我国人为源大气污染物排放清单研究进展
2023-06-13黄浩瑜高艳珊
黄浩瑜, 高艳珊, *, 王 强
(1. 北京林业大学 环境科学与工程学院 水体污染源控制技术北京市重点实验室, 北京 100083; 2. 北京林业大学 环境科学与工程学院 污染水体源控制与生态修复技术北京市 高等学校工程研究中心, 北京 100083)
0 引 言
21世纪以来,随着经济的发展以及城市化进程的加快,珠江三角洲、长江三角洲、京津冀地区等区域大气污染日益严重[1],成为中国城市面临的主要环境问题。恶劣的大气环境还会危害人类身心健康[2-3]。近年来,各地深入推进大气污染治理,大气环境质量得到了明显改善。然而,“十四五”规划进一步提出了到2025年,全国地级及以上城市空气质量优良天数比率要提高到87.5%。由于大气污染的多样性和复杂性,大气污染防控工作面临很大挑战。大气污染物排放清单不仅能够提供大气污染物排放源的基本信息,助力大气污染防治决策的制定,还能为空气质量模式模拟提供基础数据[4-5],但是排放清单的准确性也会极大程度上影响大气污染决策的有效性及模型建模的准确性。因此一份准确的大气污染物排放清单在大气污染防控工作中至关重要。
自1970年美国颁布《空气清洁法案》以来,先后建立了污染源分类编码[6]、污染源排放因子库[7]、空气质量模拟平台[8]等一系列标准化体系。同期,欧洲环境署也颁布了一系列排放清单编制技术手册、排放因子数据库[9],以期管控欧洲各国间的大气污染物传输[10-11]。我国有关大气污染物排放清单的研究开展较晚,从20世纪90年代开始,相关学者从排放清单编制方法学、排放清单校验评估等方面开展了一系列的研究,在我国建立了不同尺度的排放清单编制体系。本文主要从排放清单编制方法学、区域和城市尺度排放清单编制以及排放清单校验评估三个方面系统论述了我国大气污染物排放清单的研究进展,并针对我国排放清单编制存在的问题提出建议与展望。
1 清单方法学研究进展
1.1 排放清单编制方法
大气污染物排放清单编制方法按照数据来源可以分为“自上而下”与“自下而上”法[12]。“自上而下”法是通过有关部门发布的统计数据进行清单编制;“自下而上”法则是根据实地测试、调研等方式获取本地化的排放因子与更加精细的污染源活动水平数据来估算大气污染物排放量。
早期编制的大气污染物排放清单,大都使用“自上而下”法,基于统计年鉴和国外的排放因子编制我国尺度的排放清单。如王文兴等[13]使用欧洲排放因子结合我国燃料消费量、燃料含硫率和化肥施用量等数据,对我国SO2、NOx以及NH3排放量进行了估算。孙庆瑞等[14]使用统计年鉴等资料计算了我国1950—1953年以来的氨排放量,并进行实地采样,测算出我国氨的时空分布特征。采用这种方法编制的大气污染物排放清单虽然能够在一定程度上反映我国大气污染物排放的特点,但由于不同地区的排放因子差异巨大,所以得到的排放清单并不完全符合实际排放情况。
随着对排放清单研究的不断深入,国内排放清单的编制方法由最初基于国家统计年鉴等数据的“自上而下”法转变为更加精准的“自下而上”法。近二十年来,研究者对工业源、移动源等源类进行了大量的调研与测试[15-19],构建了本地化的排放因子数据库,提高了排放清单的准确性。为了规范排放清单的编制方法,生态环境部于2014年先后颁布了包括《大气细颗粒物一次源排放清单编制技术指南(试行)》在内的共8个技术指南[20-27],技术指南中提供了较为详细的源分类方法、排放因子以及末端处理技术的处理效率,并于2015年在北京、上海、广州等14个城市开展大气污染物排放清单编制试点工作。此外,也在排放清单的编制方法上进行了革新,使用逐步线性回归、蒙特卡洛模拟[28]、库茨涅兹曲线[29]等数学方法建立了一系列的模型,降低了编制排放清单的数据要求与工作量。Cheng等[30]以邯郸市为研究区域构建了一种逐步回归模型,用该模型估算唐山市PM10排放量,并与唐山市县级排放清单进行对比与误差分析(图1),结果表明使用回归模型计算的各个区县污染物排放误差均控制在100%之内,取得了较好的效果;并在后续的研究中建立了线性优化模型,进一步提高逐步回归模型的准确性[31];在此基础上,Zhou等[32]讨论了SO2、NOx、CO以及VOCs的回归模型,在邯郸市范围内进行全面的污染源信息调查进行排放清单计算,之后使用统计分析方法筛选出可以代表该污染源的变量,将工业源与非工业源分别进行建模,得到不同污染物的线性回归模型。但这种模型只能应用于能源、产业结构类似的区域范围,所以并未得到广泛应用。
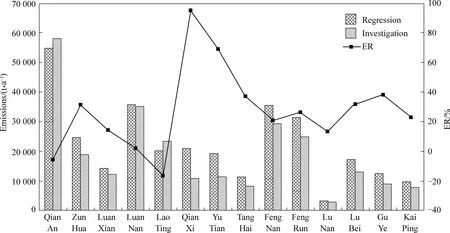
图1 回归模型计算排放量与唐山市县级排放清单对比结果[30]Fig. 1 The comparison between the emission calculated by regression model and the Tangshan county-level emission inventory[30]
目前,我国排放清单编制方法仍旧以“自下而上”法为主,通过实地调查研究得到的排放因子与活动水平数据越来越精确,但仍旧未建立国家层面的排放因子数据库,诸多排放因子需要更新,排放清单编制方法也需要进一步完善。
1.2 时空分配
随着第三代空气质量模型在我国的推广与应用,大气污染物排放清单作为模型重要的输入数据,污染物的时空分布特征也受到了广泛关注[33-34]。污染物的时空分配就是将一定时间(一般为一年)内的污染物排放量根据表征数据进行时间(月、日、小时)和空间(一般为一定分辨率的网格)的分配。使用污染源的地理位置进行污染物排放量空间分配是最准确的方式[35],但对于民用源、农业源等面源来说,获取准确的地理位置信息是十分困难的,所以对于道路移动源、面源等位置信息难以获取的排放源通常使用人口、GDP等栅格数据进行分配[36]。早期由于缺乏准确的工业源地理信息,空间分配一般使用栅格数据进行分配,如郑君瑜等[37]使用珠江三角洲2006年的人口分布栅格数据作为空间分配权重因子,构建了珠江三角洲四种常规污染物网格化排放清单,为后续构建空气质量模拟平台打下基础。但仅使用栅格数据对污染物进行粗略的网格分配不能准确的反映污染物的空间分布情况,需要对研究区域开展实地调研,收集准确的工业源地理信息,将其与栅格数据结合进行更加精准的污染物空间分配研究。Huang等[38]使用经纬度坐标对电厂等固定燃烧源进行空间分配,对于其他工业源则使用GDP栅格数据进行分配,构建中国长江三角洲地区人为源大气污染物网格化排放清单;Zheng等[39]收集了中国近100 000个工业设施的基础信息,并将其与中国多尺度排放清单模型(MEIC)结合,估算了中国2013年30″×30″(~1 km)的网格化排放清单,分配过程中将电厂、工业燃烧、工艺过程均视为点源,结合面源表征数据将污染物排放量分配至1 km×1 km的网格中,图2对比了MEIC与高分辨率MEIC(MEIC-HR)中点源、道路移动源与面源的占比,通过此方法极大程度上提高了MEIC清单的精度,降低了对于人口密集地区模型建模的偏差,改善了空气质量模型的模拟效果。
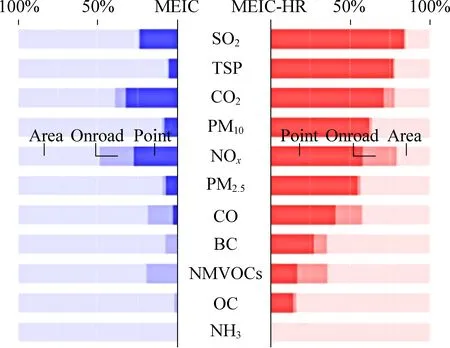
图2 MEIC与MEIC-HR中不同排放源类占比[39]Fig. 2 Proportion of different emission sources in MEIC and MEIC-HR[39]
对于时间分配来说,需要使用与污染源时间排放特征相关性较高的表征数据来计算分配系数,对数据的要求较高,如电厂需要使用每月发电量来进行月份分配,工业源则需要使用每月产值来进行分配等[40],精确到周与小时的时间分配则需要更加精细的表征数据。李莉莉等[41]使用气象因子作为污染物的时间表征数据,根据哈尔滨市13个气象站的观测数据确定了扬尘源污染物排放的时间分配系数;Zhu等[42]使用取暖相关参数构建了能源消耗回归模型,综合考虑社会经济情况,计算出民用取暖部门的时间分配因子;Zheng等[43]对珠江三角洲地区的污染源进行了详细的调查,将部分排放源的污染物排放量分配至月、周以及小时,构建了高分辨率精细化的大气污染物排放清单,对当地污染防控工作提供可靠的数据支撑。
2 我国排放清单研究进展
2.1 区域尺度
区域尺度排放清单的编制有利于明确地区间污染物传输对当地大气环境的影响。随着我国国际影响力的不断增强,逐渐参与到部分国际排放清单的编制工作中。Zhang等[44]基于美国国家航天局的INTEX-B计划编制了2006年亚洲区域的排放清单,使用动态更新的方法,结合国家统计年鉴,重点计算了中国的大气污染物排放量。清华大学在MEIC清单基础上与美国、韩国、日本等多国学者共同建立了亚洲排放清单数据库MIX-Asia,包括九种常规大气污染物与部分温室气体,能够导出多种化学机制,对区域大气污染物模拟等工作具有重要意义。由于国家层面以上的排放清单编制需要收集多国数据,难度较大,因此近几年的研究主要集中于国家、城市尺度排放清单的编制。

在双碳的大背景下,也有部分研究将大气污染物排放清单与碳排放清单进行对比,明确温室气体与大气污染物之间的关系,为我国减污降碳协同增效提供新思路。Zhang等[66]评估了我国钢铁行业使用节能措施所带来的大气污染物、温室气体协同减排的收益,构建了节能供应曲线(ECSC),并将其输入污染物与温室气体的协同减排模型中,研究表明中国钢铁行业到2030年节能减排潜力约为5.7 EJ,节能增效措施可以极大的降低大气污染控制成本。
然而,较大尺度的排放清单编制过程中容易忽略一些较小的污染物排放源,并且各个城市之间的能源与产业结构不尽相同,导致较大尺度的排放清单并不适用于解决单一城市的大气污染问题。
2.2 城市尺度
近几年,我国排放清单研究重点从国家、区域尺度逐渐转变为更加精细的城市尺度,源类划分也更加全面,逐渐涉及到特定源类、单一污染物以及污染物分组分的城市排放清单。Gong等[67]、张雅瑞等[68]分别建立了郑州市、渭南市的道路移动源排放清单,并根据道路类型、车流量等数据对污染物排放量进行时空分配,对于缺少车流量数据的道路使用基于调查的车型比例进行分配[69];邵蕊等[70]使用排放因子法建立了青岛市人为源NH3排放清单,并使用表征数据对污染物排放量进行空间分配,计算得出青岛市北部的NH3排放强度最高;庞可等[71]对工业企业进行实地调研,使用发放调查表的方式获取企业活动水平数据,利用排放因子法建立了天水市人为源VOCs排放清单,明确道路移动源为天水市VOCs的主要排放源,为大气环境治理提供数据支撑;Yuan等[72]对喷漆和印刷过程中挥发性有机化合物排放的成分进行了采样和测量,构建了北京市溶剂使用源VOCs组分清单,发现在生产过程中利用水性涂料代替溶剂型涂料会大大降低OFP的排放。
城市尺度的排放清单可以通过实地调查获取详细的活动水平数据,能够在一定程度上提升排放清单准确性,但目前城市尺度的排放清单研究主要集中在我国东部污染较为严重的城市,对西部及其他城市的研究较少。
除区域尺度和城市尺度外,目前排放清单的研究还涉及机场大气污染物[73]、火电厂大气污染物[64]以及船舶大气污染物[74]等分部门、分行业编制的排放清单。
3 排放清单评估方法
3.1 不确定性分析
不确定性分析是评估排放清单的重要方法,主要包括:定性分析和定量分析。排放清单的不确定性来源包括数据来源误差、计算方法误差、合并误差、清单核算误差以及编制人为错误等,活动水平与排放因子作为计算排放清单的基础数据,其不确定性会极大程度影响排放清单的质量[75]。准确的数据对提升排放清单准确性至关重要,相关研究发现我国不同官方统计数据之间也存在较大差异[76-77],使排放清单不确定性进一步增加。
随着对清单研究的不断深入,带有较强主观性的定性分析方法并不能对清单做出较为合理的评价。部分学者开始将研究重点放在定量不确定性分析上,通过专家判断或统计学方法,对排放因子、活动水平以及其他参数进行量化,再通过数值模拟等方法将其不确定性传递至排放清单中。早期的定量分析大都基于专家判断法,当某一排放源缺乏经验数据时,即可通过专家判断的方式,确定其不确定度。
专家判断仍旧带有一定的主观性,Zheng等[78]提出可以使用自展模拟法对排放因子进行量化,此方法在排放因子数据充足的条件下可以给出其概率分布模型,被广泛应用于排放因子不确定性的量化之中。钟流举等[79]明确提出了不确定性分析的具体流程(图4),并以电厂NOx排放清单作为案例,定量分析了排放量的不确定性,为我国排放清单定量不确定性分析打下基础。此外,Zhao等[80]利用自展模拟和蒙特卡罗模拟法构建了包括详细燃烧技术和燃料品质分类的中国燃煤电厂排放因子数据集。活动水平数据受制于其自身的独特性,一般无法根据自展模拟等统计学方法对其进行量化,一般默认概率分布模型为对数正态分布,并采用专家判断的方式给出其概率分布模型参数[81]。
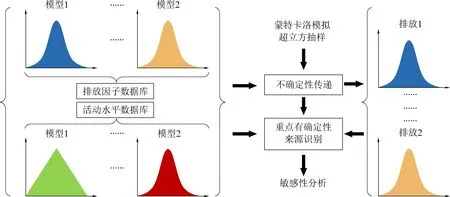
图4 定量不确定性分析流程[79]Fig. 4 Quantitative uncertainty analysis process[79]
不确定性传递的方法包括:误差分析法、拉丁超立方抽样以及蒙特卡洛模拟等。误差分析法基于泰勒展开式,只能以相互独立并且呈正态分布特征的样本进行不确定性的模拟传递,适用范围较窄,在定量不确定性分析中并不常用。拉丁超立方抽样[82]和蒙特卡洛模拟[83]适用于具有任何分布特征的不确定性传递,是排放清单定量不确定性传递最灵活、最准确的方法。Chen等[84]通过排放因子法建立了中国燃煤电厂排放清单,并使用蒙特卡洛模拟分析了排放清单的不确定性,在此基础上进一步分析了不确定性的敏感来源,确定了山东等燃煤大省对排放清单不确定性贡献较大。He等[85]建立了2003—2007年珠江三角洲地区生物质燃烧源排放清单,并使用蒙特卡洛模拟量化了排放清单的不确定性,明确了主要不确定性来源。
目前国外已经建立起了相对完善的排放清单不确定分析体系,国内早期排放清单中几乎没有不确定性分析的相关内容,近几年才开始逐渐重视。魏巍等[86]使用蒙特卡洛模拟评估了中国人为源VOCs排放清单的不确定性,识别出对不确定度影响最大的20个输入信息,分别为生物质燃烧、机动车等部门的活动水平与排放因子。李楠[87]编制了广东省大气污染物排放清单,并建立了分行业的排放因子数据库,对源清单进行定量不确定性分析等研究,发现排放因子是排放清单最重要的不确定性来源,活动水平其次。巫玉杞[88]从数据质量、空间分布等多方面对2017年广东排放清单进行评估,依据前期研究[86, 89]总结出了活动水平数据不确定性判断表格(表1),根据不确定性分析评估结果,可以识别重点不确定性贡献源,从而指导排放清单的进一步优化工作。王君驰等[90]使用实测因子法与比值法两种方法编制了广东省移动源排放清单,并使用蒙特卡洛模拟对两种方法进行定量不确定性分析,结果表明使用实测因子法计算的排放清单不确定度明显低于比值法。

表1 数据不确定性水平评价标准[87-88]Table 1 Evaluation criteria for data uncertainty level[87-88]
由于我国排放清单研究起步较晚,并未建立完善的本地化排放因子库,导致不确定性分析只能通过查阅文献等方式参考国外相关研究进行,无疑增加了工作难度。据有关统计,我国近年来发布的600余篇大气污染物排放清单文献中,60%讨论了清单不确定性,其中仅有40%进行了定量不确定性分析[91]。
3.2 模型校验
模型校验主要包括两种方法,一是使用正交矩阵因子分解模型(PMF)以及化学质量平衡模型(CMB)对观测数据进行解析,由于CMB模型需要使用污染物成分谱,对数据要求偏高,所以目前大都使用PMF模型开展研究。PMF使用的观测数据不受到排放因子、活动水平的影响,主要包括污染物的浓度与污染物的组分浓度,将模型输出的结果与排放清单中源贡献率进行对比,评估清单质量,一般常用于VOCs与PM2.5排放清单校验研究中。如采用“示踪物比值-PMF”联用方法对煤炭资源城市人为源VOCs排放清单进行验证,结果表明清单基本准确,但仍有一部分污染物排放量存在较大差异,需要重点研究以提升清单质量[92]。Li等[93]根据卫星观测数据与PMF模型评估了京津冀地区的人为源VOCs排放清单,结果表明排放清单中大大低估了民用燃煤的排放,需要使用更精确的估算方法。LIU等[94]使用足迹模型、PMF等多种模型分析了北京2016年冬季PM2.5排放源类型与来源,对先前研究中的排放清单进行评估优化,构建了新的高时间分辨率的北京市冬季PM2.5排放清单。
另一种模型校验的方法则是基于第三代空气质量模型对高精度的排放清单进行模拟,将模拟结果与观测值进行对比,以此来验证清单的准确性。目前较为常用的空气质量模型有:嵌套网格空气质量模式预报系统(NAQPMS)、扩展综合空气质量模型(CAMx)以及多尺度空气质量模型(CMAQ),其中CMAQ是最新一代空气质量模型的代表模型[95]。CMAQ模型的适用范围十分广泛,包括但不限于模拟大气污染物浓度、评估源清单、研究大气污染物的产生机理等。夏泽群等[96]使用CMAQ模型模拟验证了不同源成分谱对模式模拟的影响,选取美国SPECIATE数据库中的PM2.5成分谱与国内不同研究者构建的不同区域本地化PM2.5成分谱进行模拟对比,结果表明对模拟效果影响较大的分别为燃煤电厂、水泥制造、道路移动源等源类的本地化成分谱,明确了提升模拟准确度的首要任务就是建立符合实际情况的排放源成分谱。刘扬、祝禄祺[97-98]分别使用WRF-Chem、WRF-CMAQ模式对天水市人为源排放清单进行模拟验证,为当地大气污染物治理提供数据支撑。
由于CMAQ等大气模型由外国学者开发,在某些方面不能直接应用于国内的大气模拟,所以需要对其进行本地化工作。如CMAQ输入排放源文件处理程序稀疏矩阵排放清单处理系统(SMOKE),需要将时空分布要素与源成分谱本地化才能对我国排放清单进行处理,这就导致需要花费大量人力与时间进行模型的本地化工作。
3.3 卫星反演
卫星反演法就是使用高精度的卫星观测数据对污染物排放进行估算,再将得到的污染物排放量与排放清单进行对比从而评估排放清单的准确性。卫星反演得到的污染物排放量不同于普通的“自上而下”或“自下而上”法编制的排放清单,其优势在于具有与卫星观测数据相同的空间分辨率,并与污染物实际的空间分布具有一致性。相比于传统方法编制的排放清单而言,卫星反演得到的污染物排放量更容易进行更新,不需要通过收集活动水平数据、测算排放因子等方式进行估算。但是卫星反演涉及到逆建模过程,通过化学传输模型对排放清单进行处理,计算得到各个污染物的浓度场,将浓度场信息与卫星观测数据进行对比,得到的浓度差异用于指导排放清单的调整和改进。
随着卫星技术的成熟,卫星反演法也被应用于排放清单的校验中。近些年针对SO2、NOx、NH3、PM2.5、PM10等污染物开展了一系列卫星反演研究,并对卫星反演方法进行改进,得到了相对准确的卫星反演产品。如使用卫星观测数据对中国燃煤电厂排放的SO2、NOx信号进行识别,对比两种污染物的浓度变化,并依据浓度变化识别出新建大型排放设施的地理位置[99]。此外,通过OMI卫星数据可以构建用于输入CMAQ模型的排放反演系统,显著提高华北地区夏季和冬季NO2的模拟水平,表明卫星观测数据对反演污染物排放量以及空气质量模拟具有一定的科学性和参考价值[100]。Gu等[101]也提出了一种基于OMI卫星观测数据与CMAQ模式模拟地面NO2浓度的方法,并对其结果的准确性进行了验证,结果显示出较好的相关性。根据2014年的OMI卫星观测数据结合CMAQ模型计算出中国大陆2014年的NO2排放清单。在此基础上,Kourtidis等[102]提出了一种新的SO2卫星反演的增强比值方法,通过使用低风速下的NOx与SO2卫星观测数据和基于卫星估算出的NOx数据来计算SO2排放量,估算了中国地区2007—2011年的SO2排放量,并将构建的ERM DECSOv1模型以及更新过后的ERM DECSOv3a模型与中国MEIC排放清单进行对比分析,发现计算结果与MEIC清单基本一致。
目前,在国家尺度上使用卫星反演的研究较多,由于受到卫星分辨率的限制,不能满足我国当前对小区域范围内排放清单校验、污染防治措施评估等工作的需要;其次由于我国尚未建立完善的排放清单编制体系,导致排放清单编制精度不同,精细化排放清单较少,卫星反演产品难以应用于实际排放清单改进工作中,因此仍需开展进一步的研究工作。
4 展 望
(1)减污降碳协同增效
在碳达峰碳中和背景下,温室气体的排放清单也逐渐受到关注,将大气污染物排放清单与温室气体排放清单相结合,可以精准把控大气污染物与温室气体的共同来源,有利于管理者制定精准、高效的大气环境管控政策。
(2)规范排放清单编制方法
虽然目前国内发布了一些排放清单编制技术手册,但不同手册指南之间推荐的污染源划分与污染物的计算方法都存在或多或少的差异,因此需要建立一个统一规范的排放清单编制体系。
(3)建立本地化排放因子数据库
准确的排放因子能够极大程度上提高排放清单的可靠性,虽然已经有部分研究者对一些重点区域开展了排放因子本地化工作,但在其他没有研究基础的地区编制排放清单就只能使用其他地区的研究成果。所以我国应该系统的建立一份全面的排放因子数据库,降低排放清单编制的难度和不确定性。
(4)编制国家层面排放清单
在规范统一编制方法与排放因子的基础上,根据不同城市的污染状况构建不同分辨率的排放清单,并由国家对排放清单进行统一整合,编制完善准确的国家大气污染物排放清单,降低排放清单的不确定性,保障大气污染联防联控工作的开展。
