消费者异质性对推荐系统的影响研究与仿真
2023-06-25陈运昌赵军
陈运昌 赵军

摘要:现有商品推荐系统的研究大多通过改进推荐算法以提升推荐效果。很少有研究从消费者视角,探究当面对同一推荐系统,消费者异质性对推荐效果的影响。基于深度强化学习算法,构建细粒度感知消费者行为的推荐系统;从消费者属性和行为模型两个角度刻画消费者异质性;基于多Agent技术组合推荐系统Agent与消费者Agent,构建商品推荐仿真模型。仿真结果表明,消费者异质性对企业利润、消费者满意度、点击率均能产生较大影响。
关键词:推荐系统; 消费者异质性; 多Agent技术; 建模与仿真; 深度强化学习
中图分类号:TP391.9 文献标识码:A
文章编号:1009-3044(2023)13-0058-05
开放科学(资源服务)标识码(OSID)
0 引言
商品推荐系统会根据消费者的浏览历史、交互行为、个人信息等数据,结合商品信息,为异质消费者提供不同的商品推荐[1]。基于深度强化学习(DRL)的推荐系统可以建模用户行为序列、捕捉动态偏好、最大化长期反馈,在商品推荐领域得到广泛研究。现有研究大多探究如何改进DRL算法,使推荐系统可以达到更好的推荐效果。然而,很少有研究明确讨论消费者异质性对推荐效果的影响。本文从消费者属性和行为模型两个角度刻画消费者异质性,并基于DRL建立推荐系统与消费者交互,从企业利润、消费者满意度、点击率三个方面,深入探讨消费者异质性对推荐效果的影响。
目前,国内外对推荐系统研究较多。在提升基于DRL的推荐系统性能方面,潘华丽等人[2]引入预训练模型和注意力机制实现多模态特征融合,结合DRL算法有效提升了个性化推荐效果;华勇等人[3]将多轮对话推荐系统与DRL相结合,考虑消费者对商品的多粒度信息反馈,有效提升了推荐成功率。在消费者异质性研究方面,程永生等人[4]针对消费者异质社交能力展开研究,基于效用理论分析消费者的购买和推荐行为,探讨消费者社交能力对企业利润的影响;杨敏等人[5]通过偏好特性与敏感特性两个方面构建旅客异质性,将异质性画像与DRL算法相结合,有效提升了推荐算法性能。动态的实验环境非常重要,多Agent建模与仿真方法已广泛应用于商品推荐的研究[6-7],通过对异质且独立的消费者Agent及推荐系统Agent建模,可以在抽象层面上合理反映消费者和企业行为,并可以降低模型训练与测试的成本。综上,本文从消费者属性和行为模型两个角度刻画消费者异质性,基于DRL构建推荐系统,基于多Agent建模与仿真方法实现动态环境,探讨消费者异质性对推荐效果的影响,具有很大的理论与应用价值。
2 基于深度强化学习的推荐系统设计
消费者行为是消费者异质性的表现方式,为了更好地探究消费者异质性对推荐效果的影响,本文基于DRL建立可以细粒度感知消费者行为的推荐系统,将消费者对商品i产生的跳过、点击、加购行为映射为消费者满意度和企业利润,并作为商品i产生的环境奖励,根据环境奖励优化推荐系统。
2.1 消费者行为映射
首先介绍消费者行为映射为消费者满意度和企业利润的方式。消费者与推荐列表中的商品i交互产生满意度[sati],满意度的计算如公式(1) 所示:
[sati=0, x=跳过α·Ii+(1-α)·quality+noise, x=点击、加购] (1)
其中,x表示消费者对商品i采取的行为,包括跳过、点击、加购。当消费者跳过商品i时,不产生满意度;当消费者点击或加购商品i时,根据公式映射为满意度sati,其中α表示异质性中的消费者感性,体现了异质性对满意度的影响。公式计算與文献[8]相同,在此不再赘述。本文将sati看作环境奖励ri1。
消费者跳过、点击和加购行为,需要经过行为转化过程,才能映射为企业利润。消费者跳过、点击或加购推荐列表中的商品i,不会产生利润,只有购买商品才能产生利润。考虑到购买行为的稀疏性,推荐系统很难单纯依靠购买产生的利润来优化推荐策略[9],故本文引入消费者行为转化率,建立跳过、点击、加购这些相对频繁的行为与购买行为之间的联系,以更好地计算商品i的利润Vi,企业利润Vi的计算公式如公式(2) 所示:
[Vi(x,i)=0, x=跳过150price(i)·1λ, x=点击120price(i)·1λ, x=加购] (2)
其中,price(i)表示商品i的价格。根据电商用户行为分析[10],消费者的点击转化率在2%左右,加购转化率在5%左右,因此[150]和[120]分别表示点击、加购的行为转化率;[1λ]为归一化参数,这里λ的取值为[120max(price(i))]。本文将Vi看作环境奖励ri2。
综上,消费者与商品i交互,产生的环境奖励包括消费者行为映射的满意度ri1和映射的企业利润ri2,则消费者对商品i的行为映射的环境奖励ri如公式(3) 所示:
[ri=0.5·ri1+0.5·ri2] (3)
其中,0.5为是归一化处理的参数。ri、ri1、ri2∈(0,1)。
2.2 构建基于深度强化学习的推荐系统
本文根据Slate-Q[8]算法构建推荐系统。Slate-Q是Ie E等人设计的用于列表推荐的DRL算法,其最大特点是可以计算列表中单个商品i的Q值Qi,并根据Qi计算商品分数以构建推荐列表,如公式(4) :
[Scorei=Ii·Qi] (4)
及計算整个推荐列表的Q值,如公式(5):
[Q(s,A)=i∈AP(i | s,A)Qi] (5)
借助于Slate-Q的这种特性,再考虑到Qi取决于商品产生的环境奖励ri,可以推断出:结合2.1提出的商品i环境奖励ri的计算公式,Slate-Q可以细粒度掌握消费者行为,根据具体的消费者行为优化推荐系统,提升推荐效果。
在此基础上,本文修改了Slate-Q的推荐动作A的环境奖励R及Q值计算公式。推荐动作A中包含多个商品i,则动作奖励R如公式⑹所示:
[R=i∈Ari] (6)
推荐动作A的Q值[Q(s,A)]的计算公式如公式(7)所示:
[Q(s,A)=i∈AQi] (7)
Slate算法结合公式(4) 与top-k算法构建推荐动作A,结合公式(6) 和(7) 与下文的商品推荐仿真模型,评价推荐动作A。
3 消费者异质性设计
3.1 消费者异质性设计
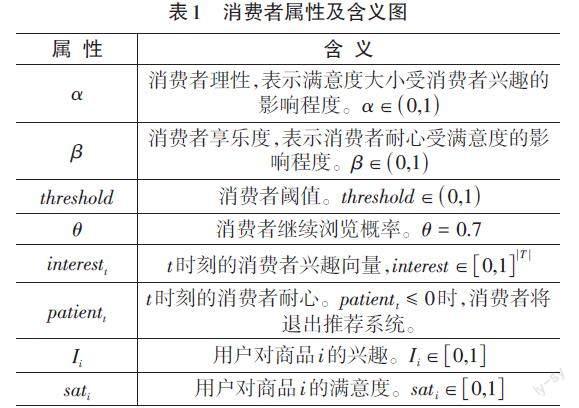
本文根据RecSim[11]中的用户模型设计消费者异质性,从消费者属性与消费者行为模型两个方面,细粒度刻画消费者异质性。消费者属性及含义如表1所示:
消费者属性包括静态属性和动态属性。静态属性包括ɑ、β、threshold、θ,构建了消费者的异质性,其中threshold又分为消费者点击阈值thresholdI和加购阈值thresholdsat,两个阈值及θ的作用在下文消费者行为模型介绍。动态属性包括interestt、patientt,Ii、sati,其中interestt、patientt表示消费者的实时状态,Ii、sati用于下文的消费者行为模型,影响行为和状态转换。4个动态属性计算公式与文献[10]相同,在此不再给出。
消费者行为模型决定了当消费者面对推荐列表中的商品时,做出跳过、点击、加购中的哪一个行为。文献[8]中提出使用MNL和CL作为消费者行为模型。根据消费者行为理论,推荐系统中消费者行为具有位置偏向性和吸引偏向性,这两种模型均忽略了这种情况,且消费者只能点击一次与事实不符。本文将Ii、sati两个动态属性与DBN(动态贝叶斯网络)结合,建立消费者行为模型,模型结构如图1所示:
我们将[Ii?thresholdI]看作消费者被商品i吸引,将[sati?thresholdsat]看作消费者很满意商品i,将上图分解为消费者行为规则如表2所示:
3.2 基于多Agent的商品推荐仿真模型
本文利用RecSim[11]推荐系统仿真平台,基于多Agent技术建立商品推荐仿真模型,模型包含异质性消费者Agent、推荐系统Agent和商品,在仿真环境下探究消费者异质性对推荐效果的影响。其中,消费者Agent为3.1建立的异质性消费者,推荐系统Agent为2.2构建的推荐系统。消费者Agent需要与商品列表交互,才能体现出消费者异质性。因此商品仿真模型的设计同样重要。本文根据RecSim中的文档模型建立商品仿真模型,本模型可以生成任意数量的商品,商品具体参数与含义如表3所示:
T为商品主题集,[topic∈T],[T=5],即本文设置五种商品主题,每个商品只属于一种主题。price为商品价格,服从分布U(a,b),主题不同价格也不同:topic0的商品价格在[10,50]之间,topic1在[50,100]之间;topic2在[100,150]之间;topic3在[150,200]之间;topic4在[200,250]之间。
综上,本文基于改进Slate-Q算法构建可细粒度感知消费者行为的推荐系统,从消费者属性与消费者行为模型两个方面构建消费者异质性,基于多Agent技术建立商品推荐仿真模型。接下来进行仿真实验,探讨消费者异质性对推荐效果的影响。
4 仿真实验
4.1 仿真过程描述
本文将消费者开始浏览至退出推荐系统的整个过程称为一个交互回合。在一次推荐过程中,推荐系统会产生推荐列表,消费者会与列表中的商品进行交互,产生企业利润及消费者满意度、点击率,并改变自身状态。一个交互回合会重复上述推荐过程,直到消费者退出推荐系统。消费者异质性会导致消费者状态及动作不同,进而导致产生的企业利润等推荐效果不同。因此,对一个交互回合进行仿真,可以探究消费者异质性对推荐效果的影响。
4.2 仿真实验设置
4.2.1实验指标设置
本文设置三个实验指标以展示推荐效果,(8)(9)(10)为计算公式。E表示一个交互回合中涉及的商品集合。
利润V:
[V=i∈EVi] (8)
该指标表示消费者在一个交互回合中产生的总利润。其中,Vi表示消费者与商品i交互产生的利润。
消费者满意度Sat:
[Sat=i∈Esati] (9)
该指标表示消费者在一个交互回合中产生的总满意度。其中,sati表示消费者与商品i交互产生的满意度。
消费者点击率Click_rate:
[Click_rate=i∈EclickiE] (10)
该指标表示消费者在一个交互回合中产生的点击率。其中,clicki表示消费者是否点击了商品i,是为1,不是为0;|E|表示一个交互回合中总的商品个数。
4.2.2 输入参数设置
消费者Agent模型需设置7个参数。五个静态属性默认参数值:α=0.5,β=0.1,thresholdI=0.5,thresholdsat=0.7,θ=0.7;两个动态属性初始参数值:t=0时,interestt=[1, 0.8, 0.5, 0.2, 0],patient=10。
企业Agent模型需设置3个参数。候选商品集D的大小|D|=20;推荐列表长度slate_size=4;折扣因子γ=1。
总之,在设置了实验指标和输入参数后,进行了40 000个时间步的模拟,其中包含了大约3 000~4 000个交互回合,以训练本文的基于DRL的推荐系统,并进行100个交互回合的测试,以探讨消费者异质性对推荐效果的影响。
4.3 消费者异质性实验
探究消费者异质性对推荐效果的影响,主要是探究消费者理性α、消费者享乐度β、兴趣阈值 interest_threshold、满意度阈值sat_threshold这些静态属性对推荐效果的影响。在接下来的实验中,本文先按照默认值运行一次实验作为对照组,之后修改某一种静态属性的取值,其余属性取默认值,运行试验记录指标变化,以探讨消费者异质性对推荐效果的影响。
4.3.1 消费者理性α
消费者理性表示决定消费者对商品的满意度是更看重对商品的兴趣还是商品本身质量。参数越高,表示满意度更看重商品质量;参数越低,表示满意度更看重对商品的兴趣。α依次取值0.5/0.2/0.8,其余属性取默认值,其中0.5为对照组实验,三次实验结果如表4所示。
橙、蓝、红线分别代表三个取值的实验结果。利润V和满意度Sat指标下,红线表现最差,橙和蓝线较接近;点击率Click_rate指标下,蓝线表现最差,橙线略优于红线。可见,更理性的消费者(α=0.8) ,其在一个交互回合中虽然有较高的点击率,但仅能产生较少的企业利润和自身满意度;不理性的消费者(α=0.2) ,其在一个交互回合中虽然点击率不高,但能产生的企业利润和自身满意度较高。
4.3.2 消费者享乐度β
消费者享乐度表示消费者耐心受满意度的影响程度,当β取值较大时,满意度对耐心的影响较大,显著增加消费者的交互回合长度。β依次取0.5/0.2/0.8,其余属性取默认值,其中0.5为对照组实验,三次实验结果如表5所示。
橙、蓝、红线分别代表三个取值的实验结果。三幅图整体来看,蓝、橙、红线的长度依次增加,可见享乐度β越高,消费者的回合长度越长。利润V和满意度Sat指标下,蓝线表现最差,橙和红线较接近;点击率Click_rate指标下,蓝线和红线表现均差与橙线。可见,享乐度更高的消费者(β=0.8) ,在一个交互回合中能产生较高的企业利润和自身满意度,但点击率较低;享乐度更低的消费者(β=0.2) ,企业利润、自身满意度及点击率均较差。
4.3.3 兴趣阈值 interest_threshold
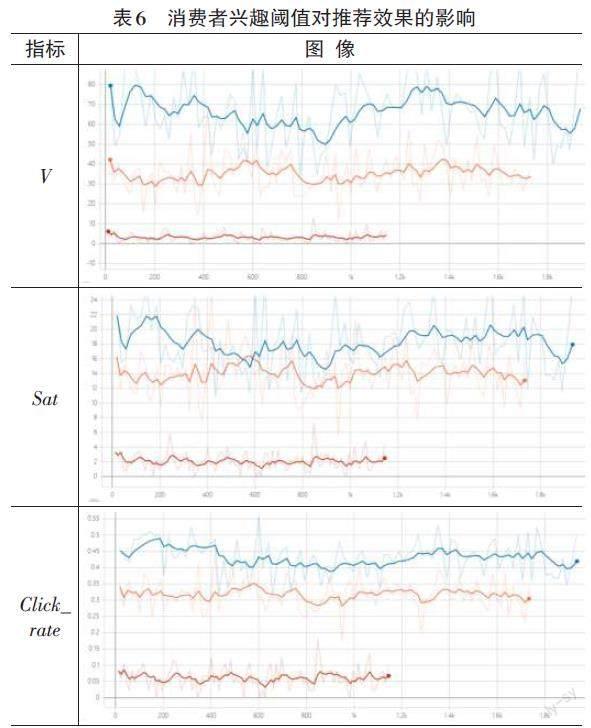
兴趣阈值表示消费者被商品吸引点击的阈值,满意度阈值越高,消费者应该越难点击。interest_threshold依次取值0.5/0.2/0.8,其余屬性取默认值,其中0.5为对照组实验,三次实验结果如表6所示。
橙、蓝、红线分别代表三个取值的实验结果。可见,消费者兴趣阈值参数在很大程度上影响推荐效果。兴趣阈值越低,一个交互回合内产生的企业利润、消费者自身满意度、点击率以及回合长度越高。
4.3.4 满意度阈值sat_threshold
满意度阈值表示消费者将商品加入购物车的阈值,满意度阈值越高,消费者应该越难加购。sat_threshold依次取值0.7/0.5/0.9,其余属性取默认值,其中0.7为对照组实验,三次实验结果如表7所示。
橙、蓝、红线分别代表三个取值的实验结果。利润V指标下,红线表现最差,蓝线略低于橙线;满意度Sat和点击率Click_rate指标下,蓝色线表现最差,蓝线与橙线表现相近。可见,满意度阈值偏高的消费者(sat_threshold=0.9),其在一个交互回合中产生的自身满意度和点击率较高,但仅能产生较少的企业利润;满意度阈值偏低的消费者(sat_threshold=0.5),其在一个交互回合中产生的企业利润较高,但其产生的自身满意度和点击率均很低。
5 总结与展望
本文研究了消费者异质性对推荐系统推荐效果的影响。基于改进Slate-Q算法构建可细粒度感知消费者行为的推荐系统,从消费者属性与行为模型两方面构建消费者异质性,基于多Agent建模与仿真方法建立商品推荐仿真环境。仿真实验表明,消费者理性、享乐度、兴趣阈值、满意度阈值等异质属性,均能对一个交互回合中的企业利润、消费者自身满意度、点击率产生重要影响。
参考文献:
[1] 宋倩.基于关联规则算法的电子商务商品推荐系统设计与实现[J].微型电脑应用,2021,37(10):205-208.
[2] 潘华莉,谢珺,高婧,等.融合多模态特征的深度强化学习推荐模型[J/OL].数据分析与知识发现:1-18[2023-02-10].http://kns.cnki.net/kcms/detail/10.1478.G2.20220907.1507.008.html.
[3] 姚华勇,叶东毅,陈昭炯.考虑多粒度反馈的多轮对话强化学习推荐算法[J].计算机应用,2023,43(1):15-21.
[4] 程永生.基于消费者异质性社交能力的推荐奖励策略[J].运筹与管理,2020,29(12):231-239.
[5] 杨敏,李宏伟,任怡凤,等.基于旅客异质性画像的公铁联程出行方案推荐方法[J].清华大学学报(自然科学版),2022,62(7):1220-1227.
[6] Ghanem Nada..Balancing consumer and business value of recommender systems:a simulation-based analysis[J].Electronic Commerce Research and Applications,2022(55):101195.
[7] Zhou M, Zhang J, Adomavicius G. Longitudinal Impact of Preference Biases on Recommender Systems' Performance[J]. Kelley School of Business Research Paper, 2021(10).
[8] Ie, Eugene et al. SlateQ - A Tractable Decomposition for Reinforcement Learning with Recommendation Sets[C]. International Joint Conference on Artificial Intelligence.(2019): 2592-2599.
[9] Pei C H,Yang X R,Cui Q,et al.Value-aware recommendation based on reinforcement profit maximization[C]//WWW '19:The World Wide Web Conference.May 13 - 17,2019,San Francisco,CA,USA.New York:ACM,2019:3123-3129.
[10] 郝浩宇,任杰成.电商平台用户行为分析系统研究[J].信息与电脑,2021,33(21):80-82.
[11] Ie E,Hsu C W,Mladenov M,et al.RecSim:a configurable simulation platform for recommender systems[EB/OL].2019:arXiv:1909.04847.https://arxiv.org/abs/1909.04847.
【通联编辑:李雅琪】