安全屏障机制下基于SAC算法的机器人导航系统
2023-06-14马丽新刘磊刘晨
马丽新 刘磊 刘晨

摘要为了提高移动机器人自主导航系统的智能化水平和安全性,设计了安全屏障机制下基于SAC(Soft Actor-Critic)算法的自主导航系统,并构建了依赖于机器人与最近障碍物距离、目标点距离以及偏航角的回报函数.在Gazebo仿真平台中,搭建载有激光雷达的移动机器人以及周围环境.实验结果表明,安全屏障机制在一定程度上降低了机器人撞击障碍物的概率,提高了导航的成功率,并使得基于SAC算法的移动机器人自主导航系统具有更高的泛化能力.在更改起终点甚至将静态环境改为动态时,系统仍具有自主导航的能力.
关键词移动机器人;SAC算法;安全屏障机制;激光雷达;自主导航;Gazebo
中图分类号
TP242.6
文献标志码
A
收稿日期
2022-06-01
资助项目
国家自然科学基金(61773152).
作者简介马丽新,女,硕士生,研究方向为强化学习、自主体控制.1623406486@qq.com
刘磊(通信作者),男,博士,教授,研究方向为强化学习理论研究与应用、多智能体系统分析与控制.liulei_hust@163.com
1河海大学理学院,南京,210098
0 引言
近几年,具有自主导航功能的无人车已应用到日常生活中,如无人公交、无人网约巴士、无人配送车等.路径规划能力是衡量无人驾驶车辆是否可以自主导航的重要标准.传统的路径规划方法通常需要人为提取特征来获知环境信息,以完成对环境地图的绘制、移动机器人的定位以及路径规划,但在复杂环境下很难实现.而强化学习[1]不依赖于环境模型以及先验知识,还可自主在线学习,近年来逐渐成为移动机器人自主导航的研究热点[2].
随着计算机硬件水平的提升,深度学习的任意逼近能力得以更大化地发挥,许多深度学习与强化学习相结合的算法被提出,如深度Q网络[3] (Deep Q-Network,DQN)、深度确定性策略梯度[4](Deep Deterministic Policy Gradient,DDPG)等.2018年,Haarnoja等[5-6]针对无模型深度学习算法训练不稳定、收敛性差、调参困难等问题,提出一种基于最大熵强化学习框架的软更新行动者-评论家算法(Soft Actor-Critic,SAC).最大熵的设计使得算法在动作的选择上尽可能地随机,既避免收敛到局部最优,也提高了训练的稳定性.另外,通过在MuJoCo模拟器上一系列最具挑战性的连续控制任务中与DDPG、每步梯度更新都需要一定数量新样本的近似策略优化[7]等算法做对比实验,凸显了SAC算法性能的高稳定性和先进性.
在路径规划领域,基于SAC算法的机器人自主导航相关研究已引起学者的广泛关注.Xiang等[8]将LSTM网络融入到SAC算法中用于移动机器人导航,以360°的10维激光雷达信息和目标信息为输入,输出连续空间的线速度和角速度,验证了改进后的算法在训练过程中平均回合回报(累计回报/累计回合数)的增长速度较快.de Jesus等[9]同样基于稀疏的10维激光雷达数据,不过激光范围是正前方180°,以雷达信息、目标方位、动作为网络输入,并创建了两个不同的Gazebo环境,在每个环境中都对SAC、DDPG两种深度强化学习技术在移动机器人导航中的应用效果做了比较,从导航成功率等方面验证了SAC算法的性能优于DDPG算法.
移动机器人的安全性在自主导航过程中是不可忽视的.近些年有学者通过在训练环节增加安全机制,来降低危险动作被选择的概率,进而促进机器人特定任务的完成.代珊珊等[10]针对无人车探索的安全问题,提出一种基于动作约束的软行动者-评论家算法(Constrained Soft Actor-Critic,CSAC),将其用于载有摄像头的无人车车道保持任务上.动作约束具体表现为当无人车转动角度过大时,回报会相对较小;当无人车执行某动作后偏离轨道或发生碰撞时,该动作将被标记为约束动作并在之后的训练中合理约束.
基于以上启发,考虑到SAC算法在移动机器人路径规划领域的应用尚未被充分研究,本文以提高机器人自主导航系统的智能化水平和安全性为出发点,设计出一种安全屏障机制下基于SAC算法的机器人导航系统.首先对SAC算法以及仿真平台Gazebo做了简单描述.然后搭建导航系统,包括机器人状态、动作、回报函数的定义以及安全屏障机制的设计.最后在Gazebo中训练模型,通过静态环境和动态环境等5组共300回合的对比测试验证了安全屏障机制在提高导航成功率上的有效性.
4 模型效果測试
4.1 静态环境
为了多方位探测模型的效果,共进行4组不同的测试,且在每组测试中都将SAC+安全屏障机制模型(SAC+)效果和无安全屏障机制的SAC模型效果做对比.其中,测试1的环境、起点和终点与训练时的设置相同,测试2相对训练仅更改了终点,测试3相对训练更改了起点和终点,测试4的设置与模型训练时完全不同,不仅将环境变得相对复杂,还改变了起点和终点(图11).详细测试条件配置及两种模型的成功率对比结果如表4所示.
由表4看出,在测试3中,两种模型的成功率均为100%,在测试1、2中,SAC+安全屏障机制模型的成功率略高于后者,而在更改了环境的测试4中,SAC+安全屏障机制模型的成功率远高于SAC模型.
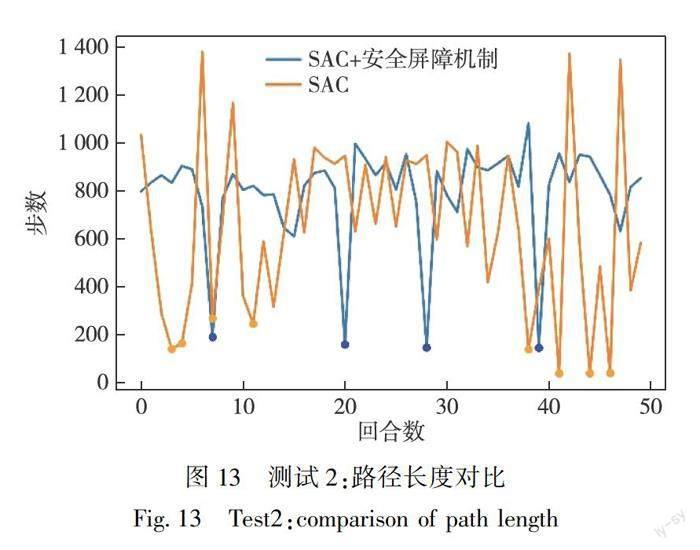
在4组测试中,两种模型的导航轨迹长度(即动作步数)对比如图12—15所示(点状表示该模型在当前回合导航失败).在测试1图12中,SAC+安全屏障机制模型的导航轨迹长度普遍低于SAC模型,而且100个回合无一失败,验证了SAC+安全屏障机制模型的高效性和稳定性.在测试2图13中,两种模型均有导航失败的情况,但SAC+安全屏障机制模型失败次数较少,且在轨迹长度与SAC模型相差不大的情况下波动相对较小,更加体现出前者的稳定性.在测试3图14中,虽然SAC+安全屏障机制模型和SAC模型均无导航失败的回合,但是在大多数回合中前者导航的轨迹长度短于后者.在测试4图15中,两种模型的效果差距很大,在SAC+安全屏障机制模型50次均导航成功时,SAC模型仅成功导航3次,一定程度上凸显了前者在新环境的高适用度.
4.2 动态环境
根据表4中的模型测试结果,可以看出安全屏障机制下基于SAC算法的移动机器人自主导航系统在不同的静态环境中导航成功率均较高.为了更全面地探究训练模型对不同环境的泛化性以及鲁棒性,创建含有静态和动态障碍物的环境(图16),再次测试模型的导航效果.
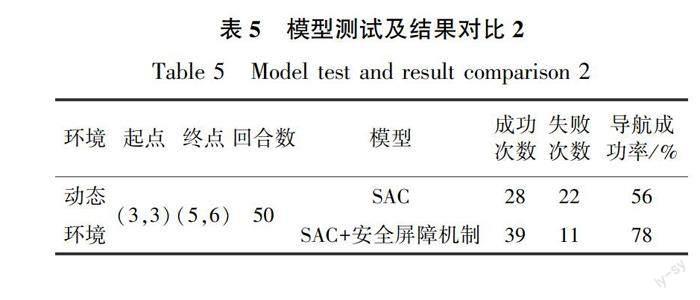
在动态环境图16中,物体A为动态障碍物,在点(3.5,5.5)与点(4.3,4.7)之间以约0.062 m/s 的速度做匀速直线往返运动(图16中黄色虚线).模型测试条件配置及导航成功率如表5所示.由表5可知,本文设计的系统在动态环境中的导航成功率表现虽然不及静态环境,但仍优于无安全屏障机制的导航系统,表明安全屏障机制在提高导航成功率方面具有积极作用.
图17为模型导航路径长度对比(点状表示该模型在当前回合导航失败).其中SAC+安全屏障机制模型在第1、12回合导航的步数多于其他回合,是因为移动机器人为了躲避动态障碍物,选择了先绕过障碍物B再向终点前进的路径,体现了该导航系统的灵活性.
5 结论
本文在Gazebo3D仿真平台构建了基于安全屏障机制和SAC算法的移动机器人自主导航系统,通过静态和动态环境中的多组对比实验验证了安全屏障机制在提高机器人导航成功率方面的有效性.仿真使用的激光雷达只可扫描360°的同一平面信息,因此只有当障碍物相对规则(如长方体形、圆柱形等)时才能比较准确地测出距离信息.未来可通过配置多个不同水平面的雷达或使用更高级的雷达来增大导航系统对障碍物形状的包容度,使得仿真环境更加贴近复杂的现实场景.
参考文献
References
[1] Sutton R S,Barto A G.Reinforcement learning:an intro-duction[J].IEEE Transactions on Neural Networks,1998,9(5):1054
[2] 刘志荣,姜树海.基于强化学习的移动机器人路径规划研究综述[J].制造业自动化,2019,41(3):90-92
LIU Zhirong,JIANG Shuhai.Review of mobile robot path planning based on reinforcement learning[J].Manufacturing Automation,2019,41(3):90-92
[3] Mnih V,Kavukcuoglu K,Silver D,et al.Playing atari with deep reinforcement learning[J].arXiv e-print,2013,arXiv:1312.5602
[4] Lillicrap T P,Hunt J J,Pritzel A,et al.Continuous control with deep reinforcement learning[J].arXiv e-print,2015,arXiv:1509.02971
[5] Haarnoja T,Zhou A,Abbeel P,et al.Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[J].arXiv e-print,2018,arXiv:1801.01290
[6] Haarnoja T,Zhou A,Hartikainen K,et al.Soft actor-critic algorithms and applications[J].arXiv e-print,2018,arXiv:1812.05905
[7] Schulman J,Wolski F,Dhariwal P,et al.Proximal policy optimization algorithms[J].arXiv e-print,2017,arXiv:1707.06347
[8] Xiang J Q,Li Q D,Dong X W,et al.Continuous control with deep reinforcement learning for mobile robot navigation[C]//2019 Chinese Automation Congress (CAC).November 22-24,2019,Hangzhou,China.IEEE,2019:1501-1506
[9] de Jesus J C,Kich V A,Kolling A H,et al.Soft actor-critic for navigation of mobile robots[J].Journal of Intelligent & Robotic Systems,2021,102(2):31
[10] 代珊珊,劉全.基于动作约束深度强化学习的安全自动驾驶方法[J].计算机科学,2021,48(9):235-243
DAI Shanshan,LIU Quan.Action constrained deep reinforcement learning based safe automatic driving method[J].Computer Science,2021,48(9):235-243
[11] Polyak B T,Juditsky A B.Acceleration of stochastic approximation by averaging[J].SIAM Journal on Control and Optimization,1992,30(4):838-855
[12] Koenig N,Howard A.Design and use paradigms for Gazebo,an open-source multi-robot simulator[C]//2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).September 28-October 2,2004,Sendai,Japan.IEEE,2004:2149-2154
[13] Quigley M,Gerkey B P,Conley K,et al.ROS:an open-source robot operating system[C]//ICRA Workshop on Open-Source Software,2009
Robot navigation system based on SAC with security barrier mechanism
MA Lixin1 LIU Lei1 LIU Chen1
1College of Science,Hohai University,Nanjing 210098
Abstract An autonomous navigation system was proposed based on Soft Actor-Critic under the security barrier mechanism to improve the intelligence and security of mobile robot autonomous navigation system.The return function was designed based on distance between the robot and the nearest obstacle,the distance from the target point,and the yaw angle.On the Gazebo simulation platform,a mobile robot with lidar and its surrounding environment were built.Experiments showed that the security barrier mechanism reduced the probability of collision with obstacles to a certain extent,improved the success rate of navigation,and made the SAC-based mobile robot autonomous navigation system have high generalization ability.The system still had the ability of autonomous navigation when changing the origin and destination or even changing the environment from static to dynamic.
Key words mobile robot;soft actor-critic (SAC);security barrier mechanism;lidar;autonomous navigation;Gazebo
