考虑车辆交互信息的高速匝道合流区车辆加减速行为研究
2023-06-07车鑫
车 鑫
(重庆交通大学,重庆 400074)
0 引 言
匝道合流区作为匝道车辆与主路车辆交汇的区域,在匝道车辆进行强制换道操作时容易出现交通流紊乱的现象,Kondyli[1]等人得出的研究表明,匝道影响区从匝道鼻端上游120 m处开始并于鼻端下游260 m处结束,而这种现象的出现会影响交通效率并带来安全性问题。因此该区域一直是学者及相关技术人士研究的重点。张鑫[2]等以效率-交通冲突率作为评价指标,分析了加速车道几何参数对合流区交通环境的影响;李巧茹[3]等提出了基于可变限速和换道控制的合流区协同控制模型;Kusuma[4]等人发现91%的临近匝道车道行驶的驾驶员会在加速车道前方进行减速,且48%的匝道合流车辆会在前25%的交通区段进行换道操作;Beinum[5]等研究了匝道合流区的驾驶行为。以上文献从人、车、路、环境四个角度对合流区交通环境进行了分析与改善。然而当前的文献资料,大多集中在匝道车辆合流行为及区域交通效率提升等方面,讨论主路及匝道车辆间微观交通参数与车辆加减速行为关系的资料相对较少。而在匝道合流区,车辆交互行为(如车辆换道)会比其它路段更多,当保持多车跟驰状态或匝道来车时,驾驶员可能会出现无法正确判断前方车辆运行状态的情况,从而提高车辆运行风险并降低通行效率。而车辆周围环境的变化往往会影响驾驶人的意图,进而影响驾驶员之后的决策行为,所以通过车辆交互信息来预判前车运行状态很有必要。在信息技术不断发展的今天,随着路端设备或车载传感器的部署,我们可以很容易的获取到这些车辆的自身信息与交互信息,使预判前方车辆行驶状态成为可能。因此本文讨论了速度、车辆间距、速度差等微观运行参数与车辆加减速行为的关系,并借助以上参数利用聚类分析的方式预判车辆未来短期的运行状态。
1 各场景下影响车加减速行为的主要因素
1.1 数据集的选取与处理
本次研究选取了清华大学苏州汽车研究院提供的Mirror-Traffic数据集,该数据集记录了某市高速公路汇入路口的车辆轨迹数据,记录时长为30 min。该数据集包含760辆车共计14.3万余条数据。数据的采样帧率为25 Hz,包含车辆编号、位置、速度、加速度等车辆运行信息。数据集所选区域为双向四车道的匝道合流区,匝道连接方式为平行式,限速80 km/h。在下面的研究中,将远离匝道一侧的主路记作主路一,靠近匝道一侧的主路记为主路二,合流区示意图如图1所示。

1—加速车道;2—主路二车道;3—主路一车道;4—x-y坐标轴:车辆点位坐标(x,y)对应的基准坐标轴。图1 平行式匝道合流区示意图
在分析数据前需对其进行简单处理。首先处理匝道车辆数据,匝道车辆轨迹图如图2所示。可以看到,匝道车辆最早在纵向点位y=160 m处左右开始出现平行于主路车道的轨迹,因此匝道合流车辆仅采集纵向点位前160 m处的车辆数据;在提取车辆间距信息时,两车纵向间距最大值设置为70 m,同时由于加速度数据波动较大,所以对其进行了卡尔曼滤波处理。

注:将每辆车在各采样点位的坐标(x,y)按采样时间顺序进行连接,形成匝道车辆行驶轨迹。图2 匝道车辆行驶轨迹图(单位:m)
1.2 各场景间的差异性分析
由于车辆的运行特性受所在车道、匝道是否有来车等因素影响,所以将合流区分为六个场景,分别为匝道来车时,主路一与主路二车辆运行场景、匝道无来车时,主路一与主路二车辆运行场景以及加速车道车辆行驶时,斜前方与斜后方(位于主路二)有车的场景。为叙述方便,将上述场景以此记为场景一到场景六。其中场景一到场景四所选的参数为自车速度、前后两车间的速度差、纵向间距、车头时距,场景五和场景六所选参数为自车速度、速度差、横向及纵向间距。以上所选参数经验证均服从正态分布。
为了验证各个场景间的差异性,这里采用独立样本t检验的方法来判断。由于各样本间的数量级不一致,会影响独立样本t检验得出的结论,故利用smote过采样算法将各个样本扩容。扩容后利用SPSS软件求出的相应结果如表1、表2所示。尽管场景一和场景二、场景三和场景四之间各有一个参数差异性不显著,但场景间其他三个参数均存在明显的差异,因此从整体上看六个场景间存在差异。接下来研究各场景对应的参数与车辆运行状态即车辆加速度之间的关系。

表2 匝道场景差异性分析
1.3 车辆微观交通参数与车辆运行状态间的关系
为研究各参数与车量加速度间的关系,采用皮尔逊相关系数r来判别二者的相关性
(1)
式中:x、y为需要判别相关性的两个样本,Cov(x,y)为x与y的协方差;Var(x)、Var(y)分别为x与y的方差。
各场景参数与加速度的相关系数如表3、表4所示。
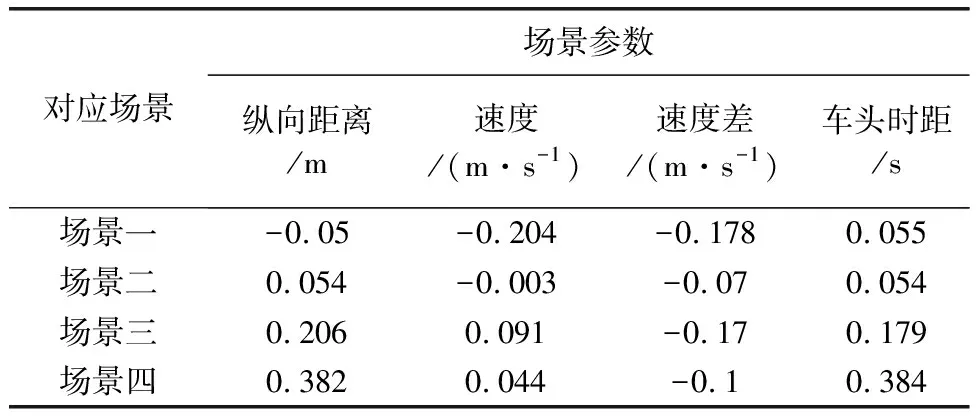
表3 各主路场景参数与加速度的相关系数

表4 各匝道场景参数与加速度的相关系数
分析包含两条主路的场景,可以看到不同场景的参数与加速度的相关程度是存在差异的,这里以场景一和场景四为例,场景一中速度和速度差与加速度相关性高,而场景四中纵向距离与车头时距与加速度相关性高。同时也可以发现不同场景下各参数与加速度的正负相关性、相关的的显著性也存在着部分差异,这也侧面验证了场景之间的差异性。再分析另外两个场景,可以看到,场景五的整体相关性水平、相关的显著性均强于场景六,说明加速车道车辆行驶状态受前方车辆影响更大。
根据相关性分析结果,选取相关性最强的系数所对应的场景作为案例进行聚类分析,因此这里以场景四和场景五作为案例进行分析。
2 车辆运行状态聚类方法研究
在常规聚类方法中k-means算法凭借着其操作简单,收敛速度快而备受广大研究者青睐,如张建波[6]等利用k-means算法分析了驾驶员的急减速特征;苏小会[7]等利用了改进的k-means算法对车辆油耗进行了分析。但由于k-means方法偏向于对球形簇进行聚类,再加上簇之间容易发生交叠现象,聚类结果在有些情况下可能会不尽人意。而高斯混合模型(GMM)作为K-means模型的优化,它可以试图找到多维高斯模型概率分布的混合表示,从而拟合出任意形状的数据分布,而该模型也广泛地运用在聚类方法的研究中,吴坚[8]等基于高斯混合模型对驾驶员的特征进行了辨识;张建波[9]等利用该模型对不同交通条件下的驾驶员进行了特征聚类。由于样本数据服从高斯分布,符合GMM的应用条件,因此这里可以选择GMM聚类的方法对车辆运行状态进行分类。在这里,将车辆的运行状态分为加速态、平稳行驶态、减速态三类,并对K-means和GMM两种聚类算法的效果进行了对比。
2.1 GMM与k-means算法的基本原理
k-means算法是通过在确定k个聚类个数的情况下随机确立k个聚类中心,分别计算第i个样本点到各个聚类中心的距离rij
rij=‖xi-μj‖2(j=1,2,…,kandi=1,2,…,N)
(2)
式中:xi为第i个样本点,μj为第j个聚类中心,k为聚类中心个数,N为聚类样本总个数。
GMM算法则通过多个正态分布的加权和来表示一个随机变量的概率分布,其对应的高斯混合分布可表示为
(0≤ωi≤1)
(3)
式中:m为高斯函数混合个数;ωi为混合系数;μi为第i个高斯混合分布的均值;σi为第i个高斯混合分布的标准差。
而利用GMM聚类过程即先划分k个聚类簇,之后利用包含多元参数的训练集来训练该模型,形成k种不同的多元高斯分布图(簇),最后将需要聚类的样本(测试集)导入训练好的模型,求出该样本在k个不同分布图中的概率,选取概率最大的簇作为结果进行输出。
在样本训练的过程中,首先对混合系数αi,均值向量μi以及协方差矩阵∑i进行初始化,之后利用隐变量确定样本来源于某一类,接下来计算该类中产生该样本的概率,从而求出对应的对数似然函数
(4)
式中:PM(xj)为样本xj的后验概率;m为样本个数;k为聚类簇个数;αi为混合系数;μi与∑i分别为对应的均值向量与协方差矩阵。

2.2 车辆运行状态的聚类分析
聚类分析前需要对聚类参数进行合理的选取,这里以参数与加速度的相关性和聚类参数之间的相关性两个方面进行评判。在场景四中,由于车辆间距与车头时距两个参数间的相关系数高达0.918,因此利用表3得出的结论选取车头时距与速度差作为聚类参数;在场景五中,各参数间相关性并不高,所以根据表4得出的结果选取速度差、纵向间距、速度作为聚类参数。
为了更好地展现聚类效果,需对上述两种场景的样本进行降维处理,即对同一辆车,每十帧数据做一次均值,得到聚类样本数据,之后对该样本数据进行聚类,通过聚类结果与实际运行情况进行对比的方式来评判聚类效果,其中实际运行情况分别通过前述两种聚类方式进行了量化分级。场景四、场景五所对应的车辆运行趋势的k-means算法聚类结果如图3、图4所示,GMM算法聚类结果如图5、图6所示。从聚类结果来看GMM算法均优于K-means算法,但在场景四、场景五所对应的两算法的预判正确率却仅为52.2%,40.74%与45.2%,43.1%。其正确率较低的原因主要归结为以下3点。

图3 场景四车辆运行趋势k-means算法聚类图

图4 场景五车辆运行趋势k-means算法聚类图

图5 场景四车辆运行趋势GMM算法聚类图

图6 场景五车辆运行趋势GMM算法聚类图
(1)在该场景下微观交通参数与加速度之间的相关性依然较低。
(2)该区域交通环境复杂,受驾驶员心理因素(驾驶风格)的影响相对于常规场景更大。比如在场景四中,就出现了在较低的车头时距中依然有车辆加速行驶的情况。
(3)应该考虑车道占有率等相对宏观的交通信息。
综上所述,在该区域进行车辆运行状态预测时应该强化对驾驶员驾驶风格的辨识,在车辆运行状态预判时应该将驾驶风格进行量化,将其作为参数与其他相关交通参数一同作为预判依据,从而减少误判的可能。
3 结 论
着重分析了车辆交互信息与车辆加减速行为的关系,其中靠近匝道侧的主路车辆运行状态与车头时距、车辆间距相关性强。而匝道车辆运行状态受临近车道前车影响更大,与其纵向距离相关性强。根据聚类的分析结果说明仅依靠车辆交互信息及自身速度并不能完全把握车辆运行状态,还需要考虑驾驶员自身特性等因素。本次研究所得出的结论为车辆行驶状态预测参数的提取提供了依据。
