大规模学术论文元数据管理系统的设计与实现
2023-06-10于林峰谭率卢锋妮黄雪娇秦振华
于林峰 谭率 卢锋妮 黄雪娇 秦振华

关键词: 学术论文;论文元数据;主题查询;合著关系;引用关系
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)12-0074-04
1 引言
信息技术的飞速发展给人们生活带来了巨大便利,同时也对海量信息的有效管理和检索带来了新的挑战。学术论文的查阅和调研是广大科研人员的一项基本工作。然而,大规模的学术论文数据虽然给科研人员提供了丰富的检索资源,但也为论文信息的高效获取提出了新的需求。
目前,一些面向学术论文的搜索引擎(如百度学术、谷歌学术、知网等)的主要作用集中在为用户检索符合输入条件的论文资源,但是它们缺少更深层次的检索服务。例如,通过论文引用关系分析可以评估论文的影响力,易于对相关技术进行溯源[1];通过分析作者合著关系可以了解特定领域内科研团体的构成和特征,促进未来研究团体间的跨界合作[2]。这些信息也是科研工作者针对特定学术领域和技术进行调研分析的重要依据。
针对现有学术搜索引擎的不足,本文聚焦于面向大规模学术论文元数据的查询和分析可视化需求,设计并实现一个大规模学术论文元数据的管理系统,致力于提供科研人员高效、多维度和多角度获取论文信息的功能,提高论文检索的效果和效率。本文所设计的系统功能具体包括:1) 自动获取多源大规模学术论文的元数据;2) 支持海量学术论文元数据的高效管理;3) 提供基于主题语义的论文信息查询功能,解决传统关键字查询导致检索结果不准确和不全面的缺陷;4) 构建论文引用关系图和作者合著关系图,实现基于图结构的检索和可视化展示。
2 大规模学术论文元数据管理系统的设计
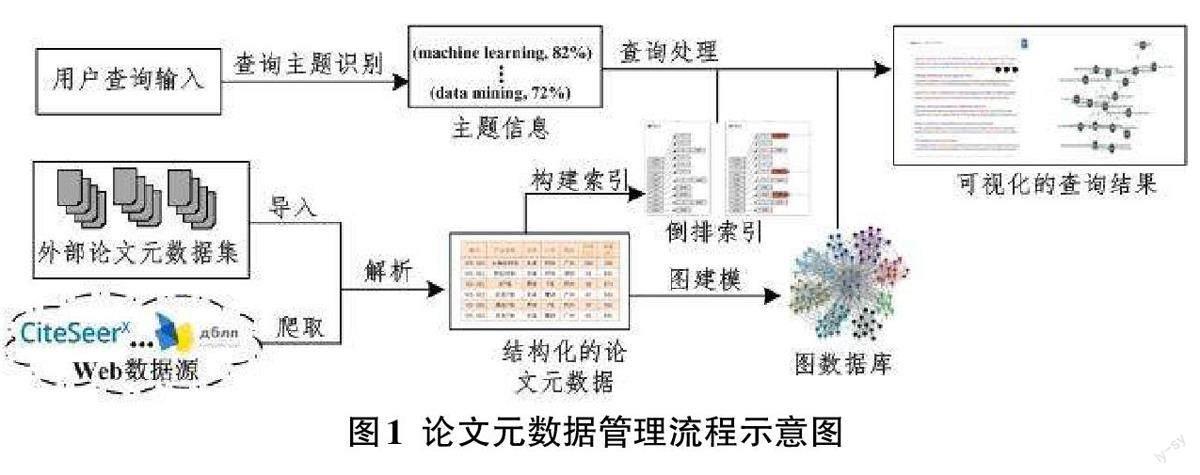
2.1 学术论文元数据的管理流程
学术论文的元数据的来源主要有两个途径:
1) 从在线学术网站上爬取论文的信息;2) 现有已构建好的公开论文数据集。这些论文的信息经过解析后组织成结构化的论文元数据,对论文摘要进行主题识别并构建倒排索引。另一方面,分别利用无向图和有向图对论文元数据中的作者合著关系和论文引用关系建模,并将这两类图存储到图数据库中。当用户根据主题的语义进行查询时,首先识别用户输入字符串的主题信息,并在倒排索引基础上检索出主题相关的论文列表,然后从主题语义的相似度、被引用情况和作者情况等角度综合评估列表中论文的重要性,最后据此进行论文结果的排序和展示。图1描述了论文元数据从数据获取到查询检索整个流程。
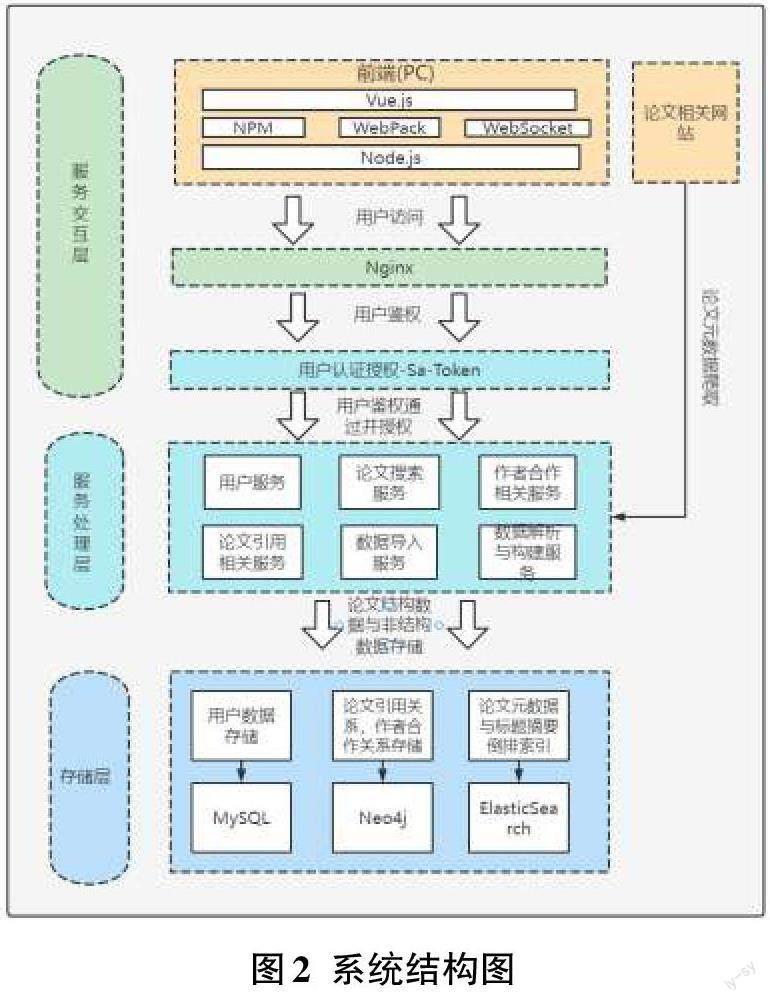
2.2 系统的体系结构系统的结构
按照功能可划分为服务交互层、服务处理层、存储层三个层次,如图2所示。
在服务交互层中,前端采用Node.js 环境,使用Vue前端框架,NPM包管理工具,WebPack打包工具和WebSocket技术,给用户展示关系查询和可视化的界面;使用Nginx Web服务器支持用户访问;采用satoken权限认证框架进行用户鉴权。
服务处理层主要负责处理论文搜索、作者合著关系查询、论文引用关系查询等操作;还可以使用批量数据导入、数据解析与构建服务来维护系统中的论文元数据。此外,从论文相关网站爬取的论文元数据也在本层加工后为系统运行提供数据基础。
存储层负责系统中论文元数据的组织、存储和管理。用户数据存储在MySQL关系型数据库中,论文引用关系、作者合著关系等关系图则采用Neo4j图数据库存储,论文元数据和主题通过倒排索引为论文元数据查询服务提供快速的检索支持。
2.3 系统核心功能的算法设计
1) 超越关键字匹配的主题语义查询
傳统基于关键字匹配的检索方法不能体现查询字符串和查询结果之间的语义关系,降低了论文检索的准确度。本系统针对基于关键字匹配的查询方法的不足,重点关注整合论文内容和领域语义相关的论文查询方法,并在查询结果中同时体现论文相关性和用户偏好,以解决传统查询方法的缺陷。除支持传统输入若干个关键字的模式外,系统还允许用户输入一串较长的字符串(如论文的摘要等),从而能够更准确和更全面地描述用户的查询意图。基于用户输入的查询字符串,算法1描述了系统中基于主题语义的查询算法。
在算法1中,首先对论文列表进行初始化(第1行),并利用文档主题生成模型LDA (Latent DirichletAllocation)[3]来识别输入字符串潜藏的主题信息(第2行)。然后,基于识别出的主题信息,通过预先构建的倒排索引快速检索出系统中包含这些主题的论文列表(第3行)。接着,利用余弦相似度计算论文列表中每篇文章与输入字符串的语义相似度(第5行):
其中str(i)和p(i)分别是输入字符串str和论文p 的第i维分量,α、β 和γ 是三个可调节的权重参数。考虑到论文被引用次数c 和作者发表论文的数量n 也能反映论文的重要性,因此通过三个权重参数(α、β 和γ) 将它们与语义相似度结合起来评估论文p 的重要性程度(第8行)。最后,根据论文的重要性指数对论文列表L中的论文进行排序(第10行)。
2) 作者合著关系的构建与查询
论文合著是科学合作的一种普遍形式,它与论文的影响力存在着紧密的联系[4],同时也是科研人员了解相关研究领域的一个重要途径。为此,系统根据论文元数据中的信息,对大规模的作者合著关系进行提取、整合和建模,并利用图数据库有效地存储这类数据。在本系统中,将作者视为无向图中的结点,合著关系视为结点之间的边,并自动维护作者间的合著关系。这种关系构建的过程如算法2所示。
本系统使用图数据库Neo4j(https://neo4j.com) 对相关的图数据进行管理,并利用声明式图数据库查询语言Cypher进行图数据的检索。首先,在解析获取每篇论文的所有作者信息后(第2行),由于这些作者间存在合著关系,因此从这些作者中任意组合两个创建一条代表合著关系的边(第3行)。接着,对每个新生成的合著关系,查询现有图中是否存在当前合著关系中的作者,如果没有,则增加相应的结点(第5、6行)。最后,如果描述当前合著关系的边不存在于图中,则在两个相应结点间增加一条边(第7 行)。在实际的应用中,可以根据需求考虑是否为图中的边赋予权重,权重高则表示对应两个作者合著的次数更多,从而描述作者间合作关系的紧密程度。
3) 论文引用关系的构建与查询
学术论文之间并不是孤立存在的,一篇学术论文通常建立在多篇论文研究的基础上,这种关联通常通过论文间的引用关系来体现[5]。因此,学术论文间的引用关系是学术研究中的普遍需要。它一方面能够为学术论文提供最佳论据并得以开展学术论证,另一方面方便读者了解相关技术并进行技术溯源。此外,论文间的引用关系隐含着论文重要程度的信息。例如,当一篇论文被大量相同领域的其他论文引用时,这意味着这篇论文是该领域的一篇重要文献。因此,本系统将论文的引用關系视作一项重要的信息并进行维护和查询。
论文之间的引用关系是一种天然的图结构信息,本系统使用有向图对这种关系进行建模:将论文视为图中的结点,如果论文A引用了论文B,则在从A引出一条有向弧指向B。由此可以得到一个描述论文引用关系的有向无环图。该图的构建和查询与作者合著关系图的构建和查询算法类似,鉴于篇幅,此处不再详述。
3 系统实现
图3展示了将“network security”作为关键字查询输入后返回的查询结果。在该页面的左边区域,用户可以设定时间年限来限制相应的内容;在输入框中,用户还可以将论文的摘要作为输入字符串,通过系统对输入字符串进行主题识别能更准确地理解用户的查询意图,返回更准确地检索结果。
对于作者合著关系查询,本文以名为“Webpageunderstanding: beyond page-level search”的论文为例,其作者的合著关系如图4所示。由图中的结果可以看出来,该查询结果明显地描述了不同的学术合作团体。
图5展示了上例论文的引用关系,为了使展示的结果简洁,我们在查询中限定引用关系为两层。该结果可以直观地体现不同论文之间的引用关系,方便用户进行技术的追踪和调研。
4 结论
本文从广大科研工作者对海量学术论文进行快速、准确和全面的检索需求出发,设计并实现了一个面向大规模学术论文元数据的管理系统。该系统根据输入字符串的语义表示,检索出语义相似且重要性高的论文结果,避免了传统学术论文搜索引擎中采用关键字匹配时面临的查询结果不准确和不全面的问题。同时,鉴于科学研究中作者合著关系和论文引用关系的重要性,系统中将这两种关系分别建模成无向图和有向图,并采用图数据库对这类数据进行有效的管理,通过图形化的方式向用户提供直观的关系查询结果。该系统的实现,能够为海量论文元数据的管理和查询提供便利,更好地满足广大科研工作者对论文的高质量检索需求。
