融合先验知识的异构多智能体强化学习算法研究
2023-06-12周佳炜孙宇祥薛宇凡周献中
周佳炜,孙宇祥,薛宇凡,项 祺,吴 莹,周献中
(南京大学,江苏 南京 210093)
目前,基于深度强化学习的机器学习方法受到越来越多的关注,更多的游戏通过训练智能体的方式与人类进行人机对抗,典型代表有在围棋领域获得成功的AlphaGo以及在游戏《星际争霸》人机对抗赛中获得成功的AlphaStar等,越来越多的研究将深度强化学习方法融入RTS游戏领域[1-3]。如Ye D尝试利用改进的PPO算法训练王者荣耀游戏中的英雄AI,取得了较好的训练效果[4]。Silver D设计了一种基于强化学习算法的训练框架,不需要游戏规则以外的任何人类知识,可以让AlphaGo自己训练,同样达到了很高的智能性[5]。Barriga N利用深度强化学习技术和监督策略学习改善RTS游戏的AI性能,取得了击败游戏内置AI的成果[6]。大数据和人工智能技术加速运用于战略问题研究,战略博弈推演的智能化特征凸显[7-8]。研究表明,人工智能在智能博弈对抗与推演方面受到广泛关注,并在近年成为研究热点[9-11]。但是,对宽泛条件下的收敛问题以及收敛速度问题,仍然缺乏有效的解决方法,特别是在对抗方面,采用强化学习算法使其具有高水平的智能性仍是当前研究的难点。
本文分析了当前主流且成熟的多智能体强化学习算法,将先验知识与强化学习算法相结合,解决了强化学习算法在多智能体对抗训练初期效果一般且不能快速收敛的问题,提升了多智能体博弈对抗中的算子智能性,同时,在实验平台中进行仿真实验,结果表明,PK-MADDPG在MaCA多智能体博弈平台训练效果与收敛速度方面均有提升。
1 基础理论
1.1 强化学习
强化学习属于机器学习中的一类,是利用求解Bellman方程以解决交互问题[12],进而改善效果并最终达到预期效果的一种学习方式。强化学习使得智能体最终形成一种策略,在达成目的的同时使获得的奖励值最大化[13]。Littman在20世纪90年代提出了以马尔科夫决策过程(Markov Decision Process, MDP)为框架的多智能体强化学习,将强化学习的思想和算法应用到多智能体系统中,通常需考虑智能体间的竞争、合作等关系[14-15]。马尔科夫过程是强化学习的基础模型,通过状态与动作建模,描述智能体与环境的交互过程[16]。一般地,MDP是由4个元素构成的元组〈S,A,R,T〉表示[17]:
1)S为有限状态空间(State Space),包含Agent在环境中所有的状态;
2)A为有限动作空间(Action Space),包含Agent在每个状态下可采取的所有动作;


在MDP中,Agent与环境交互如图1所示。
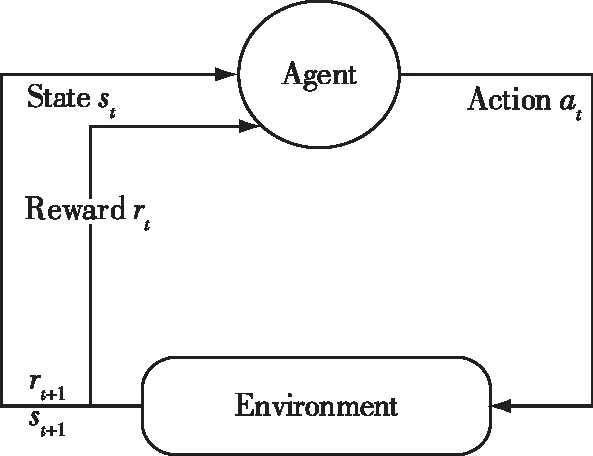
图1 强化学习与环境交互示意图Fig.1 Schematic diagram of interaction between reinforcement learning and environment

(1)
其中,Eπ表示策略下的期望值,γ∈[0,1)为折扣率(Discount Rate),k为后续时间周期,rt+k表示Agent在时间周期(t+k)上获得的即时奖赏。
(2)
(3)
1.2 MADDPG算法
Multi-agent Deep Deterministic Policy Gradient (MADDPG)算法是一种应用在多智能体强化学习中的训练算法,由Open AI研究人员提出[19]。作为DDPG (Deep Deterministic Policy Gradient)的延伸,MADDPG算法基于Actor-Critic架构,可应用于连续动作空间,有如下特征:
1)通过学习得到最优策略,在应用时,仅借助局部信息就能给出最优动作;
2)无需构建环境的动力学模型以及智能体间特殊通信需求;
3)该算法可用于合作关系多智能体,同时适用于竞争关系多智能体。
MADDPG算法采用集中式训练,分布式执行的方式。训练时采用集中式学习训练Critic与Actor,使用时Actor只需知道局部信息即可执行[20]。同时,对每个智能体训练多个策略,并基于所有策略的整体效果进行优化,以提高算法的稳定性和鲁棒性。该算法网络结构与更新方式如图2所示。
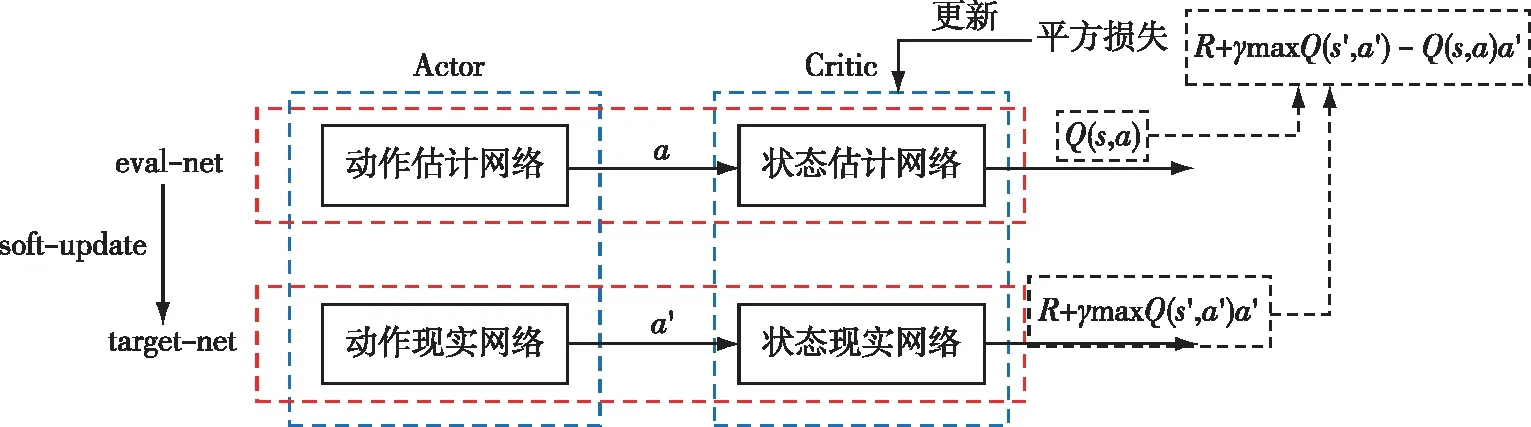
图2 MADDPG算法网络结构与更新方式Fig.2 MADDPG algorithm network structure and update method
MADDPG算法采用了类似DQN的双网络结构,Actor和Critic都拥有target和eval两个网络组成[21],在训练过
程中,只有Actor和Critic的eval网络进行实际的参数训练,而target网络只需要在一定训练迭代次数后,通过eval网络进行参数拷贝即可,这种设计使得MADDPG算法能够保持比较稳定的参数更新效果。
2 PK-MADDPG
2.1 PK-MADDPG算法
为加快训练收敛,提升训练效果,本文对MADDPG进行改进,对其结构进行优化,形成基于先验知识和强化学习的PK-MADDPG(Prior Knowledge-Multi-Agent Deep Deterministic Policy Gradient)。
在PK-MADDPG的奖赏函数设计上,本文考虑算子特征与全局目标问题,从个体回报与全局回报两方面进行奖赏函数设置,根据每个回合的对抗结果设置奖赏函数。若训练过程中每一步未获得奖励,容易导致稀疏奖励,影响算法收敛,本文根据不同个体类型在对抗过程中的动作选择给予奖励,优化训练的收敛。为防止智能体在探索过程中陷入局部最优,在全局回报中加入智能体推演回合消耗,获胜前,每多一个回合都会接收惩罚。具体奖励回报如表1、2所示。
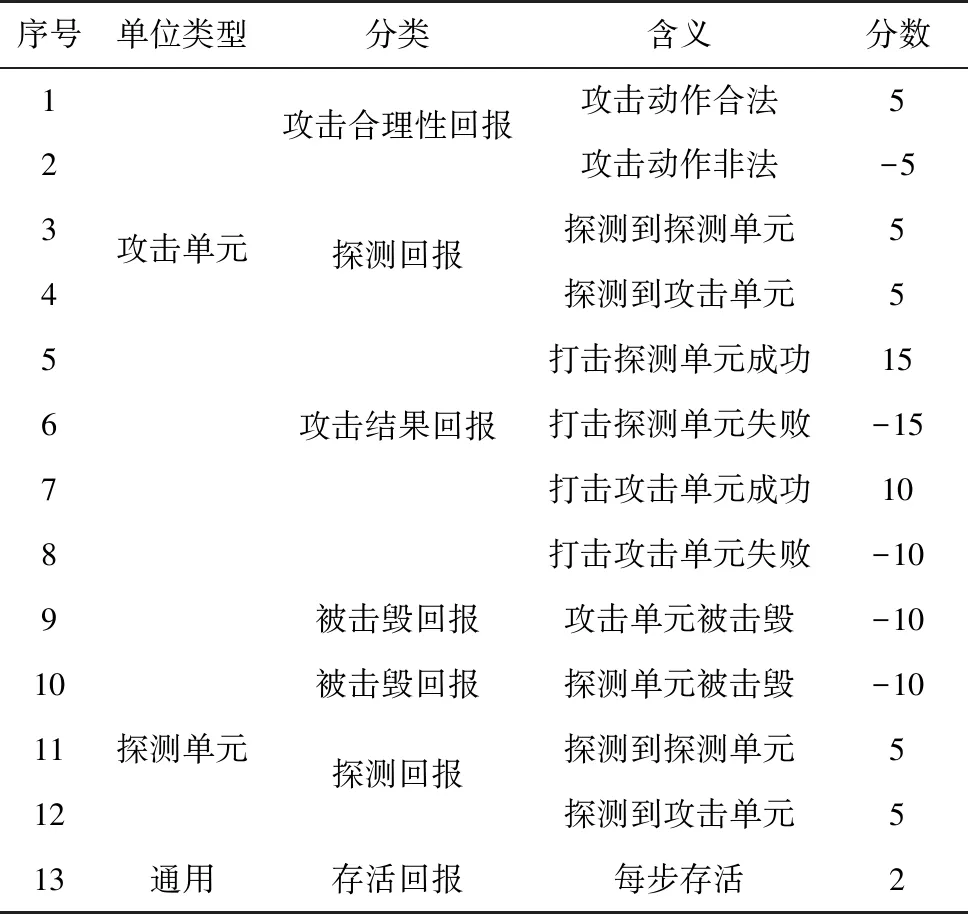
表1 个体回报定义Tab.1 Individual reward definition
针对强化学习训练收敛问题,本文融入先验知识进行经验优先回放。对于先验知识和强化学习的融合,本文对领域专家经验数据和强化学习行动序列数据分别进行构建。把领域专家经验数据转化为对应的状态-行动序列存储到经验池中,并计算得出先验知识QF值。针对领域专家经验数据从历史胜率、敌我双方相对实力、我方兵力三个因素考虑,进行加权求和,并定义了获胜回合数、总回合数、相对实力和兵力构成(侦察机数量、战斗机数量、导弹数量与敌方单位数量),以此来计算领域专家经验数据的Q值。具体计算公式如下:
其中,k(·),g(·),h(·)分别表示历史胜率、敌我双方相对实力与我方兵力构成,roundswin,roundsall表示获胜回合数与比赛总合数。基于MADDPG算法的状态-行动序列也存储到经验池中,同样可以拟合出QP值。在推演过程中,每个固定step对QF和QP值进行比较,选择较大的Q值所对应的动作进行执行。
除此之外,本文也对经验提取机制进行优化。在实现经验回放过程中,将先验知识存入经验池,根据随机优先级和重要性采样原理等进行经验抽样,以此计算优先值。利用随机优先级进行经验抽取可解决数据间的强相关性以及丢弃将来可能有用的经验等问题,同时,通过重要性采样的修正作用抑制由非均匀采样带来的误差。随机优先级与重要性采样系数如下:
(5)
(6)
其中,P(i)表示随机优先采样的概率,pi>0表示优先级,指数α决定使用多少优先级,α=0时对应均匀分布;wi表示重要性采样权重。根据求出的优先值生成最小batch,传入MADDPG算法进行动作选择。通过与环境交互生成训练数据,并将数据存入经验池中进行知识更新。经验池划分到部分内存空间,设定内存空间的大小,把分配的数组数据依次传入并存储。当存储空间大于内存空间时,剔除之前的数据,同时不断提取batch size大小的数据传入学习模块进行策略网络更新,从而降低loss函数。通过上述方式,实现先验知识的融入与经验回放,提高MADDPG算法的训练效果。具体流程如图3所示。

图3 先验知识优先回放过程Fig.3 Prior knowledge priority playback process
针对结构调整,本文构建了双重Critic框架的MADDPG,同时最大化Global Reward和Local Reward,使得策略选择向着使全局和局部Critic最大化的方向进行。在此基础上,使用双延迟深度确定性策略梯度更新Local Critic网络,并使用经验优先回放来优化先验知识提取,以此解决动作价值函数过拟合问题。如图4所示,整个流程中,每个Agent均构建一个Actor和Local Critic,每个Agent的Actor进行动作输出和状态输出,存入Replay Buffer中。Critic网络从各自的Replay Buffer中提取对应的先验知识,反向更新各自的Actor。通过构建整体的Global Replay Buffer提取信息用以训练Global Critic,再反向指导各Actor提高训练效果。PK-MADDPG训练优化使目标沿着全局和局部均最大化的方向,避免可能出现的局部最优问题,同时可以利用TD3等方式进一步优化先验知识提取,解决过拟合等问题。
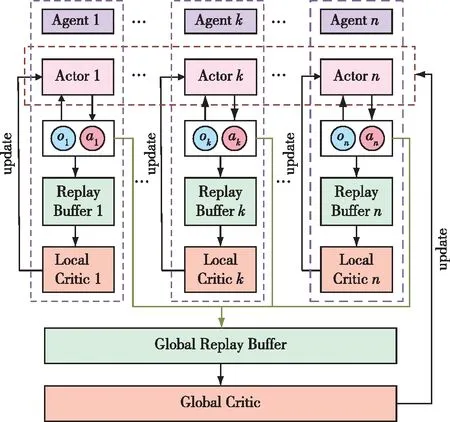
图4 MADDPG模型改进Fig.4 MADDPG model improvement
2.2 PK-MADDPG训练流程
基于Tensorflow和Gym两个框架对改进的PK-MADDPG算法进行训练时,在与环境交互中,可利用MaCA环境获取回报值。训练基于对抗进行,将改进的PK-MADDPG智能体作为红方,规则智能体作为蓝方,具体对抗流程如下:
1)初始化蓝方规则智能体,初始化并获取地图尺度、探测单元和攻击单元数量,实例化状态信息重构对象obs_convert,设定网络输出动作空间维度为6(每个探测单元2个动作,每个攻击单元4个动作),构造动作空间结构action_space_n和状态空间结构obs_shape_n。
2)根据action_space_n(动作空间)、obs_shape_n (状态空间)以及各类单元数量,实例化训练器trainers,并调用U.initialize()初始化网络结构和参数。
3)实例化Tensorflow存储器对象saver,用于保存和读取网络参数。
4)初始化total_reward用于存放各类单元回报值,初始化胜利计数常量,用于记录训练过程中红蓝双方各自胜利次数。
5)对于每一个episode:
②对于每一个step:
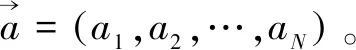

c)判断各个智能体是否存活,是否到达边界以及是否航向角度发生变化,并根据这些因素对相应智能体的回报值进行修改。
d)判断环境是否终止,由于一轮推演结束后才会输出双方round_reward,若终止,则判断双方round_reward高低,并将低的一方各单元reward减去round_reward,高的一方单元reward加上round_reward。
f)对本次step产生的双方的reward进行汇总,便于后续输出reward均值。
g)对每一个Agent调用preupdate()函数和update()函数,根据从经验池中取得的样本对其神经网络进行参数更新。
h)判断是否满足step终止条件,如果满足,那么结束本次训练,并转5)开始新一轮训练,同时更新红蓝双方胜利次数。
i)判断是否满足保存模型条件,如果满足,则进行模型保存操作,同时输出截至当前回合中红蓝双方胜利次数信息、各Agent的信息、reward均值信息以及所用时间。
2.3 决策机制
作战单元决策是基于综合规则和多智能体强化学习算法制定的。在实际对抗中,根据当前状态信息,首先使用基于规则的算法进行决策,如果规则算法决策无效,则切换到强化学习算法进行决策,Agent行为根据每次所选的决策采取适用于当前对抗态势的行动。整体思路如图5所示。
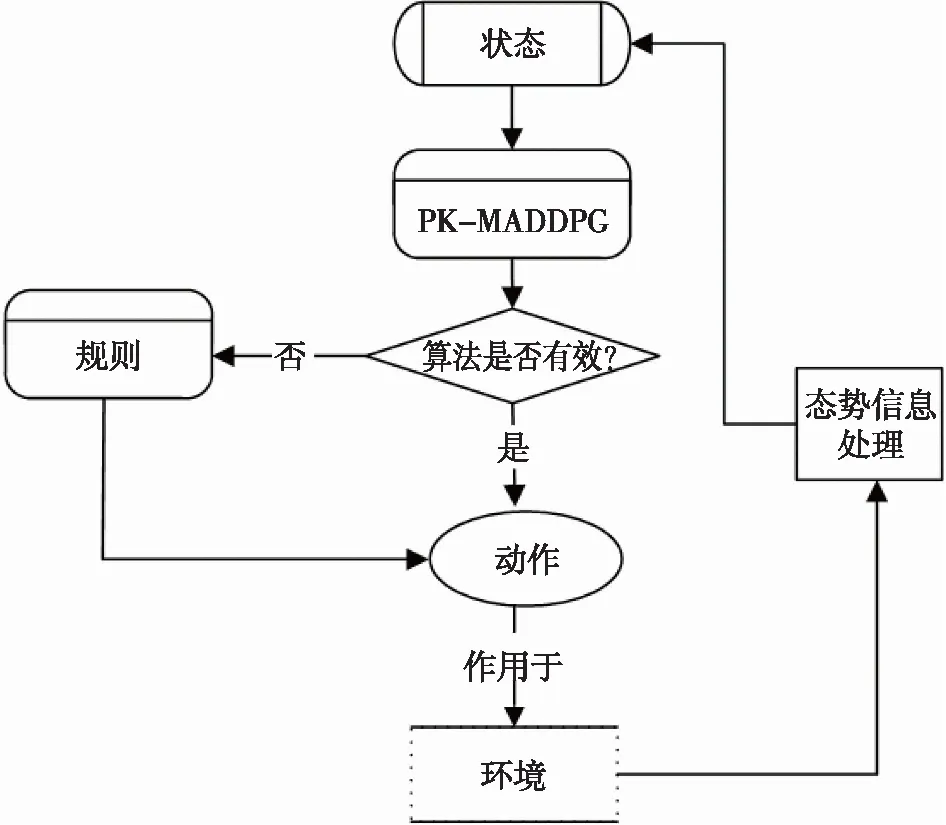
图5 决策生成机制Fig.5 Decision generation mechanism
3 MaCA环境
3.1 环境概述
MaCA(Multi-agent Combat Arena)是由国内某重点实验室发布的多智能体对抗算法研究、训练、测试和评估环境,可支持作战场景和规模自定义,智能体数量和种类自定义,智能体特征和属性自定义,支持智能体行为回报规则和回报值自定义等[23]。MaCA提供了一个电磁空间对抗的多智能体实验环境,环境中预设了两种智能体类型:探测单元和攻击单元。探测单元可模拟L、S波段雷达进行全向探测,支持多频点切换[23];攻击单元具备侦察、探测、干扰、打击等功能,可模拟X波段雷达进行指向性探测,模拟L、S、X频段干扰设备进行阻塞式和瞄准式电子干扰,支持多频点切换,攻击单元还可对对方智能体进行导弹攻击,同时具有无源侦测能力,可模拟多站无源协同定位和辐射源特征识别。
MaCA环境为研究利用人工智能方法解决大规模多智能体分布式对抗问题提供了很好的支撑,专门面向多智能体深度强化学习开放了RL-API接口[23]。环境支持使用Python语言进行算法实现,并可调用Tensorflow、Pytorch等常用深度学习框架。
3.2 MaCA环境与算法交互关系
MaCA环境支持红蓝双方智能算法在设定地图场景中进行对抗博弈,最终进行对抗的算法可以是基于规则直接实现的,也可以是基于强化学习等方法训练后得到的模型,环境中预先制定了简单的基于规则实现的对抗算法。设计MaCA环境的主要目的是促进多智能体强化学习方法在智能对抗领域的研究与应用。强化学习算法与环境交互过程可以分为两个阶段:一是训练阶段,通过收集算法与环境交互的实时数据更新模型参数;二是训练完成之后通过调用训练好的模型与其他对手进行对抗。
4 先验知识说明
本文结合MaCA对抗的任务特点,参照专业选手采取的行动策略,设计规则算法,同时将其作为先验知识的补充和完善。规则算法中针对不同作战动作的策略设计详见攻击策略、干扰频点设置策略及躲避策略。为提高算法训练的适应性,本文重构了从仿真对抗环境获取的原始态势。
4.1 具体先验知识设计
4.1.1 攻击策略
对于处在我方任何攻击单元攻击范围以外的敌方单元,我方将比较战机间的相对距离,由距敌最近的我方空闲攻击单元进行追踪。同时,限制追踪同一敌方的我方攻击单元数量,以保证追踪的有效性和剩余攻击资源的充足性。
对于处在攻击范围内的敌方单元,统筹分配我方空闲的作战单元,具体原则如下:
1)尽可能地攻击在我方攻击范围之内的所有敌方单元;
2)攻击任务分配采用基于优化的贪心算法实现;
3)为节约弹药,对同一敌方单元进行攻击时,限定我方攻击单元的数量;
4)为提高导弹命中率,扩大侦察单元雷达照射范围,指引在途任务的单元完成相关动作任务;
5)为提高命中率,在发动攻击时调整我方攻击航向,保持正面接敌。
4.1.2 干扰频点设置策略
考虑敌方雷达频点具有周期性变化规律,干扰频点策略主要采用在线学习预测方式,包括学习过程与预测过程两部分。
学习过程从进入推演开始贯穿整个推演过程。其具体过程如下:
1)获取某敌机雷达频点的变化,以三个连续时间点内的变化情况作为样本;
2)按时序组合前两个频点作为特征,预测并存储第三个频点的概率分布[22]。
预测过程是从推演的第二轮起,直至整个推演过程结束。在预测过程中,统计每次预测结果与实际结果的相同次数,从而得出预测过程中的算法成功率。预先设定成功率阈值(默认0.95),通过比较成功率来判断预测模块的结果是否有效[22],然后决定后续对抗中是否使用获得的预测结果。具体判断方式如下:
1)若预测成功率高于阈值,则表明学习过程和预测过程的结果与敌方雷达频点的变化具有相同规律,可使用预测的结果;
2)若低于阈值,则表明学习过程和预测过程的结果与敌方雷达频点变化的规律不同,故不可使用预测的结果,且将干扰模式设置为阻塞式干扰。
4.1.3 躲避策略
我方算子侦察获取敌方算子在连续两个step的态势信息,计算出敌方算子可能机动的航向,结合上一个step中我方算子的信息,推算敌方算子追踪我方算子时可能采取的航向等信息。根据推测结果,调度我方相应的侦察单元与无攻击能力的攻击单元做出躲避动作。
4.2 状态信息重构
为了更好地适应训练,本文对仿真对抗环境获取的原始态势进行重构,包括探测单元态势重构与攻击单元态势重构。
4.2.1 探测单元态势重构
本文分别对异构环境中我方所具有的2个探测单元进行状态信息组织,具体如下。
1)我方基本属性:该算子存活状态、X坐标、Y坐标、航向、雷达状态以及雷达频点;
2)友方基本信息:与友方另一探测单元的距离、与友方所有攻击单元的距离;
3)敌方基本信息:与雷达发现的所有敌方单元的距离。
4.2.2 攻击单元态势重构
异构环境中我方10个攻击单元的状态信息组织如下。
1)我方基本属性:算子存活状态、X坐标、Y坐标、航向、雷达状态、雷达频点、干扰雷达状态、干扰雷达频点、远程导弹数量以及中程导弹数量;
2)友方基本信息:与友方所有探测单元的距离、与友方其他存活攻击单元的距离;
3)敌方基本信息:与雷达主动观测到的敌方单元的距离、与干扰雷达被动观测到的敌方单元的距离、敌方单元的方向以及敌方单元的雷达频点。
5 实验仿真设计
5.1 配置及运行说明
MaCA环境适用于Linux 64-bit 、Mac OS及windows10 x64操作系统,通过Pycharm进行Python环境配置,使用Tensorflow强化学习框架。在MaCA根目录中运行相关py文件,将其“Work Directory”均设置为MaCA根目录。
5.2 超参数设计
强化学习的actor与critic神经网络均使用两个隐藏层,每个隐藏层包含64个全连接神经元。训练过程中使用的超参数如表3所示。

表3 超参数设置Tab.3 Hyperparameter setting
5.3 MaCA环境仿真
5.3.1 异构多智能体环境设置
本文基于MaCA环境开展实验仿真,分析融合规则算法的深度强化学习MADDPG算法在多智能体博弈对抗中的实际使用效果。MaCA支持红蓝双方多智能体在设定的地图场景中进行博弈对抗,在异构地图中对战双方各拥有12个不同属性的攻击单元和探测单元,探测单元具备侦察和探测功能,攻击单元具备侦察、探测、干扰和打击等功能,具体信息如表4所示。红蓝双方作战单元接敌开始对抗,当一轮对战符合结束规则时,本轮结束并进行胜负判定。若一方被全部击毁,判定另一方完胜;若双方导弹存量为0或达到最大step,判定剩余作战单元数量多的一方获胜;若双方作战单元全部被击毁,判定为平局。当双方导弹存量为0或达到最大step时,双方存活作战单元数量相同的情况下,也判定为平局。MaCA异构多智能体环境中红蓝双方作战单元与侦察单元初始配置情况如图6所示。

表4 MaCA异构多智能体单元属性Tab.4 Properties of MaCA heterogeneous multi-agent unit

图6 MaCA异构多智能体地图Fig.6 MaCA heterogeneous multi-agent map
5.3.2 实验结果与分析
本文利用基于先验知识和强化学习的PK-MADDPG算法与MADDPG算法、基准规则算法进行胜率比较分析。首先,对基准规则算法进行实验,将红蓝双方智能体均基于规则算法进行博弈对抗;将MADDPG算法用于红方,基准规则算法用于蓝方算法,获取强化学习算法在异构多智能体环境中的效果;然后,将PK-MADDPG作用于红方智能体,将基准规则算法作用于蓝方智能体,验证本文算法在实验中的实际效果。比较3类实验在博弈对抗500局中的胜率,实验胜率结果如图7~10所示,红蓝双方对抗获胜次数如表5~8所示。从实验结果中发现,MADDPG算法较传统规则算法能提高博弈对抗胜率,但在实验初期收敛较慢;而PK-MADDPG算法的Agent胜率提高效果明显,在利用先验知识的情况下能够使训练收敛较快,红方使用PK-MADDPG算法对抗蓝方规则算法时,胜率维持在90%以上。同时,在实验中,将PK-MADDPG与MADDPG算法进行对比可知:1)在同样对抗基准规则AI下,曲线在100回合左右时,PK-MADDPG算法胜率经平稳增长逐步达到收敛,MADDPG算法仍存在较明显波动,收敛速度和效果均有欠缺;2)在PK-MADDPG与MADDPG直接对抗时,PK-MADDPG的胜率优于MADDPG。这表明本文设计的融合规则算法的MADDPG算法能有效提高多智能体对抗博弈的智能性。

表5 base rule与base rule获胜次数比较Tab.5 The compare of winning times between base rule and base rule
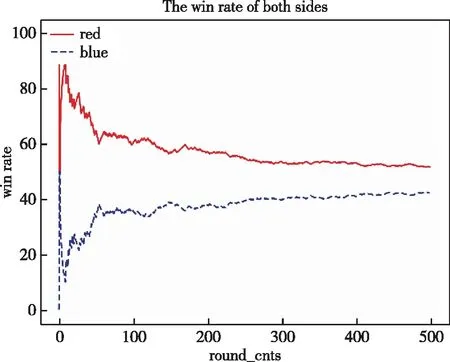
图7 base rule (red)与base rule (blue)对抗胜率图Fig.7 The winning rate of base rule (red) and base rule (blue)

表6 MADDPG与base rule获胜次数比较Tab.6 The compare of winning times between MADDPG and base rule
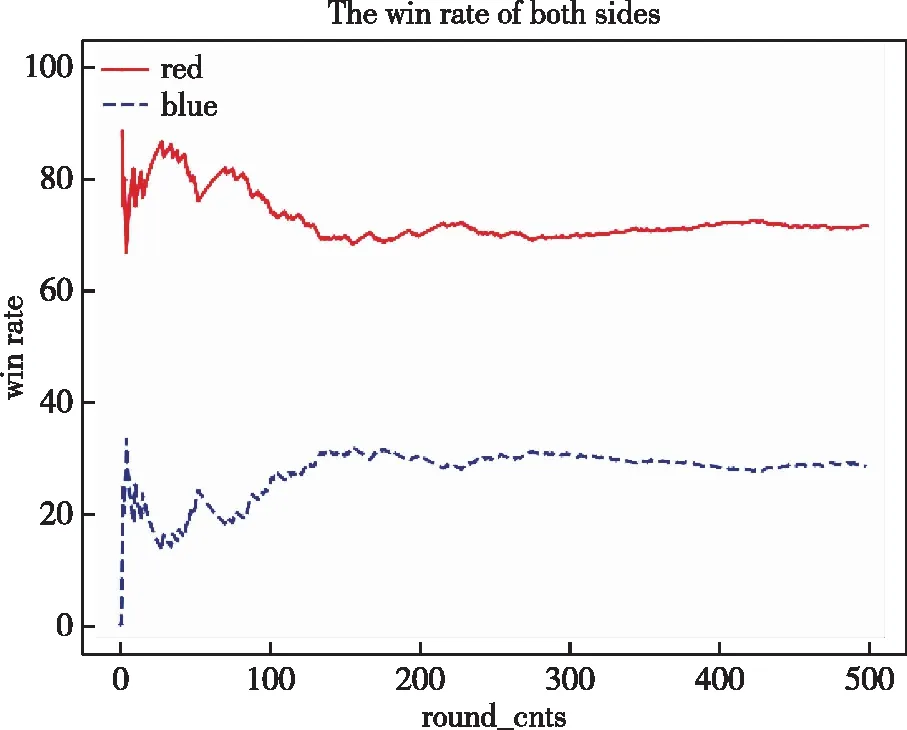
图8 MADDPG(red)与base rule(blue)对抗胜率图Fig.8 The winning rate of MADDPG (red) and base rule (blue)

表7 PK-MADDPG与base rule获胜次数比较Tab.7 The compare of winning times between PK-MADDPG and base rule

图9 PK-MADDPG (red)与base rule (blue) 对抗胜率图Fig.9 The winning rate of PK-MADDPG (red) and base rule (blue)

表8 PK-MADDPG与MADDPG获胜次数比较Tab.8 The compare of winning times between PK-MADDPG and MADDPG
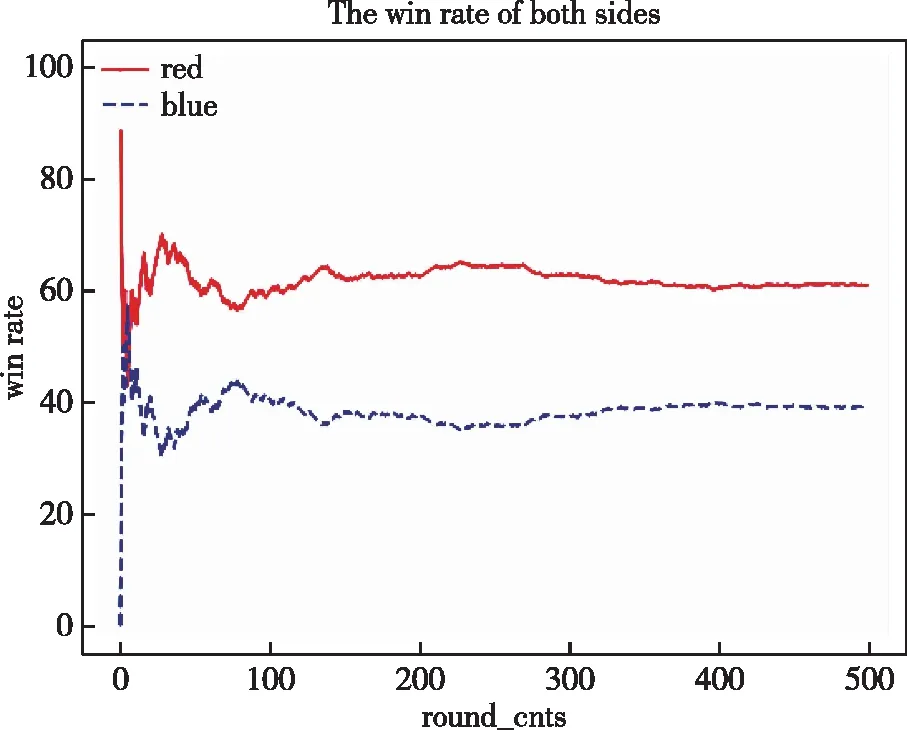
图10 PK-MADDPG(red)与base rule(blue)对抗胜率图Fig.10 The winning rate of PK-MADDPG (red) and base rule (blue)
6 结束语
本文针对强化学习算法在多智能体对抗博弈中训练收敛过慢,以及智能体对抗特定规则下智能体胜率较低的问题,提出了一种先验知识与强化学习结合的多智能体博弈对抗算法PK-MADDPG,并在MaCA异构多智能体环境中对该算法进行实验,验证了算法的智能性。其中,引入规则算法解决了强化学习算法在多智能体对抗初期收敛速度较慢且博弈效果较差的问题,同时保留了强化学习自我探索能力,使得智能体在现有规则策略的基础上进一步优化对抗过程,提高了整体奖励值。在该领域中,我们尝试和探索了多智能体博弈对抗,在传统规则算法的基础上,利用先验知识融合强化学习算法,降低了异构多智能体复杂度高状态多变情况下规则算法设计的难度,进一步提高了推演对抗过程的智能性。
强化学习算法MADDPG在星际争霸、Atari等多个游戏平台上实现应用,充分体现了MADDPG算法较强的可适用性,具有一定的泛化性。本文基于先验知识和强化学习算法提出的PK-MADDPG在MaCA平台得到实验验证,较传统强化学习算法和一般规则算法具有优越性。
