算法推荐风险影响因素系统动力学研究
2023-06-18崔文波张涛孙钦莹马海群
崔文波 张涛 孙钦莹 马海群
摘 要:作为智能情报分析中的重要应用场景,算法推荐提供的个性化和精准化信息服务为现代快速决策增加了价值,但算法推荐风险问题也尤为突出,探寻算法推荐风险影响因素对科学地提出算法风险治理策略至关重要。文章采用LDA模型对科研论文进行主题聚类,聚类结果与《互联网信息服务算法推荐管理规定》进行相似度计算,以识别算法推荐风险影响因素,从风险产生和风险治理两个维度构建系统动力学模型,然后利用Vensim PLE软件和文本计算数据进行仿真与灵敏度分析。研究识别出算法素养、大数据技术、算法偏见、网络安全审查等影响因素,通过文本计算获得的数据进行仿真能够较好的拟合算法推荐风险治理现实情况,并基于灵敏度分析提出如下建议:加强算法素养教育,提高个人隐私保护意识;建立算法全流程监管机制,提升算法的可解释性;建立“制度+技术”机制,提高平台风险防范能力。
关键词:算法推荐;LDA;主题聚类;系统动力学;仿真分析
中图分类号:N941.3 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2023008
Abstract As an important application scenario in intelligent intelligence analysis, personalized and precise information services provided by algorithm recommendation add value to modern fast decision-making, but the problem of algorithm recommendation risk is also particularly prominent. Exploring the influencing factors of algorithm recommendation risk is crucial to scientifically proposing algorithm risk governance strategies, so this study has important practical significance. This paper using the LDA model for research paper topic clustering, clustering results should be compared with the "Regulations on the Recommendation Management administration of Internet Information Service Algorithms" for similarity calculation, to identify the risk influencing factors of algorithm recommendation, the system dynamics model is constructed from two dimensions of risk generation and risk governance, and then use Vensim PLE calculation software and text data to analyze simulation and sensitivity. Identify algorithm literacy, big data technology, and algorithm of prejudice, network security, and other factors, for the calculation of the data obtained through the calculation of the text to a better fitting method recommended management reality, and put forward the following suggestions based on sensitivity analysis: strengthen algorithm literacy education, to improve personal privacy protection awareness; Establish the whole process supervision mechanism of the algorithm to improve the interpretability of the algorithm; We will establish an "institutional and technological governance" mechanism to improve the platform's ability to prevent risks.
Key words algorithm recommendation; LDA; topic clustering; system dynamics; the simulation analysis
隨着大数据和人工智能的快速发展与应用,算法推荐逐渐进入公众视野,它通过提供个性化和精准化信息来增加价值、辅助决策,以智能情报为例,近年来算法推荐被广泛应用到智能情报分析项目中[1],并且在科技情报检索[2]、科技情报关联[3]等方面发挥了重要作用。但由于算法推荐本身的不透明性、不可解释性以及各个平台对用户隐私安全保护强度不一,平台质量无法保障等造成大数据杀熟、隐私泄露事件频发,严重威胁用户的隐私安全,成为当下亟需解决的问题。为此,2021年我国出台了《互联网信息服务算法推荐管理规定》(以下简称《规定》)[4],旨在对算法推荐风险进行规制,使用户免受其特定数据驱动的算法支配,确保用户隐私和数据安全。《规定》作为顶层设计,为我国算法风险治理的战略指导方向,但当前我国算法风险治理相关配套制度尚未建立,面对智能算法的快速迭代升级和用户数据量爆炸式增长的双重挑战,现有制度无法灵活地应对动态复杂的算法推荐产生的风险问题。因此,一方面应基于政策与科研主题的协同性[5],充分结合现有政策和科研成果,积极探寻算法推荐风险影响因素,有利于政府更为全面地制定算法风险治理策略;另一方面应基于系统仿真视角,模拟算法风险的动态,有利于科学地提出算法风险治理策略,具有重要的现实意义。
1 文献述评
随着互联网的广泛普及,使得人们对大量以算法推荐提供个性化信息服务的APP应用平台产生过度依赖,但同时算法推荐也为个人带来了隐私安全风险。国内外学者围绕这一现实问题从定性与定量两个维度展开研究:一是在定性研究方面。主要包括:(1)算法推荐应用风险治理。围绕算法推荐应用所产生的公共风险[6]、伦理安全[7-8]、信息茧房[9]、可解释性和透明性[10-11]等从风险预防和外部问责的方式展开治理[12-13],研究成果多集中在法学和公共管理等领域。如Banker和Khetani[14]基于实验证明了消费者经常过于依赖算法生成的推荐,对自身福祉构成潜在危害,并导致其在传播中可能影响其他用户的系统性偏见方面发挥作用。马天一提出在《规定》的基础上,以传统法学教义学方法解决未成年人数字化阅读中的算法推荐服务中存在的不良数据等风险[15];(2)算法推荐内生风险治理。从算法内部优化的视角,将安全因素考虑到算法的设计和应用当中。如Descampe等基于自动新闻推荐系统实验证明了嵌入算法的标准与其公开的意图相对应,提出定义算法问责制时应考虑对抗行为的鲁棒性,以更好地捕捉算法决策固有的风险[16]。马鑫等将内容安全风险问题纳入用户协同过滤推荐算法的优化过程,提出一种改进面向电商内容安全风险管控的CSCFR算法[17];二是定量研究方面。目前专门针对算法推荐的量化研究较少,如丁睿豪和夏德元使用Citespace软件对国内新闻传播学领域个性化算法推荐文献进行科学知识图谱分析[18]。陈军等使用社会网络分析方法等对WOS和CNKI的大数据算法推荐文献进行高频关键词共现等量化比较研究[19]。
综上所述,现有研究主要以定性的方式针对算法推荐产生的风险提出对应的治理措施,有少部分学者使用文献计量的方式进行算法推荐知识图谱构建,但较少有学者从系统仿真视角考虑算法推荐的风险治理。虽然已有学者使用系統动力学围绕政府数据开放[20-22]等展开研究,但其以定性的方式确定影响因素、以问卷调查法和专家访谈法获得仿真数据的研究方法存在一定程度上的主观性和片面性。因此,本文在已有研究的基础上,提出在政策与科研主题协同视角下,使用能够挖掘文本浅层语义信息的LDA模型定量识别算法推荐风险影响因素[23-24],并通过文本计算获得的数据,利用系统动力学方法对算法推荐风险影响因素进行仿真研究。本文主要贡献有两点:(1)通过政策与科研主题协同性定量识别算法推荐风险的影响因素;(2)通过文本计算为算法推荐系统流图进行科学化赋值。
2 研究方法
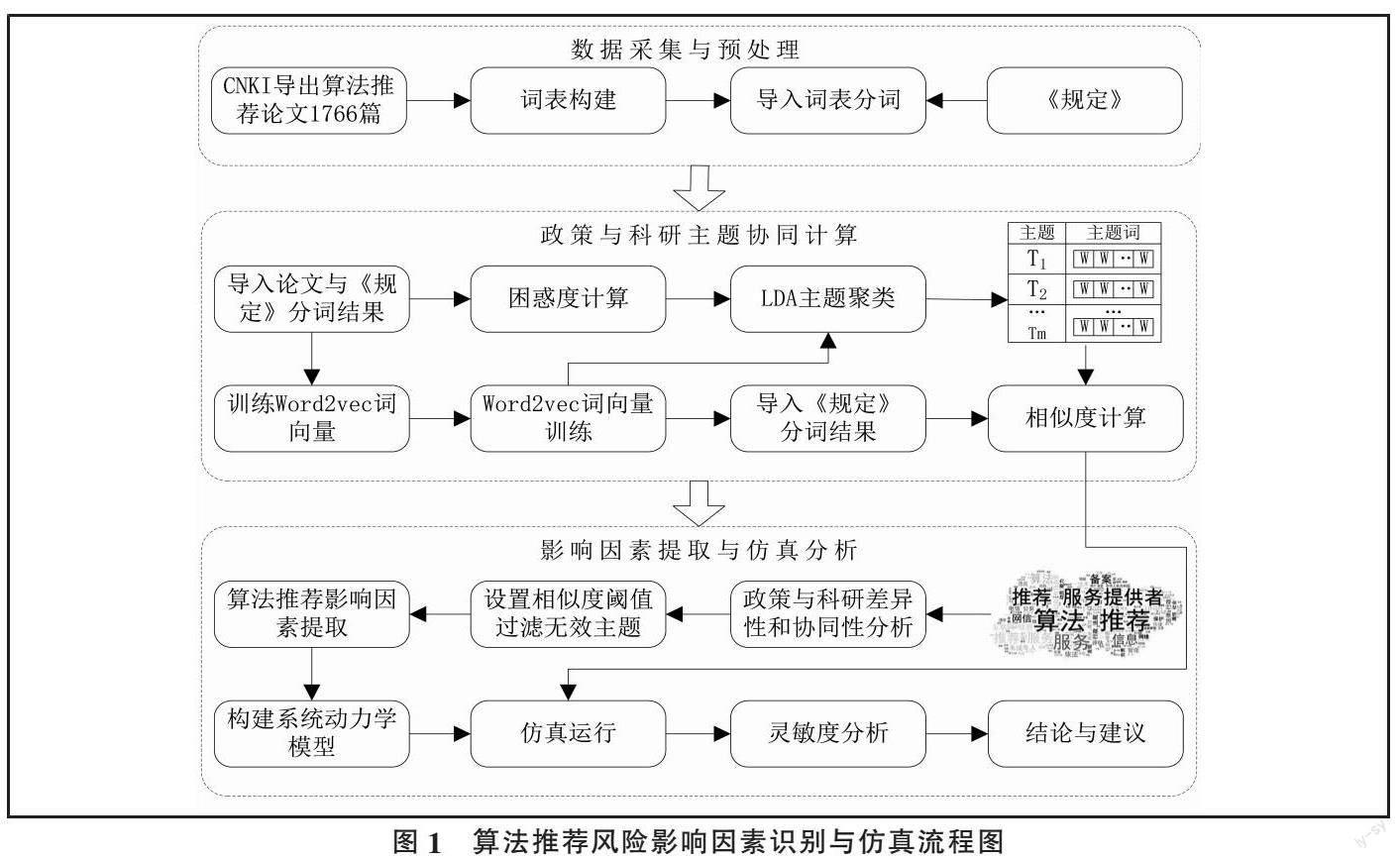
本文提出文本计算与系统动力学相融合的方法研究算法推荐风险治理。主要包括:数据采集与预处理、政策与科研主题协同计算、影响因素提取与仿真分析三个步骤(见图1)。
首先,选择CNKI数据库中算法推荐治理核心期刊论文作为研究对象,使用LDA进行主题聚类,然后结合《规定》使用Word2Vec训练词向量[25],使用余弦相似度计算每个主题与《规定》之间的相似度,基于政策和科研主题协同性,过滤协同性低的主题,提取出算法推荐影响因素;其次,在此基础上,使用系统动力学构建算法推荐影响因素之间的因果关系图和系统流图;最后,利用Vensim PLE软件,结合相似度数值对系统模型进行仿真运行和灵敏度分析,进而对我国算法推荐风险影响因素变化情况进行探讨。
3 实证研究
3.1 数据采集与预处理
鉴于科研成果通常以科研论文的形式呈现,本文选择《规定》和 CNKI中算法推荐科研论文作为数据源。首先,通过文献调研确定检索式为“算法推荐”OR“推荐算法”,在 CNKI数据库中进行主题高级检索,提取论文的篇名、摘要和关键词。同时为了聚焦算法推荐风险主题,基于《规定》从风险识别和风险治理两个维度进行人工初步筛选,截至时间到2023年2月,共筛选出2309篇;其次,提取科研论文关键词构建算法推荐的特征词表;最后,利用python语言jieba工具对由“篇名+摘要”组成的文本进行分词、去停用词等数据预处理操作。
3.2 主题数目确定
研究采用困惑度评价指标确定文本数据的最优主题数目。困惑度表示对文档所属主题的不确定性,困惑度越低,说明聚类的效果越好,主题数目最优[26],为防止过拟合,选取困惑度下降不明显或处于拐点的值,结合困惑度曲线最终确定最优主题数目为18(见图2)。
3.3 政策与科研主题识别
研究通过相似度定量探讨政策与科研主题的协同性。首先,使用LDA模型对分词后的论文的篇名、摘要及关键词进行主题聚类,生成主题-词的分布;其次,合并《规定》和论文数据,使用Word2Vec训练词向量;最后,使用余弦相似度计算《规定》与每个主题之间的相似度(主题识别和相似度计算结果见表1)。
3.4 政策与科研主题分析
由表1可知,算法推荐在政策与科研主题之间存在差异性和协同性特征,并根据主题的可解释性将0.25作为区分差异性和协同性的相似度阈值[27]。一是差异性(S<0.25),包括:T1、T6、T8、T11、T16五个主题。这类主题与《规定》差异性特征主要体现在三个方面:(1)算法推荐文本分析方法,如语义、位置、语义分析等主题词;(2)算法推荐的方式和过程,如个性化推荐、推荐系统等主题词;(3)推荐算法的设计,如差分隐私、协同过滤推荐等主题词。二是协同性(S>=0.25),这类主题反映了《规定》和科研论文在算法推荐方面具有一定共性,科研能够围绕算法风险治理的顶层设计进行完善治理策略,能够从学术研究和政府治理等多个层面反映出我国算法推荐治理现状。基于此,本文选择与《规定》具有协同性的主题作为算法推荐影响因素的来源。
3.5 政策和科研主题协同视角下的系统动力学模型构建
系统动力学可以实现对真实系统的仿真,能够有效地揭示复杂系统在各种因果关系作用下所呈现出的动态变化规律[28]。因此,运用系统动力学方法研究算法推荐风险问题,能够从系统视角深入地分析算法推荐风险治理的结构、功能与行为之间的动态关系,从而为我国算法推荐治理提供科学化的建议。
(1)系统边界。以《规定》所涉及的风险要素与治理要素作为系统的边界,可以将LDA主题识别结果划分为:算法推荐风险、算法推荐治理、算法推荐主体和信息技术应用四大类。每类中所包含的影响因素取自《规定》与科研论文协同性的主题。针对存在主题词不明确的情况,设定选取规则:若同一主题包含相同含义主题词,则进行补充;若不存在同一主题包含相同含义主题词,则结合数据或算法本体安全治理特征进行整合(结果见表2)。
(2)模型假设。由于算法推荐系统动力学模型构建涉及影响因素众多,包括用户、数据、智能算法、平台、政府等,为保证模型的正常构建,无法囊括所有因素,故做以下假设:
假设1:采用一种开放的态度,不刻意区分数据与信息,且算法推荐风险形成与风险治理是持续运转的动态过程,要素之间能够互动反馈;
假设2:通过用户隐私安全程度来表征风险治理效果,且仅使用算法推荐风险程度和算法推荐治理程度来衡量;
假设3:算法推荐模型中算法推荐风险程度、算法推荐治理程度及用户隐私安全程度默认初始值为1,并在多次预仿真实验中调整和确定,其余变量赋值通过文本计算方式设定;
假设4:算法推荐模型只受划定系统边界内因素的影响,不涉及平台利益等其它外部因素。
(3)因果关系图。为了刻画出算法推荐治理影响因素之间的逻辑关系和反馈回路[29],本文在影响因素识别的基础上,梳理要素之间的因果关系,并从风险形成与风险治理的视角构建算法推荐系统的因果关系图(见图3)。算法推荐风险是指平台使用智能推荐算法基于用户行为数据提供个性化服务过程产生的各种安全风险;算法推荐治理是指对算法推荐产生的风险进行治理,主要以政府网络安全审查为主导,用户数据保护、平台风险防范等多方参与的协同治理。
研究系统中包括两条重要的回路类型(见表3):回路类型1从系统层面呈现算法推荐从风险形成到风险治理后,风险降低的过程,在此过程中,虚假数据是算法推荐风险的重要源头,这类数据若被智能推荐算法应用,会产生谣言传播等一系列风险,从而导致算法推荐风险程度增加,进而需要政府开展网络安全审查等治理工作以降低风险,因此,虚假数据所反映出的数据质量问题决定了算法推荐风险的程度;回路类型2主要是从用户行为数据层面呈现算法推荐风险与用户网络活动安全保护能力的关系,用户网络活动安全保护能力越强,用户进行网络活动所产生的行为数据量越少、脱敏程度越高,从而能够降低算法推荐风险的程度。
(4)系统流图。为探究算法推荐风险形成与风险治理之间的内在结构关系及治理机制,研究基于因果关系图,根据实际情况在模型中不断修正并最终确定各子系统中相应变量,最终绘制出算法推荐的系统动力学模型流图(见图4)。
该系统流图包括3个状态变量,4个速率变量,10个辅助变量和15个常量(见表4)。
(5)参数设定。由于《规定》颁布较晚,处理事件产生的数据有限,通过以上分析可知,算法推荐是以“个人-数据-算法-平台-政府”构建的具有非线性、复杂性、动态性的循环交互系统,影响因素宽泛、复杂,本文提出文本计算的方法,将影响因素对应的主题与《规定》之间的相似度数值作为参数的初始设定,并乘0.1进行数据归一化处理,如虚假数据取自T9主题,则其初始值为0.51*0.1=0.051。相似度数值反应了《规定》与科研论文的协同性,影响因素选取是概率值较高的主题词,能够反映出算法推荐关注的重点。因此,将相似度数值作为系统仿真数据具备合理性和科学性(主要方程设计及参数说明见表5)。
4 仿真分析
4.1 模型仿真分析
對算法推荐模型进行有效性检验,旨在观察通过文本计算获得的仿真数据是否符合真实系统的特点与变化规律,确保模型的有效运行。利用仿真软件Vensim PLE,将仿真时间限定为12个月,时间步长为1个月,选取关键变量进行验证,得到初始状态下仿真结果(见图5)。
(1)已知风险率和治理率呈先快速增长后逐渐下降的趋势。这是由于算法推荐中产生的隐私泄露等可检测的已知风险,能够通过《规定》等进行规制。因此,在开展算法推荐治理工作的前一个月内,已知风险被快速监测和治理,对应的风险率和治理率快速增长,但随着时间的推移,可治理的已知风险逐渐下降,对应的风险率和治理率也随之下降。
(2)潜在风险率和未治理率呈先快速增长后逐渐增长的趋势。潜在风险是指由智能算法所导致的算法黑箱、算法共谋、算法操纵等难预测的未知风险。且随着大数据、区块链、人工智能以及元宇宙等技术的发展和场景应用,潜在风险会不断加剧。因此,整体上潜在风险率和未治理率呈增长的趋势,从而导致算法治理程度也呈上升趋势。而在系统中前一个月内潜在风险率和未治理率增长幅度较大的原因可能是由于治理手段均是针对已知风险的治理,而风险的产生是多方面,且潜在风险转变成已知风险需要一定的时间。
(3)用户隐私安全程度始终呈持续增长趋势。尽管治理率在后期呈逐渐下降、潜在风险率和未治理率呈增长趋势,但算法推荐风险经过系统治理,总体上算法推荐风险程度的增长小于算法推荐治理程度的增长,从而使得用户隐私安全程度始终呈持续增长的趋势。因此,该系统仿真变化曲线符合算法推荐治理现实情况,同时也证明了使用文本计算获取的数据的合理性。
4.2 灵敏度分析
通过算法推荐系统因果关系图和系统流图分析可知,数据与算法都是两个不可分割的数字世界底层逻辑融合体,平台是数据与算法融合的载体。为探究算法推荐关键变量对系统的影响及影响程度,本文对算法推荐应用过程涉及的影响因素进行灵敏度分析[30],即从“用户-算法-平台”视角选取算法素养、算法黑箱、平台风险防范3个变量。设定各变量初始值为文本计算得到的数值,根据控制变量法将其中某一个变量上下变化0.02,其它变量数值不变,其中数值变化反映了在某一时间内《规定》发布修订版或该主题论文数量变化情况。以上三个影响因素分别从用户、算法及平台维度探讨算法推荐治理,能够较好地反映对算法推荐系统的影响。
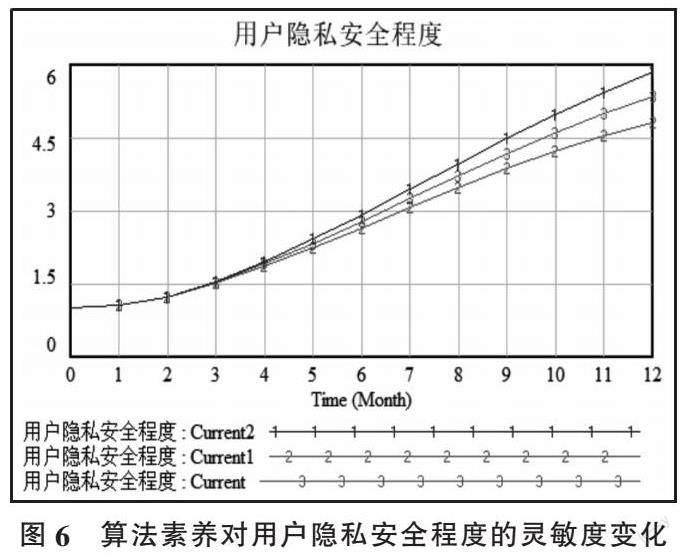
(1)算法素养。将算法素养分别设置为Current(0.044),Current1(0.024),Current2(0.064),通过对比三条模拟曲线发现,随着算法素养不断提升,用户隐私安全程度能够得到明显提高,呈正向影响(见图6)。算法是由数据驱动的,通过系统反馈回路可知,用户行为数据是算法推荐风险产生的关键。因此,提高用户算法素养,进而提高用户网络活动安全保护能力,能起到事前风险防范,从算法推荐风险源头解决问题的作用。此外,与算法素养具有同样作用的还包括媒介素养及思想政治教育。
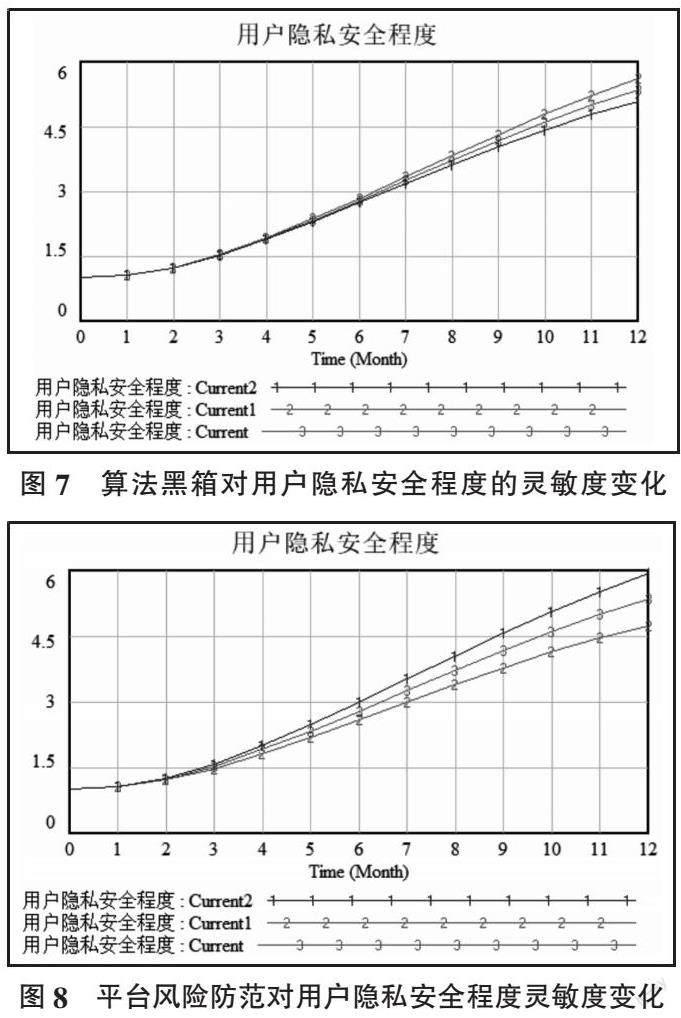
(2)算法黑箱。将算法黑箱分别设置为Current(0.044),Current1(0.024),Current2(0.064),通过对比三条模拟曲线发现,随着算法黑箱程度的提高,用户隐私安全程度逐渐下降,呈负向影响(见图7)。但由于系统内部算法推荐治理主要聚焦于用户和制度在系统内对用户隐私安全程度影响,这类风险对用户隐私安全程度表现变化幅度相对较小。由于算法的复杂性导致了算法黑箱的形成,这也是是技术因素的体现,需要从算法设计本身、算法可解释性层面考虑算法黑箱问题,将安全贯穿到算法的全生命周期内,从而提高算法的鲁棒性和安全性。
(3)平台风险防范。将平台风险防范能力分别设置为Current(0.041),Current1(0.021),Current2(0.061),通过对比三条模拟曲线发现,随着平台风险防范的提高,用户隐私安全程度能够得到明显提高,呈正向影响,特别是后期增幅显著(见图8)。政府作为监管者,往往只能起到事后风险问责的作用,而平台作为数据和算法融合的载体,决定了提供用户信息服务方式和内容。随着政府支持平台参与算法推荐治理,平台的风险防范能力逐渐提高,用户隐私安全程度进一步得到保障。因此,强化平台风险防范可以起到事前风险预防、事中风险监控的作用。
5 结论与建议
本文提出政策文本计算与系统动力学相融合的方法,使用LDA模型并结合相似度定量识别出:算法素养、大数据技术、算法偏见、网络安全审查等影响因素,在此基础上建立算法推荐治理系统动力学模型,并使用文本计算获取的数据,对算法推荐影响因素作用过程进行系统仿真,并对已知风险率、潜在风险率、治理率、未治理率、算法推荐风险程度、算法推荐治理程度及用户隐私安全程度进行了有效性检验,证明系统仿真表现符合现实情况,为算法推荐治理及政策系统仿真研究提供了方向和理论参考。存在的不足之处在于,影响因素的提取具有一定的经验因素,未来将进一步探索主题识别模型并提高影响因素识别的准确性。基于灵敏度分析结果,提出以下建议:
(1)加强算法素养教育,提高个人隐私保护意识。受当下疫情等突发事件的影响,网络成为日常生活和学习必不可少的组成部分,需要进一步加强算法素养教育,预防信息泄露、谣言传播、大数据杀熟等事件发生。一是建立算法素养评估体系,针对不同群体特征,进行算法素养差异性分析,从而有针对性地开展全民算法素养教育,以及对算法素养教育进行反馈评估;二是根据算法素养评估体系开展算法素养教育。对于算法推荐设计者与控制者,需要掌握算法安全专业知识、算法技术伦理规范及法律规范,起到在源头开展算法推荐治理的作用;对于算法推荐治理主体和普通用户,特别儿童、老人等信息弱势群体,可以依托课程设置、网络资源等开展算法知识通识性教育,使人们在特定算法推荐应用情景下,认识算法的存在及其可能带来的风险,提高防范、对抗风险的能力[31]。
(2)建立算法全流程监管机制,提升算法的可解釋性。规制算法黑箱问题的重要途径是提高算法的可解释性,而提高算法的可解释性可通过建立算法全流程设计的监管机制,从算法黑箱产生的前中后三方面进行考虑。一是算法设计前:算法的形成是为了从数据中总结出普遍规律和发现新的知识。因此,在保证算法精度的情况下,尽量生成具有可解释性的算法,可通过可视化、异常点排查、代表性样本选择等方法明确训练数据的质量和特点,并通过给算法增加稀疏性、可加性、单调性等适度降低算法的复杂度,使得算法具有可解释性。二是算法设计中:算法初步形成后,可通过第三方平台进行风险检测,其中可解释性检测可通过对比敏感性分析、LIME、SHAP等解析方法并出具合格报告;三是算法设计后:算法通过第三方平台检测合格后,递交政府进行算法监管沙盒测试[32],以发现算法在不同真实应用场景中导致变化的原因,从而降低算法重构和应用风险。同时政府建立算法备案机制,便于对算法应用后进行审查和回溯。
(3)建立“制度+技术”治理机制,提高平台风险防范能力。互联网平台作为发展数字经济重要的服务机构,具有关系多层性、主体多元性、影响跨边性、功能社会性及边界动态性[33],需要在强化平台风险监管的同时,平衡好安全与创新发展的关系[34]。一是需要以平台为载体,加强数据与算法的协同治理。虽然目前我国出台了《数据保护法》《个人信息保护法》《网络安全法》及《规定》形成“三法一规”的顶层设计[35],但以数据为驱动的算法推荐涉及各种风险管理场景,需要解决算法推荐的精准性、个性化与数据安全的平衡问题,围绕“三法一规”构建数据与算法协同的安全标准体系;二是需要政策支持平台参与算法推荐治理,助推平台突破核心技术以提高风险监测和安全评估能力。通过差分隐私、透明度工具等新技术应用风险监管以弥补政府外部问责的监管漏洞,从而将平台真正融入风险治理中,与政府、社会、个人等构建起多方参与、协同共治的风险治理模式,进而保障个人数据安全,引导更为公平、开放的数字竞争市场。
参考文献:
[1] 张涛,马海群.智能情报分析中算法风险及其规制研究[J].图书情报工作,2021,65(12):47-56.
[2] 张建伟,李月琳,李东东.网络学术资源平台个性化推荐服务特征研究[J].情报资料工作,2021,42(5):76-83.
[3] 趙辉,化柏林,何鸿魏.科技情报用户画像标签生成与推荐[J].情报学报,2020,39(11):1214-1222.
[4] 国家互联网信息办公室.互联网信息服务算法推荐管理规定[EB/OL].[2023-01-01].http://www.cac.gov.cn/2022-01/04/c_1642894606364259.htm.
[5] 文禹衡,付张祎.基于计量分析的我国数据确权政策与科研协同研究[J].现代情报,2022,42(10):58-70.
[6] 夏梦颖.算法推荐可能引致的公共风险及综合治理路径[J].天府新论,2022(2):124-129.
[7] 周颖玉,柯平,刘海鸥.面向算法推荐伦理失范的人机和谐生态建构研究[J].情报理论与实践,2022,45(10):54-61.
[8] Seaver N.CARE AND SCALE:Decorrelative Ethics in Algorithmic Recommendation[J].Cultural Anthropology,2021,36(3): 509-537.
[9] 李龙飞,张国良.算法时代“信息茧房”效应生成机理与治理路径——基于信息生态理论视角[J].电子政务,2022(9):51-62.
[10] 苏宇.优化算法可解释性及透明度义务之诠释与展开[J].法律科学(西北政法大学学报),2022,40(1):133-141.
[11] Watson H J,Nations C.Addressing the Growing Need for Algorithmic Transparency[J].Communications of the Association for Information Systems,2019,45(1):26.
[12] 林洹民.个性化推荐算法的多维治理[J].法制与社会发展,2022,28(4):162-179.
[13] 许可.算法规制体系的中国建构与理论反思[J].法律科学(西北政法大学学报),2022,40(1):124-132.
[14] Banker S.Khetani S.Algorithm Overdependence: How the Use of Algorithmic Recommendation Systems Can Increase Risks to Consumer Well-Being[J].Journal of Public Policy & Marketing,2019,38(4):500-515.
[15] 马天一.算法推荐视域下的智慧图书馆未成年人保护进路[J].图书馆论坛,2023,43(2):14-25.
[16] Descampe A,Massart C,Poelman S,et al.Automated news recommendation in front of adversarial examples and the technical limits of transparency in algorithmic accountability[J].Ai & Society,2022,37(1):67-80.
[17] 马鑫,王芳,段刚龙.面向电商内容安全风险管控的协同过滤推荐算法研究[J].情报理论与实践,2022,45(10):176-187.
[18] 丁睿豪,夏德元.传播学视角下算法推荐研究的学术场域——基于2010-2019年新闻传播学文献的Citespace可视化科学知识图谱分析[J].新闻爱好者,2022(1):16-21.
[19] 陈军,谢卫红,陈扬森.国内外大数据推荐算法领域前沿动态研究[J].中国科技论坛,2018(1):173-181.
[20] 马海群,张涛,李钟隽.新冠疫情下政府数据开放与安全的系统动力学研究[J].现代情报,2020,40(7):3-13.
[21] 张晓娟,莫富传,冯翠翠.政府数据开放价值实现的机理:基于系统动力学的分析[J].情报理论与实践,2022,45(5):75-83.
[22] 袁红,王焘.政府开放数据生态系统可持续发展实现路径的系统动力学分析[J].图书情报工作,2021,65(17):13-25.
[23] Blei D M.Probabilistic topic models[J].Communications of the ACM,2012,55(4):77-84.
[24] Blei D M,Ng A Y,Jordan M J.Latent Dirichlet allocation[J].Machine Learning Research,2003,3(Jan):993-1022.
[25] Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[J].Advances in Neural Information Processing Systems,2013,26:3111-3119.
[26] Griffiths T L,Steyvers M.Finding scientific topics[J].Proceedings of the National academy fo Sciences,2004,101(S1):5228-5235.
[27] 李慧,胡吉霞,佟志颖.面向多源数据的学科主题挖掘与演化分析[J].数据分析与知识发现,2022,6(7):44-55.
[28] 张涛,马海群.人工智能数据安全影响因素的系统动力学研究[J].情报探索,2021(3):1-10.
[29] 孙华伟,王克平,张亚男,等.基于大数据思维的科技智库情报服务机制系统动力学仿真研究[J].情报理论与实践,2022,45(12):128-137.
[30] 赵又霖,曹宏楠.面向应急管理的政务微博信息交流效率及其影响因素研究[J].农业图书情报学报,2022,34(9):72-85.
[31] 彭兰.如何实现“与算法共存”——算法社会中的算法素养及其两大面向[J].探索与争鸣,2021(3):13-15.
[32] 张涛,马海群.智能情报分析中数据与算法风险识别模型构建研究[J].情报学报,2022,41(8):832-844.
[33] 肖红军,李平.平台型企业社会责任的生态化治理[J].管理世界,2019,35(4):120-144.
[34] 李凌.平台经济发展与政府管制模式变革[J].经济学家,2015(7):27-34.
[35] 马海群,张涛.我国数据与算法安全治理:特征及对策[J].电子政务,2023(3):118-128.
作者简介:崔文波,男,黑龙江大学信息管理学院硕士研究生,研究方向:数据分析与知识发现;张涛,男,黑龙江大学信息管理学院副教授,研究方向:政策文本计算与数据分析;孙钦莹,女,黑龙江大学信息管理学院讲师,研究方向:应急情报管理;马海群,男,黑龙江大学信息管理学院二级教授,博士生导师,研究方向:信息政策与法律、数据治理。
