面向点击通过率预测的交互边选择算法研究
2023-06-26陈乔松江泳锋由博文孙开伟朴昌浩
陈乔松,曹 凤,江泳锋,由博文,孙开伟,邓 欣,王 进,朴昌浩
(1.重庆邮电大学 计算机科学与技术学院,重庆400065;2.重庆邮电大学 自动化学院/工业互联网学院,重庆 400065 )
0 引 言
在许多Web应用(例如社交媒体,购物平台)中,推荐系统在解决信息爆炸问题方面发挥着核心作用[1]。其中,点击通过率预测(click-through rate,CTR)是一项至关重要的任务,其目的是预测用户点击推荐商品(广告,电影)的概率[2],因此,如何准确地推荐给用户感兴趣的物品,提高用户的体验和平台的收益,这已经成为学术界和工业界非常重视的一项研究。
特征交互在CTR预测中发挥着非常重要的作用,例如篮球爱好者偏向于点击运动产品,程序员更偏好点击电脑产品,这就表明交互特征<用户,物品>比特征<用户>或者<物品>在CTR预测性能上效果更好[3]。传统的CTR预估模型常以机器学习模型为基础,例如线性模型(logistic regression,LR)[4]和树模型(light gradient boosting machine,LightGBM)[5],这些模型结构简单,需要结合复杂的特征工程才能达到令人满意的预测结果。因子分解机(factorization machines,FM)[6]通过向量内积学习二阶特征交互。注意力因子分解机(attention factorization machines,AFM)[7]加入一个注意力子网络去学习特征交互的重要性,但缺乏学习非线性特征交互。近几年随着深度学习技术的发展,基于神经网络的推荐模型也层出不穷,如神经网络因子分解机(neural factorization machines,NFM)[8],深度与交叉神经网络(deep cross network,DCN)[9],显隐式特征交互网络(extreme deep factorization machine,xDeepFM)[10],图神经网络用于特征交互(feature interaction graph neural networks,Fi-GNN)[11]等深度学习网络,能够学习高阶特征交互,但这些模型只是简单地枚举了所有的特征交互,存在可解释性差、特征交互冗余等缺点,此外,无用的交互特征也会带来不必要的噪声,使训练过程复杂化。
针对目前存在的交互特征冗余等问题,本文提出了基于图神经网络的交互边选择模型(interactive edge selection based on graph neural networks for CTR prediction,IES-GNN)。具体来说,IES-GNN将特征之间的联系转化为一种图结构,图中的每个节点对应相应的特征域,不同域之间的特征交互就转换为图中节点之间的交互边,主要创新点如下。
1)提出一种交互边选择网络(interactive edge selection network,IESNet)结合图神经网络,通过引入一个过滤阈值机制在聚合所有邻居节点信息之前来自动选择有利于预测结果的交互边,从而获得节点最优的聚合信息。
2)基于图和注意力机制,提出了节点相似度注意力机制(node similarity attention,NSA)去学习一个相似度权重矩阵来解决图节点过度平滑的问题。
本文提出的IES-GNN模型在Criteo和Avazu两个公开数据集上的大量实验证明,本文模型的预测能力优于CTR预测领域已有的最佳模型。
1 相关工作
1.1 CTR预测任务中的特征交互
特征交互在CTR预测任务中至关重要,传统的CTR预估模型常以机器学习模型为基础,例如,LR和LightGBM是预测CTR的简单基线模型,然而基于人工经验的特征工程非常繁琐低效,使模型表达能力有限。FM将每个特征嵌入到一个低维稠密的向量中,并通过向量内积学习二阶特征交互,但没有区分特征交互之间的重要性,若用该模型进行高阶交互,则会出现计算复杂度高、开销大等问题。AFM加入一个注意力子网络去学习特征交互的重要性,区别对待不同的特征,让它们对预测结果的贡献程度不同,但模型中没有使用更深层次的网络去学习高阶交叉特征。在深度学习领域,基于神经网络的推荐系统模型也层出不穷,NFM在嵌入层和深度神经网络层之间增加一个双向交互池化层来模拟二阶特征交互,相比于之前的模型,NFM降低了参数量。DCN引入了一个交叉网络以显式的方式进行高阶特征交互。xDeepFM引入一个压缩交互网络(compressed interaction network,CIN)进行向量外积。
1.2 图神经网络用于CTR预测任务
特征域之间的简单非结构化组合将不可避免地限制特征交互的建模能力,图是一种对一组对象和关系建模的数据结构,由于图的强大表示能力,近几年有很多与之相关的研究出现。图神经网络(graph neural networks,GNN)[12]是在图结构数据上学习嵌入的一种方法,图神经网络中的节点通过聚合其邻居节点的信息和更新邻居节点的隐藏状态来与其他节点进行交互。门控图神经网络(gated graph neural networks,GGNN)[13]使用门控循环单元(gated recurrent neural,GRU)[14]作为更新器。图卷积神经网络(graph convolutional networks,GCN)[15]引入卷积网络作为节点信息聚合器。Fi-GNN引入多头自注意力机制(multi-head self attention,MHA)[16]来捕获对特征域之间的依赖关系。虽然通过图结构能够非常灵活和明确地来对特征交互进行建模,但仍然存在一些问题;比如,Fi-GNN明确指出构造的是完全连接图,即任意2个特征之间都存在交互,但是列举所有特征交互会带来特征信息冗余和交互低效等问题,无用的交互也会带来不必要的噪声,使训练过程更复杂。
1.3 特征选择
近年来,特征选择在很多领域都有应用,通过特征选择机制能有效提高模型预测准确率。因子分解机模型下的自动特征交互选择模型(automatic feature interaction selection,AutoFIS)[17]在FM模型的基础上对交互特征进行选择,把较大的离散型迭代搜索的问题转换为连续型的系数求解问题。快速自适应特征约简模型(granular ball neighborhood rough sets,GBNRS)[18]为每个对象生成不同的邻域,处理没有先验知识可用的场景,极大地降低了模型的时间复杂度。检测推荐系统中有益特征交互(L0 statistical interaction graph neural network,L0-SIGN)[19]通过L0正则化自下而上地发现有意义的特征组合。基于图的特征过滤方法(infinite feature selection,Inf-FS)[20]利用矩阵幂级数的性质和马尔科夫链的基本原理对特征进行排序,并去除低排名的特征。基于样本和特征搜索空间不断缩小特征选择模型[21]采用特征冗余概念缩减特征的搜索范围来移除冗余特征。
2 面向点击通过率预测的交互边选择算法研究
2.1 IES-GNN总体框架
IES-GNN整体框架如图1所示,IES-GNN由以下几部分组成:数据输入层、数据嵌入层、交互边选择网络层、节点相似度注意力层、输出层。其中,数据嵌入层的处理方式最早是由S.Rendle[6]提出,特征嵌入(Embedding)是CTR预测的前提条件,因为点击记录包含离散的分类项,不能直接应用于数值计算,通过嵌入层将高维稀疏的特征嵌入到一个低维稠密的向量中。在经过嵌入层之后,通过交互边选择图神经网络层对图中特征交互的边进行选择,获取对预测结果最有益的特征交互边,通过多层的图神经网络层就可以达到不同特征之间的高阶交互,其中在每一层交互边选择网络层之后都输入到一个节点相似度注意力网络层,通过为每一个图节点分配一个注意力权重防止节点间出现过度平滑问题。最后将所有的特征拼接为一维的张量,最后把该张量输入到多层感知机网络进行预测。

图1 IES-GNN整体架构图Fig.1 Overall architecture of IES-GNN
2.2 数据输入层
CTR预测领域的数据通常包含数值型和类别型特征,类别特征通常是稀疏离散的,不能直接用于数值计算,因此要对其进行独热(one-hot)编码将其转换为高维的稀疏向量。比如一部电影,其由特征{类型:喜剧,语言:中文,导演:史蒂芬}构成,通过独热编码转换为高维稀疏特征:
[1,0,…,0],[0,1,…,0][0,0,…,1]
所有的数据实例可以表示为
(1)
(1)式中:m表示类别特征个数;p表示数值特征个数;xi表示第个i特征,分为独热编码向量和数值标量。
2.3 数据嵌入层
由于独热编码之后的数据是高维稀疏的,常用做法是将其嵌入到低维,密集的实值向量中,Embedding模块是后续模型的基石,直接影响最终的预测准确率[22]。
本文通过Embedding模块的映射向量Vi将特征xi嵌入到一个低维的向量ei中,表达式为
ei=Vi·xi
(2)
(2)式中:Vi∈Rd×mi;ei∈Rd,R表示数据张量的维度标识;mi是特征i的种类数;d表示低维向量的嵌入维数。
特征Embedding模块的输出是将多个嵌入向量拼接为
E=[e1,e2,e3,…,eh]
(3)
(3)式中:E∈Rh×d,h表示数据中单个样本所有的特征域。
2.4 特征图结构
以往研究中只是简单地将特征向量拼接到一起,学习特征交互信息之后输入到深度神经网络中进行训练预测,本文采用图结构,将特征表示为图结构形式,特征图可以表示为
G=(N,ε)
(4)
(4)式中:N表示所有的节点域,|N|=h,每个节点ni∈N对应每个特征ei;ε表示节点ni的所有邻居节点。它是一个完全连通图,不同的节点可以通过边进行交互作用,而边的值就是特征交互的重要性,因此,特征交互就转换为图中节点之间的交互。
2.5 交互边选择网络层
模型Fi-GNN[11]在特征图上对所有节点进行交互建模,图中所有特征交互边的存在会带来特征信息冗余和交互低效等问题,无用的交互边也会带来不必要的噪声,使训练过程复杂。因此,本文提出的IESNet模型,能够在特征图结构中自动选择有益的交互边。在本节中,将详细说明该网络是如何工作的,以及最后图神经网络是如何聚合节点间交互边信息的。
在IESNet中,图结构状态由下面节点组成
(5)
(5)式中Ht∈Rh×d,t表示交互步骤,数据嵌入层学习到的特征表示作为该层的初始节点状态H1,节点通过多层图神经网络循环地进行交互边选择和节点状态的更新,如图2所示。

图2 交互边选择网络层Fig.2 Edge-interaction selection network
在每一个交互步骤中,IESNet通过设置可训练的动态关联矩阵来动态地获取每一层交互步骤中节点之间的交互关系,通过过滤阈值机制来过滤动态关联矩阵的值,符合条件的值被保留并对应选择一个交互边,最后通过张量内积的计算方式来聚合交互边信息。IESNet的实现细节如下。
2.5.1 节点交互边选择网络
传统的图神经网络模型中的邻接矩阵通常是二进制形式的,包含0和1,它反映节点之间的连通关系,并且以往模型中的图结构都是完全连接图,且不能反映节点之间边的重要性程度。为了便于算法的实现,IESNet引入动态关联矩阵W∈Rh×h,它同时学习图中节点之间的连通关系和边的重要性程度,建模灵活的交互,整个动态关联矩阵的运算流程为
W=α⊙w
(6)
(6)式中:α={α(n1,n2),…,α(nh-1,nh)}是结构参数,表示图中交互边对最终预测的相对贡献值,通过梯度下降来自动学习;⊙表示矩阵元素位乘法,w={w(n1,n2),…,w(nh-1,nh)}是权重参数,w(ni,nj)表示节点ni和节点nj之间的交互程度,通过注意力机制获得
(7)
(7)式中:β∈R2d是权重矩阵;‖是连接操作符;ni∈δ表示ni的所有邻居节点。
最后,图中任意2个节点之间的边的值存在负数,这会导致模型产生不必要的噪声[19],贡献程度偏小的边也会成为冗余特征,因此,本文引入过滤阈值机制来自动选择对最终预测结果有益的交互边,λ为一个固定的阈值,在3.4节中,将讨论不同阈值下的性能差异,eij∈W是动态关联矩阵中交互边的值,∏i.j表示过滤之后的值。
(8)
A[ni,nj]=eij∏i,j
(9)
(9)式中,A∈Rh×h表示通过过滤阈值机制后的交互边选择动态关联矩阵。
2.5.2 节点交互边信息聚合策略
在传统图神经网络中,每个节点将聚合邻居节点的状态信息,IESNet模型以另外一种方式对节点ni的所有交互边的信息进行加权聚合,学习到更多具有鉴别力的节点嵌入。
H′=A⊗H1
(10)
(10)式中:H′∈Rh×d;⊗表示张量积,张量积用于初始节点状态与动态关联矩阵进行交互边信息聚合。
2.6 节点相似度注意力层
在经过多层的图神经网络,图中的节点之间会出现过度平滑的现象,Zhao等[23]将相似度算法与加权的Jaccard相似度算法有效结合,受Y.Bai等[24]激发,本文提出节点相似度注意力层,在CTR预测中,如果2个用户的行为特征相似,则这2个用户就相似[25],因此,在图结构中,如果2个节点的所有邻居节点聚合信息相似,则这2个节点就相似,就会导致过度平滑现象。
2.6.1 节点相似度注意力网络
IES-GNN模型中的节点相似度注意力层(NSA)通过对相似的节点分配不同的权重使之不相似,定义节点相似度注意力矩阵T∈Rh×h
(11)
(12)
(11)—(12)式中:*表示所有节点;‖‖1表示L1范数用于防止模型过拟合;sim(*)∈Rh×h表示任意2个节点之间的相似度度量,两节点相似度越小则注意力权重越大,在3.5节中,将讨论有无节点相似度注意力层对预测结果的影响。
最后为每个节点分配权重,采用张量积的方式
H′=T⊗H′
(13)
2.6.2 图节点状态更新
在传统的门控图神经网络(GGNN)中,节点的状态是根据当前层聚合节点信息和它上一层的节点信息通过GRU进行更新得来的,由于第t层只包含t层节点交互信息,受改进的深度交叉网络(DCN V2)[26]激发,将低阶和高阶特征结合在一起对预测结果有效,因此,本文将残差网络与GRU结合使用,公式为
Ht=GRU(Ht-1,H′)+H1
(14)
2.7 输出层
在进行t层节点交互之后,每个节点捕获了全局信息,先对图中节点进行拼接,由Rh×d变为Rhd×1,分别预测每个特征域,最终的结果为
(15)

(16)
(17)
(18)
3 实验结果与分析
3.1 实验设置
3.1.1 数据集
本文在Criteo和Avazu 两个公开数据集上进行实验,这两个数据集在已有的论文[10,11,27]中被广泛使用,其统计分析情况如表1所示。

表1 数据集统计情况Tab.1 datasets statistics
Criteo:这是工业界著名的CTR预测基准数据集,其中包含大约4 500万用户的点击记录和39个特征字段(包含26个类别特征和13个数值特征),这些特征字段都是匿名的。
Avazu:该数据集包含用户在移动广告上的点击行为,其中包含大约4 000万条用户点击记录和23个类别特征字段。
对于这2个数据集,本文在参考多篇论文中的数据处理方式之后,将2种数据集都按8∶1∶1的比例划分进行训练,验证和预测,此外由于数据中的数值特征可能会有很大的方差,因此,本文对特征值大于2的数值特征进行变换:z=log2(z)。
3.1.2 评估指标
在真实的训练数据中,通常会遇到正样本很少负样本很多的情况,对数损失函数(LogLoss)很低,但正样本的预测效果却很不理想[28],因此,本文使用受试者工作特征曲线(receiver operating characteristic curve,ROC)下与坐标轴围成的面积(area under curve,AUC)和LogLoss这2个指标同时来评估模型。
AUC:是衡量分类模型优劣的一种评价指标。表示预测的正样本排在负样本前面的概率,AUC值越高,表示模型效果越好。
LogLoss:又称二分类交叉熵损失函数,反应样本的平均偏差,作为模型的损失函数来做优化,衡量预测结果与真实结果之间的距离,LogLoss越低,模型性能越好。
(19)

3.1.3 基线模型
如1.1,1.2节所述,本文对比了CTR预测领域已有的模型,包括传统的一阶交互模型:LR,二阶交互模型:FM,AFM,高阶交互模型:NFM,CrossNet,XdeepFM,Fi-GNN等模型。
3.1.4 模型实现细节
基线模型的实施遵循[11],所有模型方法的Embedding嵌入大小设置为64,批处理大小设置为1 024,学习率为0.000 1,神经网络优化器采用Adam,图节点嵌入维数和图神经网络层数为在3.3节中讨论。本文所有的模型都是基于Tensorflow 1.5深度学习框架来实现,计算机操作系统为:Centos 3.10.0,显卡为Tesla V100-SXM2-32GB,内存为64 GByte。
3.2 模型效果比较
模型效果比较如表2所示,本文提出的IES-GNN模型的性能在两个数据集上比之前出现的模型都好,在广告点击率预测领域,数据集上AUC指标0.000 1的提升是具有重要意义的。具体地,相比于侧重于图神经网络的Fi-GNN,IES-GNN模型在Criteo和Avazu两个数据集上的AUC分别提升了0.28%和0.23%,在LogLoss上分别降低了0.24%和0.15%。IES-GNN模型在Criteo数据集的相对改进程度高于Avazu数据集,这是因为Criteo数据集拥有更多的特征字段,能够更好地利用图结构的表示能力。
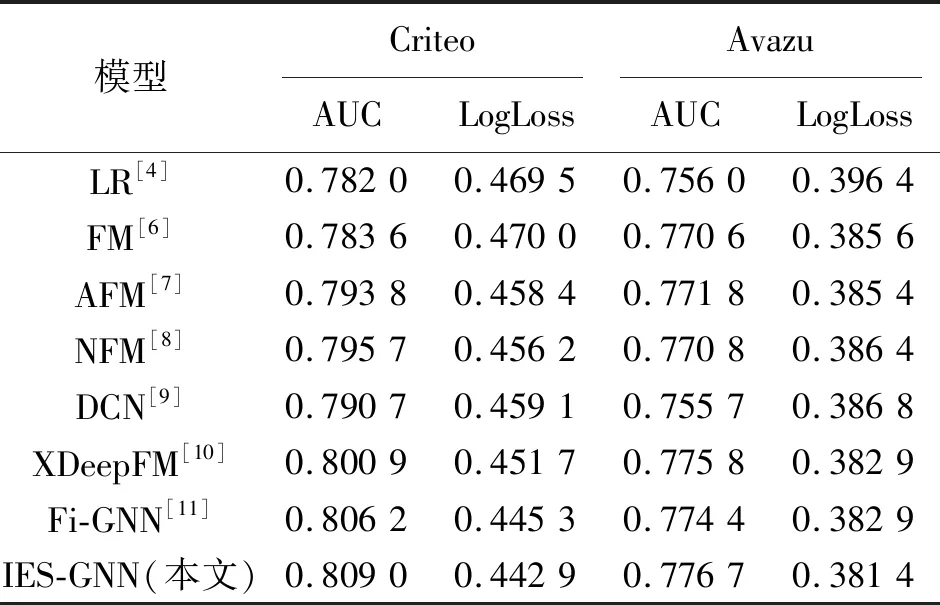
表2 各模型在Criteo和Avazu上的表现Tab.2 Performance comparison of each model on Criteo and Avazu
3.3 超参数研究
本节主要是对IES-GNN模型的超参数进行研究,主要包括图节点嵌入维数,图神经网络的层数,这些参数的变化对模型有一定的影响。
3.3.1 图节点嵌入维数对模型性能的影响
实验过程中,除特别说明的参数之外,其他参数都按照3.1.4节设置,实验首次对比了不同图节点嵌入维数对模型性能的影响,维数设置从8到64,图神经网络层数设置为1,表3是不同图节点嵌入维数下模型的性能指标,其中,Criteo数据集最佳表现的嵌入维数为64,AUC为0.807 0,LogLoss为0.444 5。这是因为数据集更大,需要更大的维度来进行训练。Avazu数据集最佳表现的嵌入维数为32,当使用更大的嵌入维数,模型会过拟合。

表3 不同图节点嵌入维数对模型性能的影响Tab.3 Impact of different embedding dimensions on model performance
3.3.2 图神经网络层数对模型性能的影响
在确定了最优的图节点嵌入维数之后,本节继续讨论不同图神经网络层数对模型性能的影响,层数设置从1到5,Criteo和Avazu两个数据集的实验结果变化趋势如图3所示,两个数据集上的最佳表现层数分别为4和5,这是合理的,因为两个数据集的数据量非常大,需要更多的交互步骤来获取更多的特征交互信息。

图3 不同图神经网络层数对模型性能的影响Fig.3 Impact of different graph neural network layers
3.4 不同阈值的性能差异
在确定最优的超参数之后,本节进一步讨论不同的过滤阈值对交互边选择的影响,本文比较了阈值为-1,0.0,0.2,0.4,0.6下的模型效果,-1表示没有设置阈值,其模型就是基线模型Fi-GNN,如表4所示。其中,在Criteo和Avazu两个数据集上,IES-GNN模型效果最优的阈值为0.2,AUC分数分别为0.809 0和0.776 7。阈值设置越大效果越低,这是因为当阈值过大,图结构中的交互边信息更少,阈值过低或者没有设置都会导致图结构中存在大量的冗余交互边信息,模型在训练过程中产生了噪声,从而影响模型的性能。
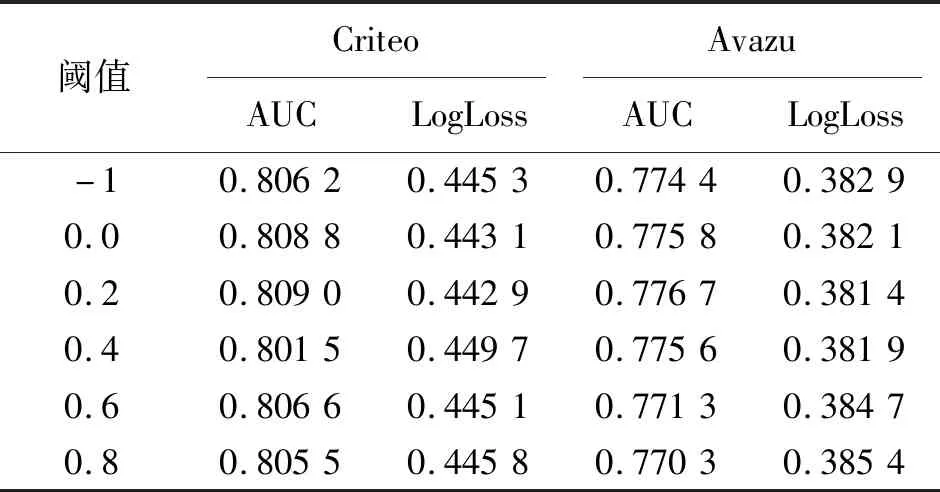
表4 不同阈值下模型的性能Tab.4 Model performance under different thresholds
3.5 消融实验
为了评估这2种改进对IES-GNN模型的有效性,在3.3,3.4节确定最优的参数条件下,本文进行了消融实验研究来验证各个模块是否起到了正向作用。
Fi-GNN:IES-GNN去除本文提出的两种网络结构:交互边选择网络(IESNet)和节点相似度注意力机制(NSA)。
NSA:IES-GNN模型去除交互边选择网络(IES)。
IESNet:IES-GNN模型去除节点相似度注意力机制(NSA)。
模型性能对比通过表5可以看出,与Fi-GNN模型相比,本文提出的IESNet和NSA在两个数据集上的表现效果确实更好,其中,IESNet在两个数据集上的AUC分别上涨了0.28%和0.16%,这表明交互边选择网络层对该模型至关重要。IESNet比NSA提升效果更明显,在Avazu数据集上AUC提升了0.07%,这说明交互边选择比节点相似度注意力机制更有效。

表5 不同网络模块对模型性能的影响Tab.5 Impact of different networks on model performance
4 结束语
本文提出的IES-GNN模型旨在弥补以往模型中交互特征信息冗余,交互低效等缺陷,将建模特征交互转换为图上的节点交互,其中交互边选择网络层自动选择有利于预测结果的交互边,从而获得节点最优的聚合信息,在每个节点获得最优的全局信息之后,本文进一步通过节点相似度注意力层去学习一个相似度权重矩阵,从而解决在经过多层图神经网络交互之后出现图节点过度平滑的问题。在Criteo和Avazu两个数据集上的性能有显著提高,这表明IES-GNN模型优于该领域已有的最佳模型,基于IES-GNN的架构思路是一种行之有效的提高CTR预估准确性的方法。
