面向服务等级的网络流多任务分类方法
2023-06-26董育宁
赵 杰,董育宁,魏 昕
(南京邮电大学 通信与信息工程学院,南京 210003)
0 引 言
网络流分类(network traffic classification,NTC)技术在互联网中有着广泛的应用,如资源分配、服务质量(quality of service,QoS)保证、网络服务提供商(internet service provider,ISP)计费和异常网络流量检测[1]等。早期NTC经过了以下几个研究阶段:基于端口、深度包检测、主机行为[2]。但是这些方法无法适用于加密流[1]。随着机器学习逐渐取而代之,出现了包括朴素贝叶斯估计[3]、无监督聚类[4]、支持向量机[5]、随机森林[6]和K-Means[7]等流分类模型。近年来,随着互联网流量中出现更为复杂的模式,深度学习模型在NTC方面取得了不错的成绩,其学习复杂模式和自动提取特征能力使其成为NTC的理想选择,尤其是卷积神经网络(convolutional neural networks,CNN)和循环神经网络(recurrent neural network,RNN)[8]。但这都需要收集大量的标记训练集,而且都是面向应用类型上的NTC,无法满足高速变化且海量数据的流媒体环境。实际上,ISP通常只需要知道数据流的所需服务类别(class of service,CoS)[9]就可决定其优先权和资源分配。为此,本文研究直接为数据流分配CoS标签,而不必考虑其应用类别[9]。同时用多任务学习(multi-task learning,MTL)方法中各任务间共享模型信息的特性来减少对标记数据的使用。
除了建立模型框架之外,还需要合理解释模型选择的理由。这对于直接CoS方法来说是一个具有挑战性的问题,因为它忽略了应用类型识别的阶段[9]。本文借鉴博弈论,通过将学习模型作为一个等价的合作博弈模型来计算每个特征对结果的影响(shapley value,SV)[10]。由于每条数据流有数百个特征,要精确计算所有特征的SV值,将导致很高的时间和空间复杂度。其次是很难理解和分析每个特征对总体CoS分类的贡献作用。为此,在实验中首先基于领域知识将流特征划分为2个宏特征(macro feature,MF),分别在MF下进行SV值计算,选择对模型贡献突出的特征映射为MF,再将每个MF映射为一种服务类型。本文的主要贡献如下。
1)选择合适特征映射为CoS 标签。包括基于领域知识将特征分为MF,对每类MF进行SV分析,选择出对模型贡献大的特征,同时分析特征之间的皮尔森相关系数(Pearson correlation coefficient,PCC)[11],为多任务模型(multi-task model,MTM)选择出贡献最大的特征,进而映射为CoS标签任务。与现有方法[9]从用户角度和获取特征难易程度来选取CoS任务不同,本文考虑了选取CoS的合理性。
2)CoS等级优化分析。分析每个CoS任务等级的分布情况,利用决策树分箱(decision tree binning,DTB)算法优化每个CoS等级阈值(cos threshold,CT)的划分,提高总体准确性。现有方法通过直方图和线性计算来划分阈值,容易导致在预处理部分增加错分率。本文中通过DTB合理化阈值划分,能够降低误分率。
3)优化网络参数。优化调整各网络模型时间损耗和分类准确性的稳定相关系数。
1 背景和相关工作
1.1 流分类模型
常用的流分类机器学习方法分为有监督、无监督和半监督学习方法[12]。文献[12]的平均聚类时间仅为传统凝聚分类器的三分之一左右,在时间消耗上有着较明显的优势,然而,由于其简单性、手动特征提取以及缺乏捕获复杂模式的高学习能力,其准确率有所欠缺。随着深度学习方法在图像分类、语音识别等各种问题上的成功应用,研究人员将这些方法用于流量分类问题中。如CNN和堆叠式自动编码器(stacked automatic encoder,SAE)框架[13]。该框架使用CNN从原始网络流量中提取高级特征,利用SAE对原始流量的统计特征(statistical feature,SF)进行编码以减少信息损失。虽然深度神经网络在一定程度上解决了机器学习初步人工特征选择的缺点,但却需要大量的标记数据集。MTM既继承深度学习自动提取特征的优点,又能使用少量标记数据完成较好的分类准确性。
文献[14]提出通过将原始数据流转换为图片 FlowPic,然后使用CNN 来预测流类别程序。除了可以将原始字节数据转换成图片,文献 [15]中利用再生核希尔伯特空间将每个流的时间序列特征转换为二维图像,生成的图像被用作CNN模型的输入。其模型以超过99%的准确率优于经典的机器学习方法。二维图像的数据输入相比于原始流的输入具有更丰富的信息。但如果对一些短流可能无法提取到足够的特征,导致在转化图片时会用大量的无用信息(0)填充。对于短流的流分类更符合早期在线流量分类问题。文献[16]讨论了CNN能够处理加密流量分类问题的根本原因,并提出基于长短时记忆(long short-term memory,LSTM)的双向流序列网络(bidirectional flow sequence network,BFSN)。其从原始流中学习出代表性特征,然后输入到端到端分类模型对其进行分类;并利用加密流的包长度和方向信息构造双向流量序列,得到不错的准确性。文献[17]用顺序消息特征(sequential message characterization,SMC)和6 个成功提取的消息大小信息的输入,特别是对于中值超过 35 个消息段的大流量,就可实现早期在线流量分类。这些方法都是面向应用类型的分类,也就是根据应用类别为数据流分配标签,无法解决新应用的不断出现。为此,可以研究面向CoS的网络流分类,直接标注CoS标签,而不必考虑它们的应用类别标签[9]。
1.2 SV简介
在合作博弈论的启发下,利用SV 构建一个加性的解释模型,所有的特征都视为“贡献者”[10]。对于每个预测样本,模型都产生一个预测值,SV就是该样本中每个特征所分配到的数值。其最大的优势是SV能反映出样本中特征的正负影响力。
2 本文方法
本文的框架模型主要分为3个部分:数据预处理、特征SV分析和MTM。
2.1 数据预处理
为了解决标记数据问题,可以将数据流分类构造成一个MTM,其中带宽吞吐需求(bandwidth throughput requirements,BT-Req)和时间敏感度(time delay sensitive,TD-Sen)任务随流量分类(traffic classification,TC)一起预测。对于前2个任务使用大量容易获得的无标签样本;而对于TC任务,使用少量的有标签样本,可以获得较高的准确率。因此,MTM避免了需要一个大的标记流量数据集。分别在ISCX公共数据集[18]和南邮数据集上进行实验,验证了该预处理的有效性和合理性。
2.2 特征SV分析
基于领域知识将76个SF分为两类MF,利用SV分析每类MF下的特征对SV贡献,分别讨论Facebook Audio (FA)、Hangouts Video (HV)、Skype File、Sftp和Netflix的Packet Information下53个特征对模型的贡献值。图1为FA应用类型的特征SV分布。横坐标为SV值,每个点代表一个样本,颜色越红说明特征本身数值越大,颜色越蓝则说明数值越小。可以看出,Packet Length Min(PLM)是一个很重要的特征,它基本上与SV呈负相关。Bwd Packet Length Min(BPLM)也会明显影响SV,但不同的是它与SV成正相关。

图1 Packet Info特征的SV贡献榜Fig.1 SV contribution list of Packet Info features
除了对于单个数据进行解释之外,还可以对整个模型特征的重要度进行分析,这里只考虑在本文模型下的特征贡献榜、重要度[10],分别在Packet Info和Time Info两类MF计算特征的SV。图2为统计特征序列箱形图,图2a为Packet Info下所有SF的SV部分图。从图2a可以看出,BPLM对模型的贡献最大,其次是PLM;从图2b可以看出,Flow IAT Max贡献最大。

图2 MF特征重要度Fig.2 Importance of MF features
MTM各任务之间应该尽量不相关,这样可以最大程度地发挥任务间的共享特性。所以,利用PCC来计算特征之间的相关性[11]。总体相关系数r定义为2个变量X、Y(特征)之间的协方差和两者标准差乘积的比值为
(1)
根据MF的特性和在802.1P[19]中定义服务等级的优先级有8种。该标准建议,最高优先级为7,应用于关键性网络流量,如路由选择信息协议(RIP)和开放最短路径优先(OSPF)协议的路由表更新。优先级6和5主要用于延迟敏感(delay-sensitive,DS)应用程序,如交互式视频和语音。优先级4到1主要用于受控负载(controlled-load,CL)应用程序,如流式多媒体和关键性业务流量。同时802.1P说明网络管理员可以根据实际来决定映射情况,所以在本文中,将DS和CL扩展为2种不同的CoS任务。
International Telecommunications Union(ITU)用QoS等级(常为0~4个)来衡量用户服务等级,所以CoS大多继承了QoS下0~4个等级来确定流量优先级和资源分配,合理优化CoS等级也十分重要。本文采用DTB来合理化CoS等级。对所有样本只包含两个SF (FIT(Fwd IAT Total)和PLM)的序列T=[FIT,PLM,Ai(样本标签)],讨论Ds和Cl两种CoS任务SF数据分布特性,其箱形图[20]分布分别记为Td和Tc,如图3所示。从图3a可以看出,不同应用类型有较明显的集中区域分层现象,HV的FIT集中值最高;FA的FIT集中值最低;从图3b可以看出,FA和HV的PLM是一样的,这也是合理的[21]。

图3 统计特征序列箱形图Fig.3 Box chart of statistical characteristic sequence
2.3 决策树分箱
在CT划分中,通过对连续值属性进行分箱操作(离散化),使其对异常数据有更好的鲁棒性。DTB的原理是将要离散化的变量用树模型拟合目标变量,用决策树内部节点的阈值作为分箱的切点。根据Gini系数[22]最大的点作为阈值划分数据集,这样得到CoS不同任务的等级阈值划分如表1所示。

表1 CoS等级阈值划分Tab.1 CoS level threshold division
对于复杂的问题,分解为简单且相互独立的子问题来单独解决,然后再合并结果得到解。这样做看似合理,其实不正确。因为实际中很多问题不能分解为多个独立的子问题;即使可以分解,各个子问题之间也是相互关联的。MTM就是为了解决此问题。把多个相关的任务放在一起学习,任务之间共享一些因素,可以在学习过程中共享所学到的信息,这是单任务学习所不具备的。
2.4 本文模型
本文模型框架如图4所示。主要分为预处理和MTL两个阶段。预处理阶段主要包括:①Wireshark提取原始PCAP数据;②利用CICFlowMeter[23]提取统计特征;③基于领域知识将统计特征划分为宏特征;④特征SV分析并进行CoS映射。MTL阶段中模型部分使用LeNet-5[24]模型,选用最大池化;除了包含 SoftMax 的最后一层之外,模型中使用ReLU作为激活函数。其他参数为卷积层1(32*3*2)→池化层(2)→卷积层2(64*3*2)→池化层(2)→卷积层3(128*3*2)→池化层(2)→Softmax(256)输出。

图4 面向CoS的MTMFig.4 MTM for CoS
3 实验结果
3.1 数据集
实验使用ISCX VPN non-VPN(2016)数据集(简称为ISCX)[18]和2021年在南京邮电大学校园网采集的南邮数据集(或ND)进行验证。ND利用WireShark抓包工具,通过在不同的网站抓取各种业务流数据,包含点播和直播视频流、文件下载、网页浏览和邮件共计4 707条数据流。经过预处理,产生4元组数据(时间戳、相对时间、数据包大小和数据包方向)的输入文件,并利用CICFlowMeter[23]计算83个SF (源地址、端口号、协议等在本文中用不到,所以实验只用了76个,如表2所示)。ISCX包含不同应用程序的43 590个加密TCP流PCAP文件。实验中主要用到FA、HV、Skype file、Sftp和Netflix五种应用数据。本方法只使用小部分标签就可预测MTM的数据流类别。对于现代加密方法,例如QUIC[25]和TLS1.3[26]传输层协议,有效负载信息基本没用。所以,本文将BT-Req和TD-Sen作为单独的任务输出结果。

表2 宏特征Tab.2 Macro features
3.2 评估指标
实验的评估包括分类准确性和时间性能评估。
采用总体准确度(Accuracy)、精度(P)、召回率(R)和F1分数(详见3.5对比试验)来量化分类器的分类准确率[27],其中,Accuracy是指所有分类正确的样本占全部样本的比例;P为预测是正例的结果中,确实是正例的比例;R是所有正例样本中被找出的比例;F1是P和R的调和平均。其计算公式为
(2)
(3)
(4)
(5)
(2)—(5)式中:TP和FP分别表示该类样本正确分类和错分的样本数;FN和TN分别表示其他类样本误分为该类和正确分类的样本数。
时间性能指标为训练和识别时间平均值。
3.3 多任务模型
通过在Keras上搭建模型进行训练和测试;实验环境是Windows 10,CPU为Inter(R) Core(TM) i5-6300HQ,内存16 GB。实验参数的设定:No.epochs=100;Batch size=64;λ =1;timestep=120。分别采用10、20、50和100个样本来训练达到稳定和防止过拟合。优化器使用Adam并自适应学习,参数默认:Learningrate=0.001,指数衰减率beta1=0.9,beta2=0.999,通过自适应学习以达到全局最优。实际训练过程真实学习率lrt,t为时间步长。
t←t+1
(6)
(7)
使用交叉熵loss函数(见(7)式)。
(8)
多分类中的loss函数为
(9)
(9)式中:yi表示样本i标签;ai表示样本i预测为正类的概率。
图5为ISCX下MTM中各任务准确性迭代曲线。从图5可以看出,BT-Req和TC任务大约在5个epochs时就基本收敛;只有TD-Sen任务在训练40个epochs时才收敛。同时可以看出,TC任务的准确性在0.99左右,比TD-Sen(0.92)和BT-Req(0.97)任务要高。这是因为TD-Sen和BT-Req这2个单任务之间的关联性很弱,但是他们对TC任务有贡献,会为TC的模型共享参数,提高其总体准确性。而TD-Sen任务的准确性较低的原因是FA和HV在Packet info上较为相似,弱化了最后的准确性。

图5 ISCX下MTM中各任务准确性迭代曲线Fig.5 Iteration curve of each task in MTM under ISCX dataset
3.4 单任务学习
将TD-Sen 、BT-Req以及TC这3个任务分别单独输入到CNN模型中。图6为ISCX下单任务CoS准确性迭代曲线。从图6可以看出,BT-Req和TC在较短时间内可以达到高的准确性。而TD-Sen相比于其他两个任务的准确性要低一点。

图6 ISCX下单任务CoS准确性迭代曲线Fig.6 Iterative curve of single-task CoS accuracy under ISCX dataset
3.5 迁移学习
在迁移学习(transfer learning,TL)中把预训练好的模型参数迁移到新模型来帮助其训练。考虑到大部分数据或任务都是存在相关性的,所以通过TL模型可以将已经学到前2个任务模型的参数通过某种方式来分享给新模型,从而加快并优化模型的学习效率。图7为ISCX下TL的TC任务准确性迭代曲线。由图7可见,TC在10个epochs之后达到近0.99的稳定准确性。TL不同于MTM之处在于后者是在同一时间和空间下完成训练和识别过程,而前者是在不同的时间和空间分别完成训练和识别过程。
3.6 对比试验
在文献[9]中从用户角度以及获取特征难易程度来选取CoS任务,却没有考虑其合理性。本文尝试做出合理性解释,并与文献[9]方法进行性能对比。表3为ISCX数据集下的性能对比。从表3可以看出,MTM的3个任务的准确性明显高于文献[9]的方法;尤其是TC任务,文献[9]方法的准确性在训练样本数为100时也只有80%;而在MTM中当样本数为10时就已经达到了较高的准确性,随着样本数的增加逐渐出现过拟合现象。体现了本文MTM可以用更少的样本实现更高准确性的优势。在TL框架下,TC的准确性也比[9]方法高。在单任务模型下文献[9]方法前2个辅助任务Bandwidth(Bw)和Duration(Du)表现较好,但最重要的TC任务却表现较差。而本文方法在单任务框架下各任务都表现较好。所以总体来说,本文选择的CoS任务和DTB划分比文献[9]的效果更好。其原因在于通过SV和PCC进行特征选择,间接将SF映射为CoS任务并解释其合理性,相比于文献[9]从用户的角度选择CoS任务更加合理。而且在文献[9]中对CoS任务只是单纯地通过直方图和线性计算来划分阈值,导致在预处理部分就增加了错分率。本文通过DTB合理划分阈值,能够减少误分率。表4为ND数据集下的性能对比,由表4可见,在ND下总体准确性优于文献[9]。

表3 不同方法准确性对比(ISCX)Tab.3 Accuracy comparison of different methods(ISCX)

表4 不同方法准确性对比(ND)Tab.4 Accuracy comparison of different methods
表5为本文方法与文献[9]方法的时间性能对比。在本文方法中,单任务模型中各任务的训练时间(training time,TT)分别是0.89 s、0.89 s和54.56 ms,而TL模型下TC任务TT为0.83 s/epoch;相比之下,MTM的TT为1.90 s/epoch就显得比较长。可能是因为其预处理过程较为复杂,以更多的时间代价获得更高分类准确性。同时可以看出,单任务模型中各任务的识别时间(inference time,Int)分别是0.19、0.19和0.20 ms。TL的Int为0.19 ms。由此可知,TL通过迁移参数来帮助新模型训练,增加了TT,但降低了TC的Int;相比之下,多任务的Int比单任务和TL模型的Int长。另外,本文方法的TT比文献[9]方法都要短;这是因为做了更为复杂的预处理,使训练过程简化,同时降低Int,体现了预处理的优越性。表6为3个任务P,R,F1比较,从表6可知,MTM中TC任务性能最好,体现了辅任务为主任务贡献参数的优点。
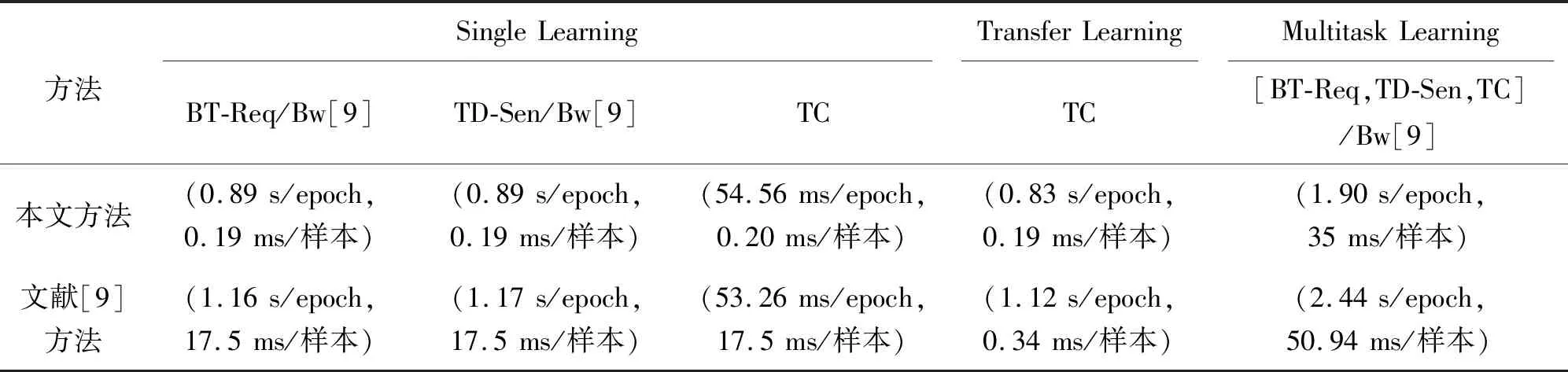
表5 本文方法与文献[9]方法的TT(/epoch)和Int(/样本)比较Tab.5 Comparison of TraT (/epoch) and Int (/sample) of this method and [9] method

表6 本文方法与文献[9]方法三个任务的P,R,F1比较Tab.6 Comparison of the three tasks P,R,F1 of this method and literature[9] method %
图8为本文方法MTM各任务混淆矩阵,从图8可以看到,本文方法BT-Req和TC两个任务的误分率非常低。在BT-Req中只有CoS等级为2的情况下被错分为CoS-0(0.03)和CoS-1(0.02)。在TC任务下只有CoS-3被错分为CoS-0(0.03)。不过TD-Sen误分率都比较大。图9为文献[9]方法MTM各任务混淆矩阵,从图9可知,Bw和TC两个任务的准确性较高,Du的错分率比较大。总的来说,相对应的任务本文方法优于文献[9]方法。

图8 本文方法MTM各任务混淆矩阵Fig.8 Confusion matrix of MTM tasks in this paper

图9 文献[9]方法MTM各任务混淆矩阵Fig.9 Confusion matrix of MTM tasks in literature[9]
4 结束语
提出了一种利用SV来选择CoS任务的方法。通过基于领域知识将多维特征降维到二维MF,以此来减少计算复杂度。以每个MF为入手点,借鉴博弈论来分析每个特征对模型的贡献大小(SV),然后计算每个MF下贡献突出的特征之间的PCC,去除冗余特征。选出的特征映射为Ds和Cl两种任务。利用DTB算法合理划分CT。实验使用ISCX和ND将Ds、Cl和TC任务通过MTM进行训练;与单任务CNN和TL模型对比,MTM有明显优势。实验结果显示本文方案在准确性和Int方面优于文献方法。本方法还有待改进之处,例如如何提高模型的时间效率,需要进一步的研究。
