交织多址接入系统定点Logistic交织序列生成算法
2023-06-26付仕明陈畅霖吴广富向碧群
付仕明,陈畅霖,吴广富,向碧群
(1.重庆第二师范学院 人工智能学院,重庆 400065;2.重庆邮电大学 通信与信息工程学院,重庆 400065;3.重庆移通学院 大数据与计算机科学学院,重庆 401520)
0 引 言
交织多址接入(interleave division multiple access,IDMA)[1]技术作为第六代移动通信系统备选多址接入技术,具有良好的抗多址接入干扰(multiple access interference,MAI)性能和较低的多用户检测算法复杂度,与码分多址接入(code division multiple access,CDMA)、正交频分复用接入(orthogonal frequency division multiple access,OFDMA)[2]、功率域非正交多址接入(power domain non-orthogonal multiple access technology,PD-NOMA)[3]、大规模多输入多输出(multiple input multiple output,MIIMO)[4]等技术结合组成混合多址接入系统,可以充分利用码域、时频域、功率域、空域等资源,显著提高移动通信系统容量和能效[5]。
IDMA技术在发送端采用不同交织器区分用户,在接收端采用逐码片(chip)迭代多用户检测技术,将用户间干扰高斯白噪声化,以提高多用户检测的有效性[6]。IDMA系统交织器的有效设计,不仅关系到发送端和接收端算法复杂度,而且关系到接收端系统性能。交织器的性能指标[7]具体包括:①距离特性:增加原始序列相邻码片有效距离,可以增加数据随机性,提高系统抗突发错误能力;②对称交织:交织和解交织结构相同,可共用软硬件资源;③相关特性:相同交织序列的自相关足够大,不同交织序列的互相关足够小,提高用户抗MAI性能;④性能稳定:由随机序列生成的交织序列,无法保证所有交织序列都具有良好性能;⑤生成简单:占用尽可能少的存储空间和计算资源。
当前IDMA系统交织器的生成算法包括:随机交织器、S-Random交织器、指数交织器、树形交织器、二维交织器和Logistic交织器[8]。其中,随机交织器为每个用户分配弱相关的交织器,在(解)交织过程中需要标记比特位置,从而需要消耗大量的存储空间和计算复杂度。当信息长度足够长时,可显著提升系统容量,但多用户检测过程的存储空间和计算复杂度均十分庞大[9]。S-Random交织器能保证随机性和距离特性,但可用交织器却非常少[10]。树形交织器在一定程度上降低了随机交织器的计算复杂度[11]。英国生态数学家R.May提出结构简单、初值敏感、计算效率高、类高斯白噪声的Logistic系统,作为经典混沌动力学系统,不但便于现场可编程逻辑门阵列(field programmable gate array,FPGA)实现,而且易于推广到其他混沌系统[12]。Logistic混沌系统可以生成数量众多、非相关、类随机而又确定可再生的Logistic交织器,但需要逐码片生成,算法时延较大[13]。
为满足算法长度和时延要求,通常基于FPGA迭代方式生成Logistic序列,每次迭代生成一个码片数据[6]。迭代过程中的乘法运算,一般基于移位相加法或查表法(look up table,LUT)[14]。基于移位相加法的乘法器时延太大[15],而基于LUT的乘法器则要求输入数据量化比特长度是2的整数次幂,当其不是2的整数次幂时,必须成倍增加乘法器输入数据量化比特长度[16]。
为了克服传统基于FPGA迭代方式生成Logistic序列生成过程时延问题和比特长度的限制,充分利用Logistic交织距离、相关、平衡度等特性,本文提出了任意量化比特长度的定点Logistic交织序列FPGA生成算法。该算法首先利用Logistic混沌系统李雅普诺夫指数,确定最小量化比特长度;然后基于平衡度和互相关门限,确定序列开始位置和初值;再采用查表法构建非对称基本乘法器,并采用移位相加法计算Logistic序列生成过程中乘法器;最后将双极性化的定点Logistic序列用于(解)交织过程。仿真结果验证了本文算法的有效性。
1 IDMA系统模型

在接收端,基本信号估计器(elementary signal estimator,ESE)和信道译码的输出数据是发送数据xk的对数似然比。ESE利用其他用户信道译码返回的外部对数似然比(log-likelihood ratios,LLR),估计目标用户的发送数据[17]。
图1中,K个复用用户总接收数据表示为
r(j)=hkxk(j)+ζk(j),j={1,2,…,J}
(1)
(1)式中:hk为用户k的信道冲激响应;xk(j)为用户k的发送数据;J为最大用户数据长度;hkxk(j)表示目标用户接收数据;ζk(j)表示目标用户k的干扰用户信号与信道高斯白噪声之和。
IDMA系统多用户检测过程[18]可概括为:首先利用信道译码并再次交织后的数据lESE(xk(j))更新发送数据均值E(xk(j))和方差Var(xk(j));然后利用接收数据估计无线信道冲激响应hk,采用无线信道冲激响应、发送数据均值、方差计算接收信号均值E(r(j))和方差Var(r(j));最后利用无线信道冲激响应、发送数据、接收数据均值和方差计算发送数据eESE(xk(j))。重复上述过程,直到完成预定义的迭代次数。IDMA系统多用户检测过程用(2)式—(6)式表示为
(2)
Var(xk(j))=1-(E(xk(j)))2
(3)
(4)
(5)
(6)
(2)式—(6)式中,σ2=N0/2为加性高斯白噪声(additive Gaussian white noise,AWGN)的方差。
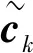
(7)
第k个用户接收数据eESE(xk(j))与Logistic序列zk相乘完成解交织功能,表示为
(8)

从以上过程可以看出,有效生成Logistic序列是IDMA系统多用户检测算法核心。
2 IDMA系统交织算法
在IDMA系统中,首先需要生成定点Logistic序列,然后将其应用到接收端多用户检测(解)交织过程。其中,生成定点Logistic序列过程,又需要首先利用混沌状态、平衡度、相关等特性查找合适的定点Logistic序列;再采用查表法和移位相加法设计便于FPGA实现的定点Logistic序列,以降低序列生成时延。
2.1 定点Logistic序列生成算法
只有当量化比特长度足够长时,混沌序列才可以看作随机序列。但在实际应用中,受计算机硬件和成本制约,无法获得无穷大的量化比特长度,因此,实际得到的混沌序列是具有周期性的伪随机序列[21]。
为得到满足平衡度、自相关和互相关要求的定点Logistic序列,首先利用李雅普诺夫指数确定最小量化比特长度;然后计算平衡度,确定序列开始位置;再双极性化Logistic序列;最后计算互相关,并输出满足要求的Logistic序列。定点Logistic序列生成过程如图2所示,包括以下步骤。

图2 定点Logistic序列生成过程Fig.2 Fixed-point Logistic sequence generation process
步骤1初始化第k个用户的第j个码片的初始值zk(j)=⎣2L·a」/2L,a取值为[0,1],⎣·」表示向下取整,L表示量化比特长度。定点Logistic序列的第j+1个码片表示为

(9)
(9)式中:码片zk(j)∈[0,1];系统参数μ∈(0,4],当μ∈(3.571 488,4]时,为混沌系统[22]。
步骤2采用(10)式计算李雅普诺夫指数,确定最小量化比特长度Lmin。
(10)
首先将最小量化比特长度L初始化为1。当λ<0时,累加L=L+1,并依次计算(9)式、(10)式。当λ>0时,Logistic序列处于混沌状态,此时的L值或增加一个余量Δ后的L+Δ值作为最终的最小量化比特长度Lmin,并将其应用到(9)式,计算码片长度为n·J的Logistic序列,其中,n取正整数。
步骤3计算平衡度,确定Logistic序列开始位置。
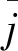
(11)
步骤4双极性化Logistic序列。
对满足平衡度要求的Logistic序列,采用(12)式或(13)式进行双极性化。
zk(j)⟸1-2「zk(j)-0.5⎤
(12)
zk(j)⟸2「zk(j)-0.5⎤-1
(13)
(12)式—(13)式中,⟸表示赋值运算。
累加k=k+1,并重复执行步骤3—4,直到k=K。
步骤5计算互相关,输出满足要求的Logistic序列。
Logistic序列zk(j)和zk′(j)的互相关系数表示为
(14)
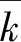

采用步骤1—5,可生成满足混沌状态、平衡度、自相关、互相关要求的定点Logistic序列zk(j),并将其应用于(7)式、(8)式交织和解交织过程。
为了更好地说明步骤1—5的执行过程,算法1给出了程序伪代码。
算法1定点Logistic序列生成算法
forL=1
初始化用户数k=1,变量a,量化比特长度L和码片序号j=0,计算zk(j)
forj=0:J
利用(9)式,计算zk(j+1)
j=j+1
end
采用(10)式,计算λ
ifλ<0
L=L+1
else
输出此时L值或L+Δ值作为最小量化比特长度Lmin
end
end
将Lmin替换L,计算(9)式
fork=1:K
初始化变量a,量化比特长度L和码片序号j=0,计算zk(j)
forj=0:n·J
利用(9)式,计算zk(j+1)
j=j+1
End



Else
break
end
end
k=k+1
end

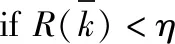
输出第k和第k′个Logistic序列
end
end
从(9)式可以看出,定点Logistic序列生成算法核心是任意量化比特长度乘法运算。
2.2任意量化比特长度乘法器
为便于描述,下面仅以单用户比特长度L=34的Logistic序列生成过程为例说明任意量化比特长度乘法器生成过程,如图3所示,具体包括以下步骤。

图3 任意量化比特长度乘法器生成过程Fig.3 Arbitrary quantization bit length multiplier generation process
步骤1初始化Logistic序列z(j)。
初始化系统参数μ,Logistic序列序号j=0,Logistic序列最大长度J,量化比特长度L,Logistic序列初值z(0)。
步骤2构建基本LUT乘法器。
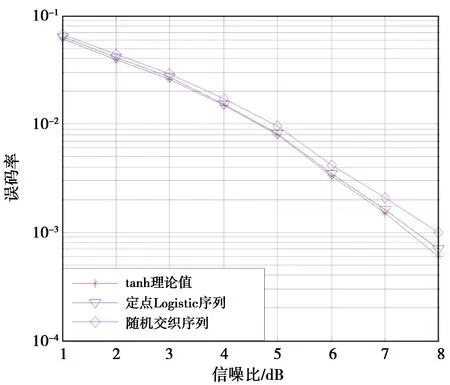
构建4种基本LUT乘法器,即UII、UIQ、UQI和UQQ。其中,I和Q分别表示基本LUT乘法器的2个输入数据量化比特长度,即I={1,2,…,Imax},Q={1,2,…,Qmax},Imax 基本LUT乘法器的构建方法不是唯一的,在具体应用中,需要综合考虑FPGA型号、存储量、时延等影响因素。下面以L=34,I=5,Q=6为例,详细说明基本LUT乘法器的构建过程。基本LUT乘法器U55的2个输入数据比特长度为5,取值为{0,1,…,31},输出数据比特长度为10,取值为{0,1,…,1 023}。同理,可得U56、U65和U66输入与输出的关系。 步骤3计算乘法器输入。 为便于迭代运算,(9)式可以重写为 (15) 当j=0时,令乘法器输入数据为A=⎣2L·z(0)」和B=2L-A;当j≠0时,更新后的乘法器的输入数据A=z(j+1)和B=2L-A。 步骤4划分基本LUT乘法器。 比特长度为L=34的乘法器输入数据A和B,由4组长度为6比特和2组5比特的子数据组成,即n=4,Q=6,m=2,I=5。典型情况下输入数据与子数据之间关系,如图4所示。4组长度为6比特子数据分别表示为A6,A5,A4,A3和B6,B5,B4,B3,2组比特子数据分别表示为A2,A1和B2,B1。很显然,由上述子数据组成乘法器输入数据A和B,有很多组合情况。为便于描述,假设比特数较多的子数据置于左侧,比特数较少的子数据置于右侧。不失一般性,假设左侧比特为高比特位,右侧比特为低比特位。采用子数据A6,…,A2,A1和B6,…,B2,B1分别表示乘法器输入数据A和B。 图4 乘数器输入数据量化比特次序Fig.4 Quantization bit order of the counters input data 步骤5基本LUT单元移位并累加。 将乘法器输入数据A和B,乘法过程采用基本LUT乘法器表示;将各基本LUT乘法器输出根据其所在比特位置移位后相加,输出量化比特长度为2L的乘法结果D35=A·B。 将Am+n,…,A2,A1分别与Bm+n,…,B2,B1进行相乘,共得到(m+n)2个基本LUT乘法器。将A1与Bm+n,…,Bm+1,Bm,…,B1相乘,结果分别记为Cm+n,…,C1,将A2与Bm+n,…,Bm+1,Bm,…,B1相乘结果分别记为C2m+2n,…,Cm+n+1,以此类推,将其余相乘结果记为Cm2+n2+2mn,…,C2m+2n+1。将Cm2+n2+2mn,…,C1根据各自位置,分别左移如下比特0,I,mI,mI+Q,mI+2Q,…,58,依次分级两两相加,最终得到2L位乘法器输出结果,如图5所示。 图5 移位相加法乘法器Fig.5 Shifted phase addition multiplier 累加过程也可以表示为(16)式,大括号内和单行的累加运算为同级运算。 D32=D28+D29,D33=D30+D31 (16) D34=D32+D33 D35=D34+D27 为仿真分析所提IDMA系统定点Logistic序列交织算法的性能,以随机交织算法[23]和随机交织序列[20]作为对比算法,仿真参数如表1所示。 表1 仿真参数Tab.1 Simulation parameters 下面重点分析算法复杂度、浮/定点算法误码率 (bit error ratio,BER)性能、Logistic序列长度与BER性能之间关系。 基于Logistic序列进行(解)交织的IDMA系统,算法复杂度主要集中在Logistic序列的生成过程。而(解)交织过程,只涉及序列乘法,并且双极性化后的Logistic序列为±1,因此,序列乘法相当于取待(解)交织序列的相反数,该部分算法复杂度和存储空间可以忽略。由于移动用户只需要计算或存储当前物理资源下复用用户交织序列,Logistic序列的生成过程可以采用仿真软件提前生成,此时算法复杂度也可以忽略。只有当基站为若干移动用户进行动态资源分配时,才需要基于FPGA方式实时生成大量Logistic序列,以降低数字信号处理时延。 采用延迟为6的1/2编码速率的卷积码,数据长度为1 024,Logistic序列长度为1 024,采用2.2节定点乘法过程。图6给出IDMA系统tanh理论值、浮点Logistic序列和量化比特长度为34的定点Logistic序列的BER性能曲线。从图6可以看出,浮点Logistic序列相对于tanh理论值的BER性能损失可以忽略;定点Logistic序列相对于浮点Logistic序列的BER性能损失低于0.5%,可以满足大多数移动通信需求。 图6 浮点、定点Logistic交织算法和tanh理论值性能Fig.6 Performance of floating point,fixed-point Logistic interleaving algorithm and tanh theoretical value 为获得交织序列长度对IDMA系统性能的影响情况,图7给出了量化比特长度为64和1 024时,定点Logistic序列、随机交织算法和随机交织序列的BER性能。从图7可以看出,基于随机交织序列的IDMA系统性能远低于其他2种算法,主要原因是该算法对原始数据引入的随机性不够,无线信道造成的影响成为次要因素,因此,该算法的BER不随SNR的增长而降低,而是保持平稳水平。定点Logistic序列相对于随机交织算法,性能损失不大。在SNR≤3 dB情况下,定点Logistic序列算法具有较好的相关性,因此,接收端多用户检测对SNR的消除效果较好,此时定点Logistic序列性能略优于随机交织算法。在SNR≥4 dB情况下,定点Logistic序列之间的互相关性降低,不同用户之间的多址接入干扰随之增大;而此时随机交织则可以完全打乱原序列,因此,随机交织算法拥有更好的BER性能。 图7 序列长度为64、1 024时不同算法性能Fig.7 Performance of different algorithms when the sequence length is 64 and 1 024 本文提出IDMA系统任意量化比特长度的定点Logistic交织序列FPGA生成算法,不仅可以充分利用混沌、平衡度、相关等特性,而且可以降低(解)交织过程存储空间和计算复杂度。该算法可以基于FPGA产生任意量化比特长度的定点Logistic序列,可以充分利用FPGA硬件资源,在序列长度较短的情况下,可以获得较好的误码率性能。本文所提算法有利于IDMA技术和基于IDMA的混合多址接入技术的发展和应用。

3 仿真分析


4 结束语
