用该功能统计了4个站点在不同预见期3个模型的前4个重要变量。从表6中可以发现规律如下:
(1) 万县和黄陵庙站的含沙量自相关性较强(见表中带下划线的变量)。而寸滩、清溪场站则主要受到上游来沙的影响,排名前二的重要性因子均为上游干流的含沙量、输沙率。
(2) 仅清溪场站的模型1和万县站的模型1,2具有3个前一天的变量(见表中加粗的變量),即对它们进行预报模型构建时,主要依据的是过去的信息。在泥沙预报的工作实践中,可操作性较强,余下的模型输入以当天的信息为主,受到信息获取时效性的影响较大。从表5中也可以发现,4个站中仅有万县站的模型2其预报性能要好于模型1。故针对万县站而言,对其进行泥沙预报模型的构建相对较易,模型受预见期的影响较小。
3 结 论
本次研究基于微软的Azure AutoML技术,进行了泥沙预报模型构建与应用的探索,以三峡水库入库、出库沙量重要控制站——寸滩、清溪场、万县、黄陵庙站为例,构建了各站的含沙量预报模型,并从模型构建与评估、预报精度、输入因子重要性等角度开展了分析,结论如下:
(1) 微软Azure AutoML技术可便捷地进行自动化机器学习模型的构建,其具有网络易于访问、低代码(Low-Code)的特点,可极大降低机器学习建模的门槛,适用于泥沙预报模型的构建。
(2) 以2020,2021年的7~9月为例,预见期1~3 d的模型针对沙峰消退阶段和输沙率偏小的稳定阶段预报效果较好。对于沙峰,预见期为1~2 d的模型可以对大多数沙峰的量级开展较为准确的预报,而预见期3 d的模型效果较差。
(3) 模型输入因子重要性分析结果表明,寸滩、清溪场站含沙量主要受到上游来沙的影响,而万县、黄陵庙站的含沙量自相关性较强,万县站的泥沙预报模型性能受预见期的影响较小。
参考文献:
[1]陈桂亚,董炳江,姜利玲,等.2018长江2号洪水期间三峡水库沙峰排沙调度[J].人民长江,2018,49(19):6-10.
[2]董炳江,陈显维,许全喜.三峡水库沙峰调度试验研究与思考[J].人民长江,2014,45(19):1-5.
[3]陶冶,刘天成.基于一维水沙模型的三峡库区泥沙预报初探[J].人民长江,2011,42(6):65-68.
[4]闫金波,代水平,刘天成,等.三峡水库泥沙作业预报方案研究[J].水利水电快报,2012,33(7):71-74.
[5]王世平,王渺林,许全喜,等.三峡入库站含沙量预报方法初探与试预报[J].水利水电快报,2015,36(5):11-14.
[6]苑希民,刘树坤,陈浩.基于人工神经网络的多泥沙洪水预报[J].水科学进展,1999,10(4):393-398.
[7]李义天,李荣,黄伟.基于神经网络的水沙运动预报模型与回归模型比较及应用[J].泥沙研究,2001,26(1):30-37.
[8]陈雨强.可降低AI应用门槛的自动机器学习技术[J].人工智能,2018(5):48-55.
[9]郭生练,何绍坤,陈柯兵,等.长江上游巨型水库群联合蓄水调度研究[J].人民长江,2020,51(1):6-10.
[10]陈柯兵,郭生练,王俊,等.长江上游ECMWF降水和径流预报产品评估[J].人民长江,2020,51(3):73-80.
[11]周银军,王军,金中武,等.三峡水库来沙的地区组成变化分析[J].泥沙研究,2020,45(4):21-26.
[12]杨成刚,许全喜,董炳江,等.三峡水库泥沙实时预报关键技术研究及应用:以2020年汛期为例[J].人民长江,2020,51(12):82-87.
[13]熊甜,郑松,徐哲壮,等.基于Azure机器学习平台的大学校园用电分析与预测[J].电气技术,2018,19(5):5-9.
[14]易植.Windows Azure新服务,让机器学习触手可及[J].英才,2014(9):101.
[15]MICROSOFT.教程:AutoML-训练无代码分类模型-Azure Machine Learning | Microsoft Learn[EB/OL].[2022-10-17].https:∥learn.microsoft.com/zh-cn/azure/machine-learning/tutorial-first-experiment-automated-ml.
[16]MICROSOFT.使用Python (v2)设置AutoML-Azure Machine Learning | Microsoft Learn[EB/OL].[2022-10-17].https:∥learn.microsoft.com/zh-cn/azure/machine-learning/how-to-configure-auto-train.
[17]MICROSOFT.使用自动化机器学习进行特征化-Azure Machine Learning | Microsoft Learn[EB/OL].[2022-10-17].https:∥learn.microsoft.com/zh-cn/azure/machine-learning/how-to-configure-auto-features.
[18]MICROSOFT.评估 AutoML 试验结果-Azure Machine Learning | Microsoft Learn[EB/OL].[2022-10-17].https:∥learn.microsoft.com/zh-cn/azure/machine-learning/how-to-understand-automated-ml.
[19]張地继,董炳江,杨霞,等.三峡水库库区沙峰输移特性研究[J].人民长江,2018,49(2):23-28.
[20]MICROSOFT.使用 Azure 机器学习工作室中的负责任 AI 仪表板(预览版)-Azure Machine Learning | Microsoft Learn[EB/OL].[2022-10-17].https:∥learn.microsoft.com/zh-cn/azure/machine-learning/how-to-responsible-ai-dashboard#feature-importances-model-explanations.
[21]MICROSOFT.使用 Python 解释和说明模型(预览版)-Azure Machine Learning | Microsoft Learn[EB/OL].[2022-10-17].https:∥learn.microsoft.com/zh-cn/azure/machine-learning/how-to-machine-learning-interpretability-aml.
(编辑:胡旭东)
Construction and application of sediment forecast model based on Azure AutoML
CAO Hui1,2,CHEN Kebing3,DONG Bingjiang3
(1.State Key Laboratory of Hydraulics and Mountain River Engineering,Sichuan University,Chengdu 610065,China; 2.Water Resources Research Center,China Yangtze Power Company Limited,Yichang 443002,China; 3.Bureau of Hydrology,Changjiang Water Resources Commission,Wuhan 430010,China)
Abstract:
Sediment forecast is the premise of real-time operation of reservoir sediment,and the complexity of water-sediment action mechanism and evolution law makes it difficult to carry out efficient and accurate sediment forecast.Based on the Azure AutoML automatic machine learning technology released by Microsoft in 2018,the construction and application of sediment prediction model were explored.The important sediment control stations along the Three Gorges Reservoir,Cuntan,Qingxichang,Wanxian and Huanglingmiao Station were selected to construct a sediment concentration prediction model,and the analysis was carried out from the perspectives of model construction and evaluation,prediction accuracy and importance of input factors.The results showed that the Azure AutoML technology can be used to construct the automatic machine learning model conveniently.The model constructed by this technology with a forecast period of 1~3 days has better prediction effect for the sediment peak regression stage and the small sediment concentration stage.While the proposed model with a forecast period of 1~2 days can carry out more accurate prediction of sediment peaks.The sediment concentration of Cuntan Station and Qingxichang Station is mainly affected by the upstream sand,while the sediment concentration of Wanxian and Huanglingmiao stations has strong autocorrelation.
Key words: sediment forecast;sediment peak spreading;sediment concentration;Azure AutoML;automatic machine learning;Three Gorges Reservoir
收稿日期:2022-07-28
基金项目:国家自然科学基金联合基金项目(U2040218);三峡后续工作项目“三峡水库区间支流水沙变化”(21303);国家重点研发计划项目(2019YFC0409000)
作者简介:曹 辉,男,高级工程师,博士研究生,主要从事水文及河流动力学相关研究。E-mail:cao_hui@ctg.com.cn
通信作者:陈柯兵,男,工程师,博士,主要从事水资源规划与管理研究。E-mail:chenkb@cjh.com.cn
