基于预训练模型和多视角循环神经网络的电力文本匹配模型
2023-06-26王文娟甘玉芳
赵 伟,王文娟,甘玉芳
(1.重庆邮电大学 国际合作与交流处,重庆 400065;2.国网重庆市电力公司信息通信分公司 调控中心,重庆401121;3.国网重庆市电力公司信息通信分公司 技术发展部,重庆 401121)
0 引 言
文本匹配的主要目标是正确判断两段自然语言形式的文本的语义是否相关[1],自动问答、信息检索、人机对话、问题复述等各类自然语言处理任务均可抽象为该问题。文本匹配技术在电力领域具有重要应用价值。随着电力业务种类及规模不断增长,电力运维系统日益复杂,对电力运维业务的效率要求也随之大幅提升。运维人员受理运维问题时,可利用文本匹配技术从专业知识库中根据运维请求检索出解决方案,快速应对运维问题。运维项目管理者可以利用文本匹配技术来对运维服务项目进行项目匹配计算,避免运维项目重复立项等问题,从而提升运维服务精益化管理水平。
神经网络模型目前已成为文本匹配领域的主要模型。其中,基于Siamese网络架构[2]的模型使用相同的神经网络(如CNN或RNN)对两个句子进行编码,然后基于编码向量表示来计算语义匹配度[3]。为了更好地关注到体现句子含义的单词,有研究还将注意力机制引入到模型结构中[4],取得了较好的效果。上述研究由于在编码过程中两个句子没有进行交互,而单个向量往往不能很好地表示句子语义,因而某些匹配信息可能被忽略[5]。为解决这类模型存在的问题,一些研究采用基于比较聚合架构的模型来进行文本匹配[6],这类模型通过比较词、短语、句子等不同级别的向量表示,再聚合比较结果来进行文本匹配。例如,文献[7]在词粒度级别上提出LSTM匹配模型;文献[8]提出一种词对交互模型,该模型首先从两个序列中抽取词语对,再使用相似性焦点层和多层CNN聚合这些单词比较的结果。
尽管这些研究取得了良好的进展,然而还存在以下问题。
1)多数模型采用Word2Vec[9]或Glove[10]词向量作为网络模型的输入,同一个词在不同上下文语境下的词向量是固定的,无法体现词向量表示的动态性。然而,单词的含义与其所处的语义环境密不可分,例如“这个苹果很好吃”和“苹果12的摄像头不错”这两句话中“苹果”的含义就大相径庭,前一句话中“苹果”指的是一种水果,后一句话指的是智能手机。因此,要准确进行文本匹配就必须考虑单词的上下文。
2)部分模型只关注了单个句子的注意力加权,而忽略了两个句子之间的交互;还有部分模型虽然考虑了句子间的交互,但对句子间的交互建模得不够充分,未能融合不同粒度的交互信息,从而导致丢失某些重要匹配信息。
针对以上问题,本文提出了基于BERT预训练模型和多视角循环神经网络的文本匹配模型。该模型利用BERT获取句子表示向量,并应用BERT-Whitening方法来对句向量进行线性转换,获得优化的句向量表示;利用BERT获取句子中词汇的上下文词向量表示,并应用多视角循环神经网络模型来对句子对进行双向交互;最后,聚合BERT句向量及词粒度交互向量后得到文本对的语义匹配度。在电力运维领域的两个真实数据集上,通过与多种基于神经网络的文本匹配模型进行实验对比,实验结果验证了本文模型在文本匹配任务上的有效性。此外,本文模型在实际系统的应用中也有效提升了电力运维服务效率。
1 相关工作
文本匹配任务在语义检索中具有重要作用[11],早期研究主要基于特征工程来找出两句子的匹配关系。但特征工程方法不仅人工工作量大,还存在泛化性差的问题,在一个数据集上使用的特征很可能在另一个数据集上表现不好。
深度学习方法将特征抽取过程作为模型的一部分,直接从原始数据中抽取特征,不仅免去了手工设计特征的大量人工开销,还可以根据训练数据的不同而将模型方便地适配到各种文本匹配任务当中。因此,深度学习被广泛应用到文本匹配领域[12]。其中,以Siamese结构为代表的深度学习模型得到很好的发展,如微软提出的DSSM[13]模型,该模型通过全连接网络将查询语句和文档进行向量化,表达简单,匹配计算速度快,是最早的深度文本匹配模型,但DSSM忽略了文本之间的时序关系和空间关系。微软研究院后续提出的CDSSM[14]将DSSM中的全连接神经网络层换为卷积-池化结构,提升了文本匹配效果。文献[15]提出多视角循环神经网络(MV-LSTM)模型,通过BiLSTM获取句子不同位置的表示向量,然后将两句子不同位置的表示向量交互计算得到匹配矩阵,最后通过K-最大池化和全连接网络得到匹配值。
除了基于Siamese结构的序列匹配模型外,基于比较聚合的匹配模型也受到了关注。这类模型通过捕捉两个序列之间更多的交互特征来进行文本匹配。如aNMM[16]基于问题和答案的向量序列得到交互矩阵,再将CNN网络作用于交互矩阵,并且采用注意力加权方式来获得匹配模型。文献[17]采用了一种动态剪辑注意力机制,这种机制通过过滤权重较小的词来去除噪声,通过改变注意力计算方式提升答案选择的语义匹配模型性能。
在应用领域中,有学者针对通信领域[18]及医疗领域[19]研究了文本匹配任务,但目前在电力领域真实数据集上进行的文本匹配研究很少,本文在这一领域进行了探索,并将本文模型投入实际应用,取得了良好的应用效果。
2 模型介绍
本文提出基于预训练模型及多视角循环神经网络的文本匹配模型,模型结构如图1所示。本模型利用BERT预训练模型获取具有上下文语义的词向量及句向量,用BERT-whitening方法[20]对句向量进行线性变换操作,用MV-LSTM模型对词向量计算文本对间的交互向量,再对句向量及交互向量进行拼接后得到拼接向量,将其送入Highway网络[21]中进行优化,然后在输出向量的基础上通过全连接网络和Softmax操作得到结果。

图1 模型结构图Fig.1 Model structure diagram
2.1 BERT
Transformer[22]是Google在2017年提出的一个新型网络结构。不像CNN只能获取局部信息,也不像RNN需要逐步进行信息提取,Transformer通过自注意力机制能够直接获取文本序列的全局信息,可以并行化操作,提高训练效率,因此,被大量地使用在自然语言处理领域中,促进了以BERT[23]为代表的大规模预训练语言模型的发展。
Transformer中对句子的多头自注意力计算过程如(1)—(3)式所示。
(1)
(2)
M=(h1⊕h2⊕…⊕hn)WO
(3)
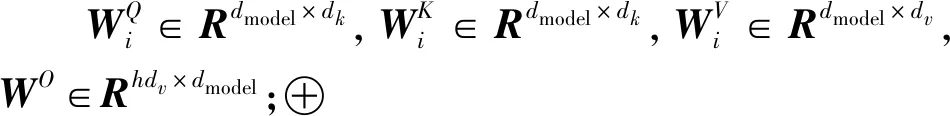
BERT通过使用Transformer结构的编码器模块,并应用掩蔽语言模型和下一句预测两个无监督预测任务进行预训练,能在大规模无监督语料上训练获得强大的文本表征能力,并获得词在不同语境下的含义。为了获得词在不同语境下的含义,本文模型先使用BERT对文本中的词汇进行嵌入表述,再得到句子序列的向量表示,对某一句子序列而言,本文获取词向量过程为
E=f([xCLS],x1,x2,…,xn,[xSEP])
(4)
(4)式中:f表示BERT模型编码操作,xi表示句子中的一个单词;[xCLS]表示句子开头字符,该标志对应的输出向量将作为整个句子的语义表示;[xSEP]表示模型识别句子的边界。根据输入获得输出为
E={eCLS,e1,e2,…,ei,…,en}
(5)
(5)式中,ei表示每个词的上下文相关词向量。
BERT由多个Transformer的编码器层组成,其结构如图2所示。

图2 BERT模型结构图Fig.2 BERT model structure diagram
图2中,Trm表示Transformer,每一层的Transformer由一个多头自注意力子层和一个全连接前馈神经网络子层组成,并在这两个子层中加入残差连接和层标准化计算。
2.2 BERT-whitening方法
BERT预训练模型在自然语言处理中取得了巨大的成功。然而,直接使用BERT模型中[eCLS]标记对应向量的句向量难以捕捉到句子的语义,在文本相似度任务中表现不好[24]。为了获得更好的句子向量表示,本文采用BERT-whitening方法来对BERT模型输出的[eCLS]进行线性转换,获得优化的句子向量表示。
句子向量间传统的余弦相似度值计算公式为
(6)

(7)
μ的求解公式为
(8)

(9)
则可以得到转换后的协方差矩阵为
(10)
新的协方差矩阵是单位矩阵,因而有
WTΣW=I
(11)
进而有
Σ=(WT)-1W-1=(W-1)TW-1
(12)
协方差矩阵Σ是一个正定对称矩阵,满足SVD分解为
Σ=UΛUT
(13)

(14)
BERT-whitening方法的算法流程如算法1所示。
算法1 BERT-whitening算法

2.计算U,Λ,UT=SVD(Σ)

4.fori=1,2,…,Ndo
6.end for
2.3 双向交互计算
对于文本匹配这样的序列匹配问题,之前的工作常常将两个待匹配的序列通过同种网络编码为两个向量,再依据这两个向量计算匹配度,但这种方式在整个编码过程中两个句子没有明确的交互,为避免这一问题,本文采用MV-LSTM模型来将两个句子在词粒度上对句子对间不同位置的交互进行建模。
根据BERT模型在序列匹配任务上的输入格式,将某一句子首尾分别加上[eCLS]和[eSEP]后拼接为一个序列,再将序列中的每个单词分别编码为词向量、段向量和位置向量,输入BERT进行编码,则BERT输出的序列E={eCLS,e1,e2,…,ei,…,en}对应于句子的BERT表示序列,将单词xi对应的向量表示ei作为某一时刻的输入xt输入到BiLSTM网络中,则LSTM单元得到词汇向量新表示的计算公式为
it=σ(Wi·[ht-1,xt]+bi)
(15)
ft=σ(Wf·[ht-1,xt]+bf)
(16)
(17)
(18)
ot=σ(Wo[ht-1,xt]+bo)
(19)
ht=ot*tanh(Ct)
(20)
(15)—(20)式中:ft表示遗忘门;σ是sigmoid函数;xt和ht-1分别是当前时刻输入和上一时刻隐藏状态;Wi、Wf和WC是学习的权重矩阵;bi、bc和bf为偏置值;it为输入门。
将词向量矩阵x=(x1,x2,…,xn)输入到BiLSTM网络中,则隐藏层的输出为
(21)
(22)
(23)
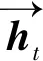
给定两个向量u和v,分别表示两个句子在双向LSTM中某一位置的输出向量,计算交互张量为
(24)
(24)式中:s是交互计算后得到的张量;M[1:c]是张量参数的一个切片;Wuv和b是线性计算部分的参数;f是一个非线性函数,计算式为
f(z)=max(0,z)
(25)
两个句子之间的匹配通常由一些强交互信号决定,使用k-最大池化操作来提取张量s中每个切片的前k个值以形成向量。这些向量进一步连接到单个向量q来作为两个序列间的交互向量。
2.4 Highway层
将两条句子x和y通过BERT输出的句子向量经过BERT-whitening方法转换后得到的句向量xCLS和yCLS,再与句子对间通过MV-LSTM获得的交互向量q拼接后形成向量υ,然后输入到Highway网络中进行处理。拼接计算式为
υ=[xCLS:q:yCLS]
(26)
Highway网络作为一种具有可学习门限机制的结构,可以在很大程度上缓解深层次网络训练困难的问题。受LSTM门结构理念的启发,Highway网络设计了转换门和携带门,通过这两个门来控制信息流,可以基于梯度的方法快速训练深层网络,对输入向量进行合适的特征变换,从而提升效果。
对于向量υ,转换门值T(υ)和携带门值C(υ)的计算式为
T(υ)=σ(Whυ+bh)
(27)
C(υ)=1-T(υ)
(28)
(27)—(28)式中:σ是非线性函数;Wh是权重矩阵;bh是偏移向量。输出向量C′计算式为
C′=τ(υ)*T(υ)+υ*C(υ)
(29)
(29)式中,τ为非线性函数。
2.5 输出结果
将输出向量C′输入到全连接神经网络,然后通过Softmax函数输出归一化后的各类别的概率分布,得到最终分类结果,即
O=Softmax(Wp×C′+bp)
(30)
(30)式中:Wp表示参数矩阵;bp为偏置。
2.6 损失函数
本文通过最小化交叉熵损失函数对模型参数进行更新,即
(31)
(31)式中:yi表示真实匹配值;pi表示模型预测的匹配值;N表示模型训练样本总数。
3 实 验
3.1 实验数据集
本文实验所用数据集来源于电力系统,包括两个数据集。第一个数据集是运维项目数据集,该数据集从某省电力运维服务项目管理系统中采集而来,通过对系统中2016—2019年运维服务项目的项目摘要文本进行整理后,得到2 000条样本,其中每条样本包含一对数据。通过人工方式进行标注,628条相似文本对样本,标签设为1;1 372条非相似文本对样本,标签设为0。另一个数据集为相似问句数据集,来源于某省电力运维知识库系统,通过采集系统中用户2019年的检索文本而得,并进行了人工标注。该数据集包括8 000条样本,每条样本由一对问句组成,如果为相似问句则标注为1,否则为0。数据集中相似问句对样本有4 000条。两个数据集的详细信息如表1所示。

表1 数据集概况Tab.1 Datasets overview
3.2 实验设置
本文模型采用google提供的中文版预训练BERT-Base模型(https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip)获取词向量。该预训练模型有12个Transformer层,768个隐藏层,12个自注意力头,参数110 M。文本长度128,超长截断,不足补零。采用Adam算法优化模型,学习率为1e-5,drop-out值设置为0.1。
3.3 评价指标
本文评价指标选取了准确率P、召回率RRECALL、F1值和准确率RAcc等指标来评价模型,计算公式为
(32)
(33)
(34)
(35)
(32)—(35)式中,NTP表示模型预测标签和真实标签都为1的样本数;NTN表示模型预测为0,真实标签也为0的样本数;NFP表示模型预测为1,真实标签为0的样本数;NFN表示模型预测为0,真实标签为1的样本数。
3.4 实验结果与分析
本文选取了如下模型进行比较。
1)CDSSM[14]。该模型通过卷积神经网络得到待匹配文本的向量表示,将这两个向量输入全连接网络中进行计算。
2)ACRII[25]。该模型将两个文本进行一维卷积,对卷积结果构造出一个二维交互矩阵,然后将交互矩阵输入卷积神经网络得到表示向量,最后将该向量输入到全连接神经网络得到匹配度。
3)MV-LSTM[15]。该模型使用BiLSTM获取两个句子序列中的每个位置的向量,再得到交互矩阵,通过K-最大池化和全连接网络计算两个句子的匹配度。
4)ESIM[26]。该模型将两个文本的词向量输入到BiLSTM网络后并结合注意力机制来得到双向注意力加权向量表示,通过分析文本词向量与注意力加权向量间的差异得到文本匹配度。
5)BIMPM[27]。该模型通过BiLSTM得到两个句子序列中不同位置的向量,再将两句子的向量进行相互比较得到不同粒度的匹配信息,并利用BiLSTM聚合比较结果,最后使用全连接神经网络计算文本匹配度。
6)DRCN[28]。该模型将词向量与字符向量拼接后输入通过Dense连接的循环神经网络,得到能表示上下文的语义向量,再将这个向量与注意力加权后的向量进行交互,最后通过全连接神经网络完成文本匹配度计算。
7)BERT-base。该模型利用BERT输出的eCLS向量作为句子向量表示,通过Softmax函数得出文本对间的匹配度。
8)BERT-BiLSTM。该模型利用BiLSTM对BERT输出的除eCLS的词向量表示作为输入,将BiLSTM的输出与BERT模型的eCLS向量拼接后输入全连接层,通过Softmax函数计算两句子的文本匹配度。
9)BERT-CNN。该模型与BERT-BiLSTM类似,只是将BiLSTM换成了CNN网络。
10)BERT-Whitening-Base。该模型对BERT输出的eCLS向量用BERT-Whitening方法进行转换后作为句子向量表示,通过Softmax函数得出文本对间的匹配概率。
11)BERT-Whitening-BiLSTM。该模型与BERT-BiLSTM类似,只是将BERT输出的eCLS向量用BERT-Whitening方法进行转换后作为句子向量表示。
12)BERT-Whitening-CN。该模型与BERT-CNN类似,只是将BERT输出的eCLS向量用BERT-Whitening方法进行转换后作为句子向量表示。
13)FMMI[29]。该模型通过提取文本中的多个粒度信息并结合注意力机制[30]来进行文本匹配。
两个数据集上的实验结果如表2—表3所示。

表2 运维项目数据集上的实验结果Tab.2 Experimental results on the operation and maintenance project dataset %

表3 相似问句数据集上的实验结果Tab.3 Experimental results on similar questions dataset %
从表2—表3可以得出以下结论。
1)本文模型各个指标均比其他模型更好。表2显示,本文模型的F1指标相比其他模型中的最好值提升3.30%,RACC指标相比其他模型中的最好值提升4.78%;表3显示,本文模型的F1指标相比其他模型中的最好值提升3.44%,RACC指标相比其他模型中的最好值提升3.69%。上述结果表明了本文模型的有效性。此外,本文模型在相似问句数据集上的F1和RACC指标值高于运维项目数据集上的对应指标值,原因是运维项目数据集样本的文本长度大约是相似问句数据集中的文本长度的7倍,而输入BERT模型的数据长度有限制,数据截断机制造成了信息的损失,一定程度上造成了模型在长文本上的性能损失。
2)本文模型与BERT-Whitening-Base模型相比,获得了性能的大幅提升。这说明了本文模型的句子对双向交互机制的有效性,也表明对于文本匹配中考虑两句子之间双向交互的计算有利于提升模型效果。此外,其他模型虽然也对两句子进行了交互,但本文模型相比于其他模型更有效,原因在于本文模型结合了句子级别的向量表示与句子间词粒度的交互向量,并充分发掘了大规模预训练语言模型的表示能力。
3)从向量表示的角度,依据BERT-Whitening-Base与BERT-Base、BERT-Whitening-BiLSTM与BERT-BiLSTM、BERT-Whitening-CNN与BERT-CNN的实验结果值来看,以BERT-Whitening方法为基础而获得的句子向量表示方式在两个数据集上的各个指标上均比以BERT模型输出的eCLS句子向量表示的结果有一定的提升。这说明BERT-Whitening方法所得到的句向量相比于BERT模型得到的句向量更能代表句子语义,也说明BERT-Whitening方法通过对句子向量进行转换以强制使其具有各向同性特性后,能得到更优化的句子表示向量。
4 结束语
针对文本匹配方法中存在的问题,本文提出了基于BERT预训练模型和句子对之间双向交互机制的文本匹配模型。该模型基于BERT模型的输出向量来进行线性转换,获得句子的向量表示,并结合两个句子在词粒度上细粒度的交互向量,通过Highway网络进行优化后,计算文本匹配度。实验验证了本文模型的可行性和有效性。目前,本文模型已投入实际应用,有效地提升了电力运维服务的效率。下一步研究将尝试扩大数据集的规模,并采集电力领域其他业务系统中的数据来构建新的数据集,提升文本匹配模型性能,并通过在实际系统中的应用来进一步增强其实用性。
