基于Baseline SVD主动学习算法的推荐系统
2015-06-15季芸等
季芸等


摘 要: 推荐系统是一种解决信息过载的新型技术,为了解决推荐系统中新用户带来的冷启动问题,提出一种基于主动学习的推荐系统。主动学习方法能有效减少需要标记的样本数量,快速建立模型,在此选择将主动学习方法和Baseline SVD推荐算法结合起来,通过记录模型训练得到的预估评价的改变程度,认为改变最大的样例即是最具有信息量的样例,供新用户标记,并重新训练模型。通过与其他选择策略进行实验比较,证实了该方法确实有效解决了新用户带来的冷启动问题。
关键词: 推荐系统; 主动学习; Baseline SVD; 样例选择
中图分类号: TN915.03?34 文献标识码: A 文章编号: 1004?373X(2015)12?0008?04
Recommender system based on Baseline SVD active learning algorithm
JI Yun1, HU Xue?lei1, 2
0 引 言
随着信息技术和互联网的高速发展,各种互联网应用充斥着每个人的生活,得益于互联网的开放性,便利性和分布性,互联网上的信息量急剧增加。为了解决信息过载问题,推荐系统成为了继分类目录和搜索引擎之后,大数据时代的新宠。协同过滤作为一种主流的推荐系统技术[1],在学术界和应用上都广受好评,它的主要思想是通过用户之间的联系来分享物品。协同过滤算法分成两种[2]:一种是基于记忆的协同过滤算法(Memory?based),包括ItemCF算法和UserCF算法,通过计算用户或物品之间的相似度来做推荐;另一种是基于模型的协同过滤(Model?based),基于模型的推荐算法往往结合了数据挖掘、人工智能、机器学习等诸多技术,常见的有基于聚类的推荐、基于矩阵分解的算法、Slope One[3]等,其中基于矩阵分解的算法有:SVD,Baseline SVD[4],SVD++[5]等。在Netflix Prize推荐大赛之后,基于矩阵的推荐算法迅速崛起。推荐系统的发展受到了诸多因素的影响,其中一种便是新用户问题。推荐系统算法非常依赖历史数据,在用户新注册互联网应用之后,系统由于没有该用户的相关数据,而无法为新用户做出准确的推荐,这会大大影响互联用应用对用户的黏着性。为了解决新用户问题,常见的方案有:
(1) 非个性化推荐,随机推荐或者推荐热门,这种方法不够个性化,系统必须累积一定数量的数据才能启动推荐系统;
(2) 根据用户注册信息做出推荐,用户的注册信息往往是有限的,这样的推荐偏向粗粒度;
(3) 主动询问,该方法通过与用户交流,主动获取建立模型需要的相关知识,快速建立准确模型。
推荐系统中,在将推荐产品呈现给用户时,一方面期望得到用户的满意度,另一方面期望能从用户的操作中学习到用户的偏好,这正是主动学习所致力的,因此将主动学习结合推荐系统是不谋而合的[6]。国外研究人员目前常用的算法是将贝叶斯理论作为样本选择策略,AM(Aspect Model)算法为基准学习器[7]。Jin等针对模型本身不确定性的问题,提出了改进,使得用户参数向着准确的方向增长[8]。Rasoul Karimi提出一种基于矩阵分解的主动学习算法,选出预估评分最低的样本供用户选择[9]。
2 基于主动学习的Baseline SVD算法
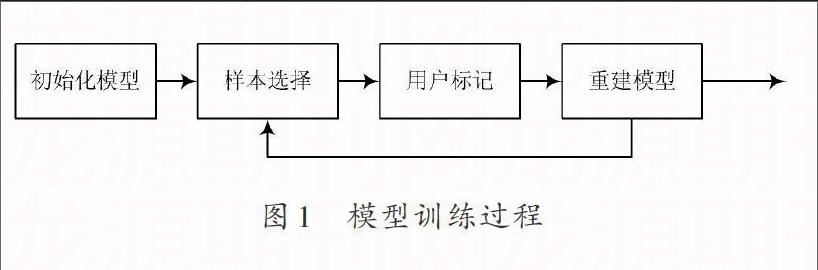
为解决新用户问题,本文选择将主动学习策略和推荐算法结合起来的方法,以加快冷启动速度。主动学习根据样本选择策略,从提问池中选择一个样本供新用户标记,并不断修正模型,直到模型稳定为止,训练模型的过程如图1所示,这是一个不断迭代的过程。主动学习的核心是样本选择策略,目前常用的样本选择策略有:基于不确定性缩减的算法,基于误差缩减的算法和基于版本空间缩减的算法。将主动学习策略与其他应用做结合的研究很多,例如基于主动学习的字符识别[10]、文本分类等。
由于不同的学习算法需要不同的主动学习策略,基于AM算法的主动选择策略并不适用于Baseline SVD算法,并且他们的模型太过复杂,本文选择Baseline SVD作为基准学习器,提出了一种基于评分改变程度作为样例选择的策略。在每次提问后,都会重新训练,同时给出新的预估评分,预估评分波动较大的物品认为是最不能确定,也是最具信息量的。图2中,(a)的预估评分在不同轮数之间的评分差变化很大,而(b)的预估评分相对于要稳定很多,相对于后者,不能确定(a)的评分的可能性更大,得到该样本的标记可以让模型更快趋于稳定,使用式(6)来衡量这种改变程度的大小:
[j=1cnt-1rj+1u,i'-rju,i'cnt-1] (6)
[i′*=argmaxi'∈I'j=1cnt-1rj+1u,i′-rju,i′cnt-1] (7)
式中:cnt表示模型训练的总次数;I′表示为标注样本的集合;[rju,i']表示第j次模型;用户u对i′的预估评分,在所有未评分的物品,最终选出该值最大的物品供用户标记,该式的意义是连续两次模型计算出来的预估评分差的平均值。具体算法流程如图3所示。
3 实验分析
实验使用经典的Movielens作为数据集,采用离线模拟的方式。为了更好地模拟在线用户的实际情况,将Movielens中的用户分成两部分,选择一部分用户和其所评价过的电影数据作为初始的训练集,认为这些用户已经不是新用户。剩下来的用户作为新用户,并将这一部分用户评价电影的数据再拆分成两个部分,每个用户随机预留20个电影评分作为最终的测试集,其他部分的电影评分作为提问池。本文假设用户对每个电影都具有打分的能力,系统每次从提问池中选择电影样本,供用户回答,再将这些被标注好的样本放入训练集后,重新训练模型。初始化时,从提问池中随机抽取该新用户的3个样本放入训练集中,具体的训练集和测试集的分布如表2所示。
表2 Movielens训练集和测试集的分布
经过研究测试,Baseline SVD算法在Movielens数据集中,选择隐分类数为200时效果较好,其中,学习速率α选择0.02,正则系数λ选择0.05。为了反映本文提出的算法性能,选择以下两种策略作为比较算法:
(1) 随机选择。每次从提问池中随机选择一部用户需要标记的电影。
(2) 选择热门。每次从提问池中选择热门的电影,热门产品的定义为,训练集中被看的次数最多的电影。
为评价本文提出的算法,使用RMSE[11]作为算法的评价指标,本文将最大的迭代次数选为8,8次迭代过后,模型对新用户的推荐基本趋向平稳。为了更好地反映结果,对每个实验都进行重复实验,最后结果取平均值,有:
[RMSE=1cu∈Ui∈I(rui-rui)2] (8)
由图4可以得出以下结论,选择热门产品的方案最差,虽然流行度高的电影普及度最广,但是其对于个性化的推荐模型建立并不能做出很大的贡献,其RMSE下降速度最慢。
随机选择策略接近于被动学习中,被动累积数据的情况,本文提出的方法在实验初期,RMSE的数值下降速度最快,明显加快了冷启动速度,随着提问次数增加,RMSE和随机选择方法效果接近。本文提出的算法在每次提问时,仅需维护一个记录累计评分改变的矩阵,为每一个新用户选择评分改变最大的物品,算法复杂度较小,也易于理解。
4 结 语
本文提出了一种基于主动学习的推荐算法,以解决推荐系统中新用户问题。该方法将预估评分的改变程度作为样本选择策略,认为预估评分改变较大的样例是模型最不能确定的,所含信息量较大。实验证明,该方法确实能有效减缓用户的冷启动。但是本文中的实验是基于用户总能回答任何问题的假设前提,这在现实中是不成立的,因此,将用户标记样本的能力结合样例选择策略将是今后的研究重点。
参考文献
[1] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用, 2012,48(7):66?76.
[3] Lemire D, Maclachlan A. Slope one predictors for online rating?based collaborative filtering [C]// Proceedings of SIAM Data Mining. Newport Beach, California: SDM, 2005, 5: 1?5.
[4] YEHUDA Koren. Factor in the neighbors: scalable and accurate collaborative filtering [J]. ACM Transactions on Knowledge Discovery from Data, 2010, 4(1): 1?10.
[5] 刘剑波,杨健.基于SVD++与行为分析的社交推荐[J].计算机应用,2013,33(1):82?86.
[6] RUBENS Neil, KAPLAN Dain, SUGIYAMA Masashi. Active learning in recommender systems [M]// Anon. Recommender Systems Handbook. US: Springer, 2011: 736?767.
[7] KARIMI Rasoul, FREUDENTHALER Christoph, NANOPOULOS Alexandros, et al. Active learning for aspect model in recommender systems [C]// Proceedings of 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM). [S.l.]: IEEE, 2011:162?167.
[8] JIN R, SI L. A bayesian approach toward active learning for collaborative filtering [C]// Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. [S.l.]: AUAI Press, 2004: 278?285.
[9] KARIMI Rasoul, FREUDENTHALER Christoph, NANOPOULOS Alexandros, et al. Non?myopic active learning for recommender systems based on matrix factorization [C]// Proceedings of 2011 IEEE International Conference on Information Reuse and Integration. [S.l.]: IEEE, 2011: 299?303.
[10] 孟凡栋.基于主动学习SVM的字符识别方法研究[D].南京:南京理工大学,2008.
[11] 刘建国,周涛,郭强,等.个性化推荐系统评价方法综述[J].复杂系统与复杂性科学,2009(3):1?10.
