基于集成学习的白流量检测过滤系统
2023-06-22杨韧卢贤涛
杨韧 卢贤涛

摘 要:目前主流的恶意流量检测方法是对所有流量都进行安全检测,耗时长,资源浪费大。为节省资源并提高流量检测效率,文章基于机器学习的白流量过滤算法开发了一套能快速辨别并过滤全流量中白流量的过滤系统。系统包括文件检测模块、算法模块和可视化模块三部分。实验证明,相较于传统算法,文章提出的算法能在保证安全性的前提下大大提高流量过滤的效率,节省大量资源。
关键词:机器学习;白流量过滤;恶意流量检测
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)03-0086-04
White Traffic Detection and Filtering System Based on Ensemble Learning
YANG Ren, LU Xiantao
(School of Computer Science and Information Security, Guilin University of Electronic Technology, Guilin 541004, China)
Abstract: The current mainstream malicious traffic detection method is to perform security detection on all traffic, which takes a long time and wastes resources. In order to save resources and improve the efficiency of traffic detection, this paper develops a set of filtering system that can quickly identify and filter white traffic in full traffic based on the white traffic filtering algorithm of machine learning. The system includes three parts: file detection module, algorithm module and visualization module. Experimental results show that, compared with traditional algorithms, the algorithm proposed in this paper can greatly improve the efficiency of traffic filtering and save a lot of resources on the premise of ensuring security.
Keywords: machine learning; white traffic filtering; detection of malicious traffic
0 引 言
近年来,互联网科技飞速发展,网络安全也越来越重要,随着互联网的普及,各种各样层出不穷的网络攻击会对网络和用户造成巨大的损失。传统检测恶意流量的方法是对全流量进行检测,即对所有流量都进行无差别的检测,找到并拦截恶意流量。但现阶段网络中的流量大多数是DNS、HTTPS、视频流量等正常流量,恶意流量的占比往往不足千分之一,对所有流量都进行检测没有必要,并且会造成大量资源的浪费,极大地消耗设备性能。
针对传统流量检测方法的缺陷,文章介绍了一种基于集成学习的白流量檢测过滤系统,从白流量的特征出发,在进入系统的全流量中,自动识别并过滤无害的白流量,然后对剩下的可疑流量进行分类,阻止恶意流量,辅助网络运维人员进行后续工作,以达到提高检测效率,节约时间和资源的目的。
1 系统总体框架设计
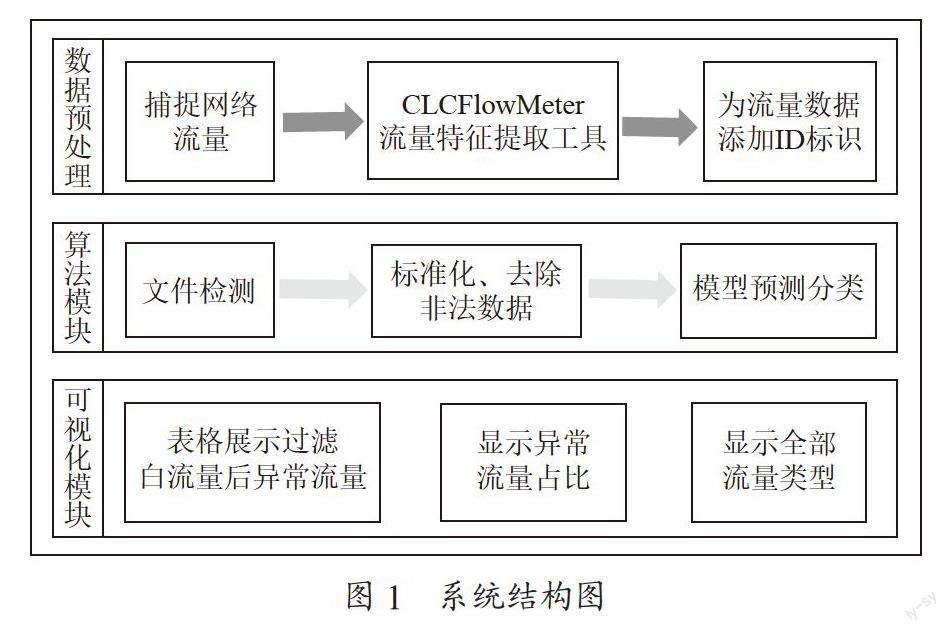
本系统由文件检测模块、算法模块、可视化模块三部分组成,系统结构图如图1所示,其中,文件检测模块用于检测上传文件是否为csv格式,以及上传文件是否包含规定的流量特征;算法模块主要作用是通过对进入系统的流量进行检测,然后判断该流量是恶意流量还是白流量并对白流量进行过滤。可视化模块的主要作用是在系统的安全检测模块检测出恶意流量后,表格展示被判断为恶意流量的流量,可视化恶意流量的占比,以及提供表格导出的功能。本系统主要通过集成学习算法——Voting Classifier算法对网络流量进行分类预测,实验结果显示,本系统对白流量的检测准确率达到了99.03%。
2 具体实施方法
2.1 算法设计
文章设计了一种基于集成学习的软件定义网络DDOS攻击协同防御方法,如图2所示。
其具体步骤如下:
步骤1:启动SDN控制器进行流量数据采集,收集正常流量和攻击流量的数据,并将数据存储在CSV文件中。需要监控和采集的特性和参数如下:
(1)IP源的速度:该特性给出了在特定时间间隔内进入网络的TP源的总数。缩写为SSIP,定义为式(1):
(1)
其中SumIPsrc为每个流进入的IP源总数,T为采样时间间隔。检测系统每T秒进行一次流量监控和数据采集,并保存在该时间段内的源IP个数。控制器需要有足够的正常流量和攻击流量数据,机器学习算法才能预测攻击。对于普通攻击,SSIP通常较低,而对于攻击,计数通常较高。
(2)流量计数:每个进入网络的流量都有一个特定的流量计数。正常流量比DDOS攻击流量少。
(3)流量表项的速度:在一定时间间隔内,网络中交换机的流量表项总数。缩写为SFE,定义为式(2):
(2)
这是攻击流量检测的一个非常相关的特征,因为在DDOS攻击的情况下,流量表项的数量在固定的时间间隔内会比正常流量的流量表项的速度值显著增加。
(4)流量对比值:指在T个时间段内,交换机流入的流量条目总数,即交互IP数除以总流量。缩写为RPF,定义为式(3):
(3)
其中SrcIP为网络流中协作IP的总数,N为总IP数。在正常流量情况下,第i条流的IP源与第j条流的目的IP相同,第j条流的IP源与第i条流的目的IP相同。这说明了一个交互流,而当它是DDOS攻击流量时就不是这样了。受到攻击时,到达目标主机的时间T的流表项迅速增加,目标主机无法响应。因此,当DDOS攻击开始时,攻击流量会突然减少。将协作流总数除以总流量,使该检测参数可扩展到不同运行条件下的网络。
步骤2:将收集到的数据放入检测模型进行训练,具体如下:
(1)对数据进行预处理和特征降维。首先进行数据标准化,接着进行特征降维。通过结合过滤法和嵌入法的降维算法,能够尽可能地避免出现特征选择偏差及弥补各单一特征选择算法的不足。选用过滤法中的两种特征选择算法卡方验证与互信息算法,以及嵌入法中的两种特征选择算法轻量级高校梯度提升树(LGBM)与极限随机树算法计算特征贡献(权重)的排序。在四个算法结果子集中采用Voting投票策略选择出权重综合较高的特征集合作为最优特征子集。
(2)引入集成学习中的多样性度量进行基分类器间的组合效果评估,选择优质的异质集成学习基分类器模型。对于拟选择的基分类器模型采用贝叶斯优化参数,通过计算模型的准确率(ACC)和曲线下面积(AUC),完成第一次的基分类器过滤。
模型ACC的计算公式如式(4)所示:
(4)
式(4)中,TP表示预测值与实际值一致且均为正值的样本数;FP表示预测值为正且真值为负的样本数;TN表示预测值与实际值一致且均为负值的样本数;FN表示其预测值为负值且其真值为正值的样本数。
AUC使用受试者工作特征ROC曲线,其计算方法如式(5)所示,AUC为1则对应理想分类器,其表示公式为:
(5)
式(5)中M、N分别表示正负样本个数,表示正样本i的排序编号,M*N表示随机从正负样本各取一个情况数。
(3)采用基于Bagging集成算法的加权投票机制进行步骤(2)选择基分类器模型的集成。系统获取基分类器的ROC曲线并根据ROC曲线计算AUC值,随后使用准确率和AUC值作为加权投票机制的权重。分类器间集成赋权函数如式(6)所示:
(6)
式(6)中,Uaoc,i表示第i个基学习器的ROC曲线未覆盖的面积(Uaoc,i=1-AUC)和分别为所有基学习器中ROC曲线未覆盖面积的最大值和最小值,ei、eb、ew分别表示第i个分类器准确率、集合中准确率最低的分类器准确率以及集合中准确率最高的分类器准确率。
步骤3:将步骤(3)生成的集成模型嵌入SDN控制器,启动DDOS攻击检测模块。当正常流量产生时,检测模型算法将其预测为正常流量,当有攻击流量产生时,立即将其检测为DDOS攻击,并阻断其进入的端口。若某个端口被阻断,控制器仍然允许其他端口的正常流量通过。控制器在一段时间后解除阻塞端口并重新开始检测,如果攻击仍然活跃,它会再次检测并阻塞该端口。只要攻击持续,阻塞就会持续下去。
2.2 模型的训练
2.2.1 数据集的选择
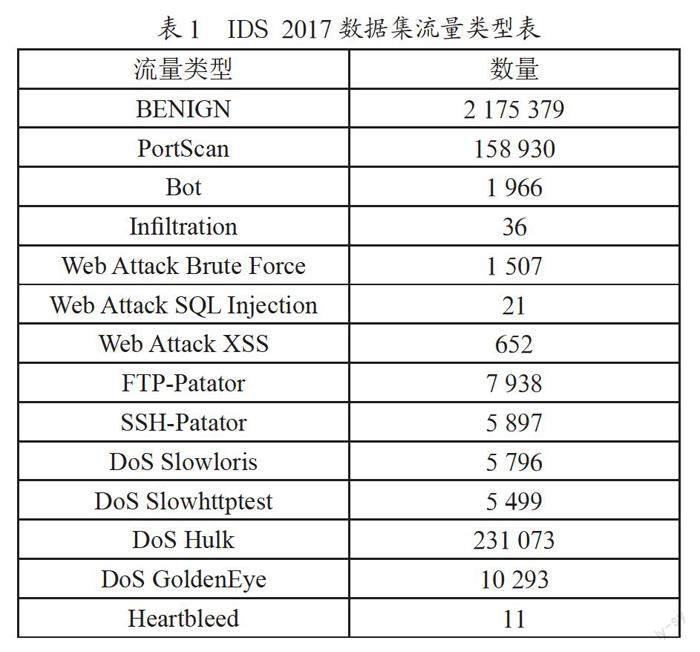
本系统采用IDS 2017以及Darknet 2020數据集用作模型的训练集。数据集包含14种现代网络攻击流量类型,包括FTP-Patator、SSH-Patator、DoS GoldenEye等,如表1所示。文章仅使用该数据集中第一层中的良性流量作为训练集。
2.2.2 数据预处理
原始流量数据是按时间保存的,实验中采用Python中的Pandas库,首先是Label标准化,原始数据中标签值是以字符串形式存储,运用LabelEncoder()函数将数据的标签进行编码,接着进行数据标准化,防止有些特征的方差过大。最后是数据清洗,对于缺失的数据行、数据中无效的数值(包括NAN值与正负无穷大)的数据行进行剔除,数据预处理过程如图3所示。
2.2.3 现实流量采集以及工具使用
本系统使用Wireshark软件进行流量采集,抓包软件Wireshark具有非常强大的功能,可以捕获网卡上的特定流量信息。文章采IDS 2017数据集,IDS 2017数据集使用CICFlowMeter作为流特征提取工具,能够根据提交的.pcap文件生成有多个特征的csv文件,使用方法有两种:在线和离线模式。在线模式可以实时监控并产生特征,监听结束之后可以保存到本地;离线模式是提交一个.pcap文件,得到一个包含特征的csv文件。
2.2.4 特征重要性及特征降维
在进行现实流量采集过程中发现,对于不同的流量数据,使用CICFlowMeter特征提取工具,并不都能获得类似IDS 2017中的78个完整特征,文章采用SKLearn库中的feature_importances_方法进行特征降维,采取10次特征重要性提取,对决策树、随机森林以及极限随机数得出的重要性进行排序,如表2所示。分别选择Destination Port、Fwd Packet Length Max等一共18个特征进行训练。如图4所示。
2.3 模型训练与参数设计
在实际数据测试中,发现对于音频流量等RandomForestClassifier的預测准确率会比ExtraTreesClassifier高,但对于视频流量以及broswing流量结果却恰恰相反,于是本算法模型加入了集成学习算法,对于上述两个分类器的预测结果,VotingClassifier选择voting='hard'参数。分类器参数如表3所示。
对于IDS 2017中2 604 998条数据,使用SKLearn中的train_test_split选用test_size=.20,random_state=42参数划分测试训练集进行模型的训练,训练集白流量与恶意流量分别为435 076与429 619条数据进行模型训练,白流量与恶意流量占比约为1:1。
3 实验测试
3.1 精确值测试
文章通过以下步骤完成精确值测试:
(1)首先是准确率测试,使用SKLearn中的train_test_split选用test_size=.20,random_state=42参数划分测试训练集进行模型的训练,得到的172 654条测试集。用score()对预测结果与标签进行比较打分,得出RandomForest准确率为98.89%,ExtraTreesClassifier准确率为98.91%,集成学习准确率为99.03%。
(2)使用Darknet中良性流量作为测试集,精确度如表4所示。
(3)使用自己采集的真实数据集,运用Wireshark捕捉的两份数据集,分别为仅包含http协议数据realtime.csv以及包含视频流量,音频流量,Chat以及Email流量等的正常网络流量srcdata.csv,两个数据集的预测准确率都为100%。
3.2 时间与占用内存测试
RandomForest测试所消耗时间为11 ms,ExtraTreesClassifier测试所消耗时间为11 ms,集成学习测试所消耗时间为42 ms。在算法运行期间,通过调用Windows任务管理器观察可知,此算法占用内存约为5 GB大小。
4 结 论
互联网发展越来越快,网络中的流量也越来越多,流量检测技术也越来越智能。传统的检测方法耗时太长,占用资源太多,检测效率也相对低下。文章基于集成学习,通过多种方式,开发出了安全,高效的白流量检测技术,大大节省了检测时间,解放了大量资源,有很大的应用价值和市场潜力,顺应了时代的发展。
本系统虽然已经实现了预期功能,但是仍需在实践中继续改进、完善,比如本系统占用的内存达到了5 GB大小,在后续开发中可以通过改进算法等方式进一步压缩。
参考文献:
[1] 李中魁.基于动态阈值的网络流量异常检测方法研究与实现 [D].成都:电子科技大学,2010.
[2] JIN S,YEUNG D S . A covariance analysis model for DDoS attack detection [C]//IEEE International Conference on Communications.IEEE,2004:1882-1886.
[3] 孙知信,张玉峰.基于多维支持向量机的P2P网络流量识别模型 [J].吉林大学学报:工学版,2010,40(5):1298-1302.
[4] 左进,陈泽茂.基于改进K均值聚类的异常检测算法 [J].计算机科学,2016,43(8):258-261.
[5] 张德慧,张德育,刘清云,等.基于粒子群算法的BP神经网络优化技术 [J].计算机工程与设计,2015,36(5):1321-1326.
作者简介:杨韧(2001—),男,汉族,安徽宁国人,本科在读,研究方向:网络安全技术。
收稿日期:2022-09-06
基金项目:广西大学生创新创业训练计划立项项目(202110595169)
