改进YOLOX的安全帽佩戴检测算法
2023-06-20沈希忠
沈希忠,戚 成
(上海应用技术大学 电气与电子工程学院,上海 201418)
在建筑工地的安全生产规范中,不允许未佩戴安全帽的情况下进入施工现场。佩戴安全帽可以有效地降低安全事故发生后因坠落、物体坠击对头部造成的损伤,可以最大限度地保护施工人员的生命安全[1]。在大多数施工场地,往往采用人工监督的方法判断是否佩戴安全帽[2],然而依赖人力监管的方式存在耗时长、效率低等诸多不利因素,远达不到现代施工安全管理的要求,而采用计算机视觉的方法可以对现场安全监管进行有效部署。当前的目标检测的方法主要分为两类:基于传统图像处理的目标检测方法和基于深度学习的目标检测算法。传统的图像检测算法通过搜索目标图像的特征从而得到检测结果,如Rubaiyat等[3]首先利用梯度方向直方图(Histogram of oriented gradient,HOG)搜索图像中工人的位置,然后使用颜色和圆环霍夫变换(Circle hough transform,CHT)来检测安全帽的佩戴情况;刘晓慧等[4]采用肤色检测的方法定位到人脸区域,以此获得脸部以上的区域图像,利用图像矩(Hu mome nts,Hu矩)检测安全帽的佩戴情况。传统的目标检测算法虽然取得了一定的效果,但是在高复杂度、强干扰的施工环境下,基于传统特征提取算法的安全帽检测表现效果较差,无法在实际的检测中保证检测的精度和实时性。随着深度学习的快速发展,卷积神经网络成为目标检测新的研究方向。现阶段的目标检测算法有两类:双阶段检测算法和单阶段检测算法。双阶段检测算法主要是以RCNN[5],FastR-CNN[6],FasterR-CNN[7]为代表的基于候选区域的目标检测算法;单阶段检测算法是以YOLO[8]系列、SSD[9]为代表的基于回归分析的目标检测算法。蒋润熙等[10]以YOLOV5为基础,基于Inverted resblock结构对主干网络进行了重构,并对BN层进行稀疏训练实现了安全帽的快速检测。赵红成等[11]针对数据集类别不平衡以及模型推理时间长这两个问题,设计了混合场景数据增强方法,采用MobileNetV2替换YOLOv5s主干网络,并对BN层进行剪枝,实现了安全帽的快速检测。徐先峰等[12]使用MobileNet对SSD算法进行改进,并采用迁移学习策略克服模型训练困难问题,相较于原算法检测速率有所提升。
在实际的工程作业环境中,不但要求网络有较好的检测精度,而且对于模型的运行速度、检测的实时性都有着较高的要求。现有的卷积神经网络存在着参数量过多、模型运行速度慢以及对不同场景的泛化能力差等问题,不利于实际的应用部署。针对上述问题,笔者提出一种基于改进的YOLOX的安全帽佩戴检测算法,通过实验证明笔者算法可以准确、高效地检测各种场景下的安全帽佩戴情况,具有较好的实时性和鲁棒性。
1 改进的YOLOX网络
许凯等[1]提出的改进YOLOV3的安全帽佩戴识别算法,主要针对检测精度对网络进行改进,通过增加一个尺度的有效特征层、重新聚类先验锚框以及改进损失函数对网络加以优化,以实现对安全帽目标更好的检测,然而这样的改动导致模型的结构变得复杂,检测速率降低。笔者所提出的改进的YOLOX安全帽佩戴检测算法,对YOLOX的主干网络进行轻量化处理以及对特征融合网络进行加强,不仅提高了网络对小目标的检测能力,而且减少了模型参数。
YOLOV3算法由主干网络Darknet53、特征提取网络FPN以及Coupled head所组成。YOLOX算法由主干网络CSPDarknet、特征提取网络PANet以及Decoupled head构成。两者的区别在于:1)YOLOV3的主干网络Darknet53由ResNe(X)t结构所组成,而YOLOX的主干网络使用了CSPResNe(X)t结构,两者结构如图1所示。CSPResNe(X)t相较于ResNe(X)t增加了一个大的残差边,这一做法可以分割梯度流,使梯度流通过不同的网络路径传播,通过切换串联和过渡步骤,传播的梯度信息可以具有较大的相关性差异,从而增强网络的学习能力、实现更丰富的梯度组合以及减少计算量。2)YOLOV3的特征提取网络FPN和YOLOX的PANet结构如图2所示,图2(a)中的FPN是自顶向下的路线,通过侧向连接,将高层的强语言特征传递下来,只增强了特征金字塔的语义信息。例如,当底层特征到P5时,中间经过非常多层的网络,此时底层的目标信息已经非常模糊,因此PANet对FPN进行了扩展,如图2(b)所示,加入了自底向上的路线,弥补并加强了定位信息。3)Coupled head和Decoupled head结构如图3所示,Coupled head虽然将分类和回归通过一个卷积操作来实现,但是分类和回归的特征不太相同,分类更加关注所提取的特征与已有类别哪一类最为接近,而回归则更多是一些轮廓边界特征。如果将两者放在一起反向传播可能会导致网络收敛速度变慢,精度降低。Decoupled head将分类和回归分开进行,可以避免Coupled head所造成的问题。综上,YOLOX算法的性能优于YOLOV3,因此选择YOLOX进行改进。
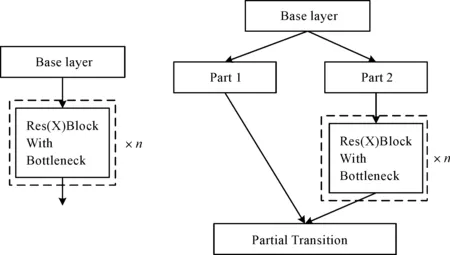
图1 ResNe(X)t和CSPResNe(X)t结构图
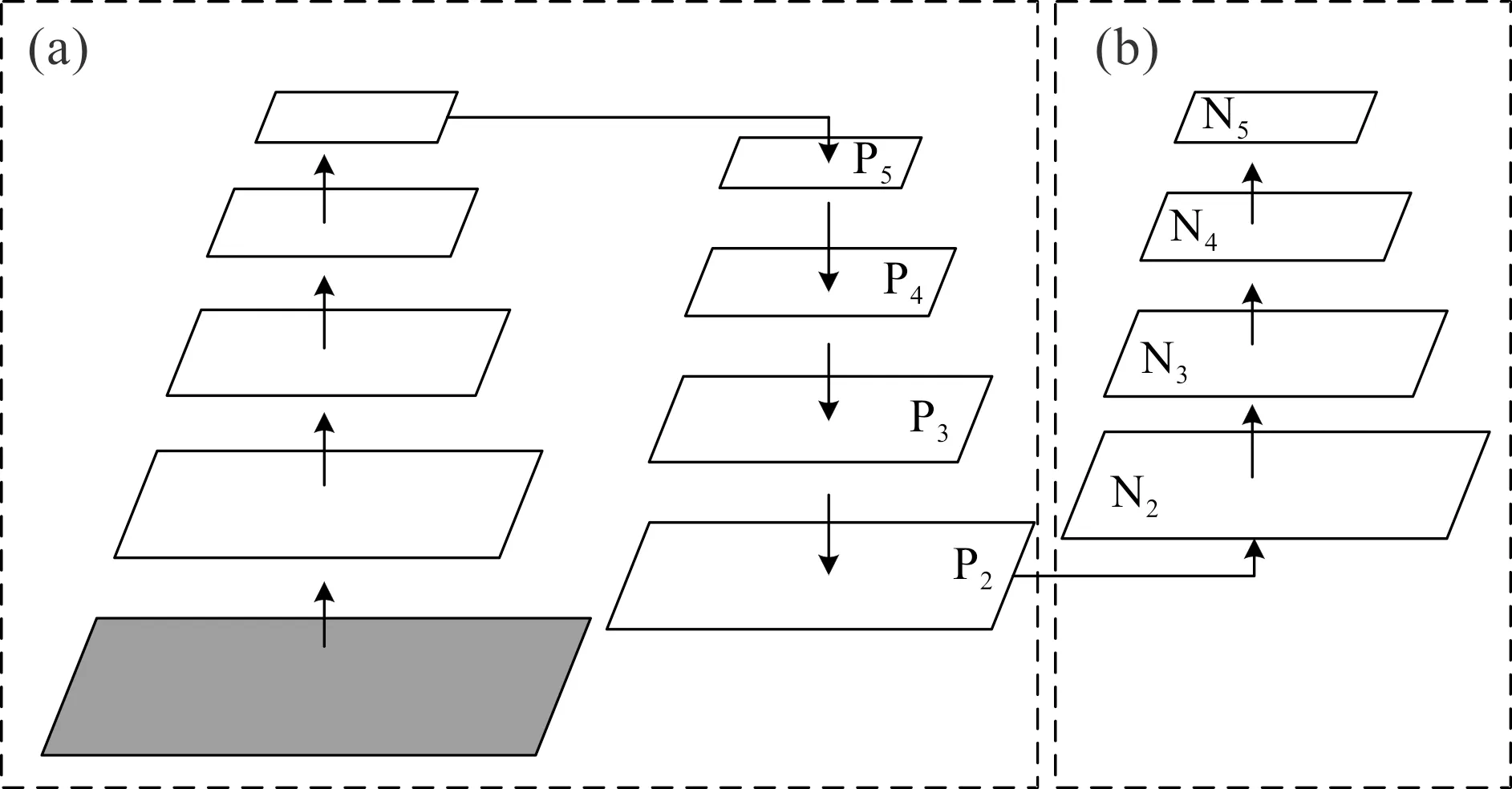
图2 FPN和PANet结构图
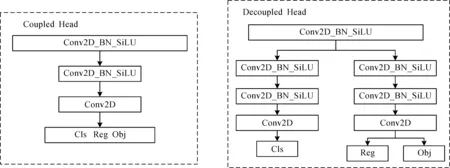
图3 Coupledhead和Decouplehead结构图
采用改进的YOLOX目标检测算法对建筑工人安全帽的佩戴情况进行检测,将YOLOX的主干特征提取网络(Backbone)替换为轻量级的GhostNet[13],达到减少网络模型参数以降低计算量加快检测速度的效果。对PANet[14]特征融合网络(Neck)进行尺度以及融合方式两方面的加强,将特征融合网络的有效特征输入扩展为160×160,80×80,40×40,20×20这4个尺度,增强对特征图浅层信息的利用,并在原2倍上采样的基础上增加4倍上采样的间隔融合结构,进一步实现浅层信息和深层信息的融合,减少卷积过程中安全帽信息的特征丢失。改进后的YOLOX网络如图4所示。
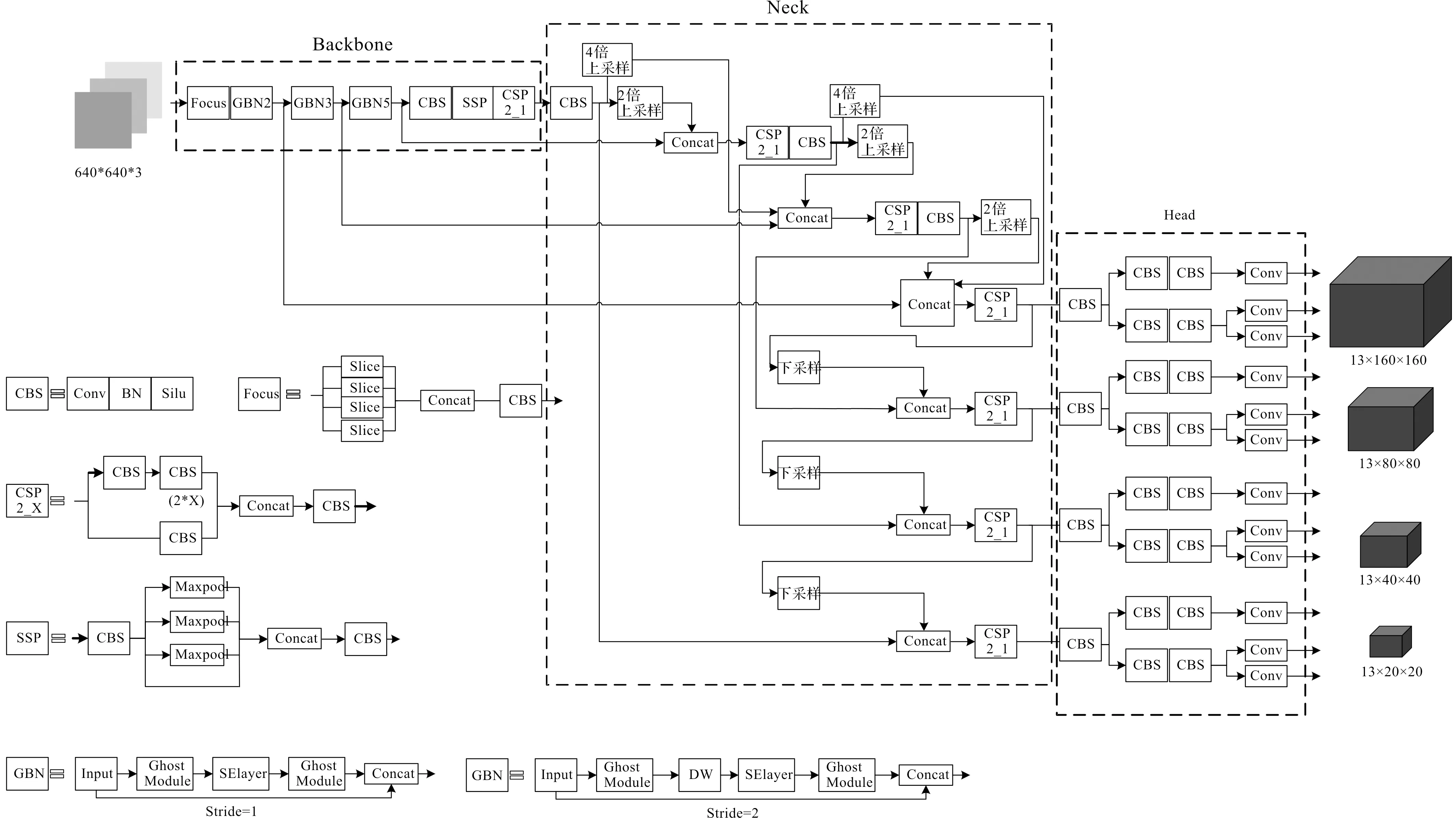
图4 改进的YOLOX网络结构图
2 网络改进部分
2.1 主干网络改进
为了实现网络的轻量化部署,需要减少网络的计算量和参数量,选择性能较好的轻量化网络GhostNet替换原YOLOX的CSPDarknet主干特征提取网络。
YOLOX的CSPDarknet主干特征提取网络主要是由跨阶段局部网络结构(Cross stage partial,CSP)[15]组成,并在CSP1结构中包含了残差单元,CSP1以及残差单元结构如图5所示。这些残差单元由两部分组成:主干部分是一次1×1的常规卷积和一次3×3的常规卷积;残差边部分不做任何处理,直接与主干部分的输出相结合得到最后的输出。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率,其内部的残差单元使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。整个CSPDarknet包含了几十个这样的残差单元,而太多的卷积操作会导致网络参数量庞大、计算度复杂。鉴于此问题,首先将残差单元中的常规卷积替换为计算量少的Ghost模块,组合成Ghost bottleneck残差结构,然后再进行下一步的堆叠得到GhostNet网络,利用较少的参数生成与普通卷积相同数量的特征图。这样既减少了参数量加快模型运行速度,又保留了残差模块容易优化、可以缓解梯度消失的优点,可以很好地对主干特征提取网络进行性能的优化。

图5 CSP1以及残差单元结构图
通过残差网络生成的特征图一般都有丰富甚至冗余的特征图信息来保证对输入的理解,Ghost模块的功能就是代替其中的普通卷积,将相似的特征图看作彼此的ghost,并提出可以使用一些计算量更低的操作去生成这些冗余的特征图,这样可以保证在良好检测效果的情况下,减少模型的参数量且提高模型的执行速度。图6(b)所示Ghost模块将普通卷积分为3部分,首先使用一个1×1的少量常规卷积操作对特征图进行特征整合,生成输入特征层的特征浓缩;然后使用深度可分离卷积(Depthwise seperable conv)或者其他的一些线性操作进行逐层卷积,利用上一步获得的特征浓缩生成Ghost特征图;最后将特征浓缩层和Ghost特征层拼接得到完整的输出特征层,这样就可以在保证良好检测效果的情况下,减少模型的参数量与提高模型的执行速度。

图6 常规卷积和Ghost模块结构对比图
当输入特征图的尺寸为c×h×w,常规卷积的输出尺寸为h′×w′×n,卷积核大小为c×k×k×n;Ghost模块的原始卷积输出特征图尺寸为h′×w′×m,使用的卷积核为c×k×k×m,线性操作后产生的Ghost特征维数为s。假设Ghost模块包含1个identity mapping和个线性操作,每个线性操作的核大小为d×d。则
常规卷积的计算量为
F1=n×h′×w′×c×k2
(1)
常规卷积的参数量为
P1=n×c×k2
(2)
Ghost模块的计算量为
(3)
Ghost模块的参数量为
(4)
将两者的计算量和参数量分别进行比值计算,则
(5)
(6)
通过式(5,6)可以明显地看出:当输入特征图的尺寸相同时,Ghost模块的参数量和计算量都比普通残差结构中的常规卷积更低,理论上可以达到更快的模型推理速度。
Ghost bottlenecks是由Ghost模块组成的残差结构,其本质上就是用Ghost模块代替残差结构里面的常规卷积。Ghost bottlenecks可以分为两个部分,分别是主干部分和残差边部分。Ghost bottlenecks有两类,如图7所示,当需要对特征层的宽高进行压缩时,设置Ghost bottlenecks的Stride=2,即步长为2。此时会在Bottlenecks里面多添加一些卷积层,在主干部分里,在两个Ghost模块中添加一个步长为2×2的深度可分离卷积进行特征层的宽高压缩。在残差边部分,也会添加上一个步长为2×2的深度可分离卷积和1×1的普通卷积。

图7 Ghost bottlenecks结构图
GhostNet由Ghostbottlenecks堆叠而成,其构建方式如表1所示。当输入特征图尺寸为640×640×3时,首先进行一个16通道的普通1×1卷积块(卷积+标准化+激活函数),开始Ghostbottlenecks的堆叠,利用Ghostbottlenecks,得到一个20×20×160的特征层;其次利用1×1的卷积块进行通道数的调整,获得20×20×960的特征层,将这些特征层平均全局池化;再次利用一个1×1的卷积块进行通道数的调整,得到一个1×1×1 280的特征层;最后平铺进行全连接进行分类。

表1 GhostNet网络结构
2.2 特征融合网络的改进
原YOLOX采用3个不同尺度的特征图进行特征融合,在输入图片尺寸为640×640的情况下将主干网络获得的20×20、40×40以及80×80这3种尺寸的特征图作为特征融合网络的有效特征层,将20×20的特征层2倍上采样和40×40的特征层融合,再将融合后的40×40的特征层经过2倍上采样与80×80的特征层进行特征融合,随后将80×80特征层经过两次下采样、两次特征融合获得3个尺度的输出层。
所检测的安全帽目标体积较小,且在实际的工程环境中,施工人员可能距离检测设备较远以及存在遮挡等情况。在通过网络的多次卷积操作之后安全帽的特征信息会存在局部丢失,导致检测效果不佳。
为解决上述问题,在原PANet的基础上增加160×160的低维有效特征层,提高网络对特征图浅层信息的泛化能力。原特征融合网络采用2倍上采样的递进融合结构,不能很好地将深层信息和浅层信息融合,在2倍上采样的基础上增加了4倍上采样的间隔融合结构,能够有效地融合不同维度的特征信息,同时可以缓解卷积操作所带来的安全帽区域的特征丢失。用深度可分离卷积(Depthwise seperable conv)替代常规卷积,减少模型参数,保证网络的轻量化。
改进后的多尺度特征融合网络结构如图8所示,将原网络的3个有效特征输入扩展为4个尺度。当输入图片为640×640时,P2,P3,P4,P5所对应的有效特征层尺寸为160×160,80×80,40×40和20×20。在原PANet的基础上增加4倍上采样的间隔融合结构,主要改进为将最底层的20×20有效特征层经过4倍上采样与两次2倍上采样后的80×80特征层进行间隔融合;将40×40有效特征层经过4倍上采样与两次2倍上采样后的160×160特征层进行间隔融合,后续的下采样融合结构与原网络保持一致。
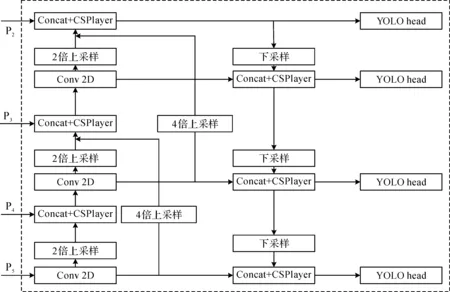
图8 多尺度特征融合网络结构
原YOLOX算法主要在COCO数据集上进行验证,而这些数据大部分需要检测的目标都比较大,改进后的算法充分利用了目标不同尺度的特征信息,提高网络对浅层信息的感知能力。安全帽佩戴在施工人员的头部位置,检测目标较小,针对特征融合网络的改进可以加强算法对小目标的检测能力。
3 实验和结果分析
3.1 实验环境
实验环境为:win10操作系统,Intel Corei5-11400 CPU,32 G运行内存,NVIDIA GeForce RTX 3060 GPU,CUDA11.0,CUDNN8.0,所用的深度学习框架为Pytorch。
3.2 实验数据集
实验所用数据集图片主要来源于开源数据集、施工现场监控视频采集图像以及网络爬虫获取。数据集包含了不同施工场景下的不同作业环境、不同清晰度、有无遮挡等条件下的施工人员佩戴安全帽和未佩戴两类图片,且在数据集中加入佩戴棒球帽、佩戴警帽、手持安全帽等的干扰图片,防止图片类别单一,增加模型的泛化能力。数据集样本如图9所示。

图9 安全帽样本示例
最终整理得到的数据集共9 000张,将图片统一编号后,采用Labelimg标注工具对数据集进行标注,将数据集标注为VOC格式,生成xml标注文件。数据统一清洗为hat和person两类,按照9∶1的比例将数据集划分为训练集和测试集。
3.3 评价指标及参数设置
为检测改进后的YOLOX算法的性能,采用平均准确率(Average precision,AP)、平均准确率均值(Mean average precision,MAP)、每秒检测帧数(Frames per second,FPS)以及模型大小等指标对算法性能进行评估。
准确率(Precision):被正确检测的正样本占所有检出(预测为正样本)样本的百分比,即
(7)
召回率(Recall):被正确检测的正样本占所有正样本(Ground truth)的比例,即
(8)
AP为预测样本的准确率均值,精确率—召回率曲线(Precision-recall curve)下的面积,即
(9)
MAP为对每个类别的AP求平均,即
(10)
式中:TP(True positive)表示将正样本预测为正,即正确检测佩戴安全帽人员;FP(False positive)表示将负样本预测为正,即未佩戴安全帽人员被检测未佩戴;FN(False negative)表示将正样本预测未负,即佩戴安全帽人员被检测为未佩戴。
实验所传入的图片大小设置为640×640,格式为JPG,batch_size和学习率分别设置为8和0.001。采用Mosaic数据增强对图片进行拼接处理,增加背景复杂度以获得多尺度的检测目标,实验设置为在前80%个epoch使用Mosaic,避免因其大量crop操作带来的不准确的标注框而对实验结果产生负面的影响。使用余弦退火学习率在网络训练时对学习率进行微调。
3.4 消融实验
为得到每个改进点所带来的不同的效果,设置消融实验来进行对比观察,实验结果如表2所示。表2中:改进1为主干特征提取网络改进;改进2为特征融合网络改进;FPS(Frames per second)为每秒传输帧数。由表2中可以看出:采用GhostNet替换原CSPDarknet主干特征提取网络虽然可以有效提升模型检测的速度,但是平均精度降低了5.9%;特征融合网络的改进虽然使得检测的平均精度提高了3.5%,但是检测速率降低。结合上述改进得到笔者提出的算法,相较于原YOLOX网络,在平均精度基本不变的情况下,提升了网络的检测速度,可进行实时高效的安全帽佩戴检测。
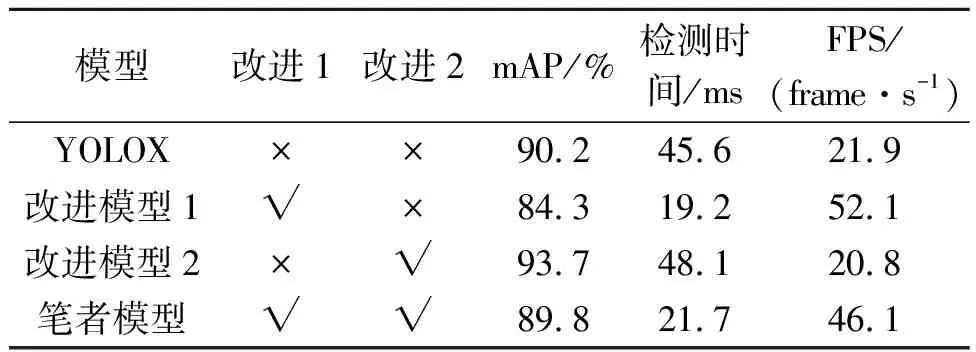
表2 消融实验结果
3.5 对比实验分析
将笔者提出的算法与YOLOX,YOLOX-tiny,YOLOv4,YOLOv4-Mobilenet等YOLO系列算法在相同实验环境下使用相同数据集进行对比实验,其中YOLOX-tiny,YOLOv4-Mobilenet都是轻量级网络,YOLOX是笔者所改进的原始算法。统计各算法的平均准确率AP、平均准确率均值MAP、FPS和模型大小等指标,对各类算法的检测效果进行对比分析,各算法检测结果如表3所示。由表3可以看出:相较于YOLOX,笔者算法和YOLOX都表现较高的检测精度。笔者算法在AP和MAP上基本保持不变,MAP仅仅下降了0.4个百分点,而在模型的轻量级评价指标方面,参数量、模型大小仅为YOLOX的1/5。在检测速度方面,笔者算法比YOLOX快23.9 ms。与YOLOv4相比,笔者算法在检测精度和检测速度上都有一定提升。与YOLOX-tiny,YOLOv4-Mobilenet这两个轻量级网络相比,笔者算法的MAP分别提升了10.9%和7.9%,检测速度上笔者算法比YOLOv4-Mobilenet快2.8 ms。笔者算法在不牺牲检测精度的情况下,对网络进行轻量化处理,相较于所对比的轻量化网络,可以达到准确且快速的检测效果。
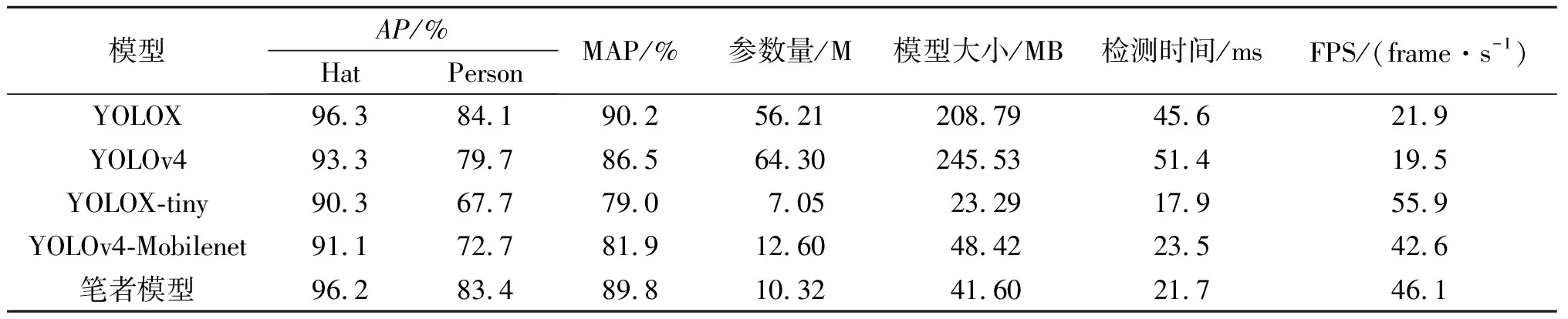
表3 不同检测算法结果对比
为了更加直观地体现出不同算法之间的性能区别,选取YOLOX、YOLOX-tiny以及笔者算法在测试集上的部分检测结果进行对比说明,检测结果如图10所示,其中佩戴安全帽的人员识别为“hat”,未佩戴安全帽的人员识别为“person”,从左向右第1列到第3列分别为YOLOX、YOLOX-tiny和笔者算法的检测结果。图10(a)为施工环境钢筋遮挡情况下的目标检测,观察可以看出YOLOX-tiny在遮挡部分存在两处漏检,而YOLOX和笔者算法全部检出;图10(b)为远距离小目标情况下的检测,可看出YOLOX-tiny只检出一处人员,YOLOX有两处漏检,而笔者算法针对特征融合网络进行改进,加强了算法对小目标的检测能力,使得在这一情况下表现良好,全部检出;图10(c)为昏暗模糊场景下的检测,对比可知,YOLOX和笔者算法没有漏检、误检的情况,而YOLOX-tiny存在两处误检;图10(d)为人员密集情况下的安全帽佩戴检测,可以明显看出YOLOX-tiny存在多处漏检,而笔者算法和YOLOX全部检出,笔者算法仅存在一处误检。由上述对比实验以及结果分析可知:笔者算法在轻量化的同时,能够保持在各种复杂场景下的良好检测效果。
4 结 论
为解决实际工作环境下安全帽佩戴检测速率低、实时性差以及精确度不高等问题,提出了一种基于改进YOLOX的轻量级安全帽佩戴检测方法。在YOLOX网络的基础上,采用GhostNet替代原网络的CSPDarknet主干特征提取网络,对网络进行轻量化处理,大幅提升模型的检测速度,改进特征融合网络网络,采用4个尺度的有效特征层进行特征融合,对特征图的浅层信息进行充分利用,提高对小目标的检测能力。经对比实验分析,笔者算法在不同场景下检测效果良好,在保证检测精度的情况下,检测速率相较于原网络提升了52.4%;相较于YOLOX-tiny等轻量级网络,检测速率基本持平,检测精度获得大幅提升。后续将进一步研究如何减小网络参数,提升在移动端的推理速度。
