基于Mahout分布式协同过滤推荐算法分析与实现
2015-12-31曾志浩张琼林姚贝孙琪
曾志浩 张琼林 姚贝 孙琪
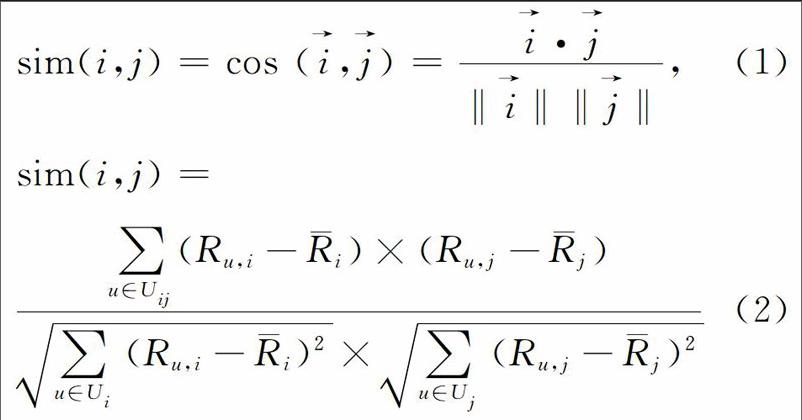

摘要:随着信息技术和互联网的发展,在信息过载的时代,用户面对海量的信息,难以正确选择。协同过滤推荐是个性化推荐中比较成熟的算法,但其稀疏性、冷启动、可扩展性问题仍然存在,尤其是不能应用于分布式推荐。在Hadoop平台上,Mahout实现了分布式基于项目的协同过滤推荐算法,该算法能够有效解决传统算法的海量数据处理的效率问题和可扩展性问题。实验结果表明,Mahout上基于项目的协同过滤推荐算法具有较好的计算高效性和可扩展性。
关键词:分布式协同过滤;Mahout;推荐系统
中图分类号:TP391 文献标识码:A
1引言
互联网和电子商务系统的兴起与发展,将人们带入了网络经济发展时代,同时网络中的信息量也在爆炸式地增长。网络信息虽然给人们带来了更多的选择,但数量庞大及自身质量差异,越来越呈现一种信息过载的趋势,使得如何从这些海量信息中识别出真正有价值的信息变得越来越困难。然而,推荐系统的出现改变了这一状况,尤其是个性化推荐服务技术的发展,成为解决信息过载问题最有效的工具,它能够收集和分析用户的信息,主动地推荐用户可能感兴趣的信息。
个性化推荐中的协同过滤推荐是比较成功的一种,它的概念是由Goldberg、Nicols、Oki以及Terry在1992年首次提出的,主要思想是,利用已有用户群过去的行为或意见预测当前用户最可能喜欢哪些东西或对哪些东西感兴趣。不到两年,Grouplens系统展示了协同过滤方法既能跨网计算又能自动完成,该系统是基于用户评分的自动化协同过滤推荐系统,用于推荐电影和新闻。麻省理工学院的Ringo系统针对音乐唱片和艺术家进行推荐。虽然传统的协同过滤推荐算法在信息过滤方面呈现出了极大的优势,但随着信息量的增加,算法在不同领域的应用中出现了很多的问题,包括稀疏性问题、冷启动问题、可扩展性问题。
为了解决这些问题,文献基于动态规划思想,根据用户以及产品的相似性,自适应地选择预测目标的近邻对象作为推荐群,同时计算把握率较高的信任子群,提出了一种不确定近邻的协同过滤推荐算法,来对预测结果进行平衡的推荐,有效缓解了用户评分数据稀疏的情况。文献在基于弱关系的微博类社交网络中,提出两阶段聚类的推荐算法GCCR,将图摘要方法和基于内容相似度的算法相结合,实现基于用户兴趣的主题推荐,有效缓解了矩阵稀疏性和冷启动问题。文献采用传播的思想,提出了一种改进的基于内存的协同过滤推荐算法SPCF,该算法通过相似度传播,寻找到更多,更可靠的邻居,从用户和项目两方面信息考虑对用户进行推荐,缓解了数据稀疏性问题。
传统的协同过滤推荐算法虽然从一定程度上减少了矩阵稀疏和冷启动问题,但随着数据规模的不断扩大,可扩展性方面仍然表现的比较差,无法适应海量数据的处理,尤其是无法应用于分布式平台。为此,国内外研究者进行了一系列的研究,这些研究大多是针对Hadoop平台和MapReduce并行编程模型,提出相关的分布式协同过滤算法。文献提出了MapReduce范式可扩展的基于相似性的邻居算法,该算法中,针对分割数据设计出运行在并行处理平台上的基本比较对,并采用降低采用率的interaction-cut技术,处理“超级用户”的计算开销,有效地解决了用户或项目大规模增长的情况下扩展性和产生推荐的速度问题。文献针对基于User-based的协同过滤算法的伸缩性问题,实现了基于Hadoop平台的User-based协同过滤算法,从而实现了算法的线性伸缩。文献提出了Hadoop平台上扩展的Item-based协同过滤推荐算法,将单机上基于项目的协同过滤算法的三个最密集的计算分割为四个MapReduce阶段,有效地解决了文献提出的算法的扩展性和效率问题,但是MapReduce阶段的项目相似度计算要求两个项目在同一节点机器上,并且要求用户数量远大于项目数量,对于项目不断增长的情况下,会增加算法的计算量。
本文所要介绍的就是Mahout在Hadoop框架下基于项目的协同过滤推荐算法的实现,该算法是基于MapReduce并行编程模型,不仅有效地解决了在海量数据下算法处理的效率问题,而且解决了随着大量用户和项目的增加产生的可扩展性问题。
2协同过滤推荐算法
协同过滤推荐算法主要包括基于用户和项目的推荐,其中基于项目的协同过滤推荐算法是目前业界应用最多的算法,所以本节内容以基于项目的协同过滤推荐算法为介绍对象,它主要分析用户的行为记录来计算项目之问的相似度。推荐系统首先建立基于项目的数据模型,然后针对目标项目计算项目与项目之间的相似性,得到目标项目的若干最近邻,最后根据最近邻来预测用户对项目的评分,产生对应的推荐列表。
2.1相似性度量方法
相似性度量方法是计算用户或项目问的相似性计算,本节内容是以项目之问的相似的研究为例,即基于项目的协同过滤算法。基于项目i和项目j通常有3种相似性度量方法:标准的余弦相似性(式(1))、修正的余弦相似性(式(2))、相关相似性(式(3))。其中,Ru,i表示用户u对项目i的评分,Ri和Rj分别表示项目i和项目j上所有用户的平均评分,Uij为项目i和项目j共同评分的用户集合,Ui和Uj分别为项目i和项目j评分的用户集合。
2.2产生推荐
基于项目i的k个最近邻居,采用基于项目均值的加权平均值Pu,i,来预测用户u对其未评分或浏览项目的评分。
其中,kNNi表示项目i的k最近邻居集合,Ri,Ri分别表示项目i和j上所有用户打分的平均值。
3Mahout中分布式协同过滤推荐算法实现
3.1Hadoop和Mahout开源框架
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。Hadoop以分布式文件系统HDFS和MapReduce为核心,为用户提供了系统底层细节透明的分布式基础架构。HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,形成分布式系统;MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。所以用户可以利用Hadoop轻松地组织计算机资源,从而搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
Mahout是2008年作为Apache Lucene的子项目出现的,到2010年4月成为了Apache的顶级开源项目。Apache Mahout的分布式计算的主要目标是建立可伸缩性的机器学习算法,通过Map Reduce模式运行在Hadoop平台上。目前Apache Mahout项目包含聚类、分类、协同过滤推荐、频繁子项挖掘和频繁模式挖掘五个部分。
本文意在结合Hadoop平台和Mahout开源框架,对Mahout中分布式基于项目的协同过滤推荐算法进行分析并通过实验实现其算法。
3.2算法实现
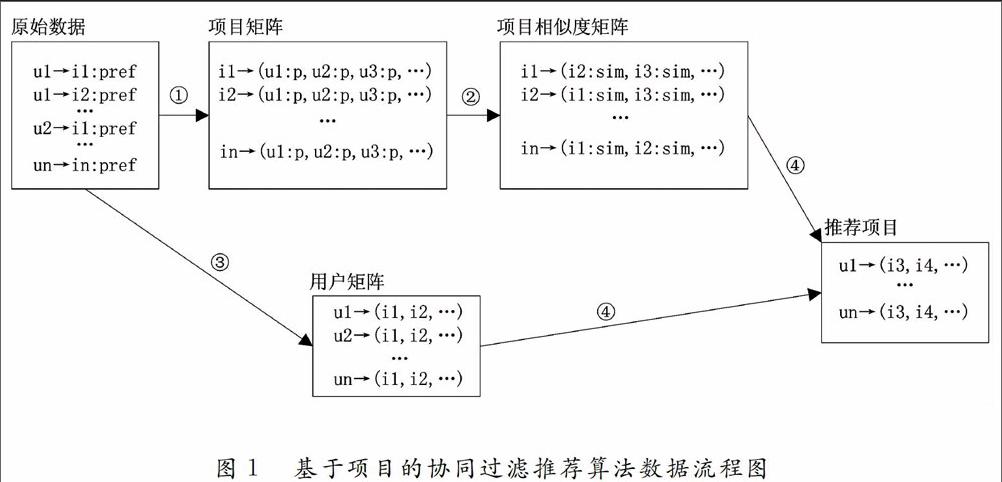
在Mahout中,实现的是基于项目的分布式协同过滤算法,该算法一共包含6个过程,这个6个过程使用了7个Map Reduce的Job任务来进行数据处理。数据流程图如图1所示:
1)用户矩阵
用户矩阵的求解过程,就是针对图1的用户一项目评分矩阵的一个数据抽取过程,把同一个用户评价过的所有项目进行整合,针对每个用户,形成用户分向量itemid:pref,含义为项目ID:用户评价,然后形成每个用户的用户向量,最终形成用户矩阵。Mahout中使用了一个Job任务来进行形成用户向量的数据处理,输出key/value对的格式是
2)项目矩阵
项目矩阵的求解过程和用户矩阵的求解过程很相似,但两者抽取的规则不一样,针对每个项目,形成项目分向量userid:pref。同样在Mahout中也使用了一个Job任务来进行形成项目矩阵的数据处理,输出的key/value对的格式是
3)项目矩阵平方和
在Mahout中使用了一个Job任务来对4.2中的项目矩阵求解平方和,针对每个项目的项目向量,项目矩阵平方和的求解方法为求解项目向量的模的平方。
4)项目相似度矩阵
项目相似度矩阵的求解在Mahout中是由两个Job任务共同处理完成的,第一个Job任务是计算项目与项目之问的相似度,假设有N个项目,首先计算项目1和项目2的相似度,以此类推,最后计算项目1与项目N的相似度,但要注意的是,在计算项目2与项目1的相似度时,因为在计算项目1与其它项目相似度时已经计算过与项目2的相似度了,所以项目2只需计算除项目1以外的与其它项目的相似度。第二个Job任务是续接,所谓续接就是把没有计算相似度的项目加入到其它项目中去,例如在第一个Job任务中,计算项目2与其它项目相似度时是没有计算与项目1的相似度,所以必须将项目1与项目2的相似度续接到项目2中,最后输出形成项目相似度矩阵表。项目相似度的计算公式如下:
其中,i1,i2分别代表项目1和项目2,U代表两个项目共同有过平方的用户集,Pui1,代表用户u对项目1的评分,Pui2代表用户u对项目2的评分,Sim代表的是两个项目的相似度,squssub>i1是对应的项目1的平方和。
5)用户一项目相似度矩阵
用户一项目相似度矩阵是结合用户矩阵和项目相似度矩阵,为每一个用户生成用户一项目向量,Mahout使用了一个Job任务来对这些矩阵进行处理,输出key/value对的格式为
6)用户推荐矩阵
用户推荐矩阵是由Mahout中的一个Job任务根据用户一项目相似度矩阵计算产生的,推荐矩阵中为每一个用户产生一个推荐向量,推荐向量由多个推荐项目及其预测评分组成,计算公式如下:
其中,simiIm是用户U1针对项目Im的相似度矩阵,M为用户评价过的项目集,prefIm是用户U1针对项目Im的评分,公式(7)只是求用户U1的推荐向量,然而,可以用公式(7)为所有用户求得推荐矩阵。
4实验结果及其分析
4.1实验配置和数据集
经分析,在小数据集条件下通过伪分布式模式或小集群的Hadoop分布式模式调试的工程,可以胜任完全分布式模式下的大数据集分布式计算的任务。本实验在一台台式机上建立三台虚拟机,并通过这三台虚拟机建立3个节点的Hadoop集群,其中包括1个Master节点,2个Slave节点,台式机具体配置信息如下:Intel(R)Pentium(R)CPUG2030@3.00GHz,6GRAM,80G硬盘。虚拟机操作系统为Ubuntu12.04,Hadoop版本为1.1.2,Mahout版本为Mahout-0.8。在我们的实验中,将每个Slave节点的map和reduce任务支持的最大数都设置为4,由于map和reduce任务不是同时执行,所以整个集群可以支持8个map和8个reduce任务,实验中将这些map和reduce任务视为计算节点数。
本实验采用MovieLens数据集(http://grou-plens.org/datasets/movielens)。MovieLens是一个基于Web的研究型推荐系统,用于接收用户对电影的评分并提供相应的电影推荐列表。我们选取的数据集包含6040个用户对3952部电影上的1000209条评分记录,其中,每个用户至少对20部电影进行了评分。另外,引入了稀疏等级的概念,其定义为用户评分数据矩阵中未评分条目所占的百分比,实验数据集的稀疏等级为1-1000209/(6040*3952)-0.9581。
4.2性能评估
首先,在相同的数据集上针对不同等级的用户数量,比较单机和分布式的基于项目协同过滤推荐算法的推荐时间,并评估算法效率;然后利用分布式的推荐算法的加速比,随着计算节点数的增加,评估固定数据规模下算法运行的性能变化情况,并验证算法的可扩展性。
1)推荐算法时间比较
本实验的MovieLens数据有1000209条用户评分记录,为了方便观察单机与分布式推荐时问的比较结果,将数据分为7个等级,如表1所示,数据等级分别选取500、1000、2000、3000、4000、5000、6000、6040个用户。实验就是分别对这7个等级的用户的评分记录数量进行处理,为所有用户推荐至多3个项目,然后比较不同条件下的推荐时问,如图2所示:
其中,横坐标表示为用户数量,纵坐标表示为对应不同用户数量推荐项目的推荐时间,以分钟为单位。从图2中可以看出,针对单机和两节点的推荐时间比较接近,这是因为在两节点的Hadoop集群环境下,只有一个主节点和一个从节点,节点之间除了必要的数据处理任务外,还要调度集群资源,以便合理的安排任务。三节点的集群整体的推荐时间要优于前两者,推荐项目时能节省很多的时间,可以得知,集群规模越大,计算的时间越少,对于单机需要几个小时才能处理的数据,如果集群规模有上百台,那么只需要几分钟就能够将数据处理完,这说明集群更适合处理海量的数据,并且效率更高。
2)加速比
加速比性能分析的计算公式如(8)所示。其中T1代表的是单个计算节点并行执行算法的总时间,Tp代表的是包含p个计算节点并行执行算法的总时间。如果算法是可扩展的,那么当数据规模固定时,加速比与计算节点的增加将呈现线性关系。本实验将数据集按评分记录数分成三个等级,分别为10000、100000、1000209,实验结果如图3所示:
可以看出,三个等级数据规模的加速比与计算节点数的增加近似呈线性关系,而且当数据规模增加时,加速比更大。由此可以得出,Mahout上分布式的基于项目的协同过滤算法在处理更大规模的数据时算法的加速比表现的更好,有效地解决了算法的可扩展性问题。
5总结
首先介绍了传统协同过滤推荐算法,虽然在数据稀疏性、冷启动问题等方面有所改善,但不能够应用于分布式平台,处理海量数据时遇到了算法瓶颈。本文借助Hadoop平台,分析Mahout中分布式的基于项目的协同过滤推荐算法,并实现其基本原理及方法,充分说明了该算法在处理海量数据时表现出色的高效率性能,其可扩展性也在分布式系统中得到了重大的改善,在商业应用之中,具有明显的竞争优势。
