双通道异构图神经网络序列推荐算法
2023-06-07邬锦琛杨兴耀李梓杨黄擅杭孙鑫杰
邬锦琛,杨兴耀,于 炯,李梓杨,黄擅杭,孙鑫杰
新疆大学 软件学院,乌鲁木齐830008
在大数据时代,用户从大量的产品和服务中想获取自己需要的信息是极其困难的。推荐系统可以根据用户的历史数据了解用户的偏好,帮助用户做出合理的决策和选择。随着推荐系统的开发和对用户数据的分析,用户的偏好可以区分为长期偏好和短期偏好[1]。传统的推荐系统只考虑用户的长期偏好,而忽略了用户偏好的转移。例如,在电子商务平台中,用户购买的物品构成了用户的行为序列,传统的推荐系统的目的是通过物品的转移来了解用户的长期偏好。用户购买物品的行为序列如图1所示。
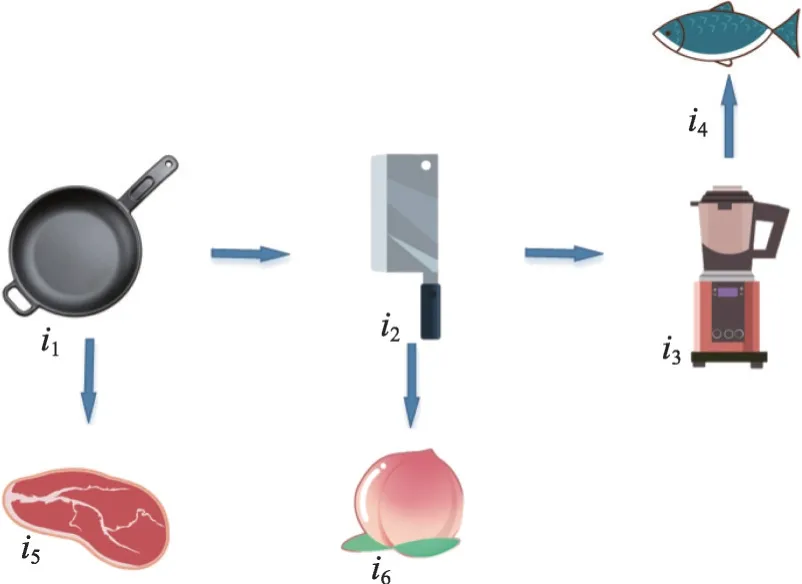
图1 用户购买物品的行为序列Fig. 1 Behavior sequence of user purchases
图1 中描述了六件物品之间的转换关系。传统的推荐系统考虑项目所有用户行为的转换关系,以便推荐系统花费很长时间关注用户注重的物品,但这会减弱推荐系统对用户偏好变化的敏感度。因此,推荐系统无法快速学习用户偏好的转移。如,一个用户买了很长时间的鱼肉,突然喜欢上了牛肉。但是,由于用户购买鱼肉的次数比购买牛肉的次数多,传统的推荐系统认为用户的偏好仍然是鱼肉。因此,传统的推荐系统由于没有考虑用户行为的交易结构而忽略了用户偏好的转移。为了解决这个问题,有必要将用户行为序列分解成更小段的序列,即会话。例如,按照时间做分割,用户一次购买的商品、一天内浏览的网页等。基于会话的推荐模型以会话作为推荐的基本单元,可以减少用户的信息损失,并且已经得到了广泛的研究。将用户行为序列分割为会话的结果如图2所示。
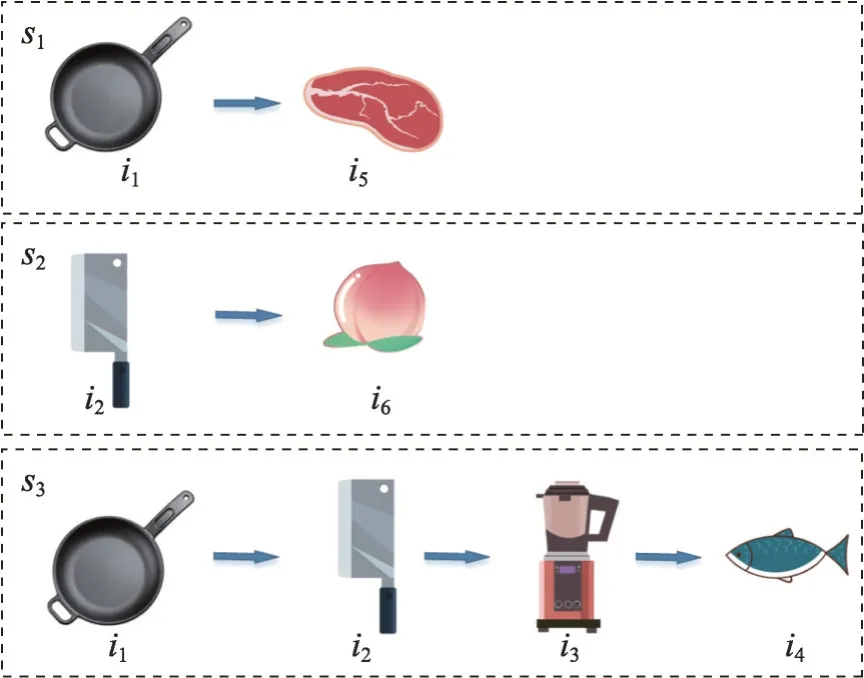
图2 用户行为序列分解Fig. 2 Decomposition of user behavior sequences
图2描述了在电商平台中,将图1中的用户的购买行为划分为了粒度更小的会话序列集合{s1,s2,s3}。基于用户行为序列的推荐系统将用户行为分解为一组会话,从而赋予用户行为事务属性,使推荐系统能够专注于用户偏好的传递。如,用户长期购买苹果,但最近更喜欢西瓜,基于用户行为序列的推荐系统可以及时捕捉用户偏好的转移。它不再像传统的推荐系统那样继续推荐不同品种的葡萄及与葡萄相关的商品,而是推荐与西瓜相关的商品。因此,基于用户行为序列的推荐系统忽略了用户的长期偏好。要使基于用户行为序列的推荐系统既关注用户的短期偏好,又考虑用户的长期偏好,就必须考虑会话之间的相关性。会话序列中的相关关系主要有三方面:同一会话中不同物品项之间的相关关系、不同会话中不同项之间的相关关系以及不同会话中不同物品项之间的相关关系。这就要求基于用户行为序列的推荐系统能够充分考虑会话的上下文,并能够了解项与项之间的复杂转移。
近年来,图神经网络(graph neural networks,GNN)被应用于基于用户行为序列的推荐系统[2]。在基于GNN 的推荐系统中,首先将用户行为序列集构造为一个有向图,有向图中的节点表示项,而项之间的转移关系用边来展现。其次根据构造出来的有向图,图神经网络可以学习项目之间复杂的转移关系,学习表达能力强的项目嵌入,生成包含项目间复杂转移信息的序列嵌入[3]。如,基于会话的图神经网络(session-based recommendation with graph neural network,SR-GNN)[4]不仅可以捕获短期内用户偏好的迁移,还可以考虑远距离物品之间的转移关系。因此,SRGNN 可以学习正确的物品嵌入。同时,SR-GNN 增加了一个注意力网络,关注用户的局部会话嵌入和全局会话嵌入,这使模型可以将用户的短期偏好和长期偏好同时考虑在内。SR-GNN 虽然考虑了用户的长短期偏好以及项与物品间的复杂转换,但它忽略了会话序列中的其他有效信息,如用户信息,这会导致不同用户的特定偏好的丢失。
目前的异构图模型中只关注了序列内部的依赖关系,而忽略了序列之间的相关效应,本文将序列作为异构图的节点,这样可以通过用户意图和用户行为模式计算序列之间的相似度,完成跨序列级的学习。本文考虑到在真实世界的信息中,每个信息节点的类型和每条边的类型都是多种的,并且每一个节点也具有不同且繁多的属性,此时同构图就无法完全表示这些信息。同时,异构图可以包含多种类型的节点,边不仅可以表示不同的关系,也可以表示不同类型节点之间的相关性。因此,本文引入异构图来构造同构图中不能表示的用户等信息,丰富需要表达的信息。以往的普通图模型中,只能对成对的关系进行建模,如用户与物品交互的关系,无法捕获各种节点信息之间的高阶关系,如相似的用户组关系。本文将带有异构信息的行为序列构建为异构图的线图来表达高阶数据关系。
异构图神经网络(heterogeneous graph neural network,HetGNN)[5]在推荐任务中,可以学习图中不同类型节点的潜在信息,同时将图中不同节点嵌入到统一的向量空间中,但无法捕捉节点间的高阶依赖关系。为此,本文对HetGNN 模型进行改进,提出双通道异构图神经网络的用户行为序列推荐算法(user behavior sequence recommendation with dual channel heterogeneous graph neural network,DC-HetGNN),通过构建异构图的线图通道,捕捉节点与节点之间高阶关系,同时充分考虑了物品项目、用户和用户行为序列之间的相关关系,可以通过丰富的信息和复杂项目转移学习序列嵌入,在异构图通道中聚合局部序列和全局序列,保证同时考虑用户的长短期偏好。本文主要贡献如下:
(1)将异构图神经网络用于用户行为序列推荐,将物品、用户和行为序列构造成异构图和异构图的线图,通过异构图神经网络来捕捉物品、用户和行为序列两两之间的关系和跨序列信息。
(2)提出一种基于用户行为序列的双通道异构图神经网络DC-HetGNN。DC-HetGNN 可以从序列中获取用户的潜在信息。
(3)在公共电商用户行为数据集上进行了大量实验。结果表明,本文提出的模型与其他新近基线模型在相同的指标上有显著的提升。
1 相关工作
协同过滤(collaborative filtering,CF)[6]是最流行的推荐方法之一。它根据用户对项目的评级对用户进行分类,并为目标用户找到具有相似兴趣的其他用户。然后CF向目标用户推荐其他用户感兴趣但目标用户没有见过或购买过的商品。矩阵分解(matrix factorization,MF)[7]是一种典型的传统推荐方法。它可以将用户和项目嵌入到相同的向量空间中。用户嵌入和项嵌入的内积是用户对项的兴趣度,而MF不能学习项的序列变换。随后,一个将贝叶斯个性化排序融入到MF中的算法出现,通过转换图来建模排序用户序列行为,即隐性反馈的贝叶斯个性化排名(Bayesian personalized ranking from implicit feedback,BPR-MF)[8]。
近年来,一些利用循环神经网络(recurrent neural network,RNN)优势且应用于用户行为序列推荐方法出现,如基于门控单元的循环网络(recurrent neural network with gate recurrent unit,GRU4Rec)[9]。GRU4Rec考虑了上一个节点与当前节点之间的相关关系,该方法对用户行为序列非常敏感,能够及时捕捉到用户偏好的转移,但是无法了解用户的长期偏好。图神经网络最近受到越来越多的关注,与基于RNN 的方法不同,基于GNN 的方法在序列构造的图中学习项目间的转换。SR-GNN 是使用门控图神经网络将用户行为序列建模为图结构数据的开创性方法。图上下文的自注意力网络(graph contextualized selfattention network,GC-SAN)[10]利用自我注意力机制通过图信息聚合来捕获物品间依赖。全图神经网络(full graph neural network,FGNN)[11]通过将节点分类和图分类相结合用于学习序列嵌入。时序图序列推荐算法(temporal graph sequential recommender,TGSRec)[12]在考虑序列内的时间动态的同时捕捉用户和物品间的相关依赖关系。全局上下文增强的图神经网络(global context enhanced graph neural network,GCE-GNN)[13]在单个序列图和全局序列图上进行图卷积,以学习局部序列和全局序列的嵌入。基于混合模型的图神经网络(graph neural network based hybrid model,GNNH)[14]融合顺序模式和非顺序模式,以捕获序列内的动态兴趣。虽然这些方法表明基于GNN的方法优于其他方法,包括基于RNN的模型,但是它们都没能捕获到复杂的高阶物品间依赖关系。
异构图(heterogeneous graph,HetG)包含了丰富的多类型节点之间的结构关系信息,以及与每个节点相关联的非结构化内容。异构信息网络(heterogeneous information network,HIN)[15]可以将多种类型的节点构建到一个图中,并将这些节点用不同类型的边连接起来,因此HIN 可以对复杂的上下文信息进行建模。由于HIN 具有不同类型的节点或边,很难将这些节点或边嵌入到同一个向量空间中。近年来,一些图嵌入方法,如DeepWalk[16]、metapath2vec[17]、node2vec[18]、LINE(large-scale information network embedding)[19]、ASNE(attributed social network embedding)[20]、Pathsim[21]、Pathselclus[22]等被提出,DeepWalk算法通过随机游走生成节点序列,将其视为一个句子,利用语言建模生成嵌入的节点表示。本文使用DeepWalk 算法将异构图嵌入到相同的向量空间中,获得各类节点的预嵌入表示。Ren 等人提出了一种基于信息网络聚类的有效引文推荐方法ClusCite[23],该方法学习异构信息网络中的引文之间的关系,并将其聚类成兴趣组。Hu等人开发了一种新的具有共同注意机制的深度神经网络——基于元路径的上下文推荐模型(leveraging metapath based context for recommendation,MCRec)[24]。MCRec 学习了基于元路径的用户、对象和上下文的有效表示,实现了较好的交互功能。
2 符号定义及问题描述
本章对描述模型的符号进行定义并描述用户行为序列的推荐问题。
2.1 符号定义
定义1(异构图)将异构图定义为HetG=(N,E),其中异构图节点N是一个包含了物品集合I、用户集合U和用户行为序列集合S的N个节点集合,该节点集合中的节点唯一。异构图边E是一个包含了M条边集合,该集合中的每条边e∈E包含两个或多个节点,并被赋予一个正权值We,e,所有权值构成了一个对角矩阵W∈RM×M。异构图可以用关联矩阵表示为H∈RN×M,其中Hi,e=1 表示边e∈E包含一个节点ni∈N,否则Hi,e=0。每个节点和边的度分别定义为Di,i=和,D和B是对角矩阵。上述中物品集合为I={i1,i2,…,in},其中n为物品的个数。有用户集合为U={u1,u2,…,um},其中m为用户个数。用户行为序列集合为S={s1,s2,…,sj},其中j为行为序列个数。用户行为序列集合S是由用户集合U中用户对物品集合I进行点击行为组成序列。其中,每一个序列s都表示成一个集合,即s={is,1,is,2,…,is,h}。其中is,k∈I(1 ≤k≤h),表示在一个行为序列中用户的一个行为交互项。将有交互项的节点嵌入到同一个模型中获得节点的嵌入集合Node*={I*,S*,U*},并使有交互项的节点嵌入到同一个向量空间中。其中I*表示物品嵌入集合,S*表示用户行为序列嵌入集合,U*表示用户嵌入集合。异构图转化为矩阵表示如图3所示。
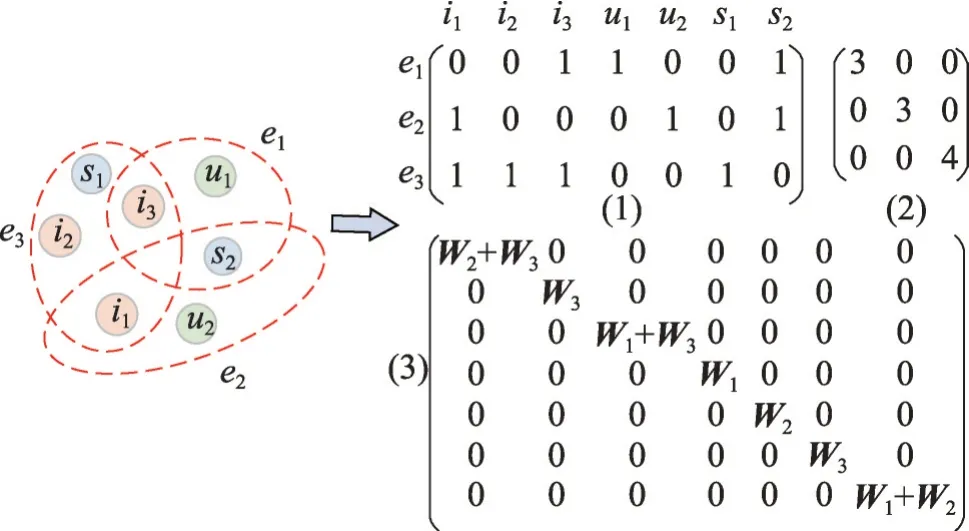
图3 异构图的矩阵表示Fig. 3 Matrix representation of heterogeneous graph
在图3中:(1)部分为异构图的关联矩阵;(2)部分为异构图边的度矩阵;(3)部分为异构图点的度矩阵。
定义2(异构图的线图)给定异构图HetG=(N,E),该图的线图L(HetG)=(NL,EL)中的每个节点是异构图HetG 中的一个边,且L(HetG)的两个节点是连通的,即它们对应的HetG 中的边至少共享一个公共节点。在L(HetG)中,线图节点定义为NL={ne:ne∈E},异构图的线图中连接节点的边定义为EL=E,eq∈E,|ep⋂eq|≥1},给每条边赋值为Wp,q=|ep⋂eq|/|ep⋃eq|。异构图的线图表示如图4所示。
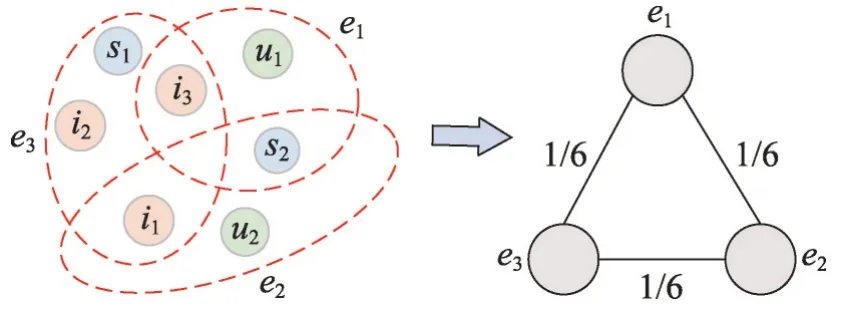
图4 异构图的线图表示Fig. 4 Representation of line graph of heterogeneous graph
在图4中,边e1与边e2中共包含6个节点,含有1个公共节点s2,故在线图中连接节点e1和节点e2的边的权重为W1,2=。其他边的权重同理。
2.2 问题描述
基于用户行为序列的推荐系统的主要任务是通过给定一个用户行为序列s,本文模型Fθ将用户行为序列集合S分别构造成异构图HetG 和异构图的线图L(HetG),通过异构图通道和线图通道学习包含了丰富信息和物品间转换关系的物品项嵌入I*={i1,i2,…,in}。然后模型将生成最终混合序列嵌入。最后通过softmax 层获得项目的得分,将排名前n的物品项is,h+1作为下一个项目推荐给用户。
(1)异构图的构建
本文将异构图节点定义为N=(I,S,U),其中I表示物品集合,S表示用户行为序列集合,U表示用户集合,将以上节点的集合构造为一个异构图HetG=(N,E)。HetG 包含三种类型的节点以及两种类型的边,三种类型的节点分别是物品节点、用户行为序列和用户节点。两种类型的边分别为连接两个物品之间有向边集合Ei和无向边集合E。其中有向边Ei=(is,h,is,h+1)表示用户在购买了物品is,h之后又购买了is,h+1。无向边E={(is,h,s),(is,h,u),(s,u)}分别表示物品与用户行为序列、物品与用户之间和用户行为序列与用户之间的关系。
(2)异构图通道学习项目嵌入
在构建异构图HetG 之后,本文利用异构图神经网络学习物品的嵌入表示,将用户节点和行为序列节点的信息聚合成物品嵌入I*={i1,i2,…,in},其中物品嵌入项ik是节点ik的向量表示。
(3)线图通道学习项目嵌入
在构建异构图的线图L(HetG)之后,本文设计了异构图的线图卷积模型。线图可以看成一个简单的图,它包含跨序列信息并描述项与项的连通性。
3 DC-HetGNN模型
本章将介绍提出的DC-HetGNN 模型,并介绍完整的DC-HetGNN 学习算法。DC-HetGNN 模型架构图如图5所示。
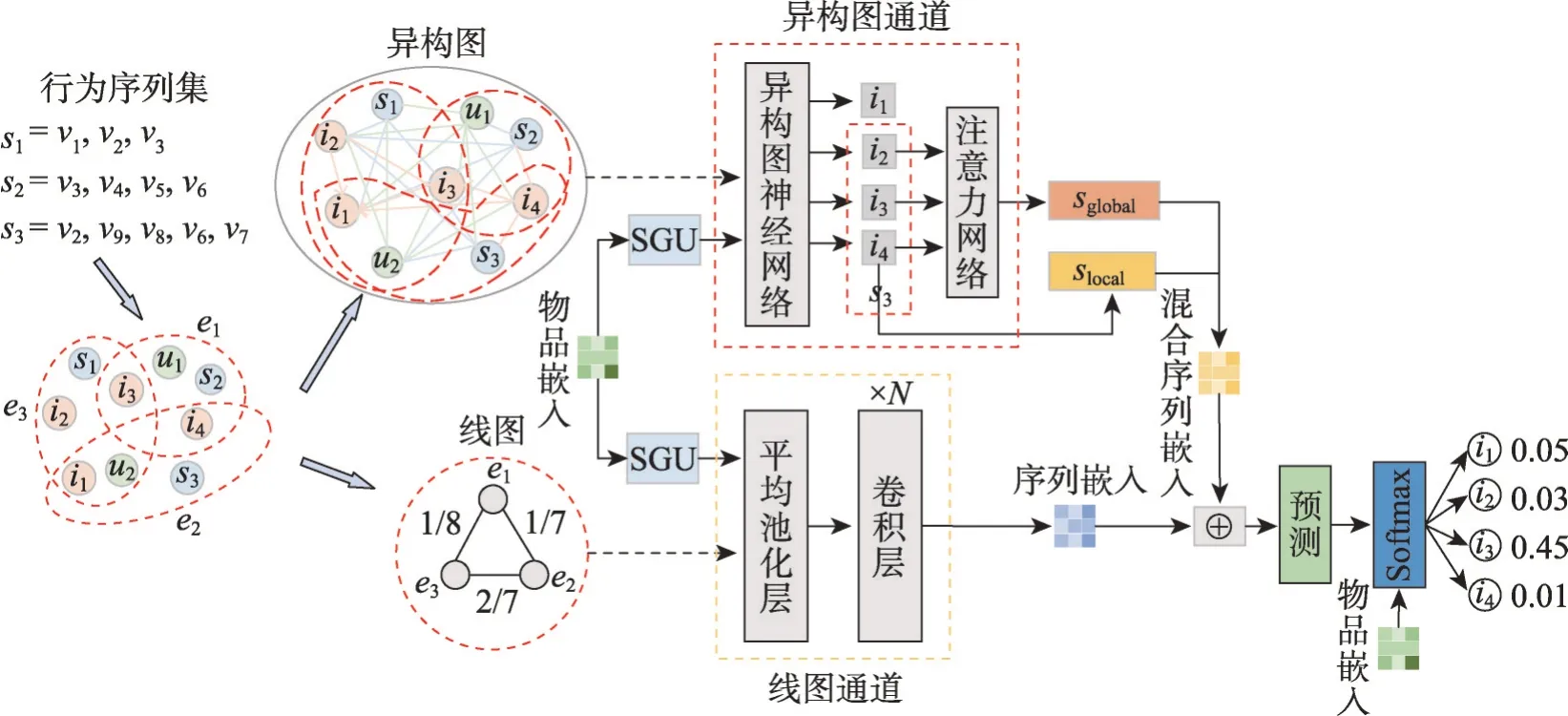
图5 DC-HetGNN模型框架Fig. 5 Model framework of DC-HetGNN
在图5中可以看到,DC-HetGNN展示对用户、物品以及用户行为序列进行异构图建模和异构图线图建模,分别将建模后的嵌入集输入异构图通道和线图通道进行物品学习。通过异构图通道和线图通道最终会分别得到序列嵌入,最后将两个序列嵌入聚合,用于物品推荐。异构图通道使用异构图神经网络进行学习节点嵌入,异构图神经网络学习物品嵌入的过程如图6所示。
图6 中异构图神经网络主要分为三部分进行描述:(1)部分首先对异构图中所有节点进行采样,采样完成之后,对节点中不同的数据类型使用不同的技术进行编码,接着将编码后的信息通过全连接层和BiLSTM 层进行特征能力累积表达,最终获得节点的内容嵌入。(2)部分将相同类型的邻居节点进行聚合。(3)部分采用注意力机制将不同类型的邻居节点与当前节点进行聚合,最终获得当前节点的内容嵌入。
3.1 构造异构图
首先,需要将用户行为序列集合S构造成异构图HetG=(I,S,U,E),接着构造异构图的线图L(HetG)=(IL,SL,UL,EL)。HetG 创建后,利用DeepWalk 算法,收集物品、用户和行为序列节点。然后使用Word2Vec对这些节点向量进行训练,生成所有节点的预嵌入向量。
3.2 异构图通道和线图通道学习项目嵌入及序列生成
3.2.1 异构图通道学习项目嵌入及序列生成
经过预训练之后生成的节点嵌入向量,每个向量在相同维度空间中。但此时预嵌入的节点向量缺乏表达能力,无法表达复杂关系之间的物品间转换。使用传统图神经网络进行异构图学习不能直接从不同类型的邻居中获取其特征信息,节点的嵌入可能受到弱相关邻居的影响,冷启动节点的嵌入不充分。异构邻居需要不同的特征转换来处理不同的特征类型和维度。采用异构图神经网络HetGNN 学习包含丰富信息和复杂转换关系的项嵌入。采用聚合异构邻居的思想,HetGNN主要分为以下四部分:
(1)对异构邻居进行采样
由于异构图中的邻居节点的类型和数量不同,聚合这些节点需要不同的特征转换。例如,用户1的3条行为序列中出现了4次商品购买行为,用户2的4条行为序列中出现了5次商品购买行为。此时,两位用户的邻居节点大小不同,为了方便使用相同的模型聚合这些异构邻居节点,采用基于重启的随机游走(random walk with restart,RWR)方法对异构邻居进行采样。RWR的主要步骤如下:
步骤1在物品集I={i1,i2,…,in}、用户集U={u1,u2,…,um}和行为序列集S={s1,s2,…,sj}中,对每个节点vi∈{I,U,S}开始随机遍历。遍历过程中,以概率P迭代地移动到当前节点的邻居或返回起始节点。直到固定数量的节点都被收集,RWR 运行就会停止。收集到的节点集中不同类型节点数量会有上限,确保所有节点类型都可以被采样。
步骤2分组不同类型的邻居。对于每个节点类型t,从步骤1中的节点集中根据出现次数进行降序排列,选取前k个节点作为节点v的t类型相关邻居节点集合。
(2)聚合异构邻居的节点内容
不同类型的异构邻居具有不同的节点内容。例如,用户节点可能包含性别、地域、角色等静态属性,也可能包含社交习惯、娱乐偏好、消费水平等动态属性。而物品节点包含名称、类型、价格等静态属性。HetGNN设计了一种基于双向长短期记忆网络(bidirectional long short-term memory,BiLSTM)的体系结构,获取节点特征之间的交互,将节点的所有属性聚合为节点的嵌入表示,使其具有更强的表达能力。节点v是节点vi的异构邻居,其属性集为Attr={attr1,attr2,…,attrn},使用不同的模型将属性attri转换成同维度的特征嵌入向量Att*={att1,att2,…,attn}。例如,使用One-Hot对预训练文本进行编码,使用卷积神经网络(convolutional neural networks,CNN)来预训练图像内容等。在得到节点各属性嵌入之后,节点嵌入f1(v)公式如下:
其中,f1(v)∈Rd×l,d表示嵌入维数;表示具有参数θx的全连接神经网络并且无需变换的特征转换器;⊕表示连接运算。LSTM公式如下:
其中,hi∈R(d/2)×l表示第i个隐藏层输出状态,∘是哈达玛积,,Wi∈R(d/2)×(d/2)和bi∈R(d/2)×l(i∈(z,f,o,c))为可学习的参数,zi、fi和oi分别为遗忘门第i层特征输出、输入门第i层特征输出和输出门第i层特征输出。上文中f1(v)首先使用不同的带参数的全连接层FCθx对不同内容特征进行转换,然后利用BiLSTM捕获深层次的特征交互,累积所有内容特征的表达能力,最后利用均值池化层处理所有隐藏状态,最终得到节点v的一般内容嵌入。
(3)聚合相同类型的异构邻居
聚合异构邻居的节点内容后,每个节点有多种类型的异构邻居且每种类型t有多个异构邻居。使用BiLSTM将相同类型的节点聚合成一个向量嵌入,HetGNN会学习它们之间的复杂关系,从而使学习到类型嵌入f2(t)具有更强的表达能力。类型嵌入f2(t)公式如下:
(4)聚合不同的类型
在得到类型嵌入后,由于不同类型的邻居会对节点v的最终表示产生不同的影响,在结合基于类型的邻居嵌入与节点v的内容嵌入的过程中,采用注意力机制。此时,节点vi的最终嵌入计算表示为:
其中,T是包含异构节点的类型集合。avi j表示每种类型对节点v产生的影响值,计算表示如下:
其中,LeakyReLU为激活函数,U∈R2d×l表示注意力参数,F2(T)表示类型嵌入f2(t)的集合,t∈T表示一个异构节点的类型。
在使用HetGNN学习项目嵌入之后,进行序列嵌入的生成。对于序列s={is,1,is,2,…,is,h},预嵌入向量的过程如下:
其中,is,h是节点is,h的节点嵌入,i0是没有固定维数的零向量,⊕表示连接操作。由于序列中的项数可能不同,需要连接i0,以便所有预嵌入的会话向量具有相同的维数。同时,考虑到用户长短期偏好分别对结果的影响,加入注意力机制,获得了能够表达长短期偏好混合的序列嵌入。首先考虑到序列的局部嵌入slocal,其表达公式如下:
其中,is,n是当前序列中最后一项的嵌入向量。对于用户长期偏好,需要重点考虑项与项之间的变换关系,同样采用注意力机制来学习序列全局嵌入sglobal,其表达公式如下:
其中,WT∈Rd,W1,W2∈Rd×2d是用于生成物品嵌入的权重矩阵。在得到序列的全局嵌入和局部嵌入后,生成混合序列嵌入,过程如下:
其中,利用W3∈Rd×2d将slocal和sglobal融合到混合序列嵌入中。异构图通道学习项目嵌入及序列生成算法如算法1所示。算法时间复杂度为O(nd2)。
算法1异构图通道学习项目嵌入及序列生成算法HLearn
3.2.2 线图通道学习项目嵌入及序列生成
线图通道对异构图的线图进行编码。线图可以看作一个包含跨行为序列信息并描述边连通性的简单图,在进行卷积操作之前,将基础物品嵌入I(0)输入SGU(self-gating unit)并获得线图通道的物品嵌入。其中获得的过程如下:
其中,Wg∈Rd×d,bg∈Rd都是需要学习的参数。σ为激活函数。
线图通道学习项目嵌入及序列生成算法如算法2所示。算法复杂度为O(n2d)。
算法2线图通道学习项目嵌入及序列生成算法LLearn
3.3 双通道异构图神经网络的用户行为序列推荐
给定一个用户行为序列s,通过分别计算I(0)和sline的点积以及I(0)和shybrid的点积为所有物品项i∈I计算一个得分,然后将两个预测分数相加得到最终预测分数:
然后,使用softmax 函数计算每一个项目成为序列中的下一个项目的概率:
本文将学习目标定义为推荐系统中得到广泛应用的交叉熵损失函数,并且使用Adam优化器最小化交叉熵以获得高质量的推荐结果。记交叉熵函数的定义为:
其中,y是真实数据的One-Hot编码向量。DC-HetGNN核心算法如算法3所示。
算法3DC-HetGNN算法
4 实验
4.1 数据集
本文采用两个电商数据集Tmall 和Diginetica 来评估本文提出的模型,两个数据集中均包含了用户的个人信息及行为信息。为了避免冗余数据对本文模型产生的影响,本文对两个数据集均进行了预处理。其中,对数据集Diginetica 进行预处理的内容如下:删除数据集中只包含一个物品的所有行为序列,并删除了出现次数少于5 次的物品。由于构建异构图需要用户节点,需要删除匿名用户的行为数据。本文将数据集Diginetica 拆分为训练集和测试集,使用最近几周的数据作为测试集,其他数据作为训练集。最终经过清洗的数据集如表1所示。

表1 Diginetica数据集Table 1 Diginetica dataset
本文选取的Tmall 数据集为用户行为数据集。对此数据集预处理的内容如下:删除产生序列行为次数少于20次的用户项,删除了出现次数少于10次的物品项。选取该数据集最近15天的行为数据作为测试集,其他作为训练集。最终经过处理的数据集如表2所示。

表2 Tmall数据集Table 2 Tmall dataset
4.2 对比模型
本文将提出的DC-HetGNN 与以下新近的序列化推荐模型进行比较,并给出不同模型的时间复杂度。
SR-GNN[4]:将会话序列构造为同构图,并利用GNN学习项嵌入。
HetGNN[5]:将会话序列构造成异构图,通过神经网络模块编码聚合采样同构和异构图节点,以端到端的方式训练模型,在聚类、分类和归纳任务中有出色表现。
BPR-MF[8]:该算法利用矩阵分解学习用户偏好,提出了一种通用的个性化排序优化准则BRP-opt,并将其应用到MF中。
GRU4Rec[9]:利用会话并行小批量训练过程,采用基于排序的损失函数对用户序列进行建模。
FGNN[11]:利用节点分类和图分类学习序列最终嵌入。
TGSRec[12]:同时考虑序列中时间动态并捕捉物品与用户之间的依赖关系。
为了方便复杂度描述,记n表示节点数,d表示隐藏层特征维度。各模型时间复杂度如表3所示。
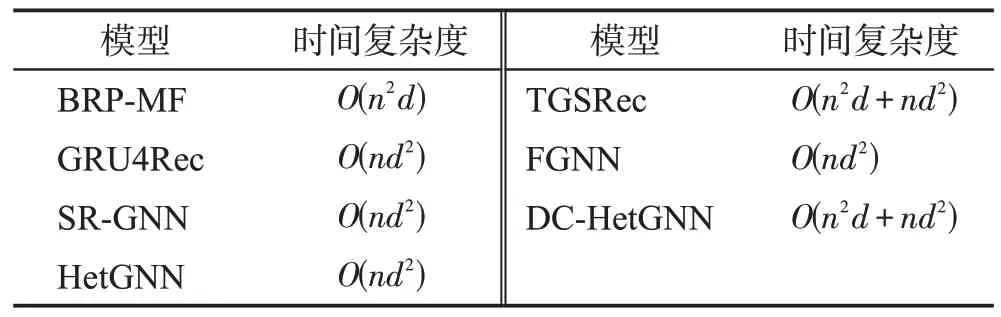
表3 模型时间复杂度Table 3 Time complexity of model
从表3 中可以看出,本文模型DC-HetGNN 时间复杂度相较于其他基线模型没有指数级的增长。
4.3 实验设置
在本文模型中,嵌入维度为128,最小批大小为200,线图通道中卷积层数为2 层,学习率设置为0.000 1。节点的异构邻居数是一个非常重要的参数,这组参数包括用户邻居数、物品邻居数和行为序列邻居数。经过在两个数据集中的大量实验,在Diginetica数据集中,用户邻居数设置为12,物品邻居数设置为8,行为序列邻居数设置为1时,模型的性能最好。在Tmall数据中,用户邻居数设置为1,物品邻居数为1,行为序列邻居数设置为15,模型性能最好。在实验过程中,通过自动更新学习率,最终在学习率lr=0.000 1 时,模型性能在数据集Diginetica 和Tmall 中都是最好的。对比模型的超参数设置除特别指出的外,其他的与原文中的设置相同。
本文在Top-n推荐场景中,采用两个推荐系统中常用指标来评估模型,分别为Recall@n和MRR@n,其中n=10,20,50。
4.4 结果及分析
本节将给出不同对比模型和本文的模型DCHetGNN 的比较结果。表4 为本文模型在Tmall 和Diginetica 数据集中不同n值下与其他基线模型的性能对比。
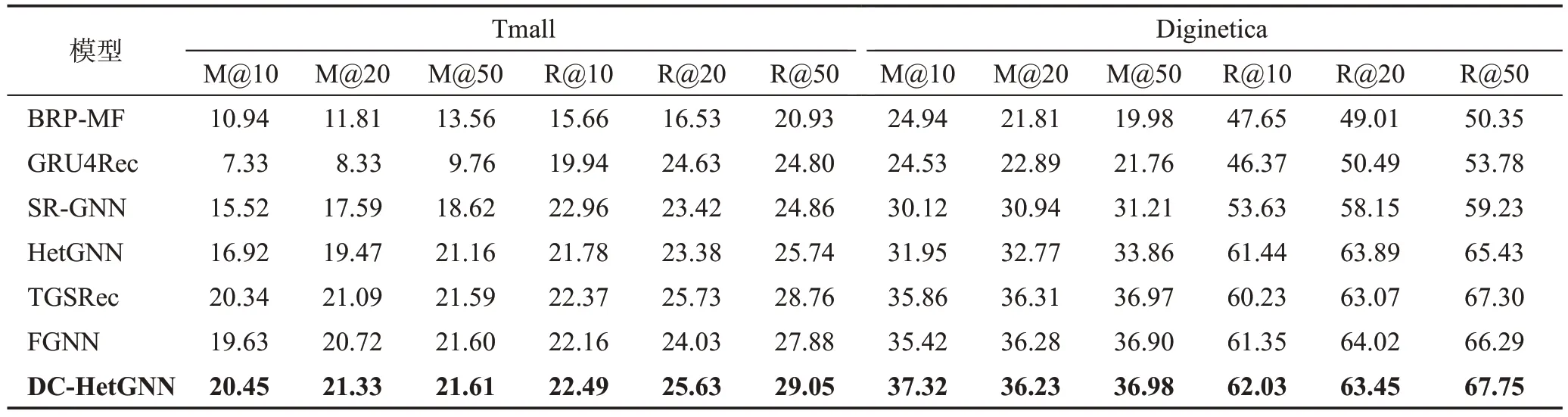
表4 在两个数据集中模型推荐性能Table 4 Recommended performance of all models on two datasets 单位:%
从表4可以看出,模型DC-HetGNN在Top-n推荐场景中较其他模型取得了较好的性能。因为DCHetGNN将用户行为序列构造成包含项目节点、用户节点和序列节点的异构图。异构图包含复杂的依赖关系,可以显示项之间的转换、物品间的转换、项与用户之间的连接关系。与HetGNN相比,大部分情况下,在相同指标下有所提升。HetGNN关注复杂物品间的转换,但忽略了用户行为序列之间的关系,本文在异构图学习通道的基础上加入异构图的线图学习通道,线图通道描述了用户行为序列级的关系,这样可以使生成的序列嵌入更加具有表现力。在n=50时,与基准模型SR-GNN对比,在数据集Diginetica中Recall提升了8.52个百分点,MRR提升了18.49%;在数据集Tmall 中Recall 和MRR 分别提升了4.19 个百分点和16.06%。与原模型HetGNN相比,在两个数据集中,Recall分别平均提升0.82%和2.09%,与GRU4Rec在各项指标上均有提升。SR-GNN和GRU4Rec两个都是基于图神经网络的模型,其中,GRU4Rec的核心是一种RNN 的变体,RNN 对序列化数据比较敏感,但是RNN 只能模拟连续项之间的单向传递,不能考虑远距离物品之间的依赖关系,从而会忽略行为序列中的一些信息。SR-GNN 将用户行为序列构造为同构图,这种同构图只具有项目之间的转换,忽略了行为序列中的其他信息,特别是用户信息。BRP-MF使用矩阵分解MF 来学习用户偏好,但MF 不能很好地处理序列化数据,因此最终的结果并不理想。DCHetGNN 与新近模型FGNN 相比,在指标MRR@n和Recall@n中平均分别提升2.08%和0.78%,FGNN 虽然将图分类和节点分类相结合,但并未考虑用户行为序列之间的关系。与TGSRec 相比,在指标MRR@n和Recall@n中平均分别提升2.70%和0.49%,TGSRec考虑了序列内部时间节点因素对于用户偏好的影响,但缺乏用户长期偏好的参考。
学习率lr是模型训练中一个重要的超参数,它决定了目标函数是否收敛到局部最小值以及何时收敛到最小值。本文设置了不同的学习率对模型进行训练,实验结果如图7所示。
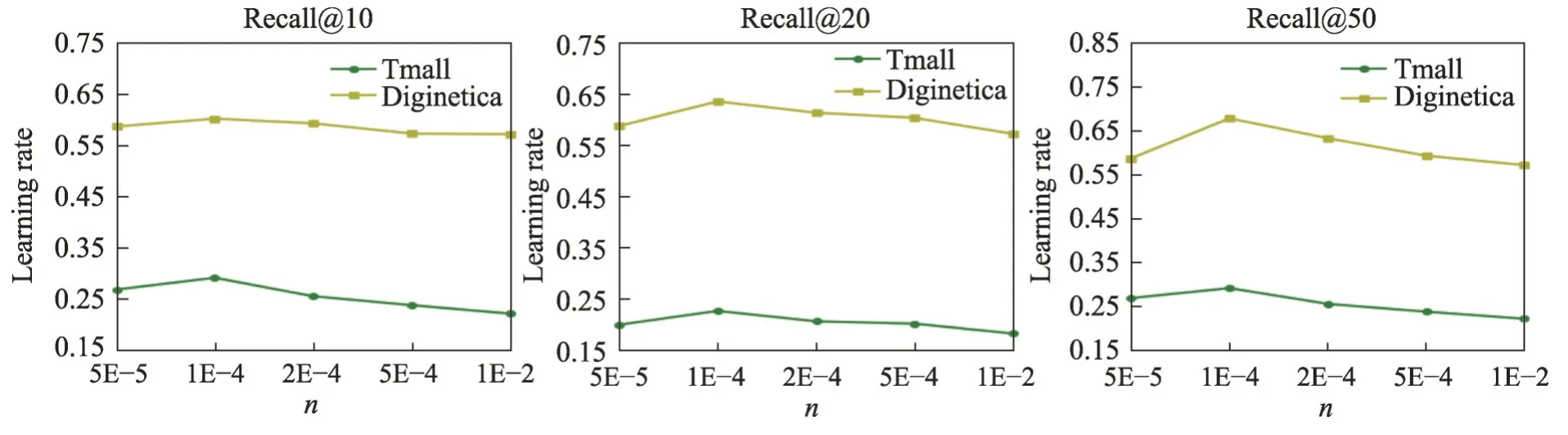
图7 不同n 值下的模型学习率Fig. 7 Learning rate of model under different n values
从图7 可以看出,模型在不同n值下,当学习率lr=0.000 1时,在Tmall和Diginetica数据集上性能都是最好。因此,选择lr=0.000 1作为本文模型的最佳参数。
在图网络学习过程中,特征嵌入维度的选择对推荐结果好坏起到了重要的作用,过多特征维度嵌入设置并不一定会使推荐效果最优,甚至导致过拟合。过低的特征维度会使图网络学习效果变差,为了得到本模型最佳嵌入维度,本文对嵌入维度的选择在两个数据集中进行了大量实验,并绘制了实验结果图,效果图如图8所示。
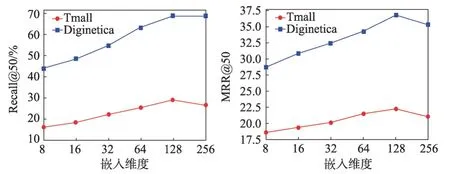
图8 不同嵌入维度下各指标的值Fig. 8 Value of each indicator under different embedded dimensions
在图8中,当嵌入维度从8到128之间变化时,在两个指标和数据集中结果都会增加,应为随着维度的增加,图网络可以更好地学习特征。但当嵌入维度进一步增加时,结果变得稳定或者下降,这可能是过拟合的原因。
在模型的训练过程中,目标函数会在某一时刻得到最优值。此时继续训练模型就没有意义,因为模型的性能很难得到明显的提升。因此,何时停止训练模型,节省时间很重要。本文选取常用优化器Adam和优化器SGD(stochastic gradient descent)并使用相同的环境与参数分别进行实验,并通过绘制模型的损失曲线来判断模型何时收敛。训练过程中的损失曲线如图9所示。
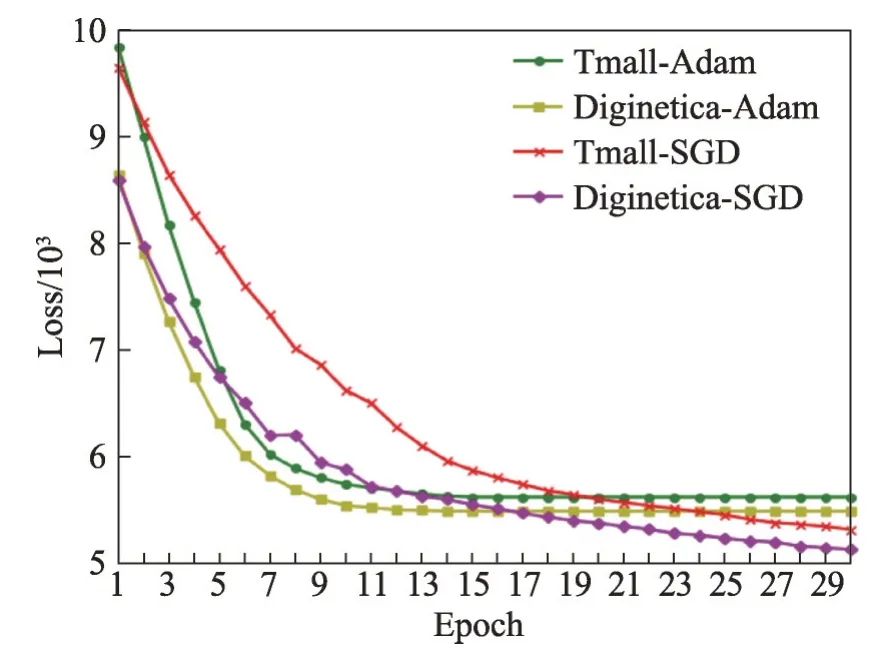
图9 模型训练的收敛过程Fig. 9 Convergence process of model
从图9可以看出,使用Adam优化器比使用SGD优化器收敛速度更快,但是精度并没有SGD高,为了降低大量的训练时间,本文选取Adam作为本文模型的优化器。本文模型使用Adam优化器在Tmall数据集和Diginetica 数据集中分别在epoch 为14 和13 时达到收敛。因此可以在训练模型时,将epoch分别设置为14 和13。使用SGD 优化器需要更多轮的训练次数才能使模型达到收敛。
节点的邻居数是本文模型一个重要的超参数,本文在进行大量实验后,得到节点的邻居数在两个数据集中的最佳值,结果如图10所示。
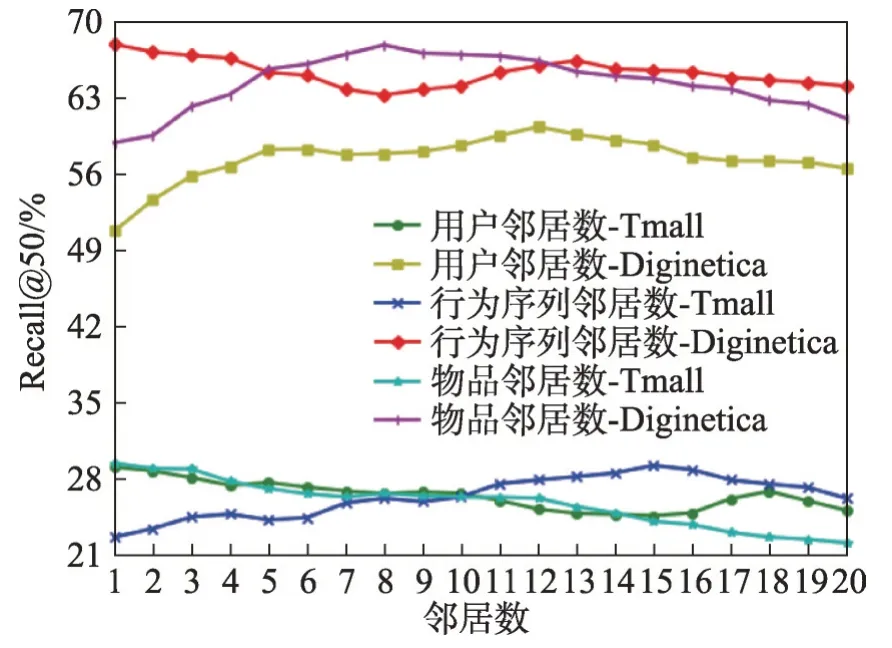
图10 不同类型节点邻居数下Recall@50的值Fig. 10 Recall@50 under different types of node neighbour number
从图10 可以看出,在Tmall 数据集中,用户邻居数设置为1,物品邻居数为1,行为序列邻居数设置为15,模型性能较好。与Tmall 数据集不同的是,Diginetica数据集中,用户邻居数设置为12,物品邻居数设置为8,行为序列邻居数设置为1时,模型的性能更好。这是因为本文模型需要不同数量的邻居来提取不同长度用户行为序列中的信息。如,在Diginetica数据集中,用户邻居数的最优值为12,而在Tmall数据集中,用户邻居数的最优值为1,可以看出,在不同场景中,使用过多的异构邻居来提取信息,可能会受到噪声节点的干扰,从而降低模型的性能。
本文考虑到在现实世界中,用户行为序列通常有不同的长度,会对本文模型产生影响,故将Tmall和Diginetica 中的序列分成两个不同长度的组,并分别命名为短序列组和长序列组。其中,短序列组包含长度小于等于5的序列,长序列组包含长度大于5的序列。DC-HetGNN 与SR-GNN、GRU4Rec、HetGNN在Recall@20 上的短序列组和长序列组的推荐结果对比如图11所示。

图11 长序列和短序列的Recall@20的值Fig. 11 Recall@20 of long sequences and short sequences
从图11可以看出,在大多数情况下,DC-HetGNN在不同序列长度下优于在Tmall 和Diginetica 上的所有基准模型。对于DC-HetGNN来说,同时关注了长序列和短序列建模,短序列更能及时地反映用户的偏好转移,长序列中含有用户历史行为序列,包含噪声,因此本文模型在短序列上的性能表现优于长序列。
为了研究DC-HetGNN 层数对性能的影响,本文对模型设置不同层数并进行实验对比。本文将模型的层数范围设为layer=1,2,3,4。实验结果如图12所示。
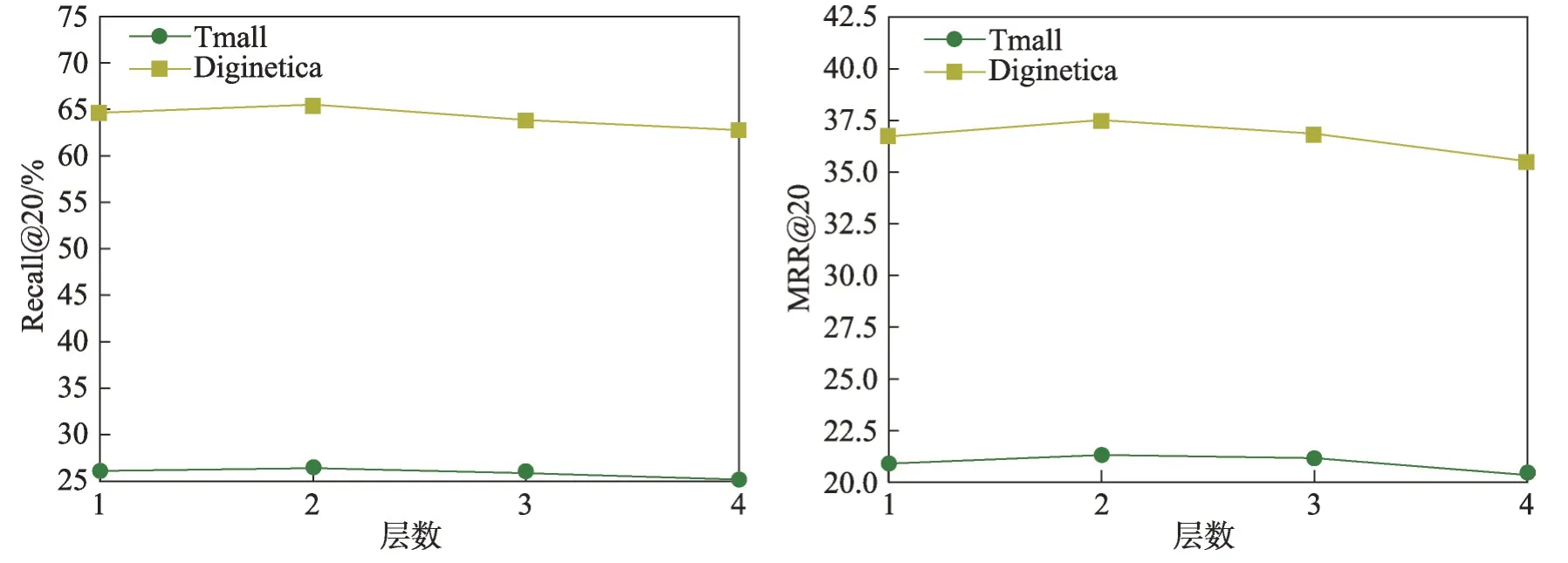
图12 模型层数性能对比Fig. 12 Performance comparison of the number of layer
从图12可以看出,DC-HetGNN在两个数据集上对层数的取值不是很敏感。层数设置为2 时是最好的,当层数大于2时,性能略有下降。
5 结束语
本文将异构图神经网络HetGNN 和转换后的异构图的线图L(HetG)结合并应用于用户行为序列的推荐。首先,将行为序列构造成包含多种类型节点的异构图。然后,使用HetGNN和L(HetG)学习包含复杂的项目转换和用户信息的项目嵌入。最后,利用注意力网络生成具有强大表达能力的序列嵌入,从而使学习到的序列嵌入能够表达用户的特定偏好。实验结果表明,本文方法优于其他常用方法。
文中使用了两个电子商务数据集,由于数据集中字段的限制,在构建异构图时只考虑三种类型的节点。在接下来的研究中,将继续研究具有多种类型节点的真实数据集,这样学习到的序列嵌入将具有更强大的表达能力。
