网约车感知等待时间判别模型及影响因素分析
2023-06-17胡三根王小霞
胡三根,李 春,杨 莹,王小霞
(广东工业大学 土木与交通工程学院,广东 广州 510006)
网约车不仅对城市居民出行方式产生了深远的影响[1],更是未来智慧城市交通系统的重要组成部分[2]。截至2021年12月,我国网约车用户规模达4.53亿[3],从其用户结构来看,大学生群体占主要比重[4],可见大学生出行是社会出行的重要组成部分[5-6]。车辆等待时间是影响乘客出行体验的关键因素[7],等待时间可分为实际等待时间与主观感知等待时间[8]。其中,实际等待时间是乘客等待车辆到达上车点的真实时间,而主观感知等待时间是乘客感知的等待时间,是对等待时间的主观估计。现有研究表明感知等待时间与实际等待时间之间会存在偏差,人们往往会高估真实等待时间,并且主观感知等待时间对乘客的情感反应如不确定、生气等会造成负面影响,对交通服务的评价如满意度等的影响效果更为显著[9],进而会影响乘客在交通出行方式中的选择。因此,研究大学生等待感知时间至关重要,可为网约车平台通过运营管理和针对个人感知情况提高其服务水平提供参考,进而增强网约车对大学生群体的吸引力。
近年来,感知等待时间的影响因素研究受到学者们越来越多的关注。Feng等[10]发现个人因素,如出行目的及出行时间段等因素对等待时间感知会有一定的影响。Tyrinopoulos等[11]发现女性乘客比男性对等待时间更敏感。Brakewooddeng等[12]、Gooze等[13]发现移动设备给用户提供实时信息时,会对乘客的等待时间感知有益处。Watkins等[14]发现没有实时信息的乘客,其感知的等待时间要大于实际等待时间。Lagune-Reutler等[15]对候车点的绿化、空气等调查发现,通过美化候车点的环境,可以削弱乘客对等待时间感知。Ji等[16]发现创造良好的等待环境对减少等待时间感知有积极作用。Millonig等[17]通过分析乘客的活动与等待时间感知,发现不同的候车行为对等待时间感知不同。孙祥龙等[18]发现乘客通过采取打电话、上网和读报刊杂志等行为可以降低自身的感知偏差。虽然上述研究证实了个人特征、环境情况、移动设备、候车行为是感知等待时间的重要影响因素,但是现有研究多从单一角度去探究感知等待时间的影响因素。此外,现有文献中仍未发现针对大学生群体的网约车感知等待时间的研究。
为此,以大学生群体为调查对象,以多元线性判别分析模型为基础,建立网约车感知等待时间判别模型。通过模型的分类结果分析个人特征、环境情况、移动设备、候车行为4种影响因素对感知等待时间的影响机理,并为减少感知等待时间提出建议,为增强网约车服务水平提出参考。
1 问卷设计
以大学生群体为对象设计调查问卷。调查内容分为2部分:大学生个体特征和问卷变量测量。其中,问卷变量测量包括候车点环境对乘客等待时间感知的影响程度、乘客感知等待时间和移动设备对乘客等待心理的影响以及乘客候车行为的调查。个体特征变量设置如表1所示。

表1 个体特征变量Table 1 Personal characteristics
由于候车点环境因素、移动设备、候车行为这3个影响因素对人的感知不能直接观测,使用显变量表征潜变量,并采用李克特五级量表进行调查。移动设备和候车行为中的1~5分别表示 “很不同意”“不同意”“不确定”“基本同意”“十分同意”;环境因素中的1~5分别是“没有影响”“影响小”“中度影响”“影响大”“影响非常大”;感知等待时间将直接询问乘客感知等待的时间,具体见表2。

表2 表征潜变量的显变量Table 2 Significant variables representing latent variables
2 数据分析
2.1 人口统计学分析
本次调查共收集540份问卷,去掉作答用时较短和填写不完整、不规范的问卷后(如所有答题相同或者漏答),共获得492份有效数据。参与调查的大学生个体特征统计数据如表3所示。
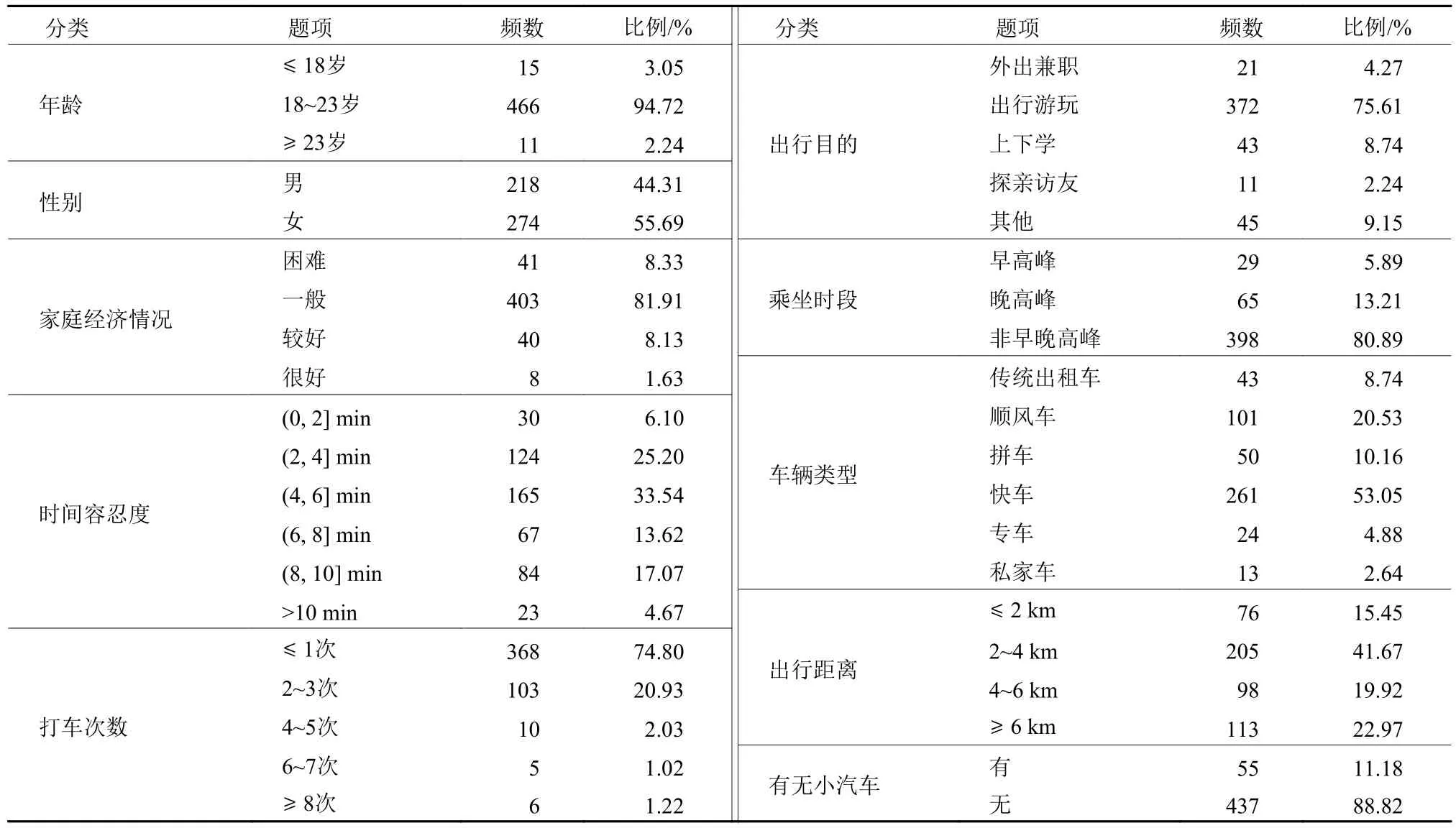
表3 个体特征统计数据Table 3 Statistical data of personal characteristics of passengers
2.2 信度与效度分析
模型建立前需对问卷进行信度效度检验,以保证问卷的可靠性和有效性。采用Cronbach’s α信度系数来测定本研究问卷的信度,系数大于0.8表明问卷具有较高的内在一致性[20]。采用KMO(Kaiser Meyer Olkin)检验统计量和巴特利特球形度来检验本研究问卷中的量表是否可以进行因子分析,KMO值一般要在0.7以上,说明适合做因子分析。巴特利特球形度检验的显著性小于0.001时,则说明原始变量之间存在相关性[21]。具体结合以下标准来判断问卷是否具有较好的结构效度[22]:(1) 公共因子应与问卷设计时
的结构假设的组成领域相符,且公共因子的累计方差贡献度要大于40%;(2) 每个条目都应在其中某一公共因子上有较高的负荷值(大于0.4)。
由表4可知,所有题项的Cronbach’s α系数均大于0.8,说明本问卷数据可靠性良好。由表5可知,KMO值大于0.9,并且巴特利特球形度检验的显著性小于0.001,说明问卷可做因子分析。此外,从表4可知累计方差贡献率已达到71.813%,表明每个问卷项目71.813%以上的方差都可以用公共因子解释;而且问卷的每个题项都在其中某个公共因子上有较高的负荷值。这些均符合上述判断标准,表明本问卷具有良好的效度。

表5 KMO和巴特利特球形度检验Table 5 KMO and Bartlett test
3 多元线性判别分析模型
3.1 模型假设
虽然通过问卷调查可以很容易获得受访者的实际等待时间,但是用确切的数值很难准确表达对时间流逝的主观感知结果[23]。因此,为了能更容易反映个体对等待时间的主观感知性,以及消除等待时间调查结果的随意性,将等待时间Y按照长短划分为“短时间(Y1) ”“中等时间(Y2) ”和“长时间(Y3)”来体现对等待时间的主观感知,即 0 ≤Y1≤5 min、5 min
本次调查到的有效数据样本量492份,属于大样本,根据林德贝格−列维中心极限定理,当样本个数大于30抽样,样本均值的抽样分布都将近似服从正态分布,同样,由于组内的样本规模较大,各组协方差矩阵基本相等[25]。为此,满足假设条件①和条件②。另外,如表6所示,在对所有显变量组间做均值差异和多重共线性检验后,发现所有显变量的Wilks’λ(组内平方和与总平方和之比)值都大于0.8,且全部满足容许度TOL(Tolerance)大于0.1和方差膨胀因子VIF(Variance Inflation Factor)小于10的条件,即所有显变量之间均值差异不大且不存在多重共线的情况[26],满足条件③与④。综上,判别分析模型可应用于本文对象的研究。
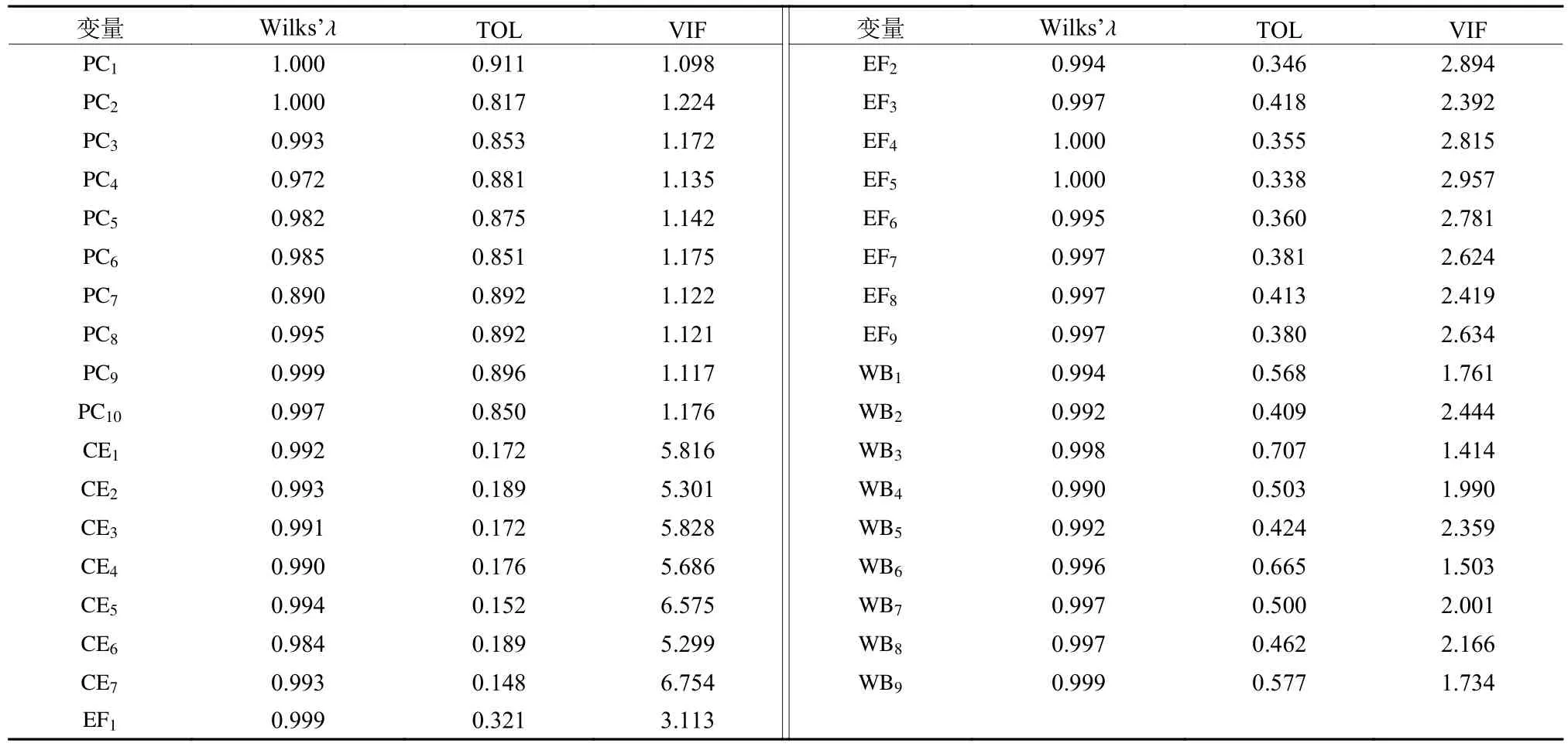
表6 显变量组间均值差异与多重共线性检验Table 6 Test of mean equality and multicollinearity between explanatory variable groups
3.2 模型建立
选择所有显变量作为多元线性判别分析模型的解释变量,将等待感知时间作为分类变量,其值域为{1,2,3} ,分别记为Y1、Y2、Y3。由于显变量不存在多重共线性,可直接把显变量全部代入判别函数中,并借助交叉验证法验证判别分析模型对未知分组的观测值的预测精度。由于原始变量所取的测量单位有所不同,非标准化系数之间没有可比性,为此,将采用标准化判别系数,使用IBM SPSS Statistics 25.0可以得到以下判别函数。
一般认为,具有较大标准化判别系数的判别变量对总体判别函数的贡献较大,由判别函数可知,PC7的系数最大,这说明时间容忍度这一指标变量对判别函数的正向影响较大,即乘客对候车时间的容忍度是感知等待时间的一个关键影响因素。
3.3 模型检验
为证明模型具有较好的判别能力,需要对模型的判别能力做进一步的检验,判别函数越好,其特征值便会越大。判别函数的特征值如表7所示,第1判别函数解释了81.30%的方差,第2判别函数仅解释了18.70%的方差,两个判别函数共同解释全部的方差。

表7 判别函数的特征值Table 7 Eigenvalues of discriminant function
由于 λ值在判别分析中表示总方差未被不同组解释的那些比例,表8中对比了两个判别函数的显著性,得到第1判别函数在0.001的显著水平上是显著的(p=0),第2判别函数则不显著(p>0.05) 。综上所述,第1判别函数是可以被接受的,因此只需要对第1判别函数展开分析,这也是在模型建立时只给出一个函数(见式(1))的原因。

表8 判别函数的λ 值检验Table 8 λ value test of discriminant function
4 结果分析
4.1 判别分析的分类结果
表9给出了判别分析的分类结果,其中,原始判别是指对建模样本观测到的分组统计结果;预测结果是指依据判别模型所得出的个体实际等待时间应归属的长短范围类别。由表9可知,在原始判别中,Y1组 328个观测中有222个判断正确,Y2组136个观测中有72个判断正确,Y3组28个观测中有15个判断正确,即共有309个观测已正确分配到对应组别,平均正确率为62.8%,说明有62.8%的个体的感知等待时间与预测时间是基本一致的。但存在以下误分类现象:在Y1组中出现106个判断错误,其中模型犯第2类错误的百分比是19.82%,模型犯第3类错误的百分比是12.50%;在Y2组中有64个判断错误,其中模型犯第1类错误的百分比是30.15%,模型犯第3类错误的百分比是16.91%;在Y3组共14个判断错误,其中模型犯第1类错误的百分比是25.0%,模型犯第2类错误的百分比是21.43%。因此最常发生的错误分类为将Y2组数据归类到Y1组中,说明个体认为自己等待时间属于“中等时间”时,预测感知时间偏向于“短时间”的概率较高,即发生个体感知的等待时间大于预测感知等待时间的概率会较高。同时,观察正确分类组别的百分比可知,个体感知等待时间的准确率为Y1>Y3>Y2,即个体对等待时间感知的准确度会在“短时间”“长时间”中感知是比较准确的;在错误分类结果中,预测感知等待时间大于个体感知等待时间的观测数据共129个,明显多于预测感知等待时间小于个体感知等待时间的55个观测数据。由此可知,在等待过程中,预测感知等待时间大于个体感知等待时间发生的概率更大。此外,通过利用交叉验证法对模型的预测效果进行验证,发现在交叉验证中,Y1组共328个观测数据中有205个判断正确,123个判断错误,其中模型犯第2类错误的百分比是22.87%,模型犯第3类错误的百分比是14.63%;Y2组共136个观测数据中有54个判断正确,82个判断错误,其中模型犯第1类错误的百分比是36.76%,模型犯第3类错误的百分比是23.53%;Y3组共28个观测数据中有7个判断正确,21个判断错误,其中模型犯第1类错误的百分比是42.86%,模型犯第2类错误的百分比是32.14%;综合来看,对模型样本进行判断的平均正确率为54.1%,与原始判别的正确率差异不大。

表9 判别分析的分类结果Table 9 Classification results of discriminant analysis
4.2 影响等待感知时间的因素分析
因为判别函数无法直接探究各个变量对各组分类的影响,所以将通过3个分类函数中的系数来探究所有显变量对感知等待时间的影响,即将所有显变量分别代入到3个分类函数中,根据函数值大小来判定属于哪个分组。3个分类函数中各变量系数如表10所示。

表10 3个分类函数中的各变量系数Table 10 Coefficients of variables in three classification functions
4.2.1 在同组分类函数中的影响分析
由表10可知,所有显变量的系数均不为0,即显变量均与感知等待时间有关,同时也证明了个人特征、移动设备、环境因素、候车行为这4个因素对感知等待时间是有影响的,与此前研究的结论相一致[10-18]。除此之外,在3组分类函数中,仅有个人特征所对应的10个显变量中的系数均大于0,说明大学生的个人属性对于感知等待时间是有正向积极作用的。对于探究移动设备、环境因素、候车行为对感知等待时间的影响,需要假设这3个潜变量的25个显变量均为1,即在个人特征相同的条件下,探究3个因素对因变量的影响。由表11可知,通过计算得出3个因素对3组分类函数的函数值的贡献度大小,可以得知在同一组分类函数中3个潜变量对感知等待时间的影响大小为:候车行为>环境因素>移动设备。
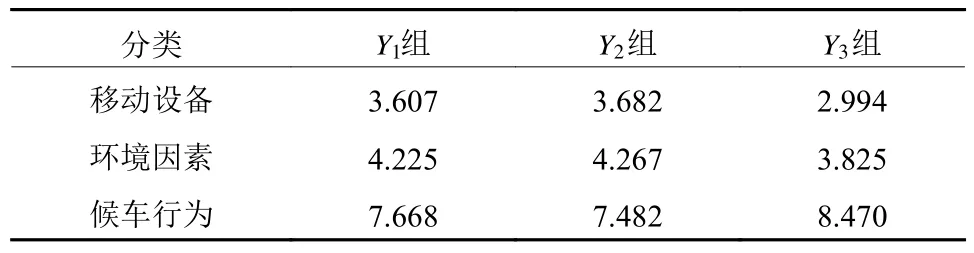
表11 3个因素对3组分类函数值的贡献度Table 11 Contribution of three factors to three groups of classification function values
4.2.2 在不同组分类函数中的影响分析
在对不同组分类函数分析前,需设定所有变量均取值相同,即假设变量取值全为1,根据表10、表11可以得出如下结论。
从移动设备方面来看,移动设备对Y2组分类函数的贡献值最大,说明移动设备对感知等待时间中的“中等时间”影响最大。对移动设备的7个显变量进行分析可知,C E1、CE6在Y1组中的系数最大,说明车辆实时位置和预计上车时间会使得个体的感知等待时间变短。原因可能是,当乘客知道车辆实时位置和预计上车时间会让乘客对自己的出行更放心,从而会减少他们感知等待时间。C E2、CE7在Y2组中的系数最大,说明车辆信息(车牌、型号等)和预计到达目的地的时间对分组为“中等时间”的感知等待时间影响最大;C E3、CE4、CE5在Y3组中的系数最大,说明在移动设备上能看到司机个人信息、规划好的路线、实时的道路通畅情况会使感知等待时间倾向于Y3组 。其中,C E3在判别函数(1)中的系数绝对值最小,说明司机的个人信息对感知等待时间的影响较小;CE4会对判别结果产生负向影响(在判别函数(1)中系数为负),可见,规划好的路线会极大程度上减少乘客的感知等待时间,反之则会造成乘客的感知等待时间增加;C E5在判别函数(1)中的系数为正数,对判别结果产生正向影响,说明道路通畅情况不佳时,乘客会产生焦虑心理,进而导致其感知等待时间的增加。然而,由于C E5在分组函数中的系数为负数,如果让乘客了解到道路通畅情况时,会有利于减少乘客的感知等待时间。
从环境因素方面来看,环境因素对Y2组分类函数的贡献度最大,说明环境因素对感知等待时间中“中等时间”的影响很大。具体来说,EF2、EF3、EF7在Y1组中的系数最大,说明天气、光照、周围有无其他人会使得个体等待感知时间偏向于Y1组,即天气与光照情况较好以及周围有人的情况下,会让个体感知等待时间缩短。E F6、EF9在Y2组中的系数最大,说明周围景色和心情好坏对分组为“中等时间”的感知等待时间影响最大。EF1、EF4、EF5、EF8在Y3组中的系数最大,说明温度、空气质量、噪音、有无亲朋好友陪伴这4个变量会使得个体感知等待时间偏向于Y3组,原因可能是当这些环境因素不利的时候,容易导致大学生产生不舒服的心理,进而增加大学生的感知等待时间。
从候车行为方面来看,候车行为对Y3组分类函数的贡献度最大,说明候车行为将会极大延长感知等待时间。具体而言,WB7、WB9、WB5、WB6在Y1组中的系数最大,说明时刻关注车辆到达位置、欣赏周围风景、上网以及静待车辆到达这4个行为会使得个体等待时间感知偏向于Y1组,即这些行为都会减少对等待时间的感知。W B2在Y2组中的系数最大,说明打电话这一行为对分组为“中等时间”的感知等待时间影响最大。W B1、WB3、WB8、WB4在Y3组中的系数最大,说明跟人聊天、听音乐、观望车辆是否到达以及吃东西这4个行为会使得个体感知等待时间偏向于Y3组。这可能是由于聊天、听音乐、吃东西这些行为有利于注意力的转移,会比较难以准确预测流逝的时间,并且大多数人往往在进行这些行为时会高估自己的感知时间能力。然而,个体若出现一直在观望路上车辆是否到达这一行为,则说明个体此时的心情已经比较焦虑了,对车辆到达十分渴望,这往往会增加感知等待时间,极易产生时间流逝十分缓慢的错觉。
5 结论
本文从大学生视角出发,通过调查他们的候车行为和感知状态,采用判别分析方法,建立了大学生感知等待时间判别模型,主要取得的研究结论如下:
(1) 在判别函数中,时间容忍度的标准化判别系数是最大的,说明大学生能够接受的网约车到达时间的范围对总体判别函数的影响较大。此外,根据判别函数及3个分类函数中各个变量的系数均不为0,可见35项显变量对感知等待时间均有影响,进一步说明个人特征、环境因素、候车行为、移动设备这4个因素均会对感知等待时间产生影响。
(2) 从感知等待时间判别模型的分类结果可以看出,模型在原始数据集和交叉验证数据集上分类正确率都大于50%以上,尤其在原始数据集上分类正确率更是高达62.8%,且两者的准确率相差仅为8.1%,说明模型具有一定的判别能力和较好的稳健性,能够在一定程度上对大学生网约车感知等待时间的“短时间”“中等时间”以及“长时间”进行不同程度的判别。
(3) 为了减少感知等待时间,网约车平台应提高车辆到达实时位置、用户预计上车时间和实时道路畅通情况等信息推送的准确性,同时也应为乘客提供更合理的出行规划路线;乘客应在光照舒适、天气宜人以及周围有人的环境下候车,并且在候车时可以通过查看车辆实时位置、欣赏周围风景、上网或者静待车辆到达等行为来减少感知等待时间。此外,候车时应尽量选择温度与空气质量宜人、少量或没有噪音以及能使自己心情愉悦的环境,候车过程中尽量避免跟别人聊天、听音乐、观望路上车辆是否到达以及吃东西这4种行为,因为这些行为都会增加感知等待时间。
本研究只针对个人特征、环境因素、候车行为以及移动设备这4种影响因素进行实证分析,未来将进一步调查和研究大学生对网约车平台的使用意愿、乘客实际候车时间等因素对乘客感知等待时间的影响。
