基于改进编辑距离的军事领域实体链接
2023-06-12夏旭东于荣欢
夏旭东,于荣欢
(航天工程大学复杂电子系统仿真重点实验室,北京 101416)
实体链接是知识图谱构建与应用过程中的关键步骤,是指将文本中抽取出的非标准命名实体规范化,并链接到知识图谱上的过程[1],也可理解为将候选集合中的最佳目标实体赋予实体指称明确的含义[2]。实体链接是词义消歧任务中的一种类型[3],需要通过建立知识库中的实体条目与输入文本中带歧义的实体之间一一对应的关系来进行歧义消除。
文本中存在的实体叫作实体指称(Mention),一般包括三种类型[4]:名称性指称、名词性指称和代词性指称。例如,在句子“[外交部发言人][华春莹]称,[我国]火星探测任务受到广泛关注”中,[外交部发言人]是名词性指称,[华春莹]是名称性指称,[我国]则是代词性指称,自然语言文本中存在歧义且查询操作频繁的指称主要是名称性指称,因此,本文将重点关注名称性指称的实体链接。
当前实体链接方法主要分为单实体链接和关联实体链接[5]。单实体通常出现在包含少量实体的简洁文本中,实体上下文信息较少,一般来说,不规范形式有迹可循[6];而关联性实体通常出现在长文本中,大量实体的含义需通过上下文语义进行确定,一词多义或多词一义等现象比较普遍[7],对不规范形式很难用简单规律进行总结。与医药、影视、电商等其他领域[8]不同的是,为准确发号施令,顺畅通信联络,进而确保“万无一失”,军事指挥员在作战、训练及其他行动和工作中,依据《中国人民解放军军语》,统一使用规范化军事用语,因此,其需求语句通常具有命令简明,无歧义,缩略形式有迹可循等特点。面向指挥员命令语句的实体链接属于典型的单实体链接形式。
因此,本文面向指挥员需求命令提出一种基于改进编辑距离模型的单实体链接方法。该方法在为标准实体建立索引的基础上,通过融合改进编辑距离的BM25模型完成候选实体排序,最后将排序位次最高的实体返回为链接目标实体,实现了将指挥员自然语言问句中的实体映射到知识图谱中标准实体的过程。
1 军事领域指称分析
为将指挥员提出的实体指称准确映射到知识图谱中的标准实体上,本文提出的实体链接方法是根据指挥员实体指称中的常见非标准形式,为知识图谱中存储的实体标准名称与指挥员需求语句的实体指称建立相同格式的索引,通过相似度计算并排序的方式返回排名最高的实体名作为实体指称对应的标准化实体名。完整的工作流程如图1所示。
经过对常见非标准形式实体的总结可知,指挥员需求语句中实体指称常见的非标准类型有以下几类。
1)指称是标准实体的别称,二者文本间无缩写关系。如“RQ-1”是美军无人侦察机“捕食者”的别称;“RSD-10弹道导弹”又称为“先锋”、“军刀”等。
2)指称是由标准实体的各部分缩写合并而来,包括名称缩写、拼音缩写、英文缩写等,如“STS”是英文“Space Transportation System”的缩写,其含义是“航天运输系统”;“TG-1”是拼音“TianGong-1”的缩写,意为“天宫一号”。
3)虽然实体名称不存在缩写与别称,但是字符间存在位置交换现象。
4)字符块省略。这是一种特殊的缩写形式,即用字母与数字组成的装备型号直接代替完整的装备名称,属于部分字符块直接省略的情况。
表1是对上述实体指称的非标准类型进行的归纳,也是后续为标准实体建立索引的依据。
2 实体索引建立
本文对T1~T4的四种非标准类型构建索引,并通过相似度计算的方式对其排序。而T5~T6两种非标准类型则直接在编辑距离计算时考虑。
首先,为知识图谱中的每一项标准实体以及指挥员需求语句中的实体指称分别建立索引,目的是根据数据分析结果,按照常见非标准形式对实体进行扩展,以提升待链接实体可能存在的不规范形式的覆盖率,进而提高后续相关度排序的准确率。
依据上一节对常见非标准形式的分析结果,索引应当包含四项内容:字、词、英文和拼音,各项索引的名称及内容如表2所示。

表2 索引格式Tab.2 Index format
其中,别称来自于《中国人民解放军军语》《航天科学技术叙词表》等相关资料文献,择取其中“别名”“又称”“又叫”等内容,如无别称,可补充该词条的外文名。名称缩写是将实体名分词后选取首字进行组合而成,如无法分词或分词后含义不清,则可不填充此项,用“/”符号表示,英文缩写以及拼音缩写按照表中要求进行补充。表3是词条“国防气象卫星计划”的索引示例。
3 基于改进编辑距离的待链接实体排序
为解决实体排序问题,本文采用BM25模型结合改进文本相似度算法进行待链接实体排序。通过对两种特殊情形的补充,提高了当前基于编辑距离的相似度计算能力,使待链接实体排序结果更符合现实情况。最后,将排序首位的标准化实体作为实体指称的最终链接结果进行返回。

表3 索引示例Tab.3 Example indexes
3.1 BM25模型
BM25(Best Match 25)模型[9]是罗伯逊等人提出的一种基于概率检索模型的算法,常用于检索的相关度评分。由于该模型对于评分的排序效果突出,当前仍被广泛用于搜索结果排序[10]。BM25模型的关键思想可归纳为:首先,对query进行特征提取并分解,生成若干特征词qi,而后,对每个搜索结果D,计算特征词qi与D的相关性得分,最后,将相关性得分进行加权求和,从而得到query与D的相关性得分[11]。BM25模型的一般公式为
(1)
式中,Wi表示特征词qi的权重,较为常用的权重计算公式为
(2)
其中,N为索引中的文档数量,dfi为包含特征词qi的文档个数,根据IDF的作用,若包含特征词qi的文档越多,则表示qi重要性越低。需要注意的是,当一个词在超过半数的文档里出现时,为避免IDF值为负,一般将其置为0。
研究发现,词频和相关性之间的关系为非线性变化的,一般来说不会超某个阈值,因此,式中用R(qi,D)表示单词和文档的相关性。
(3)
(4)
其中,tftd为单词的词频,Ld为文档的长度,Lave为文档集合的平均长度。超参数k1代表词语频率饱和度,用于调节特征词文本频率尺度,当k1=0时,模型退化为二元模型,k1越大,则代表特征词qi的词频参与度更高。而b表示字段规约长度,b越大,表示文档长度对相关性得分的影响就越大,b=1代表完全使用文档长度来衡量相关性,b=0即不使用文档长度。
BM25模型的最终公式为
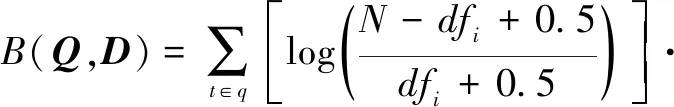
(5)
对于上述两个超参数,通常取k1∈[1.2,2.0],b=0.75。
3.2 达梅劳编辑距离
达梅劳编辑距离(Damerau Levenshtein Distance)是传统编辑距离(Levenshtein Distance)的一种变体,也是用于衡量两个字符串之间相似程度的常用方法[12]。传统编辑距离的基本原理是计算两个字符串
传统的编辑距离对于文本中存在字符交换的情形难以得到正确结果,例如,文本“长征六号改进型”与“改进型长征六号”从字面来看属于相同语义的重复表达,但是通过上述编辑距离计算会得到两个文本不相同的分词串,会得到二者不相似的错误结论,因此,达梅劳编辑距离在传统编辑距离的基础上加入“交换”操作,该操作cost=1,其含义是交换两个相邻字符的位置。
达梅劳编辑距离可定义为DlevQ,D(i,j):
DlevQ,D(i,j)=
(6)
其中case1为“if min(i,j)=0”;case2为“ifQi=Di-1andQi-1=Dj”;case3代表“otherwise”。上式表示,当两个字符串
3.3 文本包含关系
仅通过达梅劳编辑距离计算相似度仍有不足之处,即不能解决含有文本包含的情形:文本“DF31弹道导弹”与“DF41弹道导弹”编辑距离为1,二者仅需通过一次替换操作即可完成转化,但是“DF31弹道导弹”与其简称“DF31”之间的编辑距离却为4,说明仅按照达梅劳编辑距离计算文本“DF31弹道导弹”与“DF41弹道导弹”的相似性高于与其简称“DF31”的相似度,这显然与实际情形不符。
因此,本文对于存在包含关系的文本,通过条件判断函数结合权重赋值,进行文本相似度加强,即
(7)
其中,α是对于文本包含情形的相似度增强权重。
3.4 改进的编辑距离模型
通过以上分析,本文最终使用BM25模型融合达梅劳编辑距离并结合文本包含关系的组合方式,对知识图谱中标准化实体构建的索引,按照文本相似度进行排序,并将排在首位的索引视为最能体现指挥员实体指称含义的标准化实体,从而完成实体链接。改进的编辑距离模型具体公式如下所示:
Score(Wa,Wb)=B(Q,D)+DlevQ,D(i,j)+Dcontain(WQ,WD)
(8)
3.5 实体缺失
由于知识库更新具有一定周期,指挥员输入错误等不可控因素存在,在实体链接过程中不可避免地会出现实体缺失的情况,一般采用设定阈值的方法处理,如在相似度计算得分的基础上设定相似度阈值为0.3,即当匹配得分小于0.3时视为该实体不存在,返回“null”。
4 实验及结果分析
4.1 实验数据
本文的实验数据以空间态势领域知识图谱中的实体名称为基础,通过收录常见实体简称、实体别称,并通过人工删减字符等方式构造了3 870余个实体指称,每个实体指称均链接对应空间态势知识图谱中的某个实体节点,部分实体指称与标准实体的对应关系如表4所示。
4.2 评价指标
实验采用三个通用的评测指标作为评价标准,即准确率(P)、召回率(R)和F1值(F-score),具体的计算公式如下:
(9)
(10)
(11)
其中,TP为正确链接的实体个数,FP表示链接错误的实体个数,FN表示未链接出的实体个数。

表4 构建的实体指称及对应的标准实体名(部分)Tab.4 Constructed entity mention and corresponding standard entity names (partial)
4.3 结果及分析
为验证本文提出的单实体链接方法对于实体指称的链接效果,实验选取的对比方法有四种:完全匹配法、基于传统检索的方法、基于传统编辑距离的方法和基于达梅劳编辑距离。
其中,完全匹配法是直接将待链接实体放入空间态势知识图谱中进行匹配;基于传统检索的方法是对文本分词后建立索引并使用BM25算法进行检索;而基于传统编辑距离法不考虑文本位置与包含相似性,仅衡量字符串之间相似度;基于达梅劳编辑距离是在传统编辑距离的基础上考虑了字符位置交换对相似度计算的影响。最终的实验结果如表5所示。
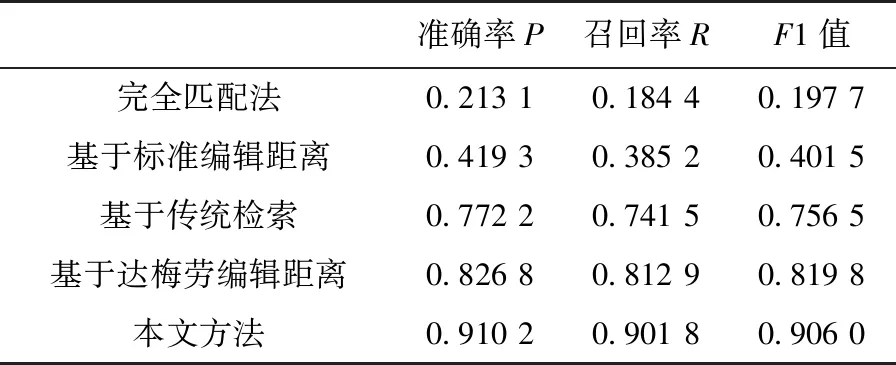
表5 对比实验结果Tab.5 Comparison of experimental results
由表5可见,本文提出的实体链接方法相对于其他方法在军事领域的实体链接领域具有明显优势,其原因是本文通过对指挥员需求语句中实体指称常见的非标准形式进行了更加细致的归纳与总结,以此建立索引,并将字符位置交换和包含相似性纳入实体链接方法,使得链接具有更高的准确度。而其他方法因未充分考虑指挥员实体指称特点、排序算法的不适应性等原因,导致未能对实体指称进行有效的链接。
5 结束语
本文提出了一种基于改进编辑距离的军事领域实体链接方法。通过总结指挥员需求语句中实体指称的非标准类型,对采用传统编辑距离的文本相似度算法进行了改进,通过实验证明了本方法的准确性。但是该算法在时间复杂度上耗费成本较高,且在别称索引部分比较依赖构建的别称词表,在下一步的研究中,将尝试采用深度学习方法,使模型自主学习标准实体别称形成规则,同时也能够提高算法链接效率。
